什么是特征检测?
在计算机视觉中,"特征"(Feature)指的是图像中具有代表性的、可重复检测的局部区域或描述符。特征检测就是从图像中自动找到这些具有"区别性"和"稳定性"的关键点,使得图像能够被机器识别、匹配或跟踪。
通俗理解:
特征就是图像中的"显著点",例如角点、边缘、斑点或局部纹理变化明显的区域。
特征点通常要满足以下条件:
- 可重复性(Repeatability)
在光照变化、旋转、尺度变化下仍可被检测到。 - 独特性(Distinctiveness)
能够与其他点区分开来。 - 局部性(Locality)
描述的是图像局部的小范围区域。 - 高效率(Efficiency)
特征点需能在有限时间内被提取。
OpenCV 中的特征检测包含三个重要步骤:
- 特征点检测(Keypoint Detection)
找到图像中的显著点,例如角点。 - 特征描述(Feature Description)
对每个特征点生成一个数字向量,例如 SIFT、ORB 描述符。 - 特征匹配(Feature Matching)
用暴力匹配(BFMatcher)或 FLANN 寻找两幅图像之间的对应点。
什么是角点?
角点的本质
角点 = 图像中梯度(方向变化)在两个方向上都很大且不同的点。
如果你把图像理解为"山地高度图"(亮度就是高度):
- 边缘(edge):像山脊,只在一个方向上变化明显
- 角点(corner):像山峰或拐角,在两个方向上都剧烈变化
为什么角点重要?
角点具有:
- 可重复性:不同角度、旋转、光照下仍能被检测到
- 定位清晰:位置容易精确到像素级
- 信息足够多:比边缘更有特征性
因此角点常用于:
- 目标跟踪(如 Lucas-Kanade 光流)
- SLAM、三维重建
- 模板匹配
- 图像拼接(全景图)
- 特征匹配(如 Harris、Shi-Tomasi、FAST)
数学视角:角点是二阶梯度矩阵的强响应点
角点检测方法(如 Harris)都基于同一个思想:
计算图像中某个小窗口在移动时,亮度变化是否很大:
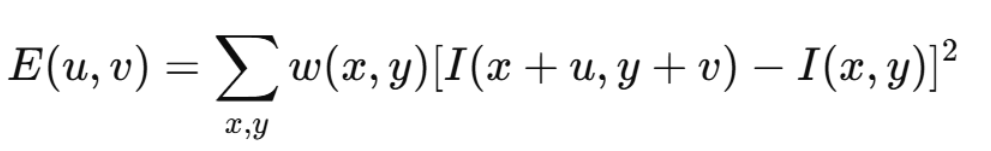
若窗口往任意方向移动都造成很大的亮度变化 → 角点。
这会形成一个 2×2 的矩阵 M:
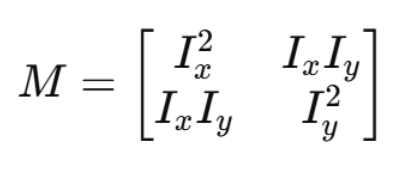
角点特征由它的 特征值 λ₁、λ₂ 决定:
| λ₁ | λ₂ | 点类型 |
|---|---|---|
| 大 | 大 | 角点 |
| 大 | 小 | 边缘 |
| 小 | 小 | 平坦区域 |
OpenCV 常见角点检测函数
| 函数 | 方法 |
|---|---|
cv::goodFeaturesToTrack() |
Shi-Tomasi 角点 |
cv::cornerHarris() |
Harris 角点 |
cv::FAST() |
FAST 高速角点 |
cv::findChessboardCorners() |
棋盘格角点,用于标定 |
特征检测的经典方法
- Harris Corner Detector(哈里斯角点)
- 主要检测角点(灰度变化强烈的点)。
- 对旋转不敏感,对尺度变化不适应。
- 计算速度快,适合实时应用。
- Shi-Tomasi(Good Features to Track)
- Harris 改进版本。
- 在光流跟踪(如 KLT)中用于检测角点。
- SIFT(尺度不变特征变换)
- 具有旋转、尺度不变性。
- 特征描述符信息丰富,匹配效果好。
- 适用于物体识别、图像拼接等。
- 由于专利问题曾从 OpenCV 中移除,但现在已重新开放。
- SURF(加速稳健特征)
- 类似 SIFT,但速度更快。
- 也具有尺度、旋转不变性。
- 因专利原因在 OpenCV-contrib 中。
- ORB(Oriented FAST and Rotated BRIEF)
- 免费且快速的二进制特征描述符。
- 结合 FAST(检测)和 BRIEF(描述)并加入方向信息。
- 非常适用于实时 SLAM、移动端应用。
特征检测方法比较:
| 特征算法 | 速度 | 描述符类型 | 尺度不变性 | 旋转不变性 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| Harris | 快 | 无 | × | × | 计算简单 | 只找角点 |
| Shi-Tomasi | 快 | 无 | × | × | 稳定、适合光流 | 只能检测,不提供描述符 |
| SIFT | 慢 | 128维浮点 | √ | √ | 匹配精度高 | 速度慢 |
| SURF | 较快 | 64/128维 | √ | √ | 性能好 | 需额外模块 |
| ORB | 最快 | 二进制 | 部分 | √ | 开源、高速 | 匹配精度略低 |
应用场景
- 图像配准、拼接(Stitching)
例如全景图生成。 - 运动估计(SLAM)
ORB-SLAM 中用 ORB 特征进行地图构建。 - 目标检测/识别
通过匹配特征位置判断对象是否存在。 - 三维重建
特征点用于多视角几何(Structure from Motion)。 - 光流跟踪
KLT 跟踪需要 Shi-Tomasi 检测角点。
深度学习中的特征检测
什么是深度学习中的特征检测?
在传统视觉中,"特征检测"依赖人为设计的算子(如 Harris、SIFT、ORB),它们通过数学公式提取图像的角点、边缘等局部模式。
而在深度学习(尤其是 CNN)中,特征不是人工定义的,而是通过训练自动学习得到的。
深度学习的"特征检测"本质是:
卷积神经网络(CNN)通过卷积核(Filter)自动学习图像局部特征,从简单边缘到复杂语义结构,形成逐层抽象的表征。
因此,深度学习中的特征检测更加灵活、表达力更强,也更适用于各种视觉任务,如分类、检测、分割等。
深度学习是如何进行特征检测的?
深度学习主要依靠 CNN 的多层结构来完成特征检测,核心机制包括:
1. 卷积(Convolution)层:学习局部特征
卷积核(滤波器)在图像上滑动,提取局部模式。
- 浅层卷积核(前几层)
自动学到边缘、纹理、角点等低级特征。 - 深层卷积核(中层)
学到形状、结构,如:物体边缘、物体局部。 - 最深层卷积核(后几层)
学习高层语义信息,如:眼睛、轮廓、人脸、车轮。
这就是为什么 CNN 能无需人工特征,却在图像任务上表现更好。
2. 激活函数(ReLU):增强非线性特征
特征检测不仅需要线性卷积,还需要非线性激活,如:
- ReLU
- GELU
- LeakyReLU
它们强化复杂特征,使网络能表达更抽象的图像结构。
3. 池化(Pooling)层:提取尺度不变特征
常见池化:
- Max Pooling(最大值池化)
- Average Pooling(平均池化)
作用:
- 提取局部最显著特征
- 增强平移不变性
- 降低特征图大小,提高效率
4. 特征图(Feature Map)表示检测到的特征
每个卷积核会得到一张输出特征图。
例如,一个包含 64 个卷积核的卷积层,会产生 64 张特征图。
这些特征图体现了网络在不同区域"检测"到的不同模式。
5. 端到端学习特征
深度学习特点:
无需为每个任务设计特征,网络在训练过程中自动学习"最有用"的特征。
这彻底区别于传统方法。
深度学习特征检测与传统特征检测的区别
| 比较项目 | 传统特征检测(SIFT/ORB) | 深度学习特征检测(CNN) |
|---|---|---|
| 特征来源 | 人工设计 | 学习得到 |
| 稳定性 | 依赖数学模型 | 可学习、鲁棒性强 |
| 尺度/旋转不变性 | 需要特别设计 | 模型自动学习到 |
| 适用任务 | 多为匹配、跟踪 | 分类、检测、分割、识别等 |
| 适应性 | 固定 | 可通过训练适应场景 |
| 计算量 | 小 | 较大,需要 GPU |
| 表达能力 | 低 | 高级语义特征 |
深度学习的特征更接近人类视觉中的"语义特征"。
深度学习中的特征类型(按深度分层)
1. 低层特征(Low-level Features)
表现为:
- 边缘
- 角点
- 颜色变化
- 纹理
卷积核类似传统滤波器,但自动学习得来。
2. 中层特征(Mid-level Features)
能够检测:
- 局部结构
- 物体部件
- 小区域形状
例如 CNN 中间层常能检测到:
- 车轮形状
- 眼睛形状
- 门框形状
3. 高层特征(High-level Features)
关注语义,如:
- 人脸
- 狗的轮廓
- 汽车
- 物体类型(猫/人/车)
高层特征对于目标识别、检测非常关键。
主流的深度学习特征检测模型
深度学习领域中最典型的特征提取(特征检测)模型包括:
1. CNN 基础模型
- LeNet
- AlexNet
- VGG
- ResNet
- Inception
- EfficientNet
这些模型都通过卷积堆叠学习图像特征。
2. 目标检测模型(2D 特征检测)
用于在图像中检测目标的位置和分类:
- Faster R-CNN
- YOLO 系列(v3/v5/v7/v8/v9)
- SSD
- RetinaNet
这些模型不仅检测特征,还定位特征区域。
3. 特征提取网络(Backbone)
如:
- ResNet50
- MobileNet
- CSPDarkNet(YOLO 用)
网络前几层负责特征检测,是核心组件。
4. Transformer 模型(ViT、Swin)
Transformer 也能进行特征检测,不过方式是:
- 将图像切成 patch
- 使用自注意力机制(Self-Attention)检测特征关系
这些模型已经逐渐超越传统 CNN。
深度学习特征检测具有哪些优势?
1. 不需要人工设计(自动学习)
比人工特征稳健很多。
2. 具有强大的表达能力
能够检测复杂模式,比如脸、动物、场景结构等。
3. 可迁移(Transfer)
在大规模数据(ImageNet)上学到的特征可以迁移到其他任务。
4. 对旋转、尺度、光照更稳健
深层网络天然具有某种不变性。
总结
特征检测是计算机视觉中非常基础但又极其重要的技术。OpenCV 提供丰富的检测器与描述符:
- 经典角点检测:Harris / Shi-Tomasi
- 尺度不变特征:SIFT / SURF
- 高速特征提取:ORB / BRIEF / BRISK
特征检测的核心作用是:
帮助机器从图像中找到可识别的 "关键点",进而实现匹配、识别、跟踪和重建等更高级功能。