文章目录
摘要
本周重点研读了《基于图神经网络提取时空特征的河网区域多点水质预测》论文的实验部分。深入学习了其如何利用GCN提取多监测点间的空间关联,并结合长周期注意力机制捕获时间特征。数据处理上,论文整合水质与流量时序数据,构建河网拓扑图作为输入,通过滑动窗口构造样本。实验验证部分,采用消融实验及与传统模型的对比,同时与其他多种模型进行对比,同时做了多种泛化实验,证明了方法的有效性,为多节点水环境动态预测提供了新思路。
Abstract
This week focused on studying the experimental section of the paper titled "Multi-Point Water Quality Prediction in River Network Areas Based on Spatiotemporal Feature Extraction via Graph Neural Networks." It involved an in-depth exploration of how the paper utilizes GCN to extract spatial correlations among multiple monitoring points and combines long-term attention mechanisms to capture temporal features. In terms of data processing, the paper integrates water quality and flow time-series data, constructing a river network topology graph as input and generating samples through sliding windows. The experimental validation includes ablation studies, comparisons with traditional models, and benchmarking against various other models, alongside multiple generalization tests. These efforts collectively demonstrate the method's effectiveness, offering new insights for dynamic multi-node water environment prediction.
本周继续对论文Temporal and spatial feature extraction using graph neural networks for
multi-point water quality prediction in river network areas进行解读,重点学习本论文实验中所用到的方法及创新点,如何对数据进行处理,如何实验验证合理性。
数据处理
异常值处理:
环境监测数据常因仪器故障、外界扰动或极端天气出现缺测与离群点,若直接用于训练会导致损失函数被极端样本主导,使模型学习到错误模式、泛化能力下降,因此采用 Z-score 对每个变量序列进行异常检测,计算
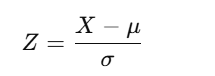
其中 X 为单个观测值,μ与σ 分别为该变量样本均值与标准差。当 Z超过阈值时,将该点判为潜在异常点,并根据数据完整性与任务需要进行筛选、插补或剔除,以提高序列平滑性与可用性。本文采用Z-score=3.5 作为异常阈值,并通过对不同國值的对比实验验证其对预测精度的影响,最终选择使误差指标最优的阈值设置。
python
import numpy as np
import pandas as pd
col = df['DO'] # 例如溶解氧这一列
mu = col.mean()
sigma = col.std()
z = (col - mu) / sigma
mask_outlier = z.abs() > 3.5 # 论文最后选的阈值 3.5数据归一化:
水质与水文变量量纲差异显著(如 °C、mg/L、NTU 等),若不做尺度统一,模型训练中梯度更新会被数值尺度较大的变量主导,从而导致收敛困难或学习偏置。在完成异常/缺失处理后,对各变量进行归一化/标准化,使不同特征处于可比的数值范围,从而提升训练稳定性与预测性能。
python
from sklearn.preprocessing import StandardScaler, MinMaxScaler
scaler = StandardScaler() # 或 MinMaxScaler()
X_scaled = scaler.fit_transform(X) # 训练集 fit+transform
# 测试集要用同一个 scaler.transform()图构建:
针对河网监测站点分布不规则、空间相互影响显著的问题,将监测站点表示为图的节点,并依据上下游流向关系与空间距离构建有向邻接矩阵 A。当站点 υi→ υ;存在水流方向且两点距离 di< RD 时建立边,并用距离倒数作为权重:
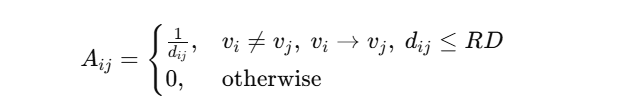
该构图方式体现"越近影响越大、上游影响下游"的物理直觉,便于 GCN 聚合邻域信息、学习污染物在空间上的传播与耦合效应。距离阈值 RD 会影响图的稀疏度与噪声引入程度,因此需通过对多个候选阈值的实验比较选取最优设置(文献实验中取 RD=20km)。
(PS:当你的数据来自多个相互连通/相互影响的测点(如河网上下游、路网、管网等),且这种影响可用拓扑或距离关系描述时,就应构图,用 GNN 显式建模空间依赖以提升预测与泛化。)
python
import numpy as np
N = len(stations)
A = np.zeros((N, N))
RD = 20_000 # 比如 20 km(单位看你距离单位)
for i in range(N):
for j in range(N):
if i == j:
continue
if is_upstream(i, j) and dist[i, j] <= RD:
A[i, j] = 1.0 / dist[i, j]滑动窗口
为将原始连续时序转化为可监督学习的样本对,采用滑动窗口将序列重构为"输入窗口一预测目标"的形式:使用过去 工 个时间步作为输入,预测未来 步的目标变量。该操作使模型能够学习短期波动和长期趋势等时间依赖结构,并与 GRU 等时序模块的输入形式一致。窗口长度 工 属于关键超参数,需结合验证集进行选择。
python
def build_sequences(data, L, H=1):
X_list, Y_list = [], []
for i in range(len(data) - L - H + 1):
X_list.append(data[i : i+L]) # 过去 L 步
Y_list.append(data[i+L : i+L+H]) # 未来 H 步
return np.array(X_list), np.array(Y_list)总结如下表
| 步骤 | 方法 | 参数/说明 |
|---|---|---|
| 异常值处理 | Z-score异常检测 | 阈值=3.5,超出则剔除或插值 |
| 归一化 | Z-score标准化 | 按特征维度标准化 |
| 图构建 | 距离+流向 | 距离<20km,权重=1/d |
| 时间滑窗 | 滑动窗口法 | 输入:过去32小时,预测:未来1--48小时 |
| 防止过拟合 | Dropout=0.2 | 每层之间加dropout |
创新性
针对河网区域多站点水质预测中"空间依赖强、拓扑结构不规则、时间动态复杂"的特点,本文采用一种将图神经网络与序列模型结合的时空预测框架,其核心思想是:用图卷积刻画站点间空间传播关系,用门控循环单元刻画水质随时间的演化规律,并通过注意力机制实现时空特征的自适应融合。该设计的创新点在于把原本分离的"空间相关性建模"和"时间序列建模"统一到同一端到端网络中,从而提升多站点预测精度、跨站点/跨流域泛化能力以及对噪声数据的鲁棒性。
GCN:
GCN具有将监测站和位置之间的邻接关系建模为图结构的能力,从而将监测站连接成一个空间互联的网络,如图所示。通过利用这一图结构,GCN可以通过高效的消息传递机制迭代地聚合来自邻近节点的信息,从而捕捉监测站之间的潜在空间相关性
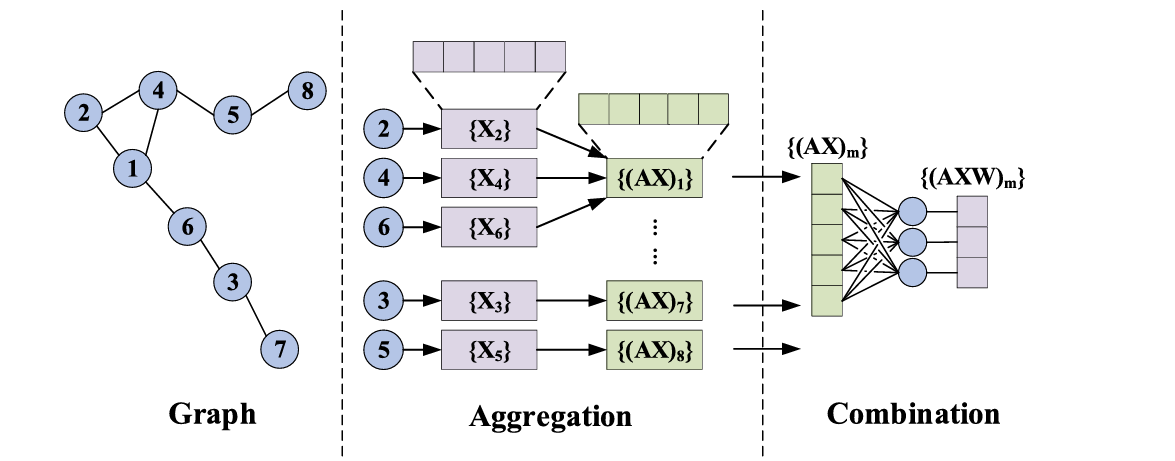
输入:图结构 + 节点特征(多变量时间序列)
输出:每个节点的"空间上下文"特征
GRU
GRU方法被引入以捕捉水文和水质数据随时间变化的动态,以便分析输入数据的时间相关性。GRU是RNN的一种变体,它可以通过一个门控机制减轻长序列预测中的梯度消失和爆炸问题。GRU能够通过门控机制实现信息保留与遗忘之间的平衡,使得能够提取输入数据中的周期性模式,从而增强长期序列预测的稳定性和效率。与LSTM相比,GRU的结构更为简洁,参数更少,因此训练速度更快

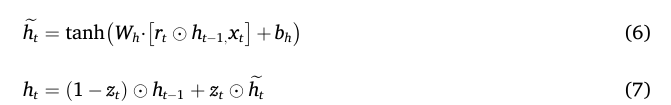
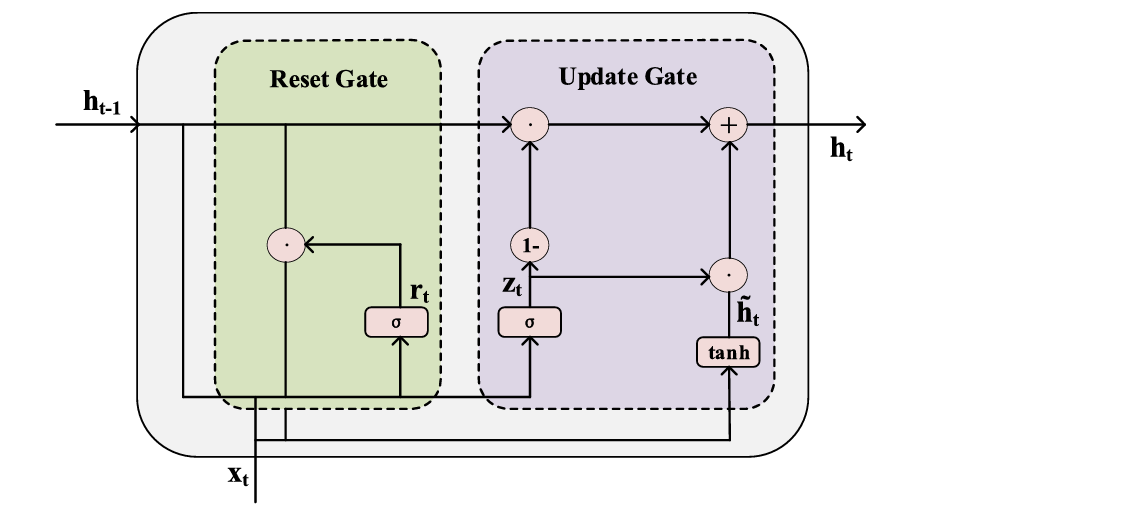
输入:某站点过去 T 个时刻的 F 维水质序列。
输出: 该站点"被门控机制提炼后的完整时间动态",后续直接与 GCN 的空间向量拼接融合
时空融合模块(Self-attention)
首先输入被映射到三个不同的新向量:查询(Query)、键(Key)和值(Value),使用三个不同的线性层。查询和键向量相乘得到一个得分值,然后除以 Vdk 以在模型训练期间保持稳定的梯度,接着,使用Softmax激活函数处理得到的结果,将相关系数映射到(0.1)范围内,确保总和等于1且所有值都为正数。最后,将相关矩阵与值向量相乘得到融合后的时空特征。
公式: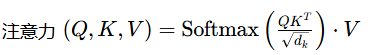
实验验证
| 实验类别 | 目的 | 数据集/场景 | 关键设置 | 主要结果(DO / TN) | 结论 |
|---|---|---|---|---|---|
| 1. 基准预测 | 验证整体精度 | 漓江 8 站,2020-01→2022-12 小时数据 | 训练 60 %、验证 20 %、测试 20 %;预测 2022-03→12 小时值 | RMSE:0.233 / 0.033;MAE:0.162 / 0.026;SMAPE:0.116 % / 0.018 % | 模型在测试期准确复现实测波动,误差 < 19 %。 |
| 2. 消融实验 | 量化各模块贡献 | 同一漓江测试集 | ①仅 GCN(去 GRU)②仅 GRU(去 GCN)③完整 STF-GNN | 相对完整模型,DO 精度↓ 18 %/12 %;TN 精度↓ 19 %/18 % | 空间+时间缺一不可;融合模块带来 12--19 % 增益。 |
| 3. 多模型对比 | 证明优于现有方法 | 同上 | 对比 RF、MLP、RNN、LSTM、Transformer、ST-GCN、DCRNN | STF-GNN RMSE 最低,较次优模型再降 36--161 % | 显式时空融合设计在河网场景显著领先。 |
| 4. 跨流域泛化 | 测试地域迁移性 | 珠江流域 8 站(未参与训练) | 直接加载漓江最优权重,零样本预测 DO、TN | 最大相对误差 < 0.64(DO)/0.61(TN);峰谷同步 ≥ 88 % | 模型无需重训即可保持高精度,泛化能力强。 |
| 5. 未训练站点泛化 | 测试空间外推 | 漓江"先进站"排除在训练集外 | 用其余 7 站训练,预测先进站 2022 小时序列 | 未训练站 RMSE:0.287 / 0.046;峰谷同步 > 88 % | 对未见站点仍具时空 extrapolation 能力。 |
| 6. 鲁棒性-噪声 | 验证抗异常能力 | 同一漓江测试集 | ①原始传感器数据(含漂移)②常规 3σ+小波去噪数据 | 未处理数据 RMSE 仅↑ 7--12 %,全部误差 < 15 % | 门控+图平滑+注意力协同,有效抑制脏数据冲击。 |
| 7. 超参敏感性 | 确定最佳阈值 | 同上 | Z-score 阈值{3.0,3.5,4.0};邻接距离{15,20,25 km} | Z=3.5、距离=20 km 时 RMSE/MAE/SMAPE 同时最小 | 给出可复现的推荐超参组合。 |
在今后的实验中,可以学习该论文对实验的分析验证思路,从多个角度入手:预测实验证明实验的正确性;消融实验和多模型对比,验证模型的优越性;像"跨流域泛化"、未训练站点泛化等实验可证明该模型的泛化能力强;鲁棒性-噪声实验:验证模型的抗异常能力等等。
总结
通过学习,我掌握了该研究将河网拓扑转化为图结构数据的处理方法,并理解了其融合水质时序与空间邻近性的模型设计创新点。实验通过严格划分训练集、验证集与测试集,并引入长周期损失函数强化时序依赖学习,增强了预测的稳健性。