文章目录
- 选用sklearn的原因
-
-
- 数据的"长相"决定了工具的选择
- [算法原理的冲突:离散 vs 连续](#算法原理的冲突:离散 vs 连续)
-
- sklearn实现
-
- 数据处理
- 继续优化
-
- 什么是特征工程?
- 针对银行营销数据的特征工程策略
-
- [1. 处理 `pdays` (上次联系天数) ------ 解决"魔法数字"](#1. 处理
pdays(上次联系天数) —— 解决“魔法数字”) - [2. 年龄分箱 (Binning) ------ 解决"非线性"](#2. 年龄分箱 (Binning) —— 解决“非线性”)
- [3. 交互特征 (Interaction) ------ 解决"关联性"](#3. 交互特征 (Interaction) —— 解决“关联性”)
- [1. 处理 `pdays` (上次联系天数) ------ 解决"魔法数字"](#1. 处理
- [1. 特征工程层面 (Feature Engineering) ------ 最核心的提升](#1. 特征工程层面 (Feature Engineering) —— 最核心的提升)
- [2. 模型策略层面 (Model Strategy) ------ 针对短板](#2. 模型策略层面 (Model Strategy) —— 针对短板)
- [3. 工程与评估层面 (Engineering & Workflow) ------ 确保结果可靠](#3. 工程与评估层面 (Engineering & Workflow) —— 确保结果可靠)
- 进一步优化
-
- [1. 对数变换 (Log Transform) ------ 解决"长尾分布"](#1. 对数变换 (Log Transform) —— 解决“长尾分布”)
- [2. 多项式特征 (Polynomial Features) ------ 暴力生成"交互"](#2. 多项式特征 (Polynomial Features) —— 暴力生成“交互”)
- [3. 目标编码 (Target Encoding) ------ 处理高维类别](#3. 目标编码 (Target Encoding) —— 处理高维类别)
- [4. 网格搜索 (Grid Search) ------ 穷举最佳参数](#4. 网格搜索 (Grid Search) —— 穷举最佳参数)
- [1. 核心原因:优化器的降维打击 (L-BFGS vs Adam)](#1. 核心原因:优化器的降维打击 (L-BFGS vs Adam))
- 冲突点
- [2. 特征工程:过犹不及 (Overfitting)](#2. 特征工程:过犹不及 (Overfitting))
- [3. 预处理:画蛇添足](#3. 预处理:画蛇添足)
- 知识补充
-
- 正则化
-
- [为什么 L2 正则能防止过拟合?](#为什么 L2 正则能防止过拟合?)
-
- [✨ 原因:让模型不敢把某个特征的系数学得太大](#✨ 原因:让模型不敢把某个特征的系数学得太大)
- 凸优化问题和非凸优化问题
-
- [A. 为什么 Sklearn 的 `lbfgs` 求解器那么强?](#A. 为什么 Sklearn 的
lbfgs求解器那么强?) - [B. 为什么 PyTorch 的 `Adam` 跑逻辑回归反而效果一般?](#B. 为什么 PyTorch 的
Adam跑逻辑回归反而效果一般?)
- [A. 为什么 Sklearn 的 `lbfgs` 求解器那么强?](#A. 为什么 Sklearn 的
- 遇到的问题
-
- **数据进行特征工程后,原先的列应该保存还是去除**
- [情况 1:分箱特征 (Binning) ------ 比如 `age` vs `age_bin`](#情况 1:分箱特征 (Binning) —— 比如
agevsage_bin) - [情况 2:组合特征 (Interaction) ------ 比如 `debt_level` vs `housing` / `loan`](#情况 2:组合特征 (Interaction) —— 比如
debt_levelvshousing/loan) - [情况 3:提取特征 (Extraction) ------ 比如 `was_contacted` vs `pdays`](#情况 3:提取特征 (Extraction) —— 比如
was_contactedvspdays)
- 类定义还在内存缓存中
kaggle地址:https://www.kaggle.com/competitions/playground-series-s5e8
选用sklearn的原因
数据的"长相"决定了工具的选择
非结构化数据(Unstructured Data) -> PyTorch/TensorFlow 的主场
- 比如:图片、音频、文本(自然语言)。
- 特点:特征之间有极强的空间或时间相关性(比如像素点组成了边缘,边缘组成了猫耳朵)。
- PyTorch 的强项:深度神经网络(CNN, Transformer)擅长从这些模糊的数据中提取高阶特征。
结构化数据(Structured/Tabular Data) -> Sklearn/GBDT 的主场
- 比如:你的这个银行数据集(年龄、职业、余额、是否有房贷)。
- 特点:每一列的物理意义完全不同,特征之间没有像像素那样明显的空间关系。"年龄"和"余额"放在一起,不需要卷积,而是需要逻辑判断。
- 树模型的强项:决策树天然适合处理这种"异质"数据。
算法原理的冲突:离散 vs 连续
PyTorch 的核心是"梯度下降" (Gradient Descent):
- 它要求每一个操作都是可导的(光滑的)。
- 神经网络是通过微调权重(比如把 0.5 变成 0.5001)来慢慢逼近结果。
决策树/随机森林的核心是"硬切分" (Hard Split):
- 逻辑是:
如果 年龄 > 30,走左边;否则,走右边。 - 这是一个阶跃函数(Step Function)。在数学上,这个操作在切分点不可导(导数为无穷大或无定义),在其他地方导数为 0。
- 结论 :因为没法求导,所以 PyTorch 最强大的"自动反向传播"机制对标准决策树完全失效。虽然有"神经决策树"这种变体,但效果通常不如传统的树模型。
sklearn实现
数据处理
panda读取
train_df = pd.read_csv('../data/train.csv')将数值列和字符列分开
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns数值列处理:中位数填充缺失值 + 标准化
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])类别列处理:unknown填充缺失值 + One-Hot编码 (遇到新类别忽略)
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='unknown')), # 保持 unknown 为一类
('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False))
])构建处理管道
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# --- 3. 定义逻辑回归模型 ---
# max_iter=2000 保证有足够时间收敛,C=1.0 是正则化强度默认值
model = LogisticRegression(max_iter=2000, random_state=42, C=1.0, solver='lbfgs')
# --- 4. 构建最终管道 ---
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', model)])12折交叉验证及计算roc-auc
# 实例化切分器
cv = StratifiedKFold(n_splits=12, shuffle=True, random_state=42)
# 计算 AUC
scores = cross_val_score(clf, X, y, cv=cv, scoring='roc_auc', n_jobs=-1)保存模型
# --- 7. 在全部训练数据上训练最终模型 ---
print("\n训练最终模型...")
clf.fit(X, y)
print("模型训练完成!")
# --- 8. 保存模型 ---
model_path = 'logistic_regression_model.pkl'
joblib.dump(clf, model_path)
print(f"\n模型已保存到: {model_path}")初步实现完整代码
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
import pandas as pd
import joblib # 用于保存模型
# 读取训练集数据
# 注意:这里的路径 '../data/train.csv' 需要根据你实际文件的位置修改
train_df = pd.read_csv('../data/train.csv')
# --- 1. 准备数据 ---
X = train_df.drop(columns=['id', 'y'])
y = train_df['y']
# --- 2. 定义预处理逻辑 ---
# 自动识别列类型
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
# 数值列处理:中位数填充缺失值 + 标准化
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
# 类别列处理:unknown填充缺失值 + One-Hot编码 (遇到新类别忽略)
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='unknown')), # 保持 unknown 为一类
('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False))
])
# 组合起来
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# --- 3. 定义逻辑回归模型 ---
# max_iter=2000 保证有足够时间收敛,C=1.0 是正则化强度默认值
model = LogisticRegression(max_iter=2000, random_state=42, C=1.0, solver='lbfgs')
# --- 4. 构建最终管道 ---
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', model)])
# --- 5. 执行 12折交叉验证 ---
print("开始执行 12-Fold Cross Validation (这可能需要几秒钟)...")
# 实例化切分器
cv = StratifiedKFold(n_splits=12, shuffle=True, random_state=42)
# 计算 AUC
scores = cross_val_score(clf, X, y, cv=cv, scoring='roc_auc', n_jobs=-1)
# --- 6. 输出结果 ---
print(f"\n每折的 AUC 分数:\n{scores}")
print(f"\n>>> 平均 AUC: {scores.mean():.5f} (标准差: {scores.std():.5f})")
# --- 7. 在全部训练数据上训练最终模型 ---
print("\n训练最终模型...")
clf.fit(X, y)
print("模型训练完成!")
# --- 8. 保存模型 ---
model_path = 'logistic_regression_model.pkl'
joblib.dump(clf, model_path)
print(f"\n模型已保存到: {model_path}")继续优化
什么是特征工程?
如果把机器学习比作做饭:
- 数据 (Data) = 原始食材(带泥的土豆、整只鸡)。
- 模型 (Model) = 烹饪设备(电饭煲、烤箱)。
- 特征工程 (Feature Engineering) = 备菜(洗净、切块、腌制、搭配)。
为什么逻辑回归特别需要特征工程? 因为逻辑回归(LR)是一个"线性模型",它的思维非常简单、直白。
- 它只能理解:"年龄越大,存款概率越高"这种直线关系。
- 它理解不了:"30-50岁的人存款概率高,但60岁以上反而变低了"(这是曲线)。
- 它理解不了:"有房贷"且"失业"的人风险极高(这是交互关系)。
特征工程就是把这些复杂的逻辑,手动算好,喂给逻辑回归吃。
针对银行营销数据的特征工程策略
为了把 AUC 从 0.74 往上提,我们需要针对这个数据集做以下 3 个具体的"手术":
1. 处理 pdays (上次联系天数) ------ 解决"魔法数字"
- 问题 :数据里
pdays= -1 表示"以前从未联系过"。但在数学上,-1 是一个很小的数字,模型会以为 -1 比 100 小很多。这完全误导了逻辑回归!其实 -1 代表的是一种"状态",而不是"天数"。 - 对策 :新增一列
was_contacted(是否曾联系过)。如果 pdays = -1,则是 0;否则是 1。
2. 年龄分箱 (Binning) ------ 解决"非线性"
- 问题:逻辑回归认为 60 岁的影响力是 30 岁的 2 倍,这不科学。通常刚工作的年轻人和退休老人没钱,中年人有钱。
- 对策 :把
age切成几段:[0-30, 30-40, 40-50, 50-60, 60+]。把连续数字变成类别,逻辑回归就能对每一段年龄赋予不同的权重了。
3. 交互特征 (Interaction) ------ 解决"关联性"
- 问题 :单看
housing(有房贷) 可能影响不大,单看loan(有个人贷款) 也还好。但如果一个人同时有房贷和个人贷款,他的经济压力可能爆表,几乎不可能存钱。 - 对策 :创造一个新特征
total_debt=housing+loan。
优化代码
import pandas as pd
import numpy as np
import joblib # 核心库:用于保存和加载模型
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, StandardScaler, KBinsDiscretizer
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
# 1. 读取数据
# 请确保路径正确
train_df = pd.read_csv('../data/train.csv')
# ==========================================
# 函数:特征工程 (Feature Engineering)
# 注意:这个函数以后对 test.csv 也要用!
# ==========================================
def feature_engineering(df):
df_eng = df.copy()
# 1. 处理 pdays (-1 代表从未联系)
df_eng['was_contacted'] = (df_eng['pdays'] != -1).astype(int)
# 2. 交互特征: 总负债状况
housing_num = df_eng['housing'].map({'yes': 1, 'no': 0, 'unknown': 0})
loan_num = df_eng['loan'].map({'yes': 1, 'no': 0, 'unknown': 0})
df_eng['debt_level'] = housing_num + loan_num
return df_eng
# 对训练集应用特征工程
print("正在进行特征工程...")
train_df_eng = feature_engineering(train_df)
# ==========================================
# 准备数据 X 和 y
# ==========================================
X = train_df_eng.drop(columns=['id', 'y'])
y = train_df_eng['y']
# 定义列名 (根据特征工程后的新列调整)
numeric_features = ['age', 'balance', 'day', 'duration', 'campaign', 'pdays', 'previous', 'debt_level', 'was_contacted']
categorical_features = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome']
# ==========================================
# 构建 Pipeline
# ==========================================
# 数值处理
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
# 年龄分箱 (把年龄变成类别,捕捉非线性)
age_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('binning', KBinsDiscretizer(n_bins=10, encode='onehot', strategy='quantile'))
])
# 类别处理
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='unknown')),
('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False))
])
# 组合处理器
preprocessor = ColumnTransformer(
transformers=[
('age_bin', age_transformer, ['age']), # 单独处理 age
('num', numeric_transformer, [c for c in numeric_features if c != 'age']), # 其他数值
('cat', categorical_transformer, categorical_features) # 类别
])
# 定义逻辑回归模型 (带 class_weight='balanced')
model = LogisticRegression(
max_iter=3000,
C=0.1,
solver='lbfgs',
class_weight='balanced', # 关键参数
random_state=42
)
# 最终管道
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', model)])
# ==========================================
# 步骤 1: 交叉验证 (评估模型好坏)
# ==========================================
print("正在执行 12-Fold Cross Validation 评估...")
cv = StratifiedKFold(n_splits=12, shuffle=True, random_state=42)
scores = cross_val_score(clf, X, y, cv=cv, scoring='roc_auc', n_jobs=-1)
print(f"每折 AUC: {scores}")
print(f">>> 平均 AUC: {scores.mean():.5f} (标准差: {scores.std():.5f})")
# ==========================================
# 步骤 2: 全量训练 (生成最终模型)
# ==========================================
print("\n正在使用所有训练数据训练最终模型...")
clf.fit(X, y)
print("模型训练完成!")
# ==========================================
# 步骤 3: 保存模型
# ==========================================
model_filename = 'logistic_regression_optimized.pkl'
joblib.dump(clf, model_filename)
print(f"模型已成功保存为: {model_filename}")
# ==========================================
# 附加步骤: 演示如何读取模型并生成提交文件
# ==========================================
print("\n--- 模拟预测 Test 集流程 ---")
# 1. 读取 Test 数据
test_df = pd.read_csv('../data/test.csv')
# 2. 重要!必须对 Test 集做同样的特征工程
test_df_eng = feature_engineering(test_df)
# 3. 加载模型 (其实可以直接用上面的 clf,这里为了演示加载流程)
loaded_model = joblib.load(model_filename)
# 4. 预测概率 (注意用 predict_proba 获取概率,取第2列即为正类概率)
# 不需要再手动调预处理,loaded_model 里的 pipeline 会自动处理
test_pred_prob = loaded_model.predict_proba(test_df_eng)[:, 1]
# 5. 生成提交 DataFrame
submission = pd.DataFrame({
'id': test_df['id'],
'y': test_pred_prob
})
print("预测完成,前 5 行预览:")
print(submission.head())
submission.to_csv('submission2.csv', index=False)这里注意一个细节,gemini不提醒还真想不到,kaggle要的其实不是0或者1的分类,而是预测的概率值,所以其实输出概率提交分数反而会更高,不信的话可以验证一下,只需要改几行代码即可
# 修改为 predict,直接输出类别
test_pred_labels = model.predict(test_df_eng)
submission_binary = pd.DataFrame({
'id': test_df['id'],
'y': test_pred_labels
})
submission_binary.to_csv('submission_binary.csv', index=False)到这一步准确率其实就已经很高了,我们梳理一下做了哪些优化
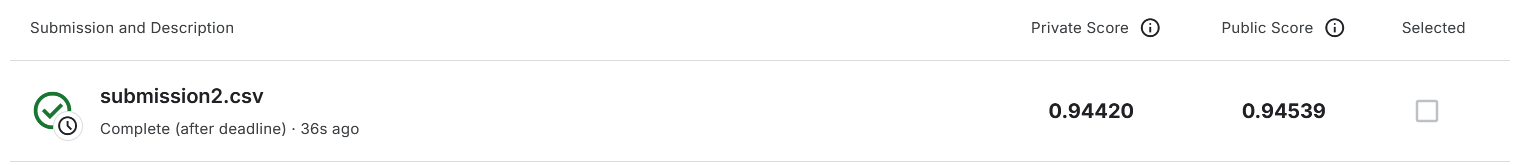
1. 特征工程层面 (Feature Engineering) ------ 最核心的提升
逻辑回归太"耿直",不懂弯弯绕绕,我们通过手动构造特征帮它"理解"数据:
- 修复逻辑漏洞 (
pdays) :- 优化前 :
-1被当作数值处理,模型认为它比0小,这在业务上是错的。 - 优化后 :新增
was_contacted(是否联系过),把-1的特殊含义剥离出来变成布尔值。
- 优化前 :
- 捕捉非线性关系 (Age Binning) :
- 优化前:逻辑回归认为年龄越大越好(或越差),是直线关系。
- 优化后 :使用
KBinsDiscretizer将年龄分箱(如 20-30岁一档,30-40岁一档)。这让线性模型也能拟合出"U型"或"倒U型"的复杂曲线(例如:年轻人和老人没钱,中年人有钱)。
- 构建交互特征 (
debt_level) :- 优化前 :房贷 (
housing) 和个贷 (loan) 各自独立。 - 优化后:将两者相加生成"总负债等级"。这帮模型捕捉到了"多重负债导致存款意愿极低"的组合效应。
- 优化前 :房贷 (
2. 模型策略层面 (Model Strategy) ------ 针对短板
针对逻辑回归的数学特性和数据的分布特性做了调整:
- 对抗类别不平衡 (
class_weight='balanced') :- 原因:银行营销数据中,只有少数人会存款(正样本少)。普通模型会倾向于预测"不存款"来混高准确率。
- 优化:强制模型给"正样本"更高的权重,宁可错杀(误报),不可放过(漏报),这直接提升了 AUC。
- 强制数值归一化 (
StandardScaler) :- 原因 :
balance(余额)的数值很大(几千几万),age很小(几十)。如果不处理,逻辑回归会完全被余额主导,忽略年龄。 - 优化:将所有数值拉回同一个起跑线(均值0,方差1),让所有特征公平竞争。
- 原因 :
- 加强正则化 (
C=0.1) :- 原因:我们做 One-Hot 和分箱后,特征维度变多了,容易过拟合。
- 优化 :降低
C值(增强惩罚力度),让模型参数更保守,泛化能力更强。
3. 工程与评估层面 (Engineering & Workflow) ------ 确保结果可靠
- 12折交叉验证 (12-Fold CV) :
- 不再依赖单一的随机划分,而是用 12 轮测试的平均分来评估,确保你的分数不是"运气好"碰上的。
- Pipeline 管道封装 :
- 将"填充缺失值 -> 归一化 -> 分箱 -> 训练"封装成一个整体。这确保了预测 Test 集时,使用的是和训练集完全一致的数据处理标准(防止数据泄露)。
- 全量训练与保存 (Fit All & Save) :
- 明确了交叉验证只是为了"体检",真正提交时,必须用所有数据重新
fit一次,并用joblib保存模型,完成了从实验到落地的闭环。
- 明确了交叉验证只是为了"体检",真正提交时,必须用所有数据重新
- 纠正提交格式 (
predict_proba) :- 明确了竞赛提交的是概率值而非类别(0/1),这是获得高 AUC 分数的关键一步。
进一步优化
尽管现在准确率已经很高了,但是有没有可能再进一步做优化呢
只能说ai还是太好用了,这是他给出的几个提升思路
1. 对数变换 (Log Transform) ------ 解决"长尾分布"
- 痛点 :逻辑回归喜欢"正态分布"的数据。但银行数据里的
balance(余额)、duration(通话时长)、campaign(联系次数)通常是严重的长尾分布(大部分人没钱,极少数人巨有钱)。 - 后果:巨有钱的那几个人的数据点会把 LR 的回归线强行拉偏,导致对普通人的预测不准。
- 方案 :对这些列取对数 (
log1p)。这能把"贫富差距"拉平,让数据看起来更像正态分布。
2. 多项式特征 (Polynomial Features) ------ 暴力生成"交互"
- 痛点 :我们之前手动做了
debt_level = housing + loan。但这只是加法。也许age * balance(年龄大且有钱)或者campaign^2(联系次数的平方,代表过度骚扰)更有用? - 方案 :使用 sklearn 的
PolynomialFeatures。它会自动帮你生成 x2, x3, x1⋅x2 等所有组合。这是增强 LR 非线性能力最暴力的手段。
3. 目标编码 (Target Encoding) ------ 处理高维类别
- 痛点 :
job有十几个职业,month有 12 个月。One-Hot 编码会产生几十列稀疏矩阵。 - 方案 :目标编码 。
- 例如:计算"学生"存钱的概率是 0.3,"蓝领"是 0.1。
- 直接把
job这一列的 "student" 替换成 0.3,"blue-collar" 替换成 0.1。 - 这样把类别变成了数字,逻辑回归非常喜欢这种直接强相关的特征。(注:Sklearn 1.3+ 版本原生支持
TargetEncoder,非常方便)。
4. 网格搜索 (Grid Search) ------ 穷举最佳参数
- 痛点 :我们之前随便设了
C=0.1。也许C=0.05或者C=0.2更好? - 方案:让电脑自动跑几百组参数,找出验证集分数最高的那一组。
先给cpu上的完整代码,后续需要将训练放到gpu上,网格搜索计算量还是大的,而sklearn的逻辑回归本身又不支持gpu,所以需要改改代码
import pandas as pd
import numpy as np
import joblib
from sklearn.model_selection import StratifiedKFold, GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, StandardScaler, KBinsDiscretizer, PolynomialFeatures, FunctionTransformer, PowerTransformer
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
# 1. 读取数据
train_df = pd.read_csv('../data/train.csv')
test_df = pd.read_csv('../data/test.csv')
# ==========================================
# 特征工程函数 (基础版)
# ==========================================
def feature_engineering(df):
df_eng = df.copy()
# 基础交互
df_eng['was_contacted'] = (df_eng['pdays'] != -1).astype(int)
# 简单的加法交互依然保留
housing_num = df_eng['housing'].map({'yes': 1, 'no': 0, 'unknown': 0})
loan_num = df_eng['loan'].map({'yes': 1, 'no': 0, 'unknown': 0})
df_eng['debt_level'] = housing_num + loan_num
# 将 duration 这种长尾数据,先做个 log 处理防止数值过大
# log1p = log(x + 1),避免 0 报错
df_eng['duration_log'] = np.log1p(df_eng['duration'])
return df_eng
# 应用特征工程
train_df_eng = feature_engineering(train_df)
test_df_eng = feature_engineering(test_df)
X = train_df_eng.drop(columns=['id', 'y'])
y = train_df_eng['y']
# ==========================================
# 定义更高级的 Pipeline
# ==========================================
# 1. 偏态数据处理 (Balance, Duration, Campaign)
# 使用 PowerTransformer (Yeo-Johnson) 自动把偏态数据变成正态分布
skewed_features = ['balance', 'duration', 'campaign', 'previous']
skewed_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('power', PowerTransformer(method='yeo-johnson')) # 比 Log 更强大,支持负数
])
# 2. 生成多项式特征 (Polynomial)
# 我们只对关键数值做多项式,防止维度爆炸
poly_features = ['day', 'pdays', 'age']
poly_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler()),
# degree=2 表示生成 x^2 和 x*y。interaction_only=False 表示保留 x^2
('poly', PolynomialFeatures(degree=2, include_bias=False))
])
# 3. 年龄分箱 (依然保留)
age_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('binning', KBinsDiscretizer(n_bins=10, encode='onehot', strategy='quantile'))
])
# 4. 类别处理
categorical_features = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome']
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='unknown')),
('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False))
])
# 5. 组合所有处理器
preprocessor = ColumnTransformer(
transformers=[
('skewed', skewed_transformer, skewed_features),
('poly', poly_transformer, poly_features),
('age_bin', age_transformer, ['age']),
('cat', categorical_transformer, categorical_features),
# 剩下的列 (如 debt_level, was_contacted) 简单过一下归一化
('rest', StandardScaler(), ['debt_level', 'was_contacted'])
])
# ==========================================
# 网格搜索 (Grid Search) 寻找最佳超参数
# ==========================================
pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(max_iter=5000, solver='saga', random_state=42))])
# 定义要搜索的参数空间
# C: 正则化强度,越小越强。我们试几个数量级
# l1_ratio: 仅当 penalty='elasticnet' 时有效,控制 L1 和 L2 的比例
param_grid = {
'classifier__C': [0.001, 0.01, 0.1, 1, 10],
'classifier__class_weight': ['balanced', None],
# 这里的 penalty 选择 'l2' (岭回归) 或 'l1' (Lasso, 能筛选特征)
'classifier__penalty': ['l1', 'l2']
}
print("开始 Grid Search (这可能需要几分钟)...")
# cv=5: 这里用 5 折是为了快一点,最后可以用 12 折验证
grid_search = GridSearchCV(pipeline, param_grid, cv=5, scoring='roc_auc', n_jobs=-1, verbose=1)
grid_search.fit(X, y)
print(f"\n最佳参数: {grid_search.best_params_}")
print(f"最佳验证集 AUC: {grid_search.best_score_:.5f}")
# ==========================================
# 用最佳模型生成预测
# ==========================================
best_model = grid_search.best_estimator_
# 预测 Test 集
print("生成预测...")
test_pred_prob = best_model.predict_proba(test_df_eng)[:, 1]
# 保存
submission = pd.DataFrame({'id': test_df['id'], 'y': test_pred_prob})
submission.to_csv('submission3.csv', index=False)
print("submission3.csv 已生成!")看着一下子爆红给我慌得,还好顶住了
转到gpu上的代码
import pandas as pd
import numpy as np
import joblib
import contextlib
from tqdm import tqdm
from sklearn.model_selection import StratifiedKFold, GridSearchCV, ParameterGrid
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, StandardScaler, KBinsDiscretizer, PolynomialFeatures, FunctionTransformer, PowerTransformer
from sklearn.impute import SimpleImputer
import warnings
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted
from sklearn.utils.multiclass import unique_labels
# 忽略警告,保持输出清爽
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning)
# ==========================================
# 核心组件:自定义 GPU 逻辑回归
# ==========================================
class PyTorchLogReg(ClassifierMixin, BaseEstimator):
# 【关键修复】强制声明自己是分类器
_estimator_type = "classifier"
def __init__(self, C=1.0, penalty='l2', class_weight=None, max_iter=2000, lr=0.05, device=None):
self.C = C
self.penalty = penalty
self.class_weight = class_weight
self.max_iter = max_iter
self.lr = lr
self.device = device # 延迟到 fit 时处理
self.model = None
self.classes_ = None # 【关键修复】必须初始化
self.n_features_in_ = None
def fit(self, X, y):
# 0. 确定设备
if self.device is None:
fit_device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
else:
fit_device = self.device
# 1. Sklearn 标准检查
X, y = check_X_y(X, y, accept_sparse=False)
self.n_features_in_ = X.shape[1]
# 【关键修复】设置 classes_ 属性,防止报错
self.classes_ = unique_labels(y)
# 2. 处理 Class Weight
pos_weight = None
if self.class_weight == 'balanced':
num_neg = (y == 0).sum()
num_pos = (y == 1).sum()
if num_pos > 0:
weight_val = num_neg / num_pos
pos_weight = torch.tensor(weight_val, dtype=torch.float32).to(fit_device)
# 3. 数据转 Tensor (全量入显存)
X_t = torch.tensor(X, dtype=torch.float32).to(fit_device)
y_t = torch.tensor(y, dtype=torch.float32).unsqueeze(1).to(fit_device)
# 4. 定义模型
self.model = nn.Linear(self.n_features_in_, 1).to(fit_device)
# 5. Loss & Optimizer
criterion = nn.BCEWithLogitsLoss(pos_weight=pos_weight)
optimizer = optim.Adam(self.model.parameters(), lr=self.lr)
# 6. 训练循环
self.model.train()
for _ in range(self.max_iter):
optimizer.zero_grad()
outputs = self.model(X_t)
loss = criterion(outputs, y_t)
# 手动实现正则化
reg_loss = 0.0
if self.penalty == 'l2':
for param in self.model.parameters():
reg_loss += torch.sum(param ** 2)
loss = loss + (1 / (2 * self.C)) * reg_loss
elif self.penalty == 'l1':
for param in self.model.parameters():
reg_loss += torch.sum(torch.abs(param))
loss = loss + (1 / self.C) * reg_loss
loss.backward()
optimizer.step()
return self
def predict_proba(self, X):
check_is_fitted(self)
if self.device is None:
pred_device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
else:
pred_device = self.device
X = check_array(X, accept_sparse=False)
X_t = torch.tensor(X, dtype=torch.float32).to(pred_device)
self.model.eval()
with torch.no_grad():
logits = self.model(X_t)
prob_pos = torch.sigmoid(logits).cpu().numpy()
return np.hstack([1 - prob_pos, prob_pos])
def predict(self, X):
probs = self.predict_proba(X)
return (probs[:, 1] > 0.5).astype(int)
# ==========================================
# 辅助工具:进度条
# ==========================================
@contextlib.contextmanager
def tqdm_joblib(tqdm_object):
class TqdmBatchCompletionCallback(joblib.parallel.BatchCompletionCallBack):
def __call__(self, *args, **kwargs):
tqdm_object.update(n=self.batch_size)
return super().__call__(*args, **kwargs)
old_batch_callback = joblib.parallel.BatchCompletionCallBack
joblib.parallel.BatchCompletionCallBack = TqdmBatchCompletionCallback
try:
yield tqdm_object
finally:
joblib.parallel.BatchCompletionCallBack = old_batch_callback
tqdm_object.close()
# ==========================================
# 1. 读取数据
# ==========================================
print("📦 读取数据...")
# 请根据实际情况修改路径
train_df = pd.read_csv('./data/train.csv')
test_df = pd.read_csv('./data/test.csv')
# ==========================================
# 2. 特征工程 (Pandas)
# ==========================================
def feature_engineering(df):
df_eng = df.copy()
df_eng['was_contacted'] = (df_eng['pdays'] != -1).astype(int)
housing_num = df_eng['housing'].map({'yes': 1, 'no': 0, 'unknown': 0})
loan_num = df_eng['loan'].map({'yes': 1, 'no': 0, 'unknown': 0})
df_eng['debt_level'] = housing_num + loan_num
df_eng['duration_log'] = np.log1p(df_eng['duration'])
return df_eng
print("🛠️ 正在进行基础特征工程...")
train_df_eng = feature_engineering(train_df)
test_df_eng = feature_engineering(test_df)
X_raw = train_df_eng.drop(columns=['id', 'y'])
y = train_df_eng['y']
# ==========================================
# 3. 预处理 (Sklearn Pipeline) - 移至循环外
# ==========================================
print("⚙️ 正在进行 CPU 密集型预处理 (Yeo-Johnson & Polynomial)...")
print(" (这步只需做一次,大概 1-2 分钟,请耐心等待...)")
skewed_features = ['balance', 'duration', 'campaign', 'previous']
skewed_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('power', PowerTransformer(method='yeo-johnson'))
])
poly_features = ['day', 'pdays', 'age']
poly_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler()),
('poly', PolynomialFeatures(degree=2, include_bias=False))
])
age_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('binning', KBinsDiscretizer(
n_bins=10,
encode='onehot',
strategy='quantile',
quantile_method='averaged_inverted_cdf' # 【修复警告】
))
])
categorical_features = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome']
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='unknown')),
('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False))
])
preprocessor = ColumnTransformer(
transformers=[
('skewed', skewed_transformer, skewed_features),
('poly', poly_transformer, poly_features),
('age_bin', age_transformer, ['age']),
('cat', categorical_transformer, categorical_features),
('rest', StandardScaler(), ['debt_level', 'was_contacted'])
])
# 先 fit_transform 训练集
X_processed = preprocessor.fit_transform(X_raw)
# 再 transform 测试集
X_test_processed = preprocessor.transform(test_df_eng)
print(f"✅ 预处理完成!特征矩阵形状: {X_processed.shape}")
# ==========================================
# 4. Grid Search (GPU 版)
# ==========================================
# 这里的 Pipeline 只包含分类器,因为数据已经处理好了
pipeline = Pipeline(steps=[
('classifier', PyTorchLogReg(max_iter=3000, lr=0.05))
])
param_grid = {
'classifier__C': [0.001, 0.01, 0.1, 1, 10],
'classifier__class_weight': ['balanced', None],
'classifier__penalty': ['l1', 'l2']
}
n_candidates = len(list(ParameterGrid(param_grid)))
n_folds = 12
total_fits = n_candidates * n_folds
print(f"\n🚀 开始 Grid Search (纯 GPU 训练,总共 {total_fits} 次)...")
grid_search = GridSearchCV(pipeline, param_grid, cv=n_folds, scoring='roc_auc', n_jobs=-1, verbose=1)
with tqdm_joblib(tqdm(desc="Grid Search Progress", total=total_fits)) as progress_bar:
# 传入处理好的数据
grid_search.fit(X_processed, y)
print(f"\n🏆 最佳参数: {grid_search.best_params_}")
print(f"🏆 最佳验证集 AUC: {grid_search.best_score_:.5f}")
# ==========================================
# 5. 生成预测
# ==========================================
best_model = grid_search.best_estimator_
print("\n📝 生成预测文件...")
test_pred_prob = best_model.predict_proba(X_test_processed)[:, 1]
submission = pd.DataFrame({'id': test_df['id'], 'y': test_pred_prob})
submission.to_csv('submission_final_gpu.csv', index=False)
print("🎉 submission_final_gpu.csv 已生成!")但是这一版的成绩不太理想,只有0.93多一点,甚至不如提升之前的代码,继续分析一下
1. 核心原因:优化器的降维打击 (L-BFGS vs Adam)
- Sklearn (CPU) : 使用的是
solver='lbfgs'。这是二阶优化算法 (拟牛顿法)。对于逻辑回归这种凸优化问题 (Convex Problem),L-BFGS 能找到全局最优解,精度极高,几乎是数学上的完美解。 - PyTorch (GPU) : 你使用的是
Adam。这是一阶随机梯度下降。它在深度学习(非凸问题)中表现很好,但在这种简单的凸问题上,它很难像 L-BFGS 那样收敛到极致的精度。它往往在最优解附近震荡,导致 AUC 略微低一点点(比如 0.93 vs 0.94)。
冲突点
不是因为"转到了 GPU"所以才用 L1,而是因为我们引入了"多项式特征 (PolynomialFeatures)"所以必须用 L1。
L-BFGS 极其依赖函数的光滑性(可导)。
- L2 正则化:完美支持 (x2 可导)。
- L1 正则化 :不支持 (∣x∣ 在 0 点不可导)。
L1 (Lasso) 的魔力:
- L2 正则化 (Ridge) 只能把特征的权重变小(比如从 100 变成 0.001),但永远不会变成 0。意味着所有垃圾特征都还在起作用,只是声音变小了。
- L1 正则化 (Lasso) 有一个数学上的特性(几何上表现为菱形约束),它能把不重要的特征权重暴力压缩成 0。
- 结果 :L1 实际上在训练过程中自动帮你做了特征筛选 (Feature Selection)。它告诉模型:"把这 500 个没用的特征删掉,只保留那 20 个有用的。
2. 特征工程:过犹不及 (Overfitting)
- GPU 版 : 你加入了
PolynomialFeatures(degree=2)。这会生成大量的交互特征(比如age * day,pdays^2)。虽然增加了非线性能力,但也引入了巨大的噪音 和过拟合风险。对于逻辑回归这种简单模型,特征太多反而会导致泛化能力下降。 - CPU 版 : 只用了
KBinsDiscretizer(分箱)。这是处理非线性最稳健、最不容易过拟合的方法。
3. 预处理:画蛇添足
PowerTransformer(Yeo-Johnson) 理论上能让数据更正态,但在树模型或逻辑回归中,简单的StandardScaler往往已经足够。复杂的变换有时候反而破坏了数据原有的分布规律。
知识补充
正则化
正则化 = 让模型更简单,避免过拟合。
L2 正则 = 惩罚权重平方,让权重更小、模型更稳定。
C 越小 = 正则化越强 = 模型越不容易过拟合。
为什么 L2 正则能防止过拟合?
✨ 原因:让模型不敢把某个特征的系数学得太大
如果没有正则化:
- 模型可能会"特别相信某几个特征"
- 导致权重变得特别大
- 非常容易被噪声数据诱导 → 过拟合
凸优化问题和非凸优化问题
凸优化(逻辑回归):
- 想象一个光滑的大碗。
- 目标:你要找到碗底(损失最小点)。
- 特性 :无论你把弹珠(模型参数)扔在碗壁的哪个位置,只要它往下滚,最终它一定会停在同一个碗底。
- 结论 :只有一个全局最优解 (Global Optimum)。不存在"陷阱",你闭着眼睛往下走都能走到终点。
非凸优化(神经网络/深度学习):
- 想象一片喀斯特地貌的山区,有无数个山谷、山峰和坑洼。
- 特性:如果你把弹珠扔在不同的位置,它可能会掉进不同的山谷里(局部最优解,Local Optima)。有的山谷深(效果好),有的山谷浅(效果差)。
- 结论 :有无数个局部最优解。你很难找到真正的最低点(全局最优),通常只能找到一个"还不错"的点。
A. 为什么 Sklearn 的 lbfgs 求解器那么强?
- L-BFGS 是一种二阶优化算法(拟牛顿法)。它不仅看坡度(一阶导数),还看坡度的变化率(二阶导数/曲率)。
- 在凸问题 (碗)里,L-BFGS 就像开了"全图视野"的上帝。它能精确计算出碗底在哪里,然后几大步就直接跳过去了。
- 这就是为什么 CPU 版的 Sklearn 逻辑回归能跑到 0.94+ 的 AUC,而且速度极快。因为它是在解一个数学上有唯一完美解的问题。
B. 为什么 PyTorch 的 Adam 跑逻辑回归反而效果一般?
- Adam 是为非凸问题(神经网络)设计的"特种兵"。它的特长是爬山涉水、跳出局部陷阱、适应崎岖路面。
- 让 Adam 去走一个光滑的"大碗",它反而会因为步长调整过于敏感,在碗底附近震荡,很难像 L-BFGS 那样直接"钉"在最深处。
遇到的问题
数据进行特征工程后,原先的列应该保存还是去除
情况 1:分箱特征 (Binning) ------ 比如 age vs age_bin
操作 :你把连续的 age (25, 30, 35...) 变成了离散的 age_bin (20-30区间, 30-40区间...)。
对于逻辑回归 (Linear Model):
- 建议 :通常只保留其中一个 (我之前的代码里是去掉了原始
age,只留了分箱后的)。 - 原因 :
- 如果你保留两者,会产生共线性 (Multicollinearity) 。因为
age和age_bin是高度相关的。逻辑回归不喜欢两个特征说同一件事,这会导致权重(系数)乱跳。 - 但在一种情况下可以保留两者:如果你认为"年龄"既有一个整体的线性趋势(年纪越大越有钱),又有局部的非线性波动(30岁是一个坎)。同时保留两者可以让模型学习"整体趋势 + 局部修正"。
- 如果你保留两者,会产生共线性 (Multicollinearity) 。因为
对于树模型 (XGBoost/LightGBM):
- 建议 :保留两者 。树模型非常聪明,它会自己在
age和age_bin之间选一个更好用的切分点。
情况 2:组合特征 (Interaction) ------ 比如 debt_level vs housing / loan
- 操作 :
debt_level=housing+loan。 - 对于逻辑回归 :
- 建议 :全部保留。
- 原因 :
housing代表"房贷类型",loan代表"个贷类型"。debt_level代表"负债总强度"。- 这三个特征虽然数学上相关,但在业务含义上是不同的维度。
- 逻辑回归有 正则化 (Regularization, 参数 C) 。如果
debt_level和housing功能重复了,L2 正则化会自动把其中一个不重要的特征权重压低。所以,把它们都扔进去,让算法自己去挑是更稳妥的策略。
情况 3:提取特征 (Extraction) ------ 比如 was_contacted vs pdays
- 操作 :从
pdays里提取出了was_contacted。 - 对于逻辑回归 :
- 建议 :全部保留,但要小心原始列。
- 原因 :
was_contacted解决了"有没有联系"的问题。pdays解决了"联系了多久"的问题。- 它们互为补充。但是! 原始的
pdays里含有-1这个魔法数字,这对逻辑回归是有毒的。
- 最佳做法 :
- 生成
was_contacted。 - 清洗
pdays:把-1变成一个很大的数字(比如 999)或者变成 0(根据业务理解),或者直接把-1的那些行在pdays列里设为平均值。 - 然后把两个都扔进模型。
- 生成
类定义还在内存缓存中
当你修改了代码(比如给类加上了 _estimator_type = "classifier"),你实际上是制造了一个新的模具。
但在 Python 的复杂运行环境(特别是涉及多进程并行时)中,发生了以下情况:
- 旧模具的残留:你的主程序(Main Process)虽然更新了代码,加载了"新模具",但在内存的某个角落(或者并行任务的序列化缓存里),还存着"旧模具"的副本。
- 并行任务的"时空穿越" :当你调用
GridSearchCV并开启n_jobs=-1时,Sklearn 会启动多个子进程(Worker Processes)。 - Pickle 的锅 :主进程需要把你的模型(模具)打包(序列化/Pickle)发送给子进程。
- 如果 Python 的序列化机制(Pickle)在这个过程中,错误地引用了旧的类定义。
- 或者子进程在导入你的脚本时,由于某种原因(如
.pyc字节码缓存)加载了旧的逻辑。
- 结果 :子进程拿到的是"旧模具"。它一检查:"咦?这个模具没有
_estimator_type标记啊?" 于是判定它为回归器,随后报错。
这是 Scikit-learn 的身份查验机制。
- Sklearn 的逻辑 :GridSearchCV 要计算 AUC (
roc_auc),它必须调用predict_proba()。 - 安检口 :在调用前,Sklearn 会检查
is_classifier(estimator)。 - 检查标准 :它会查看对象是否有
_estimator_type属性,且值为"classifier"。 - 你的代码 :
- 你虽然继承了
ClassifierMixin,但因为这是自定义类,且涉及多进程传输。 - 在传输过程中,这个继承关系可能丢失了,或者属性没传过去。
- Sklearn 一看:"没身份证?那你就是回归器(Regressor)。"
- 你虽然继承了
- 崩溃 :Sklearn 试图对一个"回归器"调用
predict_proba(这是分类器才有的方法),于是报错。
解决方案
改名 (GpuLogisticRegression -> PyTorchLogReg):
- 作用:避开内存缓存。
- 原理 :无论之前的环境里缓存了多少个
GpuLogisticRegression的旧版本,我现在叫PyTorchLogReg了。Python 必须重新分配内存、重新解析代码。这就像"换个马甲",让旧的缓存彻底失效。
调整继承顺序 (ClassifierMixin, BaseEstimator):
- 作用:强化身份识别。
- 原理 :Python 的 MRO(方法解析顺序)是从左到右的。把
ClassifierMixin放在第一位,能确保is_classifier检查时优先看到"我是分类器"的特征,防止被BaseEstimator的默认行为覆盖。