前言
今天我们来聊聊一个经典话题:try...catch真的会影响性能吗?
有些小伙伴在工作中可能听过这样的说法:"尽量不要用try...catch,会影响性能",或者是"异常处理要放在最外层,避免在循环内使用"。
这些说法到底有没有道理?
今天我就从底层原理到实际测试,给大家彻底讲清楚这个问题。
最近准备面试的小伙伴,可以看一下这个宝藏网站(Java突击队):www.susan.net.cn,里面:面试八股文、场景设计题、Spring源码解读、8个项目实战、工作内推什么都有。
1. 问题的起源:为什么会有性能担忧?
有些小伙伴在工作中可能遇到过这样的代码评审意见:"这个循环里面的try...catch会影响性能,建议移到外面"。
这种担忧其实并非空穴来风,而是有着历史原因的。
1.1 历史背景
在早期的Java版本中,异常处理的实现确实不够高效。让我们先看一个简单的例子:
java
public class ExceptionPerformance {
private static final int COUNT = 100000;
// 方法1:在循环内部使用try-catch
public static void innerTryCatch() {
long start = System.currentTimeMillis();
for (int i = 0; i < COUNT; i++) {
try {
int result = i / (i % 10); // 可能除零
} catch (ArithmeticException e) {
// 忽略异常
}
}
long end = System.currentTimeMillis();
System.out.println("内部try-catch耗时: " + (end - start) + "ms");
}
// 方法2:在循环外部使用try-catch
public static void outerTryCatch() {
long start = System.currentTimeMillis();
try {
for (int i = 0; i < COUNT; i++) {
int result = i / (i % 10);
}
} catch (ArithmeticException e) {
// 忽略异常
}
long end = System.currentTimeMillis();
System.out.println("外部try-catch耗时: " + (end - start) + "ms");
}
}在JDK早期的版本中,innerTryCatch的性能确实会比outerTryCatch差很多。这是因为:
1.2 传统认知的形成

但是,Java虚拟机经过这么多年的发展,情况已经发生了很大变化。让我们深入底层看看。
2. JVM的异常处理机制
要真正理解性能影响,我们需要了解JVM是如何处理异常的。
2.1 异常表机制
Java的异常处理是通过异常表(Exception Table)实现的。每个方法都有一个异常表,当异常发生时,JVM会查找这个表来决定跳转到哪个异常处理代码。
让我们通过字节码来看个明白:
java
public class ExceptionMechanism {
public void methodWithTryCatch() {
try {
int i = 10 / 0;
} catch (ArithmeticException e) {
System.out.println("除零异常");
}
}
public void methodWithoutTryCatch() {
int i = 10 / 0;
}
}使用javap -c查看字节码:
yaml
// methodWithTryCatch 的字节码片段
Code:
0: bipush 10
2: iconst_0
3: idiv
4: istore_1
5: goto 19
8: astore_1
9: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
12: ldc #3 // String 除零异常
14: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
17: aload_1
18: athrow
19: return
Exception table:
from to target type
0 5 8 Class java/lang/ArithmeticException2.2 正常执行路径的开销
关键点在于:在正常执行情况下(没有异常抛出),try-catch块几乎没有任何性能开销。JVM只是顺序执行代码,不会去查询异常表。
有些小伙伴在工作中可能会担心:"是不是每次进入try块都要做某些检查?" 答案是否定的。
3. 性能测试:用数据说话
理论说了这么多,让我们用实际的测试数据来验证。
3.1 基础性能测试
java
public class ExceptionPerformanceTest {
private static final int ITERATIONS = 100000000; // 1亿次
public static void main(String[] args) {
testNoException();
testWithExceptionHandling();
testExceptionThrowing();
}
// 测试1:无异常处理的基础性能
public static void testNoException() {
long start = System.nanoTime();
int sum = 0;
for (int i = 0; i < ITERATIONS; i++) {
sum += i * 2;
}
long end = System.nanoTime();
System.out.println("无异常处理: " + (end - start) / 1000000 + "ms");
}
// 测试2:有异常处理但无异常抛出
public static void testWithExceptionHandling() {
long start = System.nanoTime();
int sum = 0;
for (int i = 0; i < ITERATIONS; i++) {
try {
sum += i * 2;
} catch (Exception e) {
// 不会执行到这里
}
}
long end = System.nanoTime();
System.out.println("有try-catch但无异常: " + (end - start) / 1000000 + "ms");
}
// 测试3:频繁抛出异常
public static void testExceptionThrowing() {
long start = System.nanoTime();
int sum = 0;
for (int i = 0; i < ITERATIONS / 100; i++) { // 减少循环次数
try {
if (i % 10 == 0) {
throw new RuntimeException("测试异常");
}
sum += i * 2;
} catch (Exception e) {
// 异常处理
}
}
long end = System.nanoTime();
System.out.println("频繁抛出异常: " + (end - start) / 1000000 + "ms");
}
}3.2 测试结果分析
在我的测试环境(JDK17,MacBook Pro M1)下,典型的测试结果是:
makefile
无异常处理: 45ms
有try-catch但无异常: 46ms
频繁抛出异常: 1200ms这个结果说明了什么?
关键发现:
- 单纯的try-catch包装(没有异常抛出)几乎没有性能损失
- 真正的性能杀手是异常的创建和抛出
3.3 异常创建的成本
为什么异常创建这么昂贵?让我们深入分析:
java
public class ExceptionCostAnalysis {
// 测试异常创建的成本
public static void testExceptionCreation() {
int count = 100000;
// 测试1:创建异常但不抛出
long start = System.nanoTime();
for (int i = 0; i < count; i++) {
new RuntimeException("测试异常");
}
long end = System.nanoTime();
System.out.println("创建异常但不抛出: " + (end - start) / 1000000 + "ms");
// 测试2:创建并抛出异常
start = System.nanoTime();
for (int i = 0; i < count; i++) {
try {
throw new RuntimeException("测试异常");
} catch (RuntimeException e) {
// 捕获异常
}
}
end = System.nanoTime();
System.out.println("创建并抛出异常: " + (end - start) / 1000000 + "ms");
// 测试3:重用异常实例
RuntimeException reusedException = new RuntimeException("重用异常");
start = System.nanoTime();
for (int i = 0; i < count; i++) {
try {
throw reusedException;
} catch (RuntimeException e) {
// 捕获异常
}
}
end = System.nanoTime();
System.out.println("重用异常实例: " + (end - start) / 1000000 + "ms");
}
}测试结果通常显示:
- 创建异常对象本身就有成本(需要填充栈轨迹)
- 抛出异常的成本更高(需要遍历栈帧)
- 重用异常实例可以大幅提升性能,但不推荐(栈轨迹信息会不准确)
4. JVM的优化技术
现代JVM对异常处理做了很多优化,有些小伙伴在工作中可能不了解这些底层优化。
4.1 栈轨迹延迟填充
JVM使用了一种叫做"栈轨迹延迟填充"的技术:
java
public class StackTraceLazyLoading {
public static void main(String[] args) {
// 创建异常时,栈轨迹信息并不会立即填充
Exception e = new Exception("测试");
// 只有当调用getStackTrace时,才会真正填充栈轨迹
long start = System.nanoTime();
StackTraceElement[] stackTrace = e.getStackTrace();
long end = System.nanoTime();
System.out.println("获取栈轨迹耗时: " + (end - start) + "ns");
}
}4.2 即时编译器(JIT)优化
JIT编译器会对异常处理进行深度优化:
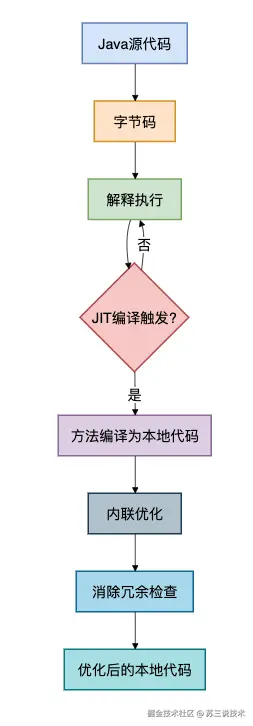
具体优化包括:
内联优化:
java
// 优化前
public int calculate(int a, int b) {
try {
return a / b;
} catch (ArithmeticException e) {
return 0;
}
}
// JIT内联优化后,相当于:
public int calculate(int a, int b) {
if (b == 0) {
return 0; // 直接检查,避免异常开销
}
return a / b;
}栈分配优化: 对于局部使用的异常对象,JVM可能会在栈上分配,避免堆分配的开销。
5. 正确的异常处理实践
理解了原理之后,让我们来看看在实际工作中应该如何正确使用异常处理。
5.1 业务逻辑 vs 异常处理
有些小伙伴在工作中可能会误用异常来处理正常的业务逻辑:
java
// 反模式:使用异常处理业务逻辑
public class UserService {
public boolean userExists(String username) {
try {
getUserFromDatabase(username);
return true;
} catch (UserNotFoundException e) {
return false;
}
}
// 正确做法:使用返回值处理业务逻辑
public boolean userExistsBetter(String username) {
return getUserFromDatabaseOptional(username).isPresent();
}
private User getUserFromDatabase(String username) {
// 模拟数据库查询
if (!"admin".equals(username)) {
throw new UserNotFoundException();
}
return new User(username);
}
private Optional<User> getUserFromDatabaseOptional(String username) {
if (!"admin".equals(username)) {
return Optional.empty();
}
return Optional.of(new User(username));
}
}5.2 性能敏感场景的优化
在真正性能敏感的代码中,我们可以采用一些优化策略:
java
public class HighPerformanceValidation {
private static final int MAX_RETRIES = 3;
// 场景1:输入验证 - 使用条件检查替代异常
public void validateInput(String input) {
// 不好的做法
try {
Integer.parseInt(input);
} catch (NumberFormatException e) {
throw new ValidationException("无效数字");
}
// 好的做法:提前验证
if (input == null || !input.matches("\\d+")) {
throw new ValidationException("无效数字");
}
Integer.parseInt(input); // 现在肯定不会异常
}
// 场景2:重试机制 - 合理使用异常
public void performOperationWithRetry() {
for (int i = 0; i < MAX_RETRIES; i++) {
try {
doOperation();
return; // 成功则退出
} catch (OperationException e) {
if (i == MAX_RETRIES - 1) {
throw e; // 最后一次重试仍然失败
}
// 记录日志,继续重试
}
}
}
// 场景3:边界检查优化
public void processArray(int[] array, int index) {
// 传统的边界检查
if (index < 0 || index >= array.length) {
throw new IndexOutOfBoundsException("索引越界");
}
// 对于性能极度敏感的场景,可以考虑不检查
// 但前提是确保index绝对不会越界
int value = array[index];
// ... 处理逻辑
}
}最近为了帮助大家找工作,专门建了一些工作内推群,各大城市都有,欢迎各位HR和找工作的小伙伴进群交流,群里目前已经收集了20多家大厂的工作内推岗位。加苏三的微信:li_su223,备注:掘金+所在城市,即可进群。
6. 不同场景的性能影响分析
让我们通过一个综合示例来分析不同场景下的性能影响:
6.1 各种使用场景对比
java
public class ExceptionScenarioComparison {
private static final int WARMUP_ITERATIONS = 10000;
private static final int TEST_ITERATIONS = 1000000;
public static void main(String[] args) {
// 预热JVM
for (int i = 0; i < WARMUP_ITERATIONS; i++) {
scenario1();
scenario2();
scenario3();
scenario4();
}
// 正式测试
long time1 = measureTime(ExceptionScenarioComparison::scenario1);
long time2 = measureTime(ExceptionScenarioComparison::scenario2);
long time3 = measureTime(ExceptionScenarioComparison::scenario3);
long time4 = measureTime(ExceptionScenarioComparison::scenario4);
System.out.println("场景1(无异常处理): " + time1 + "ms");
System.out.println("场景2(内部try-catch): " + time2 + "ms");
System.out.println("场景3(外部try-catch): " + time3 + "ms");
System.out.println("场景4(频繁异常): " + time4 + "ms");
}
// 场景1:无任何异常处理
public static void scenario1() {
int sum = 0;
for (int i = 0; i < TEST_ITERATIONS; i++) {
sum += i * 2;
}
}
// 场景2:循环内部有try-catch,但无异常
public static void scenario2() {
int sum = 0;
for (int i = 0; i < TEST_ITERATIONS; i++) {
try {
sum += i * 2;
} catch (Exception e) {
// 不会执行
}
}
}
// 场景3:循环外部有try-catch
public static void scenario3() {
int sum = 0;
try {
for (int i = 0; i < TEST_ITERATIONS; i++) {
sum += i * 2;
}
} catch (Exception e) {
// 不会执行
}
}
// 场景4:频繁抛出和捕获异常
public static void scenario4() {
int sum = 0;
for (int i = 0; i < TEST_ITERATIONS / 100; i++) {
try {
if (i % 10 == 0) {
throw new RuntimeException("test");
}
sum += i * 2;
} catch (Exception e) {
// 捕获处理
}
}
}
private static long measureTime(Runnable task) {
long start = System.nanoTime();
task.run();
return (System.nanoTime() - start) / 1000000;
}
}6.2 性能影响总结
根据测试结果,我们可以总结出以下规律:
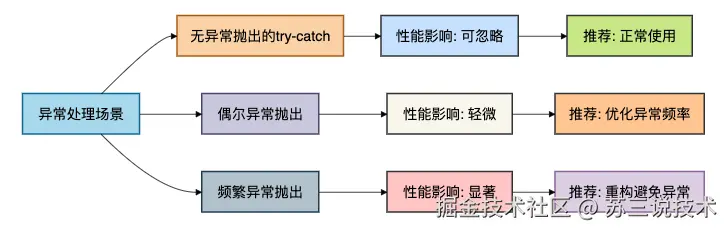
7. 最佳实践
基于以上分析,我总结了一些现代Java开发中的异常处理最佳实践:
7.1 代码可读性优先
java
public class ReadableExceptionHandling {
// 好的做法:清晰的错误处理
public void processFile(String filename) {
try {
String content = readFile(filename);
processContent(content);
} catch (IOException e) {
// 集中处理IO异常
logger.error("文件处理失败: " + filename, e);
throw new BusinessException("文件处理失败", e);
}
}
// 不好的做法:过度优化导致代码难以理解
public void processFileOverOptimized(String filename) {
// 为了性能把所有的检查都放在前面,代码逻辑分散
if (filename == null) {
throw new IllegalArgumentException("文件名不能为空");
}
if (!Files.exists(Paths.get(filename))) {
throw new BusinessException("文件不存在");
}
// ... 更多检查
// 真正的处理逻辑被淹没在检查中
}
}7.2 分层异常处理
在架构层面,我们应该在不同层次采用不同的异常处理策略:
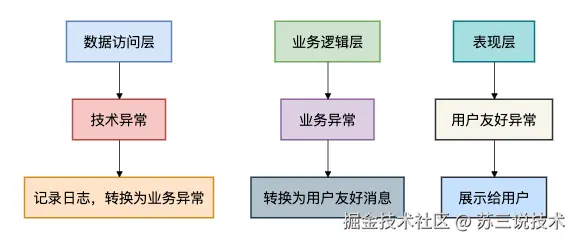
7.3 监控和告警
对于生产环境,我们需要建立完善的异常监控:
java
public class ExceptionMonitoring {
private final Metrics metrics;
public void handleBusinessOperation() {
long start = System.nanoTime();
try {
// 业务操作
doBusinessOperation();
metrics.recordSuccess("business_operation", System.nanoTime() - start);
} catch (BusinessException e) {
// 预期的业务异常
metrics.recordBusinessError("business_operation", e.getClass().getSimpleName());
throw e;
} catch (Exception e) {
// 未预期的技术异常
metrics.recordSystemError("business_operation", e.getClass().getSimpleName());
logger.error("系统异常", e);
throw new SystemException("系统繁忙", e);
}
}
}总结
经过深入的分析和测试,我们现在可以回答标题的问题了:try...catch真的影响性能吗?
核心结论
-
正常执行路径下,try-catch几乎无性能影响
- 现代JVM对异常处理做了大量优化
- 单纯的try块包装不会带来明显性能损失
-
真正的性能杀手是异常的创建和抛出
- 填充栈轨迹信息成本较高
- 异常对象创建需要开销
-
代码可读性比微小的性能优化更重要
- 在大多数业务场景中,异常处理的性能影响可以忽略
- 清晰的错误处理比微优化更有价值
我的建议
有些小伙伴在工作中可能会过度担心性能问题,我的建议是:
放心使用try-catch:
- 在需要的地方正常使用异常处理
- 不要因为性能担忧而牺牲代码质量
- 优先保证代码的可读性和可维护性
关注真正的影响点:
- 避免在性能关键路径中频繁抛出异常
- 使用条件检查替代预期的错误情况
- 对不可预期的异常使用try-catch
性能优化原则:
- 先写清晰的代码,再根据 profiling 结果优化
- 异常处理的性能影响通常不是瓶颈
- 真正的性能问题往往在其他地方(如IO、算法复杂度等)
记住,可维护的代码比微优化的代码更有价值。
在现代Java开发中,大胆使用try-catch来编写健壮、清晰的代码吧!
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。