目录
[1.1 内核态 vs 用户态:本质是 "权限的边界"](#1.1 内核态 vs 用户态:本质是 “权限的边界”)
[二、关键问题:态的切换有多 "贵"?](#二、关键问题:态的切换有多 “贵”?)
[2.1 什么时候会触发态的切换?](#2.1 什么时候会触发态的切换?)
[三、传统文件传输:被 "态切换" 拖垮的性能](#三、传统文件传输:被 “态切换” 拖垮的性能)
[3.1 传统文件传输步骤](#3.1 传统文件传输步骤)
[3.2 步骤详解:](#3.2 步骤详解:)
[3.3 总结与问题所在](#3.3 总结与问题所在)
[4.1 核心思想](#4.1 核心思想)
[4.2 sendfile系统调用的魔力](#4.2 sendfile系统调用的魔力)
[4.3 零拷贝 vs 传统传输:性能差距一目了然](#4.3 零拷贝 vs 传统传输:性能差距一目了然)
每一次数据读写,都是一次穿越内核与用户空间的漫长旅行。而零拷贝技术,为我们开辟了一条高速公路。
前言:为什么你的应用程序不够快?
"为什么同样是做文件传输,我的应用程序传大文件就 CPU 飙升、响应超时,而 Nginx 能轻松扛住万级并发?Kafka 每秒处理百万条消息的底气又在哪?"
如果你曾被这类性能问题困扰,那答案或许藏在计算机最底层的设计逻辑里 ------内核态与用户态的权限隔离 ,以及由此衍生的零拷贝技术。这对看似抽象的概念,正是高性能服务器的 "隐形引擎"。
一、内核态与用户态:权限的鸿沟
现代操作系统的核心设计哲学是 "安全优先"。想象一下:如果你的浏览器能直接读写磁盘的系统文件,或者你的办公软件能随意修改内存中的进程数据,电脑崩溃只是早晚的事。
为了避免这种灾难,CPU 架构被设计成 "权限分级制",最核心的就是内核态(Kernel Mode) 与用户态(User Mode) 的划分。
1.1 内核态 vs 用户态:本质是 "权限的边界"
我们用一张通俗的对比表,拆解二者的核心差异:
| 特性 | 内核态(Kernel Mode) | 用户态(User Mode) |
|---|---|---|
| 别名 | 系统态、特权态(x86 架构的 Ring 0) | 普通态、非特权态(x86 架构的 Ring 3) |
| 权限级别 | 最高权限,"管理团队" 身份 | 低权限,"普通员工" 身份 |
| 核心能力 | 执行所有 CPU 指令,直接操作磁盘、网卡等硬件 | 仅执行受限指令,无法直接访问硬件 |
| 运行内容 | 内核核心逻辑(进程调度、内存管理、设备驱动) | 普通应用程序代码 |
| 内存访问 | 可访问全内存(内核空间 + 用户空间) | 仅能访问自己的用户空间内存 |
| 设计目的 | 保障系统安全稳定,防破坏 | 隔离应用,让其在 "沙箱" 中受控运行 |
一个简单的比喻:
-
内核态 好比是操作系统的 "核心管理团队",拥有公司的最高权限,可以进入任何房间(硬件),调用任何资源。
-
用户态 好比是 "普通员工" (应用程序),只能在自己的工位上工作,要调用公司资源(如打印文件、使用网络)必须向管理团队提交申请(系统调用)。
二、关键问题:态的切换有多 "贵"?
用户态的应用程序要完成 "读文件、发网络" 这类需要硬件参与的操作,必须通过系统调用 向内核 "求助",而这会触发上下文切换------CPU 从执行应用代码,切换到执行内核代码,完成后再切回应用。
这个切换过程,就是性能损耗的 "隐形杀手"。
2.1 什么时候会触发态的切换?
这种切换并非随意发生,通常由三类 "陷阱(Trap)" 事件触发:
-
系统调用(最常见) :应用主动请求内核服务,比如
read()(读文件)、write()(写网络)、open()(打开文件)。 -
异常事件:应用执行非法操作,比如除以零、访问无效内存,内核需介入处理。
-
硬件中断:硬件完成任务后通知 CPU,比如磁盘读完数据后 "告诉" 内核 "可以拿数据了"。
其中,系统调用是文件传输场景中最频繁的切换触发源,而每一次切换都伴随着显著开销:CPU 要保存当前应用的执行状态(寄存器、程序计数器),加载内核状态,处理完后再反向恢复 ------ 这个过程看似短暂,但高并发场景下会被无限放大。
三、传统文件传输:被 "态切换" 拖垮的性能
3.1 传统文件传输步骤
我们结合"态"的切换,来完整分析一次传统文件传输 (使用 read 和 write 系统调用)的全过程。
应用程序调用read()读取文件
↓
上下文切换1:用户态→内核态
↓
DMA拷贝:磁盘→内核缓冲区(无需CPU)
↓
CPU拷贝:内核缓冲区→用户缓冲区(昂贵!)
↓
上下文切换2:内核态→用户态
↓
应用程序调用write()发送数据
↓
上下文切换3:用户态→内核态
↓
CPU拷贝:用户缓冲区→Socket缓冲区(昂贵!)
↓
DMA拷贝:Socket缓冲区→网卡(无需CPU)
↓
上下文切换4:内核态→用户态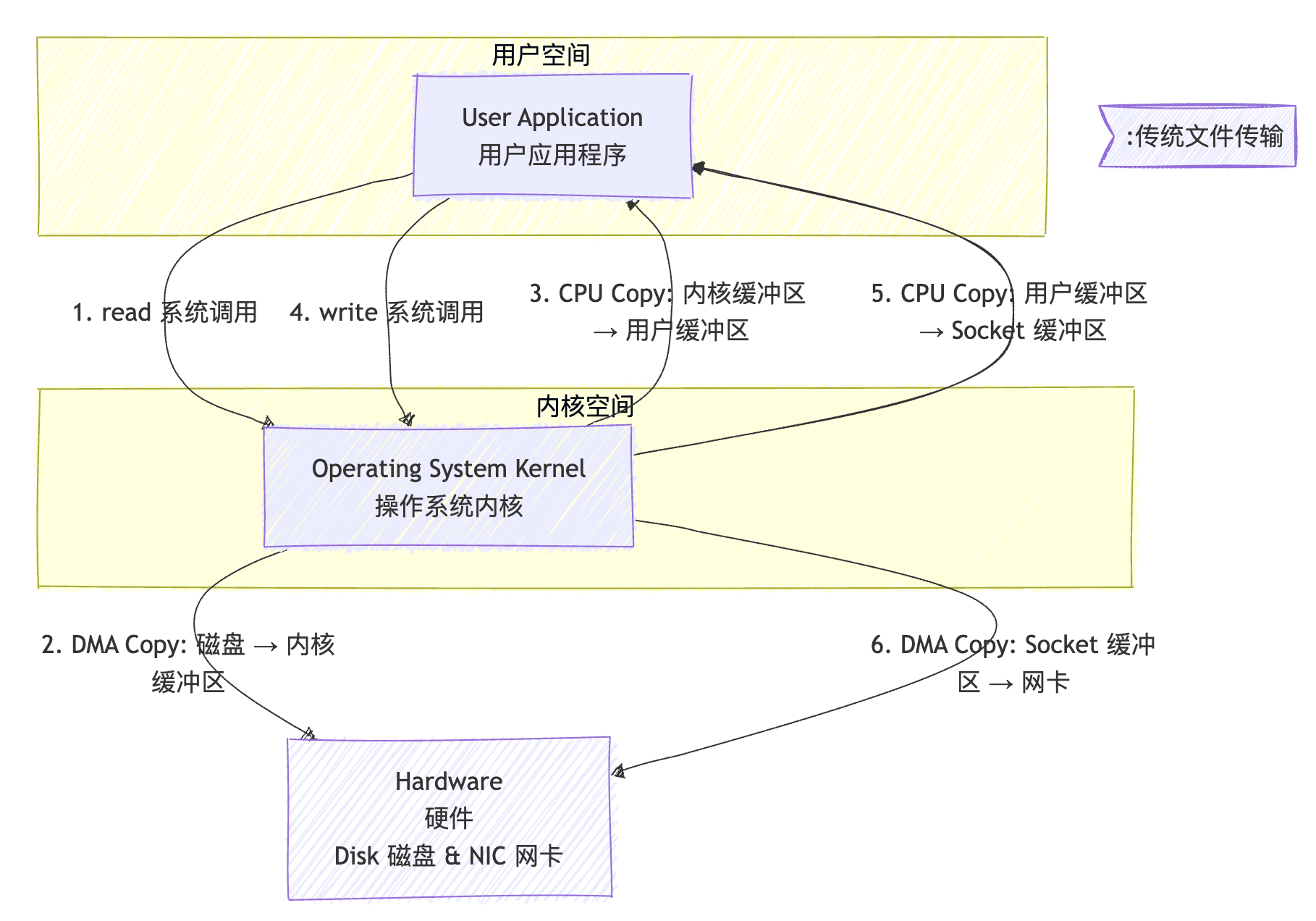 传统文件传输
传统文件传输
3.2 步骤详解:
- 系统调用 (
read) - 切换至内核态
(1)应用程序调用 read() 函数。这触发了一次系统调用。
(2)上下文切换 1 :CPU从用户态 切换到内核态 。内核开始执行 read 的系统调用处理代码。
2. DMA 拷贝(磁盘 → 内核缓冲区)
(1)内核向磁盘控制器发出指令。磁盘控制器使用 DMA 技术,将数据从磁盘直接拷贝 到内核的缓冲区(Page Cache)。此过程CPU无需参与拷贝,可以处理其他事务。
3. CPU 拷贝(内核缓冲区 → 用户缓冲区)- 切换回用户态
(1)内核将数据从自己的缓冲区通过CPU拷贝到应用程序在用户空间指定的内存地址(User Buffer)。
(2)上下文切换 2 :read() 系统调用完成,CPU从内核态 切换回用户态。应用程序现在拿到了数据。
4. 系统调用 (write) - 再次切换至内核态
(1)应用程序调用 write() 函数,请求将数据发送到网络。
(2)上下文切换 3 :CPU再次从用户态 切换到内核态。
5. CPU 拷贝(用户缓冲区 → Socket 缓冲区)
(1)内核将数据从用户缓冲区的数据再次通过CPU拷贝到内核的网络协议栈的缓冲区(Socket Buffer)。
6. DMA 拷贝(Socket 缓冲区 → 网卡)
(1)内核协议栈准备好数据后,网卡控制器使用 DMA 技术,将数据从Socket缓冲区直接拷贝到网卡的硬件缓冲区中,随后由网卡发送出去。
(2)上下文切换 4 :write() 系统调用完成,CPU从内核态 切换回用户态。
3.3 总结与问题所在
-
4次上下文切换:用户态 ⇄ 内核态的来回切换,每次都有开销。
-
2次不必要的CPU拷贝:数据在内核缓冲区与用户缓冲区之间来回搬运
最重要的是,应用程序通常只是中转数据,并不需要修改这些数据。这种"数据旅游"造成了巨大的CPU和内存带宽浪费。
四、零拷贝:性能优化的终极武器
4.1 核心思想
零拷贝技术的核心洞察很简单:如果应用程序不需要处理数据,为什么还要让数据穿越用户空间?
通过让数据在内核空间内直接流动,我们可以避免不必要的拷贝和上下文切换。
4.2 sendfile系统调用的魔力
Linux提供的sendfile()系统调用实现了这一理念:
应用程序调用sendfile()
↓
上下文切换1:用户态→内核态
↓
DMA拷贝:磁盘→内核缓冲区
↓
内核内部映射:仅拷贝数据描述符到Socket缓冲区
↓
DMA拷贝:内核缓冲区→网卡
↓
上下文切换2:内核态→用户态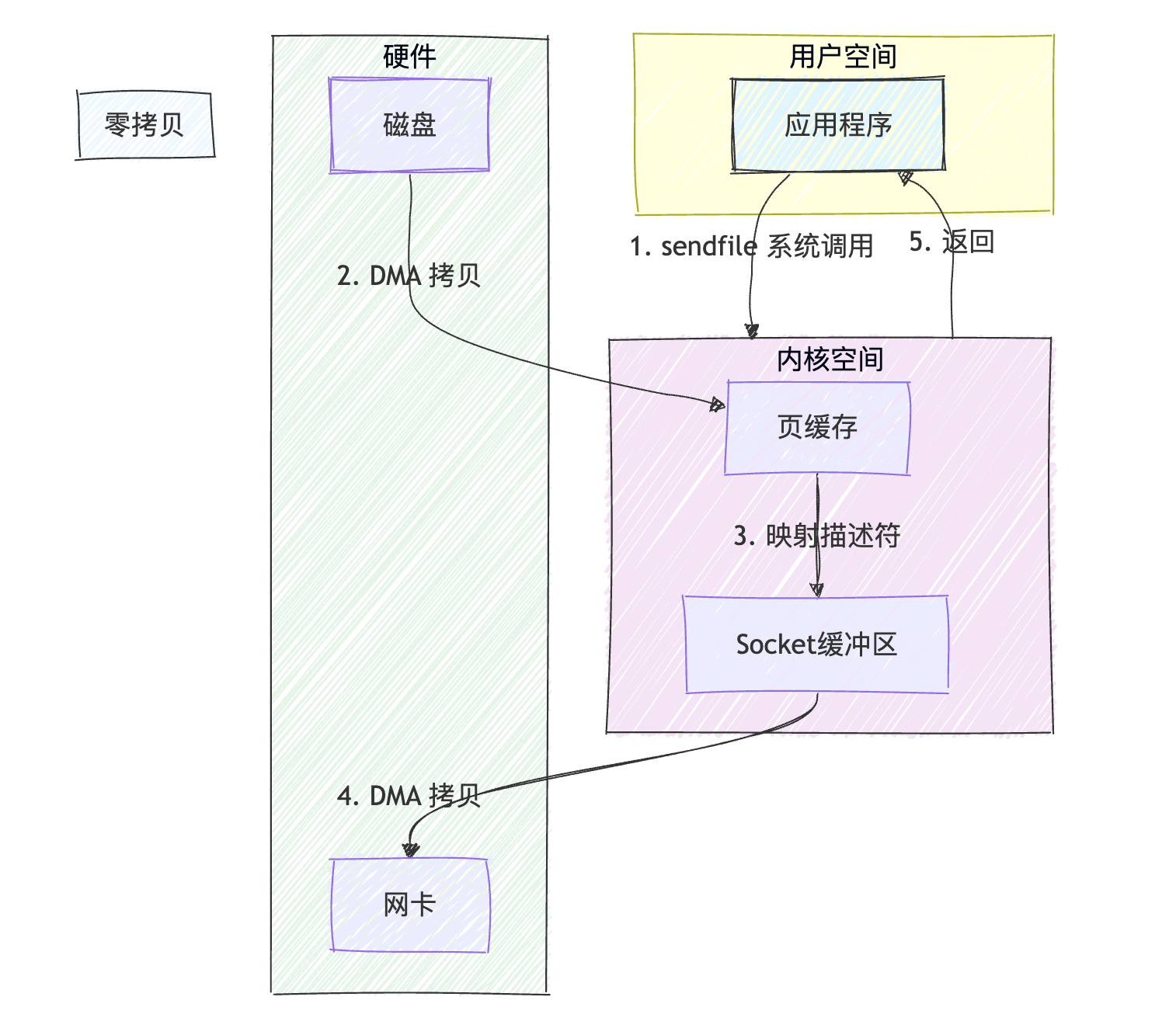 零拷贝文件传输
零拷贝文件传输
步骤详解:
-
用户缓冲区 调用
sendfile()系统调用。(1)上下文切换 1:CPU从用户态切换到内核态。
-
DMA Copy (磁盘 → 内核缓冲区):
(1)内核通过DMA 将磁盘文件数据拷贝 到内核的页缓存(Page Cache)。此过程与传统方式相同,不占用CPU。
3. 内核内部操作 (零拷贝的关键):
(1)内核不再将数据拷贝到用户空间,而是直接将页缓存中的数据块映射(描述信息)拷贝到Socket缓冲区 。这是一个极其轻量级的操作,只拷贝了数据的地址和长度等元数据,没有拷贝数据本身。
4. DMA Copy (内核缓冲区 → 网卡):
(1)网卡控制器使用DMA ,根据Socket缓冲区中的描述信息,直接从页缓存中 将数据拷贝 到网卡缓冲区。此过程不占用CPU。
(2)上下文切换 2 :sendfile() 调用完成,CPU从内核态切换回用户态。
4.3 零拷贝 vs 传统传输:性能差距一目了然
| 指标 | 传统传输(read ()+write ()) | 零拷贝(sendfile ()) |
|---|---|---|
| 上下文切换次数 | 4 次 | 2 次 |
| 数据拷贝次数 | 4 次(2 次 CPU+2 次 DMA) | 2 次(0 次 CPU+2 次 DMA) |
| CPU 开销 | 极高(拷贝 + 切换占满资源) | 极低(仅少量切换开销) |
| 核心优化点 | 无 | 内核内部指针映射,消除冗余拷贝 |
五、深入理解:DMA的重要性
直接内存访问(DMA)技术是零拷贝能够实现的基础。DMA允许外设(如磁盘控制器、网卡)直接与主内存交互,无需CPU参与数据搬运。
在传统流程中,虽然DMA负责了两次拷贝(磁盘→内核缓冲区和Socket缓冲区→网卡),但CPU仍然需要负责内核缓冲区与用户缓冲区之间的拷贝。零拷贝技术通过消除这两次CPU拷贝,真正释放了CPU的计算能力。
六、不仅仅是sendfile:其他零拷贝技术
除了sendfile(),现代操作系统还提供了其他零拷贝技术:
-
mmap():将文件直接映射到用户空间,避免read()调用的拷贝
-
splice():在两个文件描述符之间移动数据,无需用户空间参与
-
直接I/O:允许应用程序绕过页面缓存,直接访问磁盘
每种技术都有其适用场景,需要根据具体应用需求选择。
七、结论:性能优化的哲学
零拷贝技术给我们带来的不仅是性能提升,更是一种设计哲学:
-
**减少不必要的移动:**数据移动的代价很高,应尽量避免
-
**信任内核:**操作系统经过多年发展,其内部优化往往比用户空间代码更加高效
-
**专注核心价值:**让CPU专注于计算,而不是数据搬运
在现代分布式系统和大数据时代,理解并应用零拷贝技术已经成为高级开发者的必备技能。它不仅能够提升系统性能,还能降低硬件成本,提高资源利用率。
八、延伸思考
零拷贝并非万能:如果应用需要对数据做修改(比如加密、解析、格式转换),就必须把数据拿到用户态处理,这时零拷贝不再适用。这种场景下,你知道还有哪些优化手段吗?