FlowBench:重访与基准测试LLM-based Agents的工作流引导规划
今天,我们来聊聊一篇来自EMNLP 2024的论文:《FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents》。这篇工作由浙江大学和阿里巴巴的研究者联合完成,针对LLM-based Agents在复杂任务规划中的"幻觉"问题,提出首个全面的工作流引导规划基准测试。面对当前Agent研究领域的快速发展,这项工作为我们提供了宝贵的洞见和工具。如果你是从事LLM代理规划、知识增强或多模态表示的研究者,这篇论文绝对值得一读。下面,我将从背景、核心贡献、基准设计、评估框架和实验启示几个部分,带你快速过一遍。
LLM Agents规划的痛点:幻觉与知识缺失
LLM-based Agents近年来如雨后春笋般涌现,它们通过迭代规划和行动来处理复杂任务,比如软件开发、网络导航或医疗支持(参考Wang et al., 2024; Hong et al., 2023)。然而,正如论文所指出的,这些Agents在知识密集型任务中容易出现"规划幻觉"(planning hallucinations)------即生成与任务知识冲突的不可控行动。这不仅源于LLM参数知识的局限性,还因为缺乏可靠的外部指导。
为了缓解这一问题,研究者们尝试引入工作流相关知识(workflow-related knowledge),如自然语言描述的行动规则(Zhu et al., 2024)或Python代码表示的控制流(Ye et al., 2023)。这些初步努力虽有成效,但知识表示形式杂乱(文本、代码、图表等),缺乏系统化形式化和全面比较。论文正是从这里切入:如何正式化不同格式的工作流知识,并通过基准测试评估其对Agents规划的提升?
FlowBench的核心创新:首个工作流引导规划基准
FlowBench是论文的最大亮点,它是首个针对工作流引导代理规划的全面基准,覆盖6个领域、22个角色、51个场景,支持文本、代码和流程图三种知识格式。不同于PlanBench(Valmeekam et al., 2023)或KnowAgent(Zhu et al., 2024)等现有基准(见下表),FlowBench强调多轮用户-代理交互、多格式知识和真实场景模拟。
| 基准名称 | 领域 | 目的 | 工作流知识 | 多轮交互 | 用户交互 |
|---|---|---|---|---|---|
| PlanBench | 物流、Blocks world | 脚本生成 | ✗ | ✗ | ✗ |
| TravelAgent | 旅行 | 旅行计划生成 | ✗ | ✗ | ✗ |
| KnowAgent | QA、文本游戏 | 在线任务规划 | 文本 | ✓ | ✗ |
| ProAgent | 机器人过程自动化 | 在线任务规划 | 代码 | ✓ | ✗ |
| FlowBench | 6领域、22角色、51场景 | 在线任务规划 | 文本、代码、流程图 | ✓ | ✓ |
FlowBench的构建采用顶层多级层次结构(领域 → 角色 → 场景 → 知识库),数据统计见下表,总计536个会话、5313个回合,覆盖客户服务、个人助理等真实应用。
| 领域 | 角色 | 场景 | 会话 | 回合 |
|---|---|---|---|---|
| 客户服务 | 4 | 12 | 114 | 1167 |
| 个人助理 | 3 | 7 | 92 | 821 |
| 电商推荐 | 2 | 5 | 32 | 330 |
| 旅行&交通 | 4 | 9 | 135 | 1421 |
| 物流解决方案 | 3 | 6 | 61 | 521 |
| 机器人过程自动化 | 6 | 12 | 102 | 1053 |
| 总计 | 22 | 51 | 536 | 5313 |
基准构建三阶段:从任务到交互
-
任务收集:从现有工作(如Mosig et al., 2020)扩展,聚焦个人和企业场景。6大领域包括客户服务(预约、售后)、电商推荐(产品发现)、RPA(业务自动化)等,确保多样性和覆盖率。
-
工作流组织:不靠脑暴,而是参考专业语料(如WikiHow、Zapier)和搜索引擎。先生成自然语言文档,经人工验证正确性、完整性;再用GPT-4转换为代码(Python伪代码)和流程图(Mermaid标记),保持知识一致性。同时定义工具调用(GPT-4函数调用格式),包括输入/输出参数。
-
交互会话生成:用GPT-4生成多样用户画像(背景、目标、语气),注入闲聊等"噪声"模拟真实性。采用人-LLM协作标注:人类起草意图/行动,LLM润色响应,确保地道性。全程多轮人工验证。
这种管道确保了基准的覆盖性、难度和专家级标注,特别支持跨场景切换和多轮对话。
工作流形式化:文本、代码与流程图的权衡

论文首先回顾并形式化三种工作流表示(见图1):
- 文本:自然语言文档,表达力强但token消耗高、歧义多。
- 代码:编程规范(如Python),精确高效,但需编码技能编辑。
- 流程图:低代码可视化(如Mermaid),平衡表达力和用户友好,支持直观编辑。
形式化后,论文提出"FlowAgent"框架:代理Mθ\mathcal{M}\thetaMθ在多轮交互中,利用历史Hi\mathcal{H}iHi和知识库B\mathcal{B}B生成行动ai+1a{i+1}ai+1和回复ri+1r{i+1}ri+1(公式1)。这扩展了传统单次输入假设,更贴合在线规划。
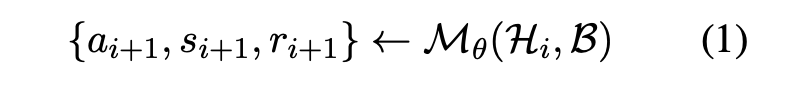
评估框架:多粒度、多意识的全面剖析
FlowBench的评估框架是另一大亮点,分任务意识 和评估协议两维:
-
任务意识:
- 单场景:预知场景,测试单一工作流利用。
- 跨场景:未知具体场景,测试灵活切换(覆盖角色所有知识)。
-
评估协议 (见图2右):
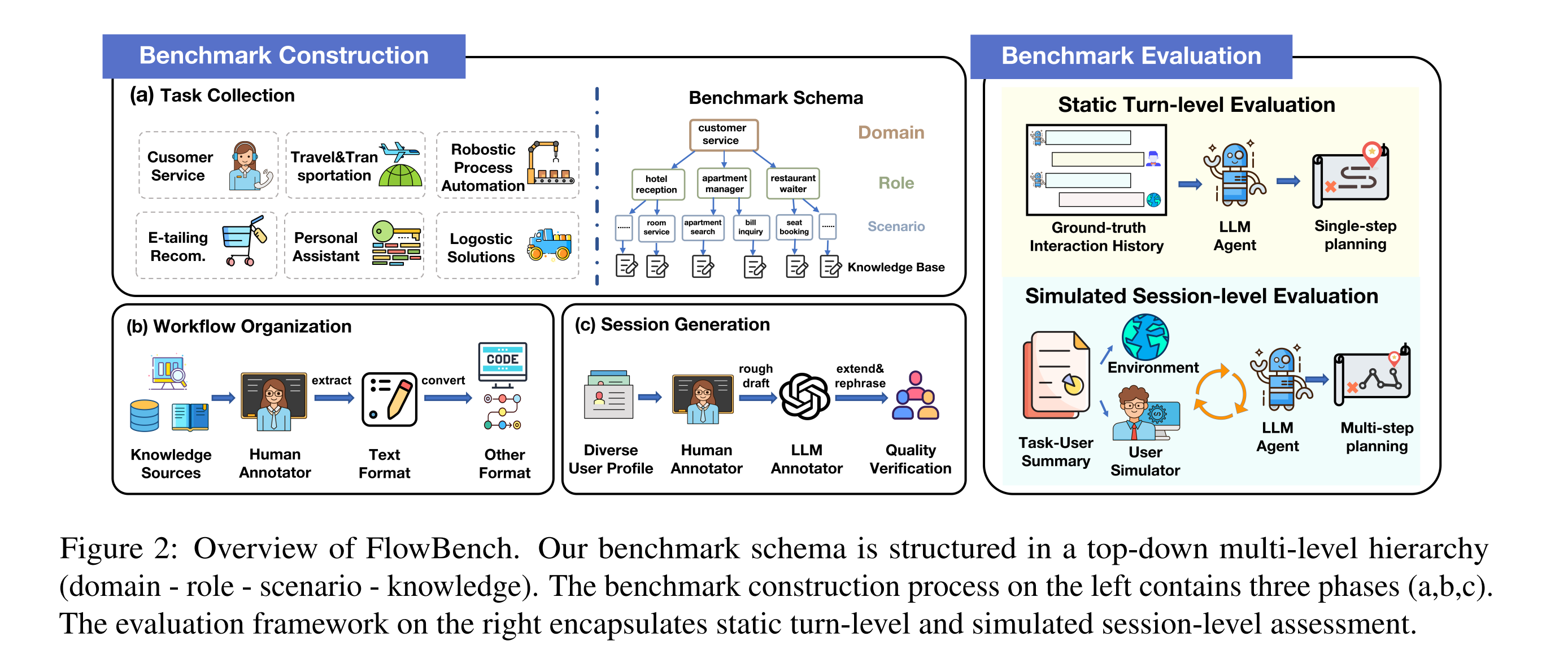
- 静态回合级:基于ground-truth会话,逐回合评估行动/响应匹配(工具调用、参数、回复的P/R/F1)。
- 模拟会话级:用GPT-4模拟用户(基于会话蒸馏的任务-用户摘要),评估序列规划成功率。
这种设计避免了传统基准的局限,支持可靠比较。
实验结果:流程图胜出,LLM仍有差距
论文评估了GPT-4o、GPT-4-Turbo、GPT-3.5-Turbo三种LLM(静态回合级结果见表3)。关键发现:
- 无知识时,成功率仅43.2%~40.9%,凸显规划挑战。
- 知识注入提升明显,流程图格式最佳(单场景F1达75.5%,跨场景63.7%),在效能、适应性和友好性间取得最佳平衡。
- GPT-4o整体领先,但跨场景下仍需改进(成功率<50%)。
这些结果揭示:当前Agents对结构化知识的利用仍有瓶颈,未来可探索混合格式或多代理协作。
| 模型 | 格式 | 单场景工具F1 | 单场景总体F1 | 跨场景工具F1 | 跨场景总体F1 |
|---|---|---|---|---|---|
| GPT-4o | 无 | 66.3 | 76.5 | 55.4 | 70.8 |
| 文本 | 69.1 | 77.2 | 59.9 | 71.0 | |
| 代码 | 69.0 | 78.3 | 58.2 | 70.7 | |
| 流程图 | 75.5 | 80.9 | 63.7 | 72.2 |
结语:为Agent规划研究铺路
FlowBench的贡献在于:(1)系统形式化工作流知识;(2)构建首个多格式、多交互基准;(3)提供全面评估框架,并揭示流程图的潜力。这不仅挑战现有LLM设计,还为知识增强、规划优化指明方向。论文数据和代码已在GitHub开源(https://github.com/Justherozen/FlowBench),强烈推荐大家下载实验,欢迎在评论区分享你的benchmark体验!
FlowBench 与其他 Agent 测试基准的差异分析
FlowBench 是 EMNLP 2024 的一篇论文提出的首个工作流引导规划基准,专为评估 LLM-based Agents 在复杂任务中的规划能力而设计。它覆盖 6 个领域、22 个角色和 51 个场景,支持多格式知识输入和多轮交互。 与其他 Agent 测试基准(如 PlanBench、AgentBench、KnowAgent、ProAgent)相比,FlowBench 在输入格式、评估框架、多轮交互、用户参与以及覆盖范围等方面有显著不同。这些差异使 FlowBench 更贴近真实世界应用,尤其在处理知识密集型任务时。下面我从几个关键维度详细比较,重点突出"文本内容输入"等方面的独特性。
1. 输入格式:多模态知识 vs 单一文本主导
- FlowBench 的独特之处 :输入不仅限于纯文本,还支持三种工作流知识格式------文本(自然语言文档) 、代码(Python 伪代码) 和 流程图(Mermaid 标记的可视化图表)。代理在规划时,会接收交互历史(包括用户输入、环境反馈和历史行动/回复)、任务描述,以及这些多格式知识库。例如,文本格式灵活表达复杂概念,但易歧义;代码格式精确高效;流程图则平衡可视化和编辑友好性。这种多格式设计允许代理在不同抽象层级上利用知识,减少规划幻觉(hallucinations)。
- 与其他基准的差异 :
- PlanBench 和 AgentBench:主要依赖单一文本输入,如任务脚本或环境描述(e.g., 物流或 OS 操作),无结构化工作流知识。输入更侧重静态任务提示,缺乏代码/图表等符号化表示,导致代理难以处理条件分支或工具调用序列。
- KnowAgent:仅支持文本格式知识(e.g., 行动规则描述),输入类似 FlowBench 的自然语言,但无代码/流程图,无法评估结构化知识的效能。
- ProAgent:引入代码格式(Python 控制流),但仅限于单一格式,输入不包括可视化图表,且覆盖领域狭窄(仅 RPA)。
- 文本内容输入的具体不同:FlowBench 的文本输入更动态,嵌入多轮对话历史和用户意图(如背景、目标、语气),而非孤立的单次提示。这模拟真实交互,避免了其他基准中常见的"非交互假设"(e.g., 一次性完整任务描述),使输入更长、更上下文依赖(平均 5313 个回合数据)。
2. 评估框架:多粒度动态 vs 静态单一
- FlowBench :采用双层框架------静态回合级 (逐转评估工具调用、参数、回复的 P/R/F1)和 模拟会话级 (用 GPT-4 模拟用户,评估序列规划成功率)。还分单场景 (预知任务)和跨场景(灵活切换知识),支持真实多轮模拟。
- 与其他基准的差异 :
- PlanBench:静态评估,焦点在脚本生成准确率,无动态模拟或跨场景切换。
- AgentBench:多环境(8 个,如 OS、数据库),但评估偏静态,强调单任务决策,无工作流格式比较。
- KnowAgent 和 ProAgent:支持在线规划评估,但缺乏会话级模拟,仅评估单一格式知识的 turn-level 性能。
- 启示:FlowBench 的评估更全面,能揭示 LLM 在长序列规划中的瓶颈(e.g., GPT-4o 跨场景成功率仅 40.9%),而其他基准多停留在"最终输出"层面。
3. 多轮交互与用户参与:真实对话 vs 自动化环境
- FlowBench :强调多轮用户-代理交互,输入包括用户渐进式修改需求(e.g., 闲聊注入噪声模拟真实性),代理需生成行动计划 + 对话回复。用户参与是核心,支持协作标注生成数据。
- 与其他基准的差异 :
- PlanBench 和 TravelAgent:无多轮交互,用户参与为 ✗,输入为一次性任务,无对话历史。
- AgentBench:有交互环境(5-50 转),但用户模拟自动化,非真实人类-like 参与。
- KnowAgent 和 ProAgent:支持多轮,但无用户(✗),输入更像代理-环境循环,而非用户驱动。
- 文本内容输入的影响:FlowBench 的输入文本更"对话化"(e.g., 包含语气、意图迭代),这增加了难度,但更真实;其他基准的文本输入往往是结构化指令,忽略用户动态反馈。
4. 覆盖范围:广域多角色 vs 窄域特定
- FlowBench:6 领域(客户服务、旅行、RPA 等)、22 角色、51 场景,总 536 会话/5313 回合,聚焦工作流密集任务。
- 与其他基准的差异 :
- PlanBench:仅物流/Blocks world,少场景,无角色多样。
- AgentBench:8 环境,但偏技术任务(e.g., 数据库),无领域角色划分。
- KnowAgent :QA/游戏,场景有限;ProAgent:仅 RPA,角色单一。
- 输入相关:FlowBench 的知识库(背景 + 工作流 + 工具)更全面,文本输入覆盖企业/个人场景,而其他多限于学术/模拟环境。
总结与启示
FlowBench 的核心创新在于将工作流知识形式化并多模态化,使输入从"纯文本任务描述"转向"交互 + 结构知识"的混合形式,这大大提升了代理规划的可靠性和实用性。 相比其他基准,它解决了"幻觉"和"非交互"痛点,但也更具挑战(e.g., 流程图格式性能最佳)。如果你在 Agent 研究中测试规划能力,推荐从 FlowBench 的 GitHub 数据集起步(https://github.com/Justherozen/FlowBench)。
FlowBench 的评估方法详解:结合源代码的实现指南
FlowBench 是 EMNLP 2024 论文《FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents》提出的首个工作流引导代理规划基准,旨在评估 LLM-based Agents 在知识密集型任务中的规划可靠性。论文中定义了多粒度评估框架,包括静态回合级(turn-level)评估 (聚焦单步规划)和模拟会话级(session-level)评估 (模拟序列规划),并区分单场景 (预知任务)和跨场景(灵活切换)设置。这些评估通过多格式工作流知识(文本、代码、流程图)注入代理,帮助量化规划幻觉的缓解效果。
下面,我结合 FlowBench 的源代码仓库(https://github.com/Justherozen/FlowBench)解释评估过程。仓库采用模块化设计,核心评估代码分布在 turn_level/ 和 session_level/ 目录下,使用 Python 脚本实现推理、模拟和指标计算。评估依赖 OpenAI API(需配置 utils/keys.json 中的 API 密钥)和数据文件(data/ 目录下的 turn_data/ 和 session_data/,包含 ground-truth 会话、知识库 knowledge.json)。整个过程无需额外安装包(依赖 requirements.txt 中的库,如 openai、pandas),支持 GPT-4o 等 LLM。
1. 总体评估流程概述
-
准备环境:
- 克隆仓库:
git clone https://github.com/Justherozen/FlowBench.git。 - 安装依赖:
pip install -r requirements.txt。 - 配置 API 密钥:在
utils/keys.json中添加 OpenAI key(用于 LLM 生成和判断)。 - 数据加载:基准数据(536 个会话、5313 个回合)已预置在
data/,包括多格式知识(文本/代码/流程图)和 ground-truth 交互历史。
- 克隆仓库:
-
评估维度 (论文公式1):代理 Mθ\mathcal{M}\thetaMθ 在多轮交互中,利用历史 Hi\mathcal{H}iHi 和知识库 B\mathcal{B}B 生成行动 ai+1a{i+1}ai+1 和回复 ri+1r{i+1}ri+1。指标包括工具调用(P/R/F1)、参数正确性、响应质量和整体成功率。
-
运行原则:评估分两阶段------生成预测(inference/simulation),然后计算指标(metric display)。支持单/跨场景,通过命令行参数切换知识格式。
2. 静态回合级(Turn-Level)评估:单步规划的精确匹配
Turn-level 评估基于 ground-truth 会话,逐回合比较代理预测与参考答案,聚焦工具调用、参数和响应。适合评估知识注入的即时效果(如表3所示,流程图格式 F1 最高达 75.5%)。
源代码实现 (turn_level/ 目录):
- 核心脚本 :
-
turn_inference.py:生成单转预测。-
关键功能 :加载输入文件夹(
--input_path,含交互历史和知识),调用 LLM(如 GPT-4o)生成行动/响应,输出到--output_path。内部使用提示模板注入工作流知识(e.g., "Based on the flowchart: Mermaid code, plan the next action.")。 -
伪代码逻辑 (基于仓库描述):
pythonimport openai # 从 keys.json 加载 API def generate_turn_prediction(history, knowledge_format): prompt = f"History: {history}\nKnowledge ({knowledge_format}): {knowledge}\nPlan next action:" response = openai.ChatCompletion.create(model="gpt-4o", messages=[{"role": "user", "content": prompt}]) return parse_action_and_reply(response) # 解析工具调用、参数、回复 # 批量处理:for turn in input_data: save to output -
运行命令 :
python ./turn_level/turn_inference.py --input_path data/turn_data/single_scenario --output_path outputs/turn_predictions --model gpt-4o --knowledge_format flowchart- 参数:
--model指定 LLM,--knowledge_format选 text/code/flowchart;单/跨场景通过输入路径区分(e.g.,single_scenariovscross_scenario)。
- 参数:
-
-
turn_metric_display.py:计算并显示指标。-
关键功能:加载预测输出和 ground-truth,计算精确率(P)、召回率(R)、F1(工具/参数/响应),并聚合显示(e.g., 表格输出)。使用字符串匹配或 LLM 判断响应质量。
-
伪代码逻辑 :
pythonfrom sklearn.metrics import precision_recall_fscore_support def compute_metrics(preds, gts): tool_p, tool_r, tool_f1, _ = precision_recall_fscore_support(gts['tools'], preds['tools'], average='macro') # 类似计算参数和响应(可能用 LLM score: "Rate correctness 0-10") return {'Tool F1': tool_f1, 'Overall Score': avg_score} # 显示:print table or save to CSV -
运行命令 :
python ./turn_level/turn_metric_display.py --output_path outputs/turn_predictions- 输出:控制台表格(如论文表3),显示单/跨场景的 F1 分数。
-
-
评估步骤:
- 准备输入:从
data/turn_data/加载会话片段(e.g., 前 i-1 转历史)。 - 生成预测:运行 inference,注入知识格式。
- 计算指标:运行 metric display,比较 a^i,r^i\hat{a}_i, \hat{r}_ia^i,r^i 与 ai,ria_i, r_iai,ri。
- 结果分析:GPT-4o 在流程图下单场景工具 F1 为 75.5%,证明结构化知识提升精确性。
3. 模拟会话级(Session-Level)评估:序列规划的端到端成功率
Session-level 评估模拟真实多轮交互,使用 GPT-4 作为用户模拟器,评估整个任务完成度(成功率 40.9%~43.2%)。更贴合在线规划,处理用户迭代需求和跨场景切换。
源代码实现 (session_level/ 目录):
- 核心脚本 :
-
session_simulate.py:模拟和评估会话,支持双模式。-
关键功能 :
simulate模式:从用户画像(背景、目标、语气)生成多转会话,代理使用知识规划行动,环境反馈(e.g., 工具执行结果)驱动下一转。注入噪声(如闲聊)模拟真实性。eval模式:基于模拟输出,计算成功率(e.g., 任务目标达成)。- 配置 LLM:代理生成(gpt-4o)、判断(gpt-4,用于评分)、用户模拟(gpt-4,基于蒸馏摘要)。
-
伪代码逻辑 (仓库核心):
pythondef simulate_session(user_profile, knowledge): session = [] # 存储 {user_input, agent_action, reply, env_feedback} for turn in range(max_turns): user_input = gpt_user_simulator(profile, history) # GPT-4 模拟用户 agent_prompt = f"History: {history}\nKnowledge: {knowledge}\nUser: {user_input}\nPlan:" action, reply = gpt_agent(history, agent_prompt) # 解析行动/回复 feedback = env_simulator(action) # 模拟工具/环境 session.append({'turn': turn, 'action': action, 'reply': reply, 'feedback': feedback}) if task_complete(session): break return session def eval_session(session, gt_summary): success_rate = gpt_judge(session, "Did the agent complete the task? 0/1") # LLM 判断 # 额外指标:workflow adherence, response fluency return {'Success Rate': success_rate, 'Overall': avg_metrics} # 运行:if mode=='simulate': generate; elif 'eval': compute -
运行命令 :
- 模拟:
python ./session_level/session_simulate.py --mode simulate --input_path data/session_data --output_path outputs/session_transcripts --model gpt-4o --knowledge_format code - 评估:
python ./session_level/session_simulate.py --mode eval --input_path data/session_data --output_path outputs/session_transcripts --eval_path outputs/session_evals
- 模拟:
-
-
session_metric_display.py:汇总指标。- 关键功能:聚合跨场景成功率,输出表格/Excel(e.g., 按领域/角色分)。
- 运行命令 :
python ./session_level/session_metric_display.py --eval_path outputs/session_evals - 输出:类似表3 的扩展版,显示 51 场景的平均成功率。
-
评估步骤:
- 准备输入:从
data/session_data/加载用户画像和知识库。 - 模拟会话:运行 simulate 模式,生成 T 转序列(T 动态结束)。
- 评估成功:运行 eval 模式,用 LLM 判断任务达成(基于 gt_summary:任务背景、目标、工具)。
- 结果分析:跨场景下,知识注入提升 5%~10%,但 GPT-4o 仍仅 40.9%,暴露长序列瓶颈。
4. 评估结果与启示
- 指标计算:Turn-level 用 P/R/F1(工具/参数/响应);Session-level 用成功率 + LLM 评分。代码支持 Excel 导出,便于比较不同 LLM/格式。
- 单/跨场景切换 :通过
--input_path指定(e.g.,cross_scenario加载全角色知识,测试灵活性)。 - 挑战与优化:源代码强调人工验证(构建时用),运行时需监控 token 消耗。未来可扩展多代理或自定义 LLM。
通过这些脚本,FlowBench 实现了论文的"整体评估框架",从静态匹配到动态模拟,确保可靠比较。仓库开源,建议直接运行实验验证(如 GPT-4o + 流程图)。
FlowBench 中跨场景评估(Cross-Scenario Evaluation)的细节解释
FlowBench 是 EMNLP 2024 论文《FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents》提出的工作流引导代理规划基准,其评估框架(Section 4.3)设计为多面化、整体性的结构,旨在可靠评估 LLM-based Agents 在不同任务意识(Task Awareness)下的规划能力。评估场景根据"任务场景是否预知"分为单场景评估(Single-Scenario Evaluation)和跨场景评估(Cross-Scenario Evaluation) 。下面,我聚焦于跨场景评估的细节解释,基于论文的描述(主要见 Section 4.3.1 和 4.3.2),结合基准设计和实验结果,帮助你理解其核心机制、实现方式及意义。跨场景评估更贴近真实世界的不确定性,测试代理的灵活性和泛化能力。
1. 跨场景评估的核心设定:任务未知下的灵活切换
-
定义与假设(Section 4.3.1 Task Awareness):
- 与单场景评估(预知具体任务场景,提供单一场景的工作流知识,仅限于该场景内导航、规划和执行行动)不同,跨场景评估假设特定任务场景未知。
- 代理角色(e.g., 公寓经理)被配备一个通用工作流知识集 (versatile set of workflow knowledge),覆盖该角色范围内的所有相关场景(e.g., 公寓经理可能涉及"公寓搜索"和"账单查询"两个场景)。
- 代理的核心挑战:灵活规划并在不同场景之间切换(flexibly plan and switch between different scenarios)。这模拟真实应用中,用户需求可能动态变化或跨领域(如从预约切换到售后支持),测试代理对多格式知识(文本、代码、流程图)的综合利用能力,而非孤立任务。
- 与基准 schema 的关联:FlowBench 的数据集结构(Section 4.1)是顶层多级层次(领域 → 角色 → 场景 → 知识库),跨场景评估利用角色级知识覆盖(e.g., 一个角色下有 2-12 个场景,总 51 个场景),确保知识多样性(操作过程、条件规则、工具/数据相关)。
-
为什么设计跨场景?:论文强调,传统代理范式假设完整任务描述一次性输入,但现实中是多轮在线规划(Section 3.1)。跨场景评估桥接这一差距,揭示 LLM 在知识密集任务中的"规划幻觉"(planning hallucinations)问题,尤其当注入的外部知识需跨场景泛化时。
2. 评估协议:双层机制(Turn-Level + Session-Level)
跨场景评估不独立运行,而是嵌入整体协议中(Section 4.3.2 Evaluation Protocols),支持静态和动态评估。协议基于多轮用户-代理交互(公式1:代理生成行动 ai+1a_{i+1}ai+1、状态 si+1s_{i+1}si+1 和回复 ri+1r_{i+1}ri+1),输入包括交互历史 Hi\mathcal{H}_iHi(用户输入 uiu_iui、环境反馈 eie_iei、历史行动/回复)和知识库 B\mathcal{B}B。
-
静态回合级评估(Static Turn-Level Evaluation):
- 实现细节 :基于 Section 4.2 生成的 ground-truth 会话(总 536 会话、5313 回合)。对于每个采样会话 did_idi 的第 iii 回合,代理接收前 (i−1)(i-1)(i−1) 回合的真实历史({ut,et,st,at,rt}t=0i−1\{u_t, e_t, s_t, a_t, r_t\}_{t=0}^{i-1}{ut,et,st,at,rt}t=0i−1),然后注入跨场景知识库,提示生成当前行动 a^i\hat{a}_ia^i 和回复 r^i\hat{r}_ir^i。
- 跨场景特定 :知识库是角色级的全覆盖集(e.g., 公寓经理的所有场景知识),代理需从通用知识中推断并切换到正确子场景。评估比较预测与 ground-truth ai,ria_i, r_iai,ri,聚焦工具调用(Tool Invocation)、参数(Parameter)和响应(Response)的精确匹配。
- 指标计算:精确率(P)、召回率(R)、F1 分数(工具/参数/响应级),以及整体分数(Score,可能用 LLM 评分 0-10)。见表3(Page 6),跨场景下性能显著低于单场景(e.g., GPT-4o 无知识时工具 F1 为 55.4%,流程图格式提升至 63.7%),凸显切换难度。
- 数据处理 :输入路径区分单/跨场景(e.g.,
data/turn_data/cross_scenario),支持不同知识格式注入(--knowledge_format flowchart)。
-
模拟会话级评估(Simulated Session-Level Evaluation):
- 实现细节 :更全面模拟真实序列规划,使用 GPT-4 构建用户模拟器(user simulator),确保行为"人类-like"。从 ground-truth 会话中蒸馏任务-用户摘要 (task-user summary,包括任务背景、用户目标、工具调用信息),这不同于 Section 4.2 的用户画像(user profile,后者强调背景/目标/语气多样性,包括噪声如闲聊)。
- 用户目标摘要总结所有潜在需求 (e.g., "用户可能从公寓搜索切换到账单查询"),驱动模拟器生成动态输入 uiu_iui。
- 代理在跨场景知识下迭代规划:从初始状态 s0s_0s0 开始,处理反馈 eie_iei,生成行动序列 {a1,...,aT}\{a_1, ..., a_T\}{a1,...,aT} 和回复 {r1,...,rT}\{r_1, ..., r_T\}{r1,...,rT},直到任务完成(T 动态)。
- 跨场景特定:模拟中,用户需求可跨场景演化(e.g., 起始"找公寓",中途切换"查账单"),测试代理的场景识别和知识切换(e.g., 从一个流程图分支跳转到另一个)。环境模拟器(env_simulator)反馈工具执行结果,推动序列。
- 指标计算:成功率(success rate,LLM 判断任务达成 0/1)、工作流遵守度(workflow adherence)和响应流畅性(response fluency)。论文结果显示,GPT-4o 跨场景成功率仅 40.9%,远低于单场景的 43.2%,强调长序列泛化瓶颈。
- 人类对齐:模拟器基于 ground-truth 蒸馏,确保真实性;支持噪声注入(off-scope intents),模拟真实交互。
- 实现细节 :更全面模拟真实序列规划,使用 GPT-4 构建用户模拟器(user simulator),确保行为"人类-like"。从 ground-truth 会话中蒸馏任务-用户摘要 (task-user summary,包括任务背景、用户目标、工具调用信息),这不同于 Section 4.2 的用户画像(user profile,后者强调背景/目标/语气多样性,包括噪声如闲聊)。
3. 实验结果与性能洞见(基于表3)
- 跨场景下,知识注入提升明显,但格式影响大:流程图最佳(GPT-4o 工具 F1 63.7%,整体 72.2%),因其可视化和结构平衡,便于切换;文本次之(59.9%),代码最低(58.2%),反映代码的精确性在泛化时易受歧义影响。
- 模型比较:GPT-4o > GPT-4-Turbo > GPT-3.5-Turbo;无知识时跨场景性能下降 10-15%,证明通用知识集的必要性。
- 统计:覆盖 22 角色、51 场景,总回合 5313;跨场景数据占比约 50%,聚焦高难度切换(如客户服务域的 12 场景)。
4. 实现与扩展建议(结合源代码)
- 在 GitHub 仓库(https://github.com/Justherozen/FlowBench)的
turn_level/和session_level/目录:- Turn-level:用
turn_inference.py指定--input_path data/turn_data/cross_scenario,注入角色全知识,生成预测;turn_metric_display.py输出 F1 表格。 - Session-level:
session_simulate.py --mode simulate --input_path data/session_data/cross,用 GPT-4 模拟跨场景演化;--mode eval计算成功率。
- Turn-level:用
- 挑战:跨场景需更多 token(通用知识长),易幻觉;未来可扩展多代理协作或混合格式。
- 数据质量:构建时三人交叉验证(Page 6),确保 ground-truth 可靠。
跨场景评估是 FlowBench 的创新亮点,它从"已知任务"转向"未知泛化",为 LLM 代理规划研究提供更严苛的基准。论文开源数据支持复现,欢迎实验验证!如果需单场景对比或代码调试细节,再细聊。
后记
2025年12月8日于上海,在supergrok辅助下完成。