目录
[一. 服务器设计流程](#一. 服务器设计流程)
[二. http协议](#二. http协议)
[2.1 URL网址](#2.1 URL网址)
[2.2 http请求Request](#2.2 http请求Request)
[2.3 http响应Response](#2.3 http响应Response)
[2.4 细节补充](#2.4 细节补充)
[三. 代码验证](#三. 代码验证)
[3.1 发送简单HTTP响应](#3.1 发送简单HTTP响应)
[四. GET/POST方法获取数据](#四. GET/POST方法获取数据)
一. 服务器设计流程
我们知道,OSI七层网络模型为:物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。**而我们网络编程一般是从传输层开始的。**具体过程如下:
服务器:socket,bind,listen,accept,recv,协议解析与数据处理,send, close。
客户端:socket,connect(系统自行bind),send,recv接收响应,close。
这些接口在网络模型哪些层工作呢?
传输层:负责两个节点之间的数据传输,如有需要,可以保证可靠性。包含接口是 socke,read,write,recv,send。bind,listen,connect,accept。
会话层:负责两个节点之间建立和断开连接:连接,会话等管理
表示层:负责设计数据和网络数据之间的转换:序列化,反序列化,加密解密等。
应用层:负责特定的应用层协议:协议解析,http/https,ssh等具体协议
二. http协议
http是超文本传输协议,服务器提供客户端可以访问资源的路径,其他用户通过url网址和http协议获取/访问/我们开放的资源,也能提交/更新/删除资源和数据。
2.1 URL网址

使用 ip+端口确实能够访问我们的服务器,但是不太容易记忆。为了方便用户和客户端解析。客户端通过URL网址来访问服务器资源。
https:协议名称
bolg.csdn.net:域名,通过DNS解析为ip地址
yzcllzx?type=blog:表示我们访问的资源,即服务器的某一个文件路径。
为何不需要端口呢?因为http和https已经固定好端口了(http:80 https:443)
2.2 http请求Request
http响应是浏览器/客户端向服务器发起的。格式如下:
bash
//第一部分是请求行,包含多种请求方法
请求方法(GET/POST) url http版本(1.0 1.1 2.0 3.0)\r\n
//第二部分是请求报头,包含多行kv字段,由:分割。末尾以\r\n结尾
name1: value1\r\n
name2: value2\r\n
name3: value3\r\n
name4: value4\r\n
//第三部分是一个空行,表示请求头部结束
\r\n
//第四部分是请求的正文,可以没有正文,也可以是由客户端发送的请求数据,有正文,第二部分就有正文长度
username="yzc"&password="123456"2.3 http响应Response
http响应是由服务器返回给客户端的,最终在浏览器显示的资源
bash
//响应的第一部分是一个状态行
http版本 状态码 状态码描述\r\n
//第二部分是响应头部,和请求一样由多个kv表示
name1: value1\r\n
name2: value2\r\n
name3: value3\r\n
name4: value4\r\n
//第三部分是空行,表示头部结束
\r\n
//第四部分是响应的正文部分,包含服务器返回的资源
html/css/js/视频/音频/文本/数据/图片...2.4 细节补充
http状态码:
|-----|----------|-------------|
| | 类别 | 说明 |
| 1xx | 信息性状状态码 | 表示服务器正在处理请求 |
| 2xx | 成功状态码 | 表示服务器正常处理完毕 |
| 3xx | 重定向状态码 | 需要附加操作完成请求 |
| 4xx | 客户端错误状态码 | 服务器无法处理请求 |
| 5xx | 服务端错误状态码 | 服务器处理请求出错 |
http常见头部
|----------------|----------------------|
| Content-Type | 数据的类型 |
| Content-Length | 数据的长度 |
| Host | 告知客户端访问资源的端口 |
| User-Agent | 客户端声明自己的软件/操作系统等信息 |
| referer | 这个页面是从哪一个页面跳转过来 |
| location | 与状态码3xx联合使用,表示跳转的为位置 |
| Cookie | 用于客户端存储少量信息,可以实现会话 |
http常见方法
主要方法如下表
|--------|--------|
| GET | 用于获取资源 |
| POST | 传输实体主体 |
| PUT | 传输文件 |
| DELETE | 删除文件 |
还有其他方法比如:HEAD,OPTIONS,TRACE,CONNECT,LINK,UNLINK
1 HTTP请求/响应是如何做到序列化和反序列化的?
可以直接使用库处理,或者使用第三方库
2 如何保证读取一个完整的请求。响应?
while循环读取一行数据(\r\n结尾),如果读到空行表示请求。响应头部读取完毕了。然后根据头部的一个字段Content-Length来读取正文。这样就能实现读取一个完整的响应,请求
三. 代码验证
首先拿到我们之前的reactorTCP服务器代码:ReactorTCP服务器代码
这里我们直接将客户端的信息进行打印返回
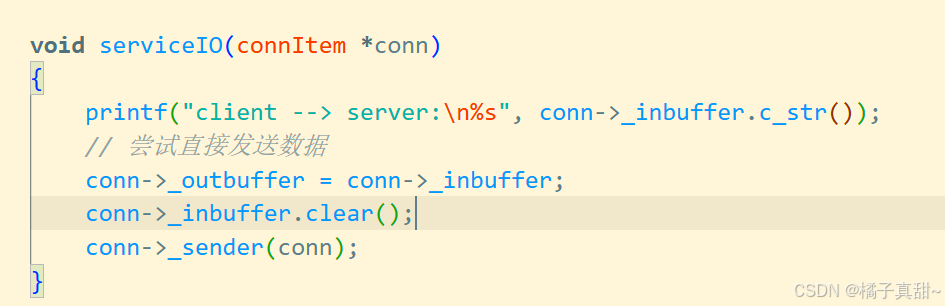
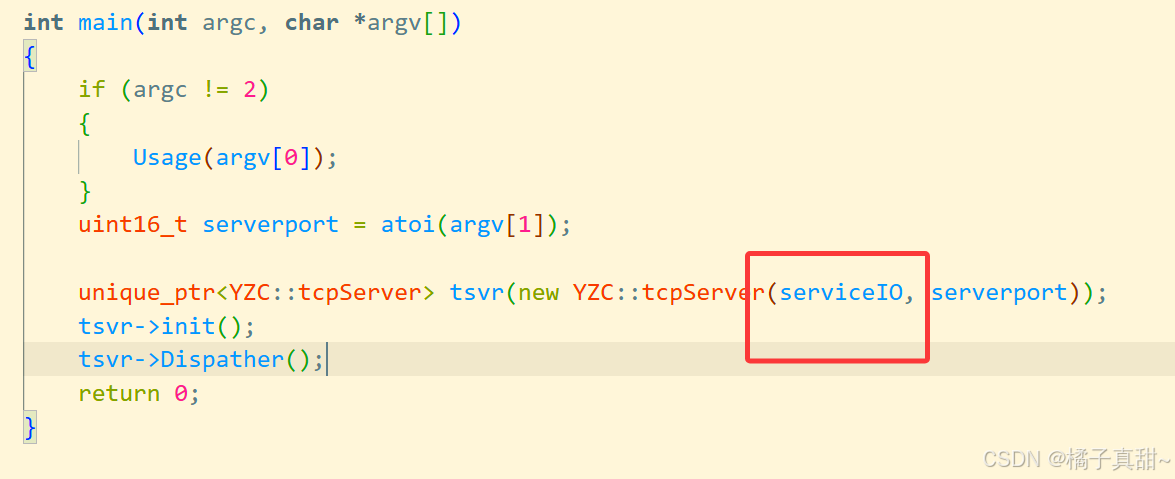
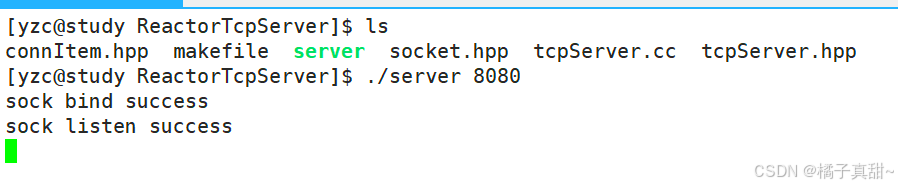
收到的HTTP请求如下:

cpp
GET / HTTP/1.1
Host: 47.105.37.157:8080
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
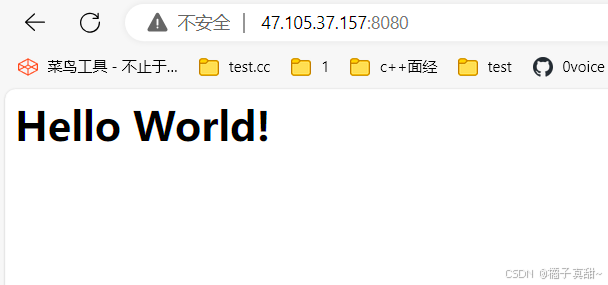
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.63.1 发送简单HTTP响应
cpp
void serviceHTTP(connItem *conn)
{
printf("client --> server:\n%s", conn->_inbuffer.c_str());
conn->_inbuffer.clear();
// 这里仅做简单的数据收发
std::string body = "<h1>Hello World!</h1>";
// 响应行
conn->_outbuffer = "HTTP/1.1 200 OK\r\n";
// 响应头
conn->_outbuffer += "Content-Type: text/html; charset=utf-8\r\n";
conn->_outbuffer += ("Content-Length: " + std::to_string(body.size()) + "\r\n");
// 响应空行
conn->_outbuffer += "\r\n";
// 响应主体
conn->_outbuffer += body;
// 无脑向客户端发送一个简单http响应
conn->_sender(conn);
}
四. GET/POST方法获取数据
GET是用于获取服务器指定路径资源的方法。如果需要提交数据,GET是通过拼接的方式将参数添加到指定目录的末尾。服务端通过解析获取客户端提交的数据。GET方法提交参数不能过长,并且隐私性并不是很好
如果使用POST方法,则是将参数提交到请求的正文中。服务端解析正文获取数据。这种方式能够提交更大的数据 甚至可以是其他的内容(比如图片,视频,大型文档)并且隐私性更好
但是这两种方式传输数据都是不安全的 。想要安全必须使用HTTPS