阅读一篇阿里国际的论文《MMQ-v2: Align, Denoise, and Amplify: Adaptive Behavior Mining for Semantic IDs Learning in Recommendation》针对 内容-行为 联合构建 SID 这个方向。
论文链接:https://arxiv.org/pdf/2510.25622
1. 背景
-
用 item id 表示 item,存在问题:
- 不带语义:不能共享知识,即使两个 item 内容几乎一样。
- 不泛化:新物品(冷启动)、长尾物品(交互少)很难学到很好的表示。
- 规模太大:每个 item 都要独立学 embedding。
-
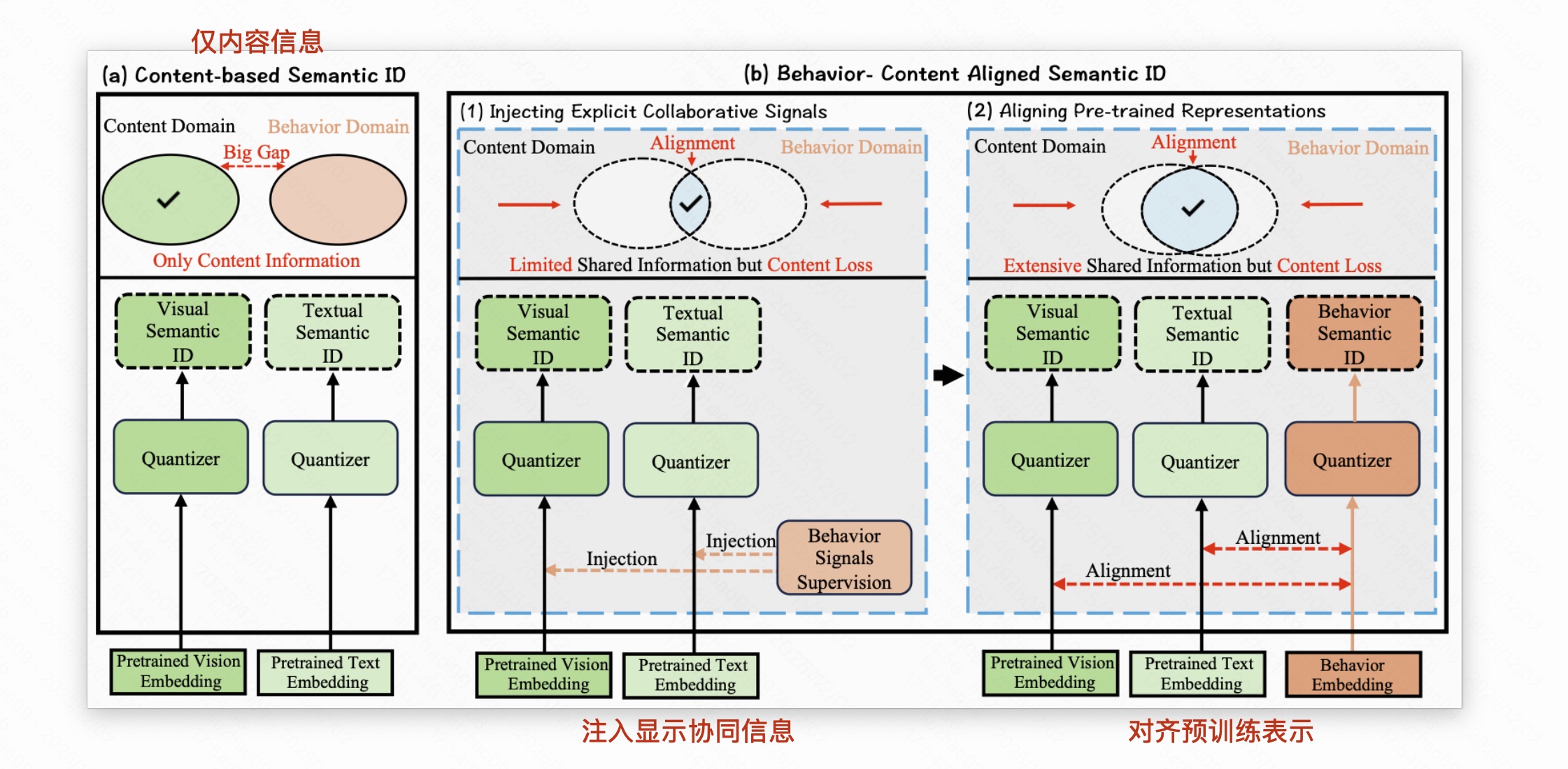
仅内容的 Semantic ID(SIDs),如 TIGER,存在问题:
- 忽略协同信息:行为里存在偏好(时效、人群),仅靠内容难以捕获 "大家最近热爱买某款丑萌玩具" 这种趋势。
- 无法表达 item 热度与交互模式:内容相似的 item 可能 "协同地位" 差异巨大(一个爆款、一个无人问津)。
- 长尾问题仍然严重:对于少数长尾 item 确实有益,但是对于头部 item,大量行为信息被浪费,只用内容信息容易表达力不足。
-
内容 + 行为,现有两种做法:1. 注入显式协同信号;2. 对齐预训练表示。
- 注入显示协同信号,把行为当监督,【LC-Rec 、ColaRec :先有一个预训练召回/排序模型,拿到稳定的行为 embedding, 再设计一堆对齐损失,让内容 SID 靠近这些协同向量,相当于"行为当 teacher,内容 SID 当 student"。IDGenRec :从推荐模型里蒸馏出协同 SID,再和内容特征拼接】,存在问题:
- 一刀切地融合行为 ,容易把长尾噪声带进来:长尾 item 行为极少,协同 embedding 不稳定,如果强行让内容 SID 去对齐这些噪声 embedding,反而会污染原本很干净的内容语义(Noise Corruption)。
- 对头部 item 又不够细致:大量、复杂的行为模式被压缩进一个协同向量,再通过对齐/蒸馏映射到一套内容 SID 上,容易丢掉细粒度交互差异,只保留粗糙的"平均行为"。
- 对齐预训练表示,分别为内容、行为学习表示后对齐到同一空间【EAGER :先对内容 embedding 和行为 embedding 各自做 K-means 得到两套 SID,再在下游任务里对齐它们。DAS :用多视角对比学习,让内容 SID 与协同信号之间信息互相最大化。LETTER :在 RQ-VAE 里显式融合层级语义 + 协同信号 + 多样的 code 分配,生成"行为-内容融合 SID"。MM-RQ-VAE :多模态版本,对文本、图像、协同分别用 RQ-VAE 得到多模态 SID,再用对比学习做行为-内容对齐。】,存在问题:
- 没有考虑 "行为信息丰富度" 的差异:不管头部还是尾部,对齐强度基本一样。
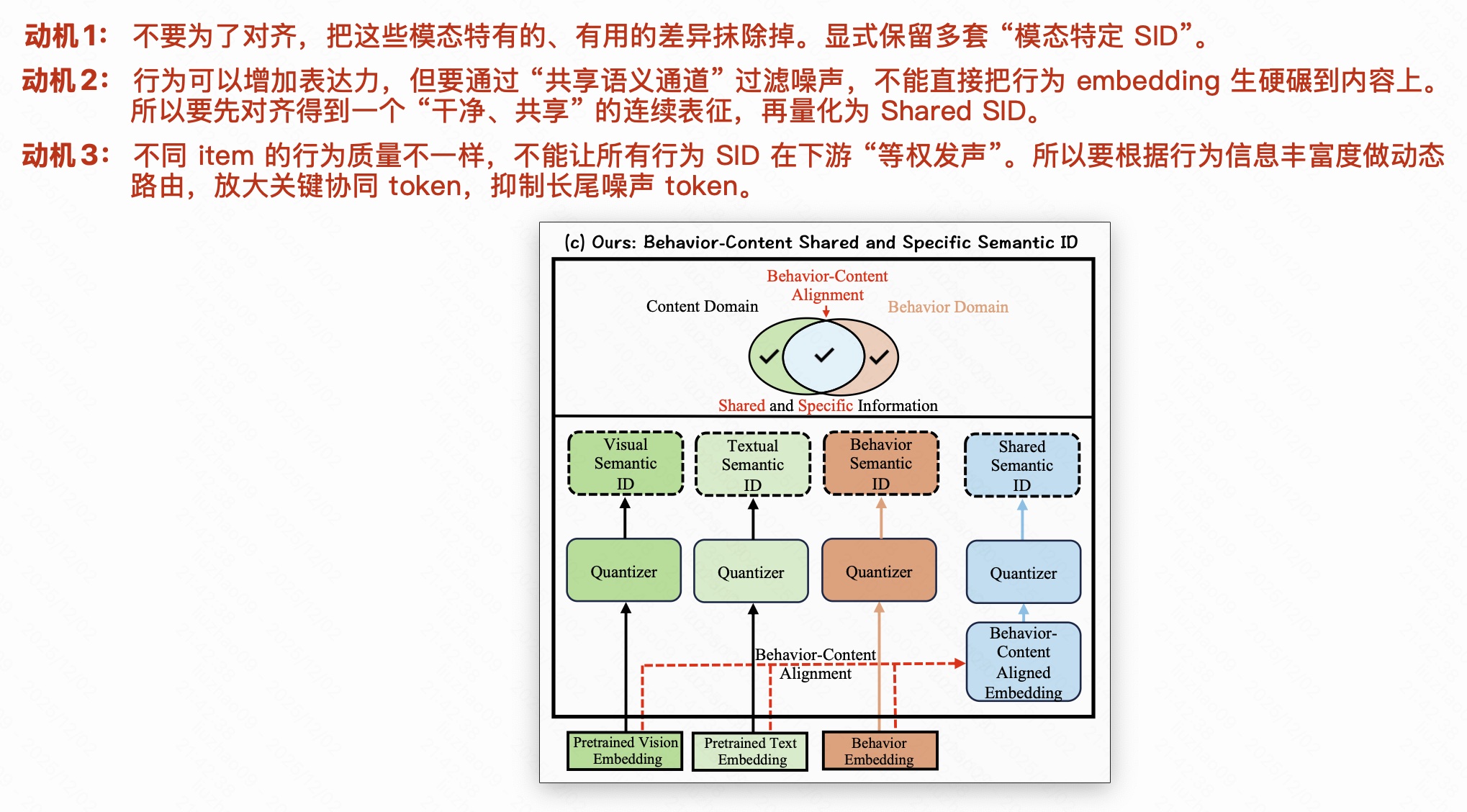
- 只学 "共享信息",忽略 "模态特有信息":多数方法最终得到的是一个 "内容 + 行为 都差不多" 的 SID,但现实中,有些特征只存在于内容(比如图像风格),有些特征只存在于行为。完全只追求对齐,会让这些模态特有的、有用的差异被抹平。
- SID token 在下游被"等权利用",导致信号被淹没 :现有行为+内容 SID 往往会为每个 item 生成多种 SID(内容、多模态、协同等),但在聚合这些 SID 时通常采用固定或简单的平均/拼接策略,缺乏基于 item 行为质量 的精细权重控制。这样一来,关键的协同信号与长尾噪声 SID 混在一起,下游模型难以区分其重要性。
- 注入显示协同信号,把行为当监督,【LC-Rec 、ColaRec :先有一个预训练召回/排序模型,拿到稳定的行为 embedding, 再设计一堆对齐损失,让内容 SID 靠近这些协同向量,相当于"行为当 teacher,内容 SID 当 student"。IDGenRec :从推荐模型里蒸馏出协同 SID,再和内容特征拼接】,存在问题:
本文动机:
2. 方法
在这篇工作里,要做的事情可以概括为:给每个物品学习一个"离散语义 ID 序列"来替代原始的连续向量表示 。具体做法是:对每个 item,先用预训练模型得到文本向量 e t \mathbf{e}_t et、视觉向量 e v \mathbf{e}_v ev 和行为向量 e b \mathbf{e}b eb,然后通过一个 item Tokenizer T item \mathcal{T}{\text{item}} Titem 把三者一起量化成长度为 l l l 的离散 token 序列:
Semantic_IDs = ( c 1 , c 2 , ... , c l ) = T item ( e t , e v , e b ) . \text{Semantic\IDs} = (c_1, c_2, \dots, c_l) = \mathcal{T}{\text{item}}(\\mathbf{e}_t, \\mathbf{e}_v, \\mathbf{e}_b). Semantic_IDs=(c1,c2,...,cl)=Titem(et,ev,eb).
其中 ( c 1 , ... , c l ) (c_1,\dots,c_l) (c1,...,cl) 就是这个物品的语义 ID 列表, l l l 是 SID 的长度(预先设定的常数 8/6),而 c i c_i ci 是第 i i i 个语义 ID 对应的码本索引。后续推荐模型就不再直接用这些连续向量 e t , e v , e b \mathbf{e}_t,\mathbf{e}_v,\mathbf{e}_b et,ev,eb,而是用这串离散的 SID token 来表示 item。
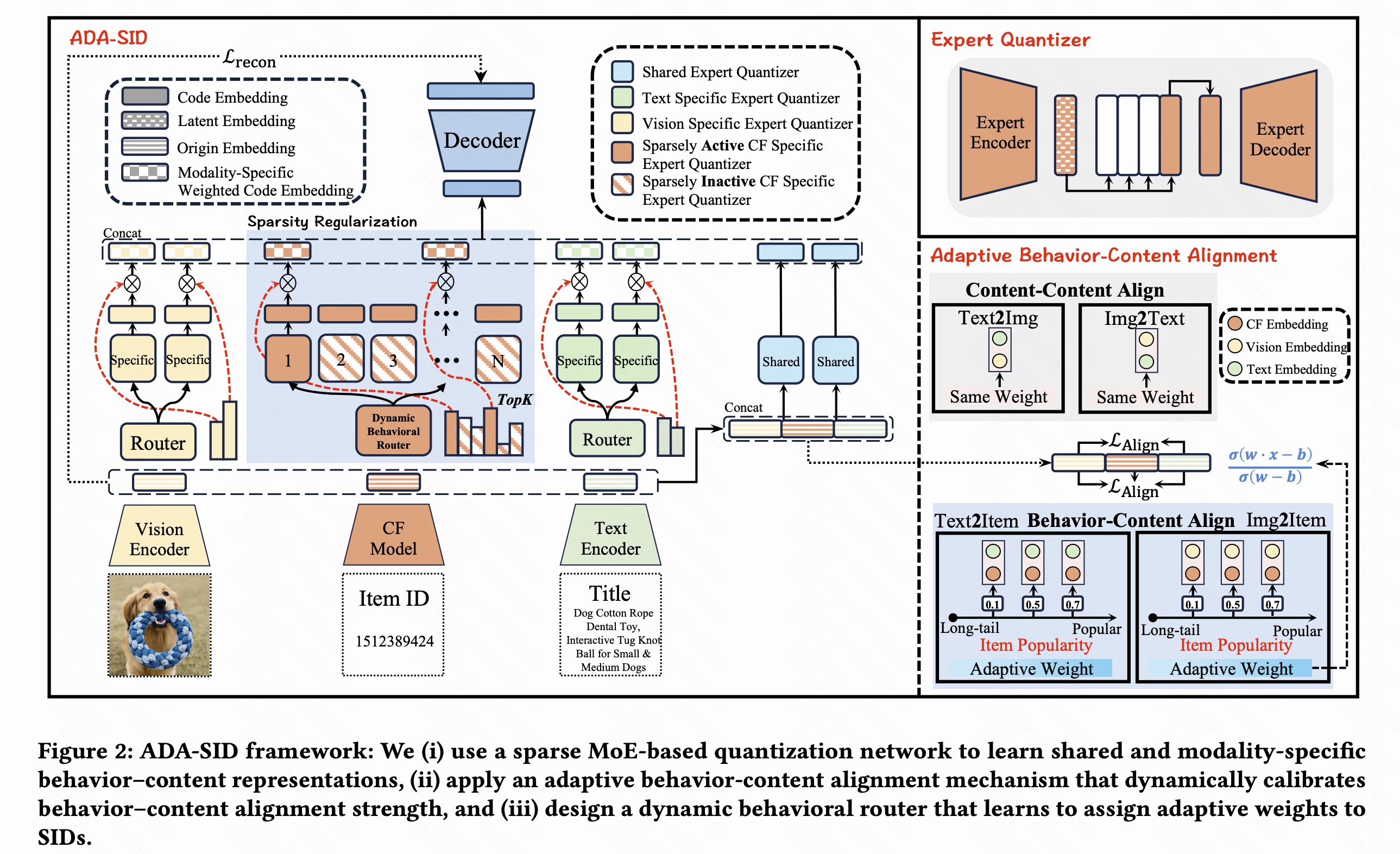
2.1 行为-内容混合量化网络
为了同时建模"行为--内容的共享信息"和"各模态特有信息",本文提出 行为-内容混合量化网络 。首先,把文本、图像和行为的预训练向量统一映射到同一高维空间。给定文本向量 e t e_t et、图像向量 e v e_v ev 和行为向量 e b e_b eb,通过三个两层 MLP 得到:
h t = D t ( e t ) , h v = D v ( e v ) , h b = D b ( e b ) , h_t = D_t(e_t), \quad h_v = D_v(e_v), \quad h_b = D_b(e_b), ht=Dt(et),hv=Dv(ev),hb=Db(eb),
并将它们拼接为整体表示:
h = h t , h v , h b . \mathbf{h} = h_t,\\, h_v,\\, h_b. h=ht,hv,hb.
在此基础上,网络分别通过 共享 experts 和 模态特定 experts 来学习不同粒度的语义信息,并用量化的方式得到一组离散的 Semantic IDs。
2.1.1 共享 Experts:行为-内容共享语义量化
共享 experts 只关注"行为与内容的共同部分"。设共有 N s N_s Ns (2) 个共享 expert,记为 { E s , i } i = 1 N s \{E_{s,i}\}_{i=1}^{N_s} {Es,i}i=1Ns。对于第 i i i 个共享 expert,先把融合表示 h \mathbf{h} h 编码成共享 latent 表示:
z s , i = E s , i ( h ) . \mathbf{z}{s,i} = E{s,i}(\mathbf{h}). zs,i=Es,i(h).
然后,从该 expert 对应的共享 codebook C s , i = { z q , j } j = 1 K C_{s,i} = \{\mathbf{z}{q,j}\}{j=1}^K Cs,i={zq,j}j=1K 中,用余弦相似度挑选最接近的 codeword,作为第 i i i 个共享 SID:
c s , i = arg max j ∈ { 1 , ... , K } z s , i ⊤ z q , j ∥ z s , i ∥ ∥ z q , j ∥ . c_{s,i} = \arg\max_{j \in \{1,\dots,K\}} \frac{\mathbf{z}{s,i}^\top \mathbf{z}{q,j}} {\|\mathbf{z}{s,i}\|\,\|\mathbf{z}{q,j}\|}. cs,i=argj∈{1,...,K}max∥zs,i∥∥zq,j∥zs,i⊤zq,j.
其中, K K K 是每个共享 codebook 的大小。这样,每个 item 会得到一组"跨模态共享"的离散 SID token,用于表达行为与内容中一致的语义模式。
2.1.2 模态特定 Experts 与融合重构
模态特定 experts 负责保留每种模态的独有信息。以文本模态 (2 experts) 为例,一组文本 experts { E t , i } i = 1 N t \{E_{t,i}\}_{i=1}^{N_t} {Et,i}i=1Nt 将文本向量 e t e_t et 映射为一系列 latent:
z t , i = E t , i ( e t ) , \mathbf{z}{t,i} = E{t,i}(e_t), zt,i=Et,i(et),
再从文本 codebooks { C t , i } i = 1 N t \{C_{t,i}\}{i=1}^{N_t} {Ct,i}i=1Nt 中检索最近的 codeword z q t , i \mathbf{z}{qt,i} zqt,i 作为文本 SID。图像模态 (2 experts) 和行为模态 (6-->2 experts) 同理,得到
z v , i = E v , i ( e v ) , z b , i = E b , i ( e b ) , \mathbf{z}{v,i} = E{v,i}(e_v), \quad \mathbf{z}{b,i} = E{b,i}(e_b), zv,i=Ev,i(ev),zb,i=Eb,i(eb),
以及对应的量化向量 z q v , i \mathbf{z}{qv,i} zqv,i、 z q b , i \mathbf{z}{qb,i} zqb,i。
接着,模型通过一组 gate 将共享 latent 与各模态 latent 按重要性加权融合,得到连续表示 z \mathbf{z} z 和其量化版本 z q \mathbf{z}_q zq:
z = ∑ i = 1 N s z s , i + ∑ i = 1 N v g v , i z v , i + ∑ i = 1 N t g t , i z t , i + ∑ i = 1 N b g b , i z b , i , \mathbf{z} = \sum_{i=1}^{N_s} \mathbf{z}{s,i} + \sum{i=1}^{N_v} g_{v,i}\,\mathbf{z}{v,i} + \sum{i=1}^{N_t} g_{t,i}\,\mathbf{z}{t,i} + \sum{i=1}^{N_b} g_{b,i}\,\mathbf{z}_{b,i}, z=i=1∑Nszs,i+i=1∑Nvgv,izv,i+i=1∑Ntgt,izt,i+i=1∑Nbgb,izb,i,
z q = ∑ i = 1 N s z q s , i + ∑ i = 1 N v g v , i z q v , i + ∑ i = 1 N t g t , i z q t , i + ∑ i = 1 N b R ( e b ) i z q b , i . \mathbf{z}q = \sum{i=1}^{N_s} \mathbf{z}{qs,i} + \sum{i=1}^{N_v} g_{v,i}\,\mathbf{z}{qv,i} + \sum{i=1}^{N_t} g_{t,i}\,\mathbf{z}{qt,i} + \sum{i=1}^{N_b} R(e_b)i\,\mathbf{z}{qb,i}. zq=i=1∑Nszqs,i+i=1∑Nvgv,izqv,i+i=1∑Ntgt,izqt,i+i=1∑NbR(eb)izqb,i.
其中, g t = softmax ( MLP t ( e t ) + b t ) g_t = \text{softmax}(\text{MLP}_t(e_t)+b_t) gt=softmax(MLPt(et)+bt)、 g v = softmax ( MLP v ( e v ) + b v ) g_v = \text{softmax}(\text{MLP}_v(e_v)+b_v) gv=softmax(MLPv(ev)+bv) 分别是文本/图像 experts 的权重,行为侧的权重由动态路由器 R ( e b ) R(e_b) R(eb) 决定。
最后,用解码器把 z \mathbf{z} z 与 z q \mathbf{z}_q zq 融合后重构回原始多模态向量 e = e t , e v , e b \mathbf{e} = e_t, e_v, e_b e=et,ev,eb,并通过重构损失进行端到端训练:
L recon = ∥ e − decoder ( z + sg ( z q − z ) ) ∥ 2 , \mathcal{L}_{\text{recon}} = \left\| \mathbf{e} - \text{decoder}\big(\mathbf{z} + \text{sg}(\mathbf{z}_q - \mathbf{z})\big) \right\|^2, Lrecon= e−decoder(z+sg(zq−z)) 2,
其中 sg ( ⋅ ) \text{sg}(\cdot) sg(⋅) 为 stop-gradient 操作,用于对量化部分采用 straight-through estimator。这样,模型同时学到 共享 SID (跨模态公共语义)和 模态特定 SID(文本/图像/行为独有语义),为后续推荐任务提供更丰富的语义离散表示。
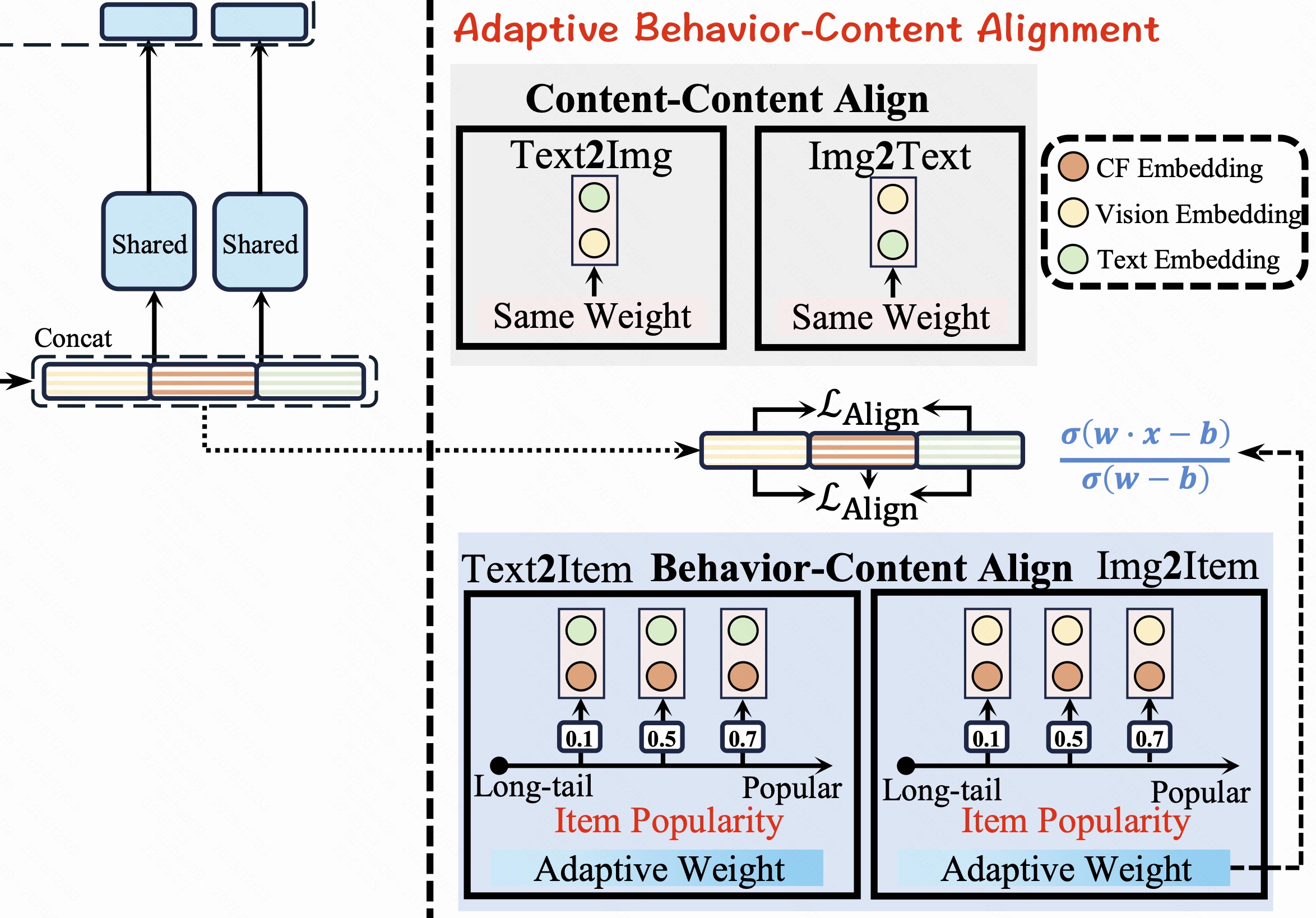
2.2 自适应 Behavior-Content 对齐
为了避免对所有 item 的行为信息"一刀切对齐",作者先用行为 embedding 的模长估计该 item 的行为信息是否丰富,再用带权重的对比学习将内容域与行为域对齐。
2.2.1 对齐强度控制器
给定行为 embedding 矩阵 E ∈ R K × D E\in\mathbb{R}^{K\times D} E∈RK×D,其中第 i i i 行为 e b , i e_{b,i} eb,i,先求出模长的最大、最小值:
N max = max i ∈ { 1 , ... , K } ∥ e b , i ∥ 2 , N min = min i ∈ { 1 , ... , K } ∥ e b , i ∥ 2 . N_{\max}=\max_{i\in\{1,\dots,K\}}\lVert e_{b,i}\rVert_2,\qquad N_{\min}=\min_{i\in\{1,\dots,K\}}\lVert e_{b,i}\rVert_2. Nmax=i∈{1,...,K}max∥eb,i∥2,Nmin=i∈{1,...,K}min∥eb,i∥2.
对第 j j j 个 item,将其模长归一化到 0 , 1 0,1 0,1:
N norm ( e b , j ) = ∥ e b , j ∥ 2 − N min N max − N min . N_{\text{norm}}(e_{b,j})=\frac{\lVert e_{b,j}\rVert_2-N_{\min}}{N_{\max}-N_{\min}}. Nnorm(eb,j)=Nmax−Nmin∥eb,j∥2−Nmin.
再用"平移+缩放后的 Sigmoid"得到该 item 的行为--内容对齐强度权重 w w w:
w = σ ( α N norm ( e b , j ) − β ) σ ( α − β ) , w=\frac{\sigma\!\big(\alpha\,N_{\text{norm}}(e_{b,j})-\beta\big)}{\sigma(\alpha-\beta)}, w=σ(α−β)σ(αNnorm(eb,j)−β),
其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 为 Sigmoid, α , β \alpha,\beta α,β 控制曲线的陡峭程度和"从长尾变为头部"的阈值。 直观上: ∥ e b , j ∥ 2 \lVert e_{b,j}\rVert_2 ∥eb,j∥2 越大(行为越丰富、越可靠), N norm ( e b , j ) N_{\text{norm}}(e_{b,j}) Nnorm(eb,j) 越接近 1 1 1,从而 w w w 越大;长尾 item 的 ∥ e b , j ∥ 2 \lVert e_{b,j}\rVert_2 ∥eb,j∥2 较小,对应的 w w w 接近 0 0 0,几乎不强迫它去对齐噪声行为。
2.2.2 行为--内容对比学习
首先把文本、图像的隐藏表示相加得到统一内容表示
h c = h t + h v . h_c = h_t + h_v. hc=ht+hv.
(1) 内容--内容对齐损失
使用 InfoNCE,让同一 item 的文本与图像互相靠近、与其他 item 远离。简写为:
L content = − log exp ( s i m ( h t , h v + ) / τ ) ∑ i = 1 B exp ( s i m ( h t , h v , i ) / τ ) − log exp ( s i m ( h v , h t + ) / τ ) ∑ i = 1 B exp ( s i m ( h v , h t , i ) / τ ) , \mathcal{L}\text{content}= -\log \frac{\exp(\mathrm{sim}(h_t,h{v^+})/\tau)} {\sum_{i=1}^{B}\exp(\mathrm{sim}(h_t,h_{v,i})/\tau)} -\log \frac{\exp(\mathrm{sim}(h_v,h_{t^+})/\tau)} {\sum_{i=1}^{B}\exp(\mathrm{sim}(h_v,h_{t,i})/\tau)}, Lcontent=−log∑i=1Bexp(sim(ht,hv,i)/τ)exp(sim(ht,hv+)/τ)−log∑i=1Bexp(sim(hv,ht,i)/τ)exp(sim(hv,ht+)/τ),
其中 s i m ( ⋅ , ⋅ ) \mathrm{sim}(\cdot,\cdot) sim(⋅,⋅) 为余弦相似度, τ \tau τ 为温度系数; ( h t , h v + ) (h_t,h_{v^+}) (ht,hv+)、 ( h v , h t + ) (h_v,h_{t^+}) (hv,ht+) 是同一 item 的正样本对,其它为负样本。
(2) 行为--内容对齐损失
再用 InfoNCE 促使同一 item 的行为表示 h b h_b hb 与其内容表示 h c h_c hc 靠近:
L align = − log exp ( s i m ( h b , h c + ) / τ ) ∑ i = 1 B exp ( s i m ( h b , h c , i ) / τ ) . \mathcal{L}\text{align}= -\log \frac{\exp(\mathrm{sim}(h_b,h{c^+})/\tau)} {\sum_{i=1}^{B}\exp(\mathrm{sim}(h_b,h_{c,i})/\tau)}. Lalign=−log∑i=1Bexp(sim(hb,hc,i)/τ)exp(sim(hb,hc+)/τ).
(3) 总对齐损失
最终的对齐损失,把内容--内容对齐视为始终重要,而行为--内容对齐的权重由 w w w 决定:
L align_total = L content + w L align . \mathcal{L}\text{align\total}= \mathcal{L}\text{content} + w\,\mathcal{L}\text{align}. Lalign_total=Lcontent+wLalign.
因此,头部 item( w w w 大)会被强烈地对齐行为与内容,从而充分利用丰富协同信号;长尾 item( w w w 小)则主要依赖稳定的内容表示,避免被稀疏、噪声行为"带偏"。
2.3 动态行为路由器与稀疏正则
为了区分"哪些行为 SID 重要",本文为每个 item 的行为向量 e b \mathbf e_b eb 设计了一个动态路由器 R ( e b ) R(\mathbf e_b) R(eb),并通过稀疏与负载均衡正则,控制实际被激活的行为 SID 数量。
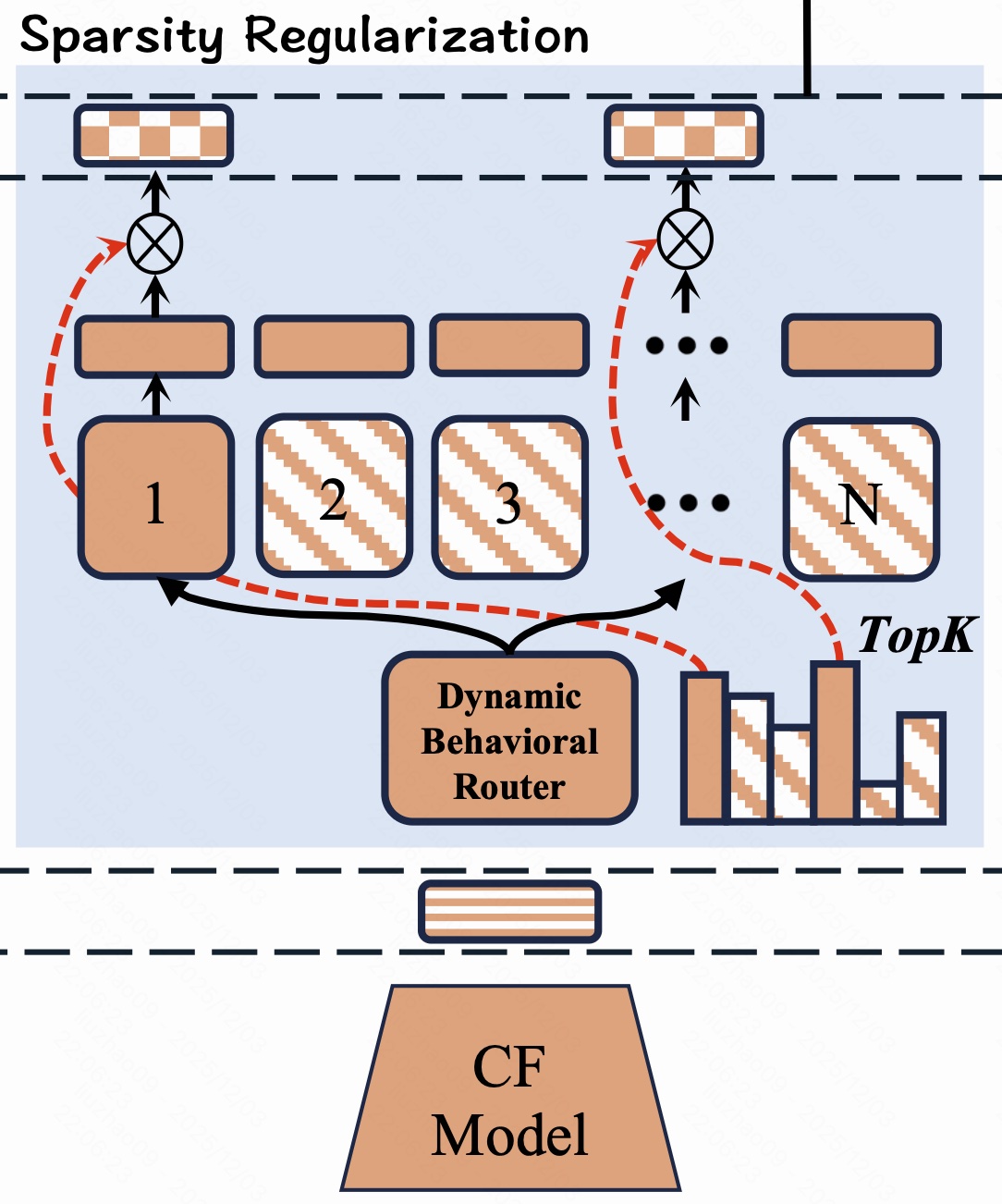
2.3.1 行为引导的动态路由器
路由器先利用 2.2.1 中得到的归一化范数 N norm ( e b ) ∈ 0 , 1 N_{\text{norm}}(\mathbf e_b)\in0,1 Nnorm(eb)∈0,1 作为该 item 行为信息丰富度,然后输出行为 SID 的软权重:
R ( e b ) = σ ( N norm ( e b ) ) ⋅ ReLU ( MLP ( e b ) + b ) . R(\mathbf e_b) = \sigma\!\big(N_{\text{norm}}(\mathbf e_b)\big)\cdot \text{ReLU}\big(\text{MLP}(\mathbf e_b)+\mathbf b\big). R(eb)=σ(Nnorm(eb))⋅ReLU(MLP(eb)+b).
- MLP ( ⋅ ) \text{MLP}(\cdot) MLP(⋅):从 e b \mathbf e_b eb 中抽取行为特有语义;
- ReLU ( ⋅ ) \text{ReLU}(\cdot) ReLU(⋅):保证权重非负,并产生 exact-zero 稀疏(部分 SID 权重变成 0 0 0);
- σ ( ⋅ ) \sigma(\cdot) σ(⋅):把整体权重缩放到 0 , 1 0,1 0,1,并随 N norm ( e b ) N_{\text{norm}}(\mathbf e_b) Nnorm(eb) 单调变化------热门 item(范数大)整体权重大,长尾 item 整体权重小。
因此 R ( e b ) j R(\mathbf e_b)_j R(eb)j 就是第 j j j 个行为 SID 的重要性分数:热门 item 倾向于保留更多、高权重的行为 SID,长尾 item 的大部分行为 SID 会被压到接近 0 0 0。
2.3.2 稀疏与负载均衡正则
为了让路由器既稀疏又稳定,作者为每个 item 设定目标稀疏度 S target S_{\text{target}} Starget,并用正则项约束实际稀疏度 S current S_{\text{current}} Scurrent。
当前稀疏度(实质上是"未被激活比例")为:
S current = 1 − 1 N b ∑ j = 1 N b 1 { R ( e b ) j > 0 } , S_{\text{current}} = 1-\frac{1}{N_b}\sum_{j=1}^{N_b}\mathbf 1\{R(\mathbf e_b)_j>0\}, Scurrent=1−Nb1j=1∑Nb1{R(eb)j>0},
其中 N b N_b Nb 为行为 experts 数量, 1 { ⋅ } \mathbf 1\{\cdot\} 1{⋅} 为指示函数;激活越多, S current S_{\text{current}} Scurrent 越小。
目标稀疏度根据行为范数自适应设定:
S target = θ ⋅ 1 − N norm ( e b ) N max − N min , S_{\text{target}} = \theta\cdot\frac{1-N_{\text{norm}}(\mathbf e_b)}{N_{\max}-N_{\min}}, Starget=θ⋅Nmax−Nmin1−Nnorm(eb),
其中 N max , N min N_{\max},N_{\min} Nmax,Nmin 是 batch 中行为范数的最大/最小值, θ \theta θ 控制整体稀疏强度。
N norm ( e b ) N_{\text{norm}}(\mathbf e_b) Nnorm(eb) 越大(热门 item), S target S_{\text{target}} Starget 越小,表示允许激活更多行为 SID;反之长尾 item 期望更稀疏。
为避免只激活极少 experts 而导致路由塌缩,引入负载均衡系数
f l b = 1 ( 1 − S target ) B ∑ t = 1 B ∑ j = 1 N b 1 { R ( e b ( t ) ) j > 0 } / N b , f_{lb} = \frac{1}{(1-S_{\text{target}})B} \sum_{t=1}^{B}\sum_{j=1}^{N_b}\mathbf 1\{R(\mathbf e_b^{(t)})_j>0\}/N_b, flb=(1−Starget)B1t=1∑Bj=1∑Nb1{R(eb(t))j>0}/Nb,
其中 B B B 为 batch 大小。整体激活过少时, f l b f_{lb} flb 会变大,从而在正则中加大惩罚。
最终的稀疏正则为
L reg , i = λ i 1 B ∑ t = 1 B ∑ j = 1 N b f l b ∥ R ( e b ( t ) ) j ∥ 1 , L_{\text{reg},i} = \lambda_i\frac{1}{B}\sum_{t=1}^{B}\sum_{j=1}^{N_b} f_{lb}\,\big\lVert R(\mathbf e_b^{(t)})_j\big\rVert_1, Lreg,i=λiB1t=1∑Bj=1∑Nbflb R(eb(t))j 1,
并通过
λ i = λ i − 1 α sign ( S target − S current ) \lambda_i = \lambda_{i-1}\alpha^{\text{sign}(S_{\text{target}}-S_{\text{current}})} λi=λi−1αsign(Starget−Scurrent)
自适应调整正则强度:若当前比目标更"稠密"( S current < S target S_{\text{current}}<S_{\text{target}} Scurrent<Starget),则增大 λ i \lambda_i λi 以鼓励更多权重变小为零;反之则减弱约束。
整体而言, R ( e b ) R(\mathbf e_b) R(eb) 为每个行为 SID 学习可为 0 0 0 的软权重,而 L reg L_{\text{reg}} Lreg 与负载均衡机制保证不同热门程度的 item 拥有合适长度、合适密度的行为 SID 序列:热门 item 得到更丰富的协同刻画,长尾 item 只保留少数高置信度的高层语义 SID。
3. 实验
3.1 主实验
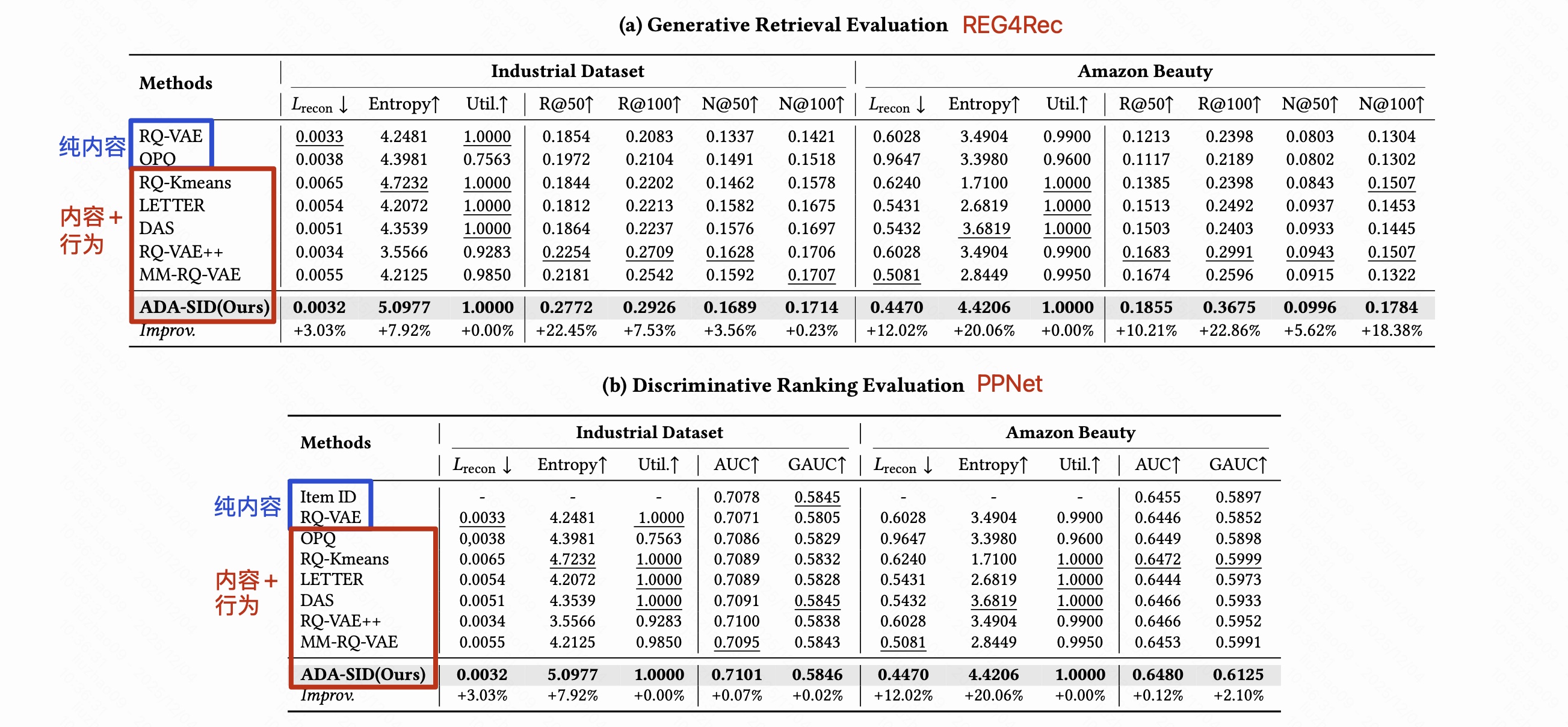
在同一 backbone(REG4Rec / PPNet)下,行为-内容融合 SID 明显优于纯内容 SID,ADA-SID 表现最优
3.2 消融实验

- w/o 2.2.1 没有 Alignment Strength Controller 相当于所有 item 的行为-内容 对齐强度是一样的,这部分对 生成式召回 Recall 影响较大,长尾 item 的 embedding 很多噪声,本该忽略或者弱对齐。
- w/o 2.2.2 没有 Behavior-Content Contrastive Learning,该部分负责把 文本、图像 内容 和 行为 embedding 拉到一个统一的空间,去掉它以后,内容域与行为域之间的模态 gap 没有被显示缩小。
- w/o 2.3.2 没有 Sparsity Regularization,没有稀疏正则,Dynamic Router 会激活更多行为 SID,一方面单个 SID 表示不再那么专注,导致重建误差、多样性都下降,另一方面,从 MoE 角度,稀疏激活可以让每个 code 更专精,整体模型容量变大。去掉后容量下降,所以召回和排序都有一点退步。但该模块影响略小。
- w/o 2.3.1 没有 Behavior-Guided Dynamic Router,动态路由根据行为 embedding 的信息丰富度给每个行为 SID 分配权重,多的激活 head item 的行为 SID,少激活长尾 item 的行为 SID。去掉它相当于行为 SID 全都一视同仁:对 head item 来说,没能额外突出那几个特别重要的行为 SID --> 表达能力打折。对于 tail item 来说,不再特别抑制那些噪声 SID --> 噪声进来。
3.3 超参分析
3.3.1 稀疏正则
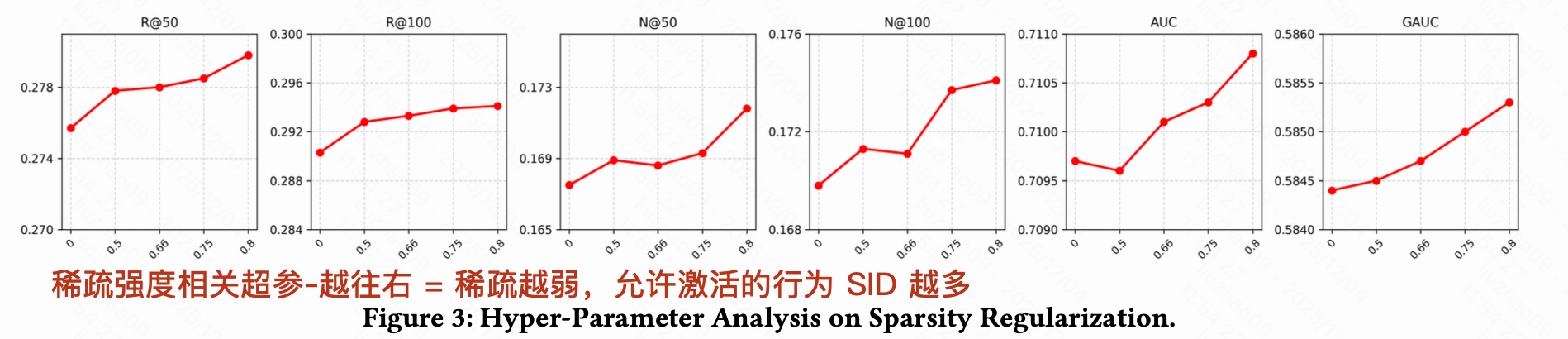
"少稀疏一点",让头部 item 多用几位行为 SID
3.3.2 对齐强度控制
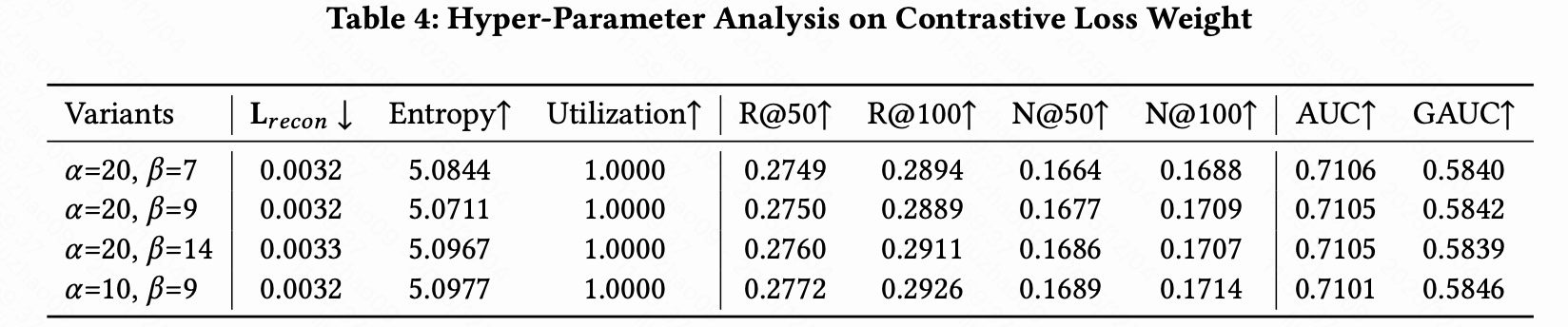
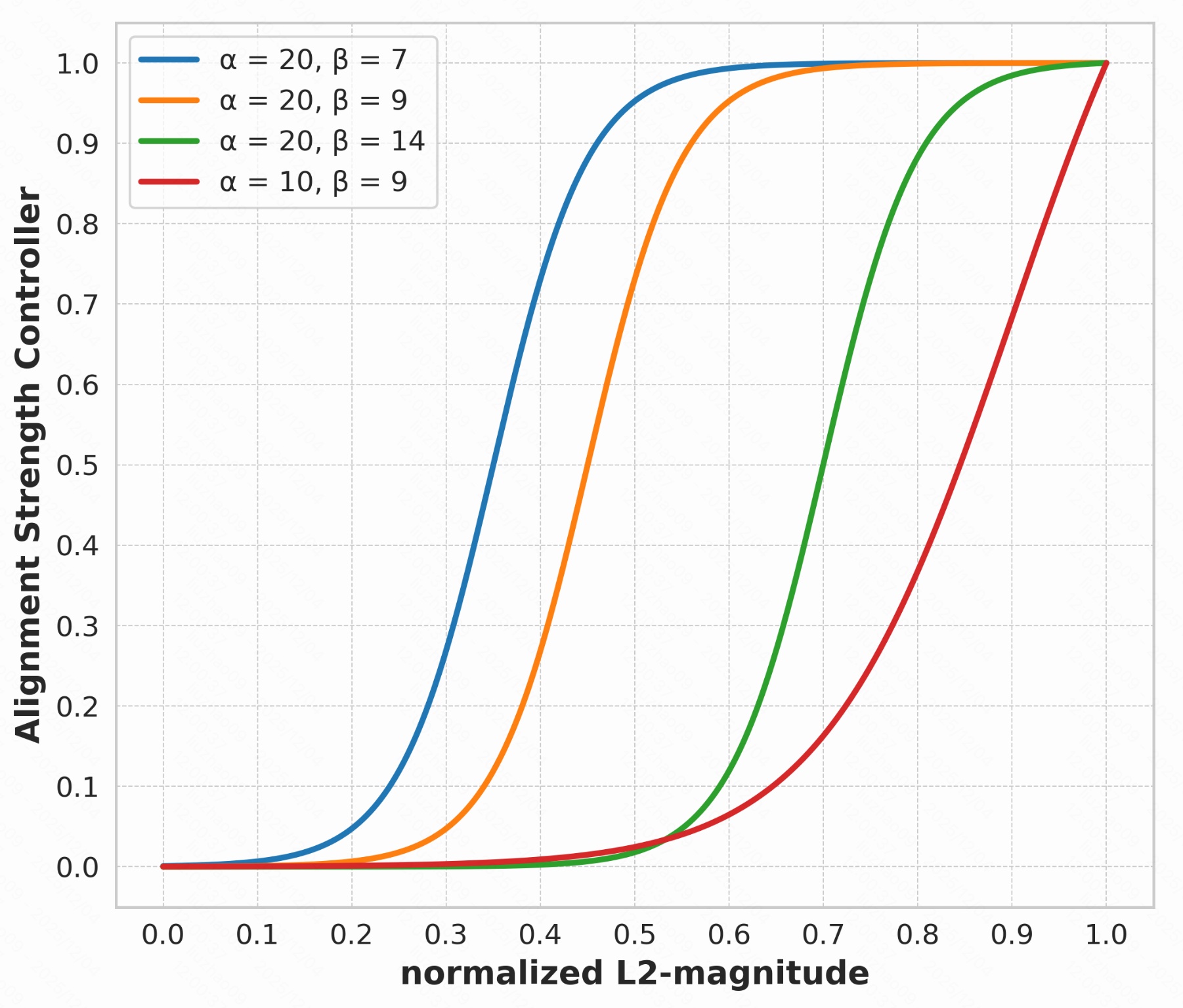
最佳状态:最左边差不多 40% 的 item 对齐权重大多接近 0,中间一段渐进式增加,右边头部 item 权重接近 1。尾部 40% item 就不用行为 embedding 去对齐了。
3.4 按曝光分桶分析
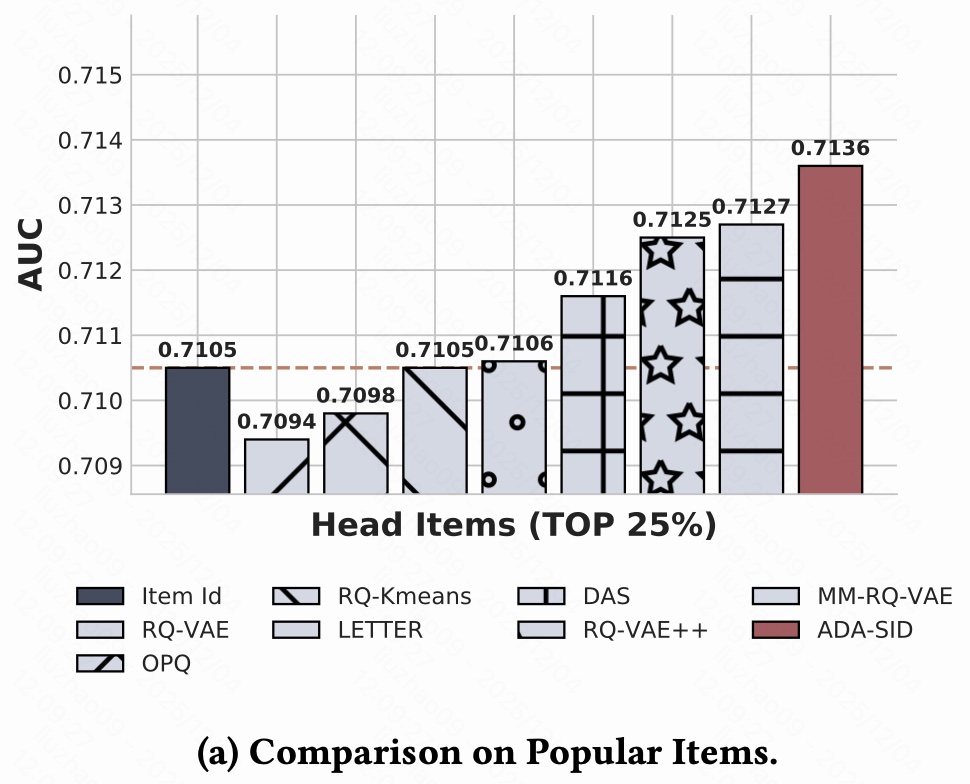
- 传统 "一个 item 一个 ID embedding" 在头部 item 上已经很强,因为这些 item 交互非常多,每个 ID 都能从行为中学到很丰富、很个性化的表示。
- 纯内容 SID(RQ-VAE、OPQ)反而略低于 ItemID。
- 加入行为的 SID(RQ-Kmeans、DAS、LETTER、RQ-VAE++、MM-RQ-VAE)整体都超过了纯内容 SID ,部分方法已经能和 ItemID 打平或略好(0.711x--0.712x):说明 把协同信息融合进 SID 的方向本身是对的,能增强表达能力。
结论:在热门 item 上,光靠内容 SID 不如 ItemID;需要把行为信号好好用起来,而 ADA-SID 是用得最精细、效果最好的一种。
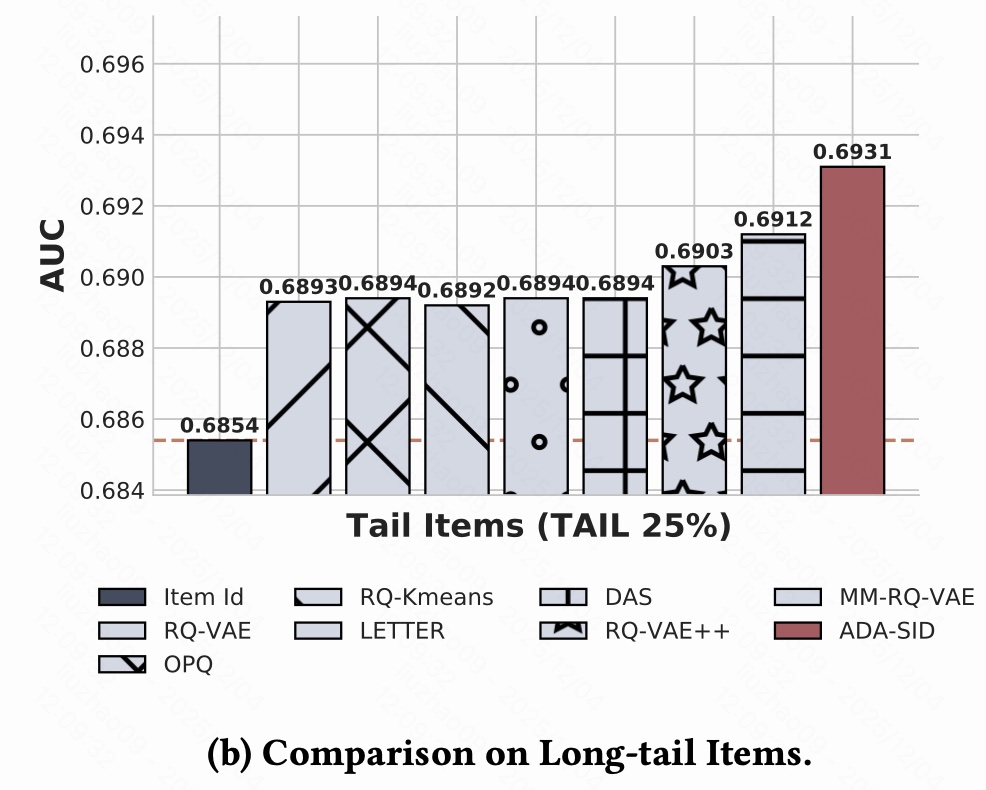
- 长尾 item 交互非常少,单独为每个 ID 学 embedding 会严重欠拟合,所以基于 Item ID 的方法在长尾上明显吃亏。
- 所有 SID-based 方法(RQ-VAE、OPQ、RQ-Kmeans、DAS、LETTER、RQ-VAE++、MM-RQ-VAE)全部显著优于 Item ID,因为 SID 会把很多语义相似的 item 映射到 共享的 code / token ,长尾 item 可以"蹭"到头部/其他 item 的知识,缓解数据稀疏问题。
结论:在长尾 item 上,所有 SID 都比传统 ItemID 好,而 ADA-SID 通过"少信行为,多信内容 + 选关键行为 SID"的策略,把长尾性能进一步推到最高。
4. 总结
感觉直接采用行为 embedding 模长来表示流行度,这个是不是有点不稳定,是不是采用更客观的比如 vv?会更合适?