一、基础信息
1.文章标题
《Improving action segmentation via explicit similarity measurement》
2.作者信息
Kamel Aouaidjia、Wenhao Zhang、Aofan Li、Chongsheng Zhang
3.关键词
Supervised action segmentation、Explicit similarity measurement、Boundary correction、Fully unsupervised segmentation
二、文章摘要
现有的监督动作分割方法依赖于使用注意力机制或时间卷积来捕获时间依赖性的逐帧分类的质量。即使是基于边界检测的方法也主要依赖于初始逐帧分类的准确性,这在低质量预测的情况下会忽略片段和边界的精确识别。
为了解决这个问题,本文提出了一种基于显式相似性度量的动作分割方法,通过引入跨帧和预测的显式相似性评估来提高分割精度。
我们的监督学习架构使用帧级多分辨率特性作为多个变压器编码器的输入。所得的多个逐帧预测用于相似性投票,以获得高质量的初始预测。
我们应用新提出的边界校正算法,该算法基于连续帧之间的特征相似性来操作,以通过学习过程迭代地调整边界位置。
然后通过多级时间卷积进一步改进校正的预测。作为后处理,我们可选地再次应用边界校正,随后是分段平滑方法,该方法使用连续预测之间的相似性度量来移除分段内的离群类。
此外,我们提出了一种完全无监督的边界检测-校正算法,该算法仅基于特征相似性而无需任何训练来识别片段边界。
在 50Salads、GTEA 和breakfast数据集上的实验表明了监督和非监督算法的有效性。Github 上提供了代码和模型。
三、现有方法与论文方法对比
现有方法缺陷
- 严重依赖单个帧的分类精度,逐帧预测中的误差会导致不准确的分割,尤其是在片段边界处
- 边界检测基于模型预测,缺乏明确验证边界位置正确性的机制
- 边界校正方法依赖于用于边界定位的初始边界预测,需要高质量的分类作为基本步骤
论文方法(ASESM)
通过在训练和测试过程中显式地测量帧之间的相似性来增强动作分割。
- 通过使用帧级多分辨率特征作为多个编码器的输入来捕获小尺度特征中的全局细节和大尺度特征中的局部细节,解决了不准确的初始预测的问题。
- 在每次训练迭代期间应用边界校正,调整学习过程以调整边界。使用时间卷积通过多个阶段进一步改进校正的预测。
- 使用分段平滑技术,通过测量连续预测之间的相似性来移除段内的离群类,以减轻错误的逐帧分类的影响
无监督方法
我们提出了一种完全无监督的边界检测-校正算法,该算法利用了我们的有监督方法中使用的相同的相似性测量度量。无监督方法直接从逐帧特征中识别片段边界,而不需要任何训练或粗略的初始边界
四、监督模型介绍
0.模型框架
特征提取 -> 相似性投票 -> 边界校正 -> 预测细化 -> 片段平滑
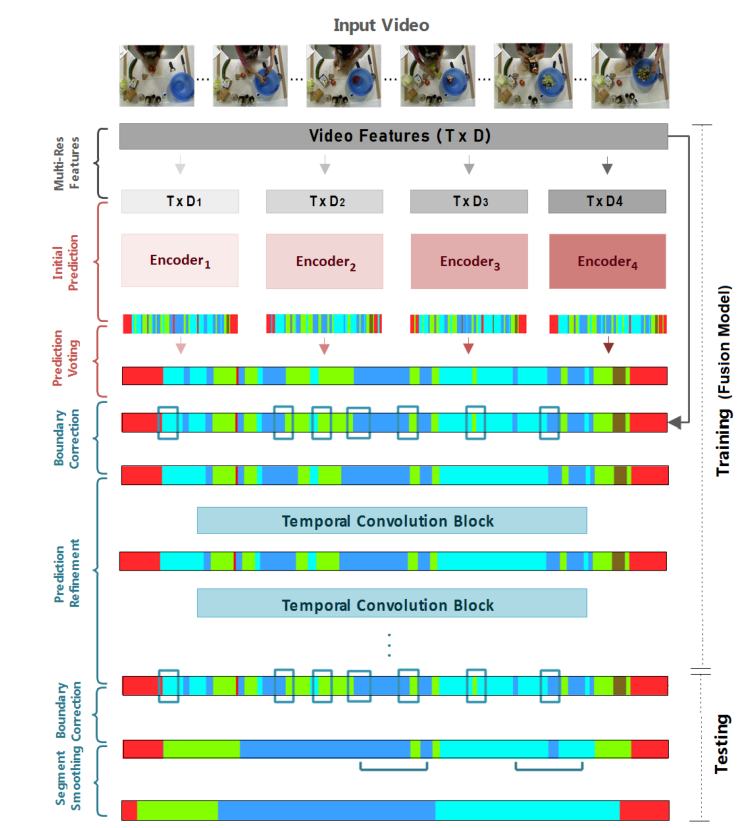
1.多分辨率特征提取
-
使用
I3D模型抽取视频特征 -
把视频中的每帧作为一个最小单位使用
I3D模型提取特征(提取之后特征不变)- xix_ixi:视频的每个帧
- fif_ifi:视频每个帧提取到的特征
V={x1,x2,...,xT}⟹f={f1,f2,...,fT} V=\{x_1,x_2,...,x_T\} \Longrightarrow f=\{f_1,f_2,...,f_T\} V={x1,x2,...,xT}⟹f={f1,f2,...,fT}
-
使用1×11\times11×1的卷积核、步长为1的1D卷积对fff进行处理,同时使其由2048个特征值降维到{32,64,128,256}\{32,64,128,256\}{32,64,128,256}。
- fff:输入特征
- DiD_iDi:输出通道数
- strstrstr:步长
- kerkerker:卷积核
- RiR_iRi:投影后的时序特征
Ri=Conv1D(f,Di,str=1,ker=1) R_i=Conv1D(f,D_i,str=1,ker=1) Ri=Conv1D(f,Di,str=1,ker=1)
2.特征提取和初始预测
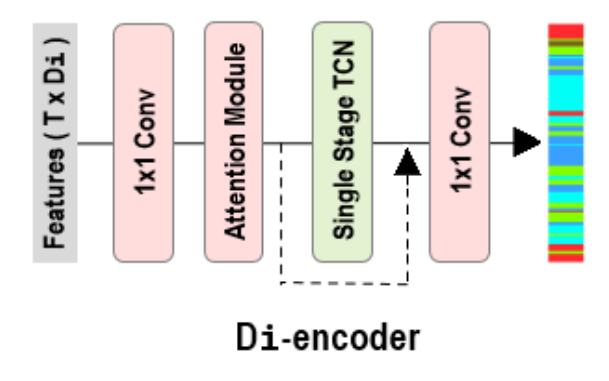
4个分辨率序列每一个都使用单独的编码器进行处理,用于时间建模和逐帧标签预测
- EncoderiEncoder_iEncoderi:第i个时序编码器
- RiR_iRi:时序投影特征
- PiP_iPi:编码后的时序语义特征
Pi=Encoderi(Ri) P_i=Encoder_i(R_i) Pi=Encoderi(Ri)
3.预测相似性投票
-
使用逐帧多数投票从四个编码器的预测中选择最可能正确的类别,以获得基于多个分辨率的精确初始预测。
-
如果有两个以上的编码器认为某个帧是相同的类,则这个类被认为是正确的。如果四个编码器认为某个帧是四个不同的类,则以编码器4(分辨率最高的那个)为准
- VotingVotingVoting:投票模型
- PiP_iPi:语义特征
- PinitP_{init}Pinit:通过投票得到的初始预测
Pinit=Voting(P1,...,P4) P_{init}=Voting(P_1,...,P_4) Pinit=Voting(P1,...,P4)
4.边界校正
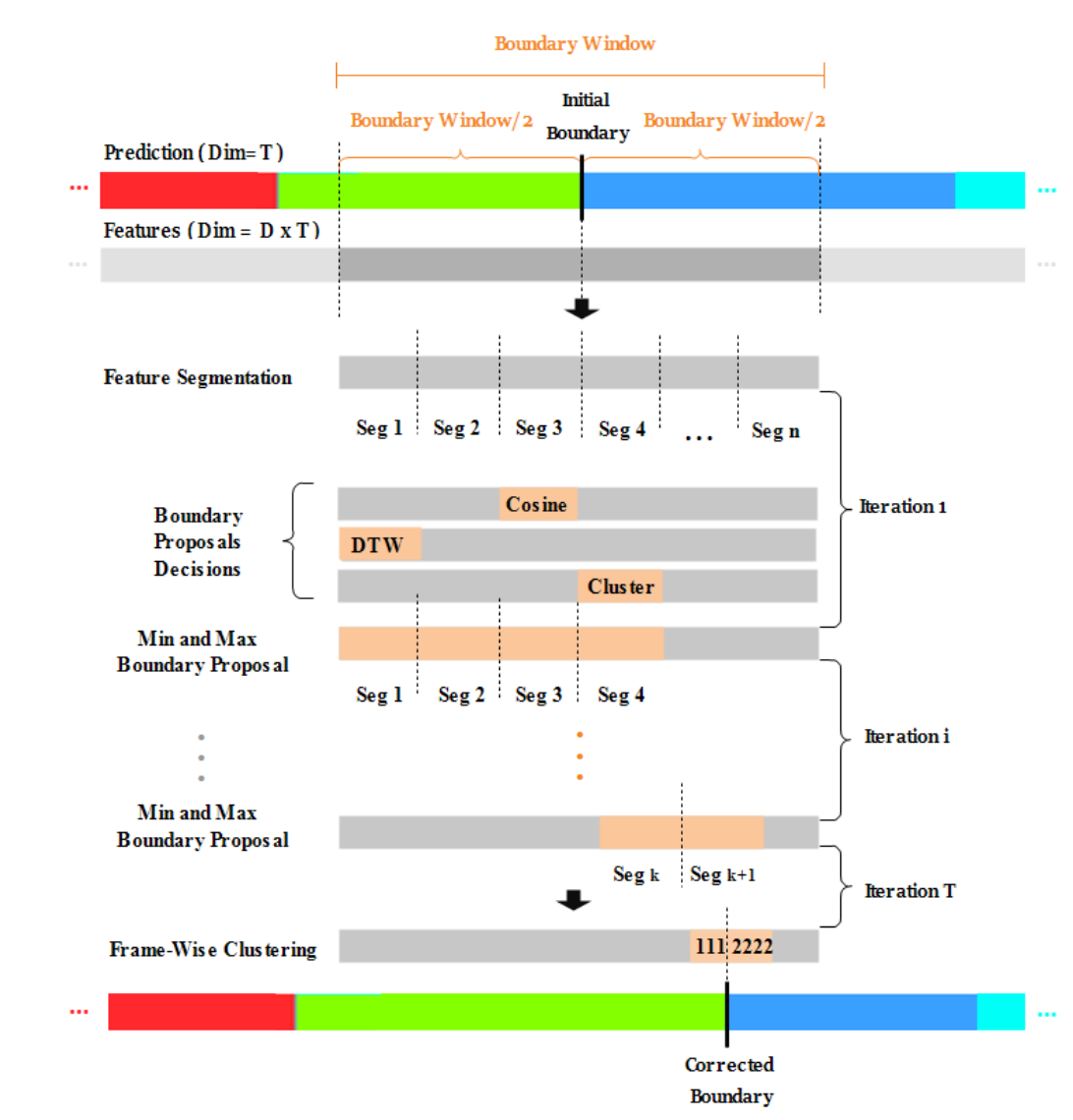
- 首先在初始预测上识别边界,通过识别到边界的索引在初始特征(I3D提取的特征)中找到对应的帧特征,在边界帧附近截取一个边界窗口BwinB_{win}Bwin,再切成小段BsegB_{seg}Bseg
- 使用3种相似性度量(
Cosine similarity、DTW、二分类聚类KMeans)对相邻段进行比较,得出3个候选片段索引,取最小值作为BstartB_{start}Bstart,最大值作为BendB_{end}Bend,进入下一次迭代 - 直到满足停止条件后,迭代停止,文中的停止条件是窗口大小等于原来1段的大小
- 停止迭代之后再做一次二分类聚类,找到动作边界点
- 根据找到的动作边界点对初始预测进行修改,比如PinitP_{init}Pinit最开始是
[AAABBBBB],边界是3,但是迭代找到的边界是5,就要把PinitP_{init}Pinit修改为[AAAAABBB]
5.分段平滑
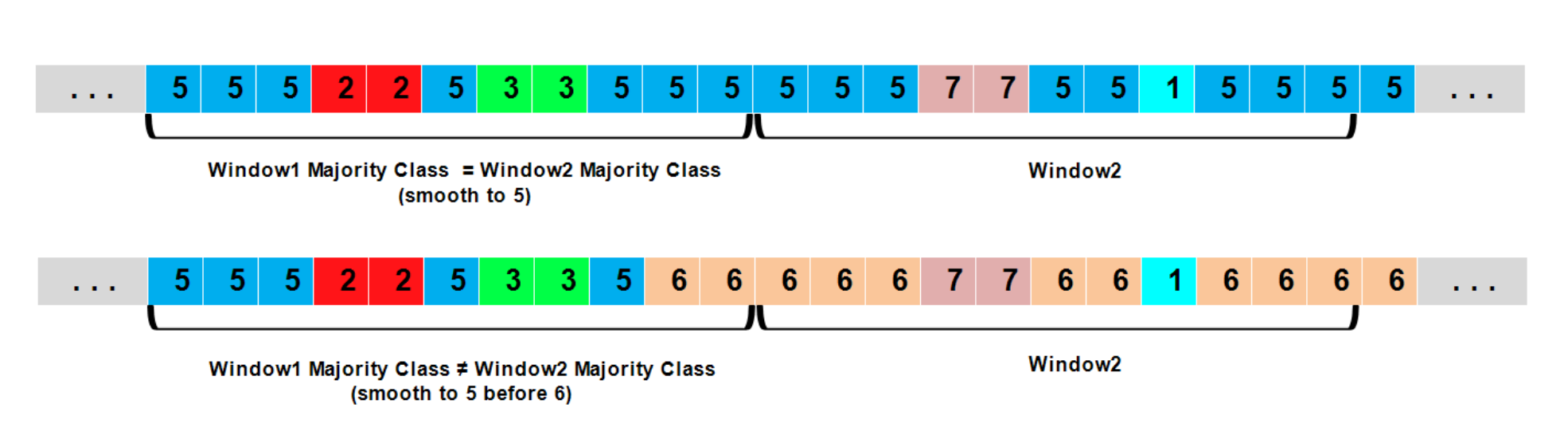
- 在上一步得到的预测标签列表上设立两个滑动窗口,第一个窗口用于分段平滑,第二个窗口用于检查下一个段是仅仅包括当前片段还是又包括了下一个片段
- 分为两种情况
- 情况1:窗口1的大多数类别和窗口2的大多数类别相同,就把窗口1的所有类别都改为大多数类
- 情况2:窗口2的大多数类别和窗口1的大多数类别不同,就把窗口1里除了窗口2大多数类以外的值改为窗口1的大多数类
这玩意挺绕,我在下边给了一个代码的讲解
python
# 1.先区分一下什么叫大多数类别
win_1 = [A,A,B,A,A,C,A,A,D] # 大多数类别就是A
win_2 = [A,A,B,B,B,B,C,C,C] # 大多数类别就是B
win_3 = [A,A,A,B,B,B,C,C,C] # 论文里没提,但是我觉得不会出现这么der的情况
# 2.情况1,窗口1的大多数类和窗口2的大多数类相同
win_1 = [A,A,B,A,A,C,A,A,D] # 大多数类是A
win_2 = [A,A,A,A,A,B,B,B,B] # 大多数类是A
# 窗口1中的所有类都改为A,窗口2保持不变
win_1 = [A,A,A,A,A,A,A,A,A]
win_2 = [A,A,A,A,A,B,B,B,B]
# 3.情况2,窗口1的大多数类和窗口2的大多数类不一样
win_1 = [A,A,B,A,A,C,A,A,D] # 大多数是A
win_2 = [A,A,A,A,B,B,B,B,B] # 大多数是B
# 窗口1中除了B以外的所有类都改为A,窗口2保持不变
win_1 = [A,A,B,A,A,A,A,A,A]
win_2 = [A,A,A,A,B,B,B,B,B]6.训练和测试过程
- 训练阶段
- 每个编码器独立训练
- 在训练迭代中,同时进行逐帧预测+投票+边界修正
- 作用:
- 每个编码器在自己的特征空间上达到最优
- 训练过程中就学习到平滑的、边界一致的预测
- 融合阶段(Fusion Stage)
- 加载四个预训练编码器
- 对每一帧生成预测
- 进行:
- 投票融合 → 多个编码器预测结果融合减少噪声
- 边界修正 → 确保动作段边界准确
- 多次迭代精炼(TCB) → 进一步优化帧预测和时间一致性
- 作用:
- 把单个编码器的知识融合成一个强预测模型
- 得到更精确的逐帧预测,同时保留动作段的时间结构
- 测试阶段(Testing Stage)
- 对模型输出进行 后处理(post-processing):
- 可选的 边界修正
- 段平滑(segment smoothing)
- 作用:
- 最终生成稳定的逐帧预测
- 消除预测噪声,保证段内一致性和段间边界清晰
- 对模型输出进行 后处理(post-processing):
测试阶段: 后处理 融合阶段: 加载预训练编码器 训练阶段: 单独训练四个编码器 段平滑 (Segment Smoothing) 可选边界修正 最终帧级预测输出 投票融合 (Voting Fusion) 生成每帧预测 边界修正 (Boundary Correction) 多次迭代精炼 (TCB) 融合后的帧级预测 投票 (Voting) 逐帧预测 边界修正 (Boundary Correction) 更新编码器参数
7.无监督边界检测-校正
基于使用聚类、余弦和 DTW 进行相似性度量的相同思想,我们提出了一种非监督边界检测-校正算法,该算法在没有任何初始粗略预测的情况下运行。
- 首先应用1D卷积减少逐帧特征尺寸,作为算法的输入
- 在输入特征中应用聚类、余弦相似度、DTW生成一个可能的边界列表
- 对于余弦相似度或者DTW相似度提出的边界,分别以平均值为界筛掉剔除一些边界。
- 最后合并三种方式得出的边界,落在一个阈值之内的边界取平均值
五、实验部分
1.数据准备与评估
- 数据集 :
50Salads、Breakfast、GTEA - 交叉验证 :
50Salads:5折交叉验证Breakfast:4折交叉验证GTEA:4折交叉验证
- 评估指标 :
Acc:Frame-wise accuracy,逐帧准确率Edit:Edit distance,编辑分数Segmental F1 Score:段级 F1 Score,考虑段与段之间的重叠比例(IoU)- F1@10 → 当预测段与真实段的 IoU ≥ 10% 时,认为预测正
- F1@25 → IoU ≥ 25%
- F1@50 → IoU ≥ 50%
2.实施细节
边界优化阶段(结论:没有明显影响)
50Salads&Breakfast:Bwin=16,Bseg=4B_{win}=16,B_{seg}=4Bwin=16,Bseg=4GTEA:Bwin=8,Bseg=4B_{win}=8,B_{seg}=4Bwin=8,Bseg=4
编码器与融合模型训练阶段
每个编码器与融合模型都被训练50个周期,每次学习迭代一个视频,学习率为0.0005
实验环境
framework:PyTorchGPU:Nvidia GeForce RTX 4090RAM:64GCPU:Intel(R) Core(TM) i9-13900k
3.结果对比
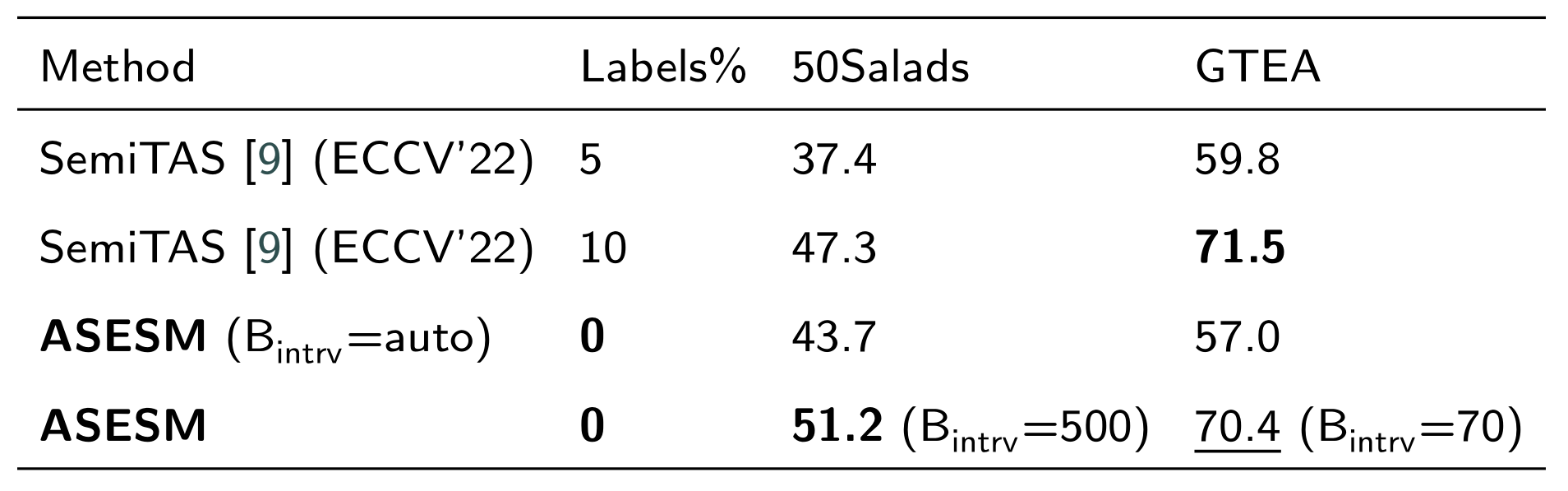
表1 :各种监督学习方法在50Salads(平滑窗口大小:80)、GTEA(平滑窗口大小:40)、Breakfast(平滑窗口大小:50)数据集的表现
结论:
- 在
50Salads数据集上,ASESM模型表现非常好 - 在
GTEA数据集上,除了Acc以外的指标都取得了更好的性能 - 在
Breakfast数据集上,具有较高的准确率,其他指标也旗鼓相当
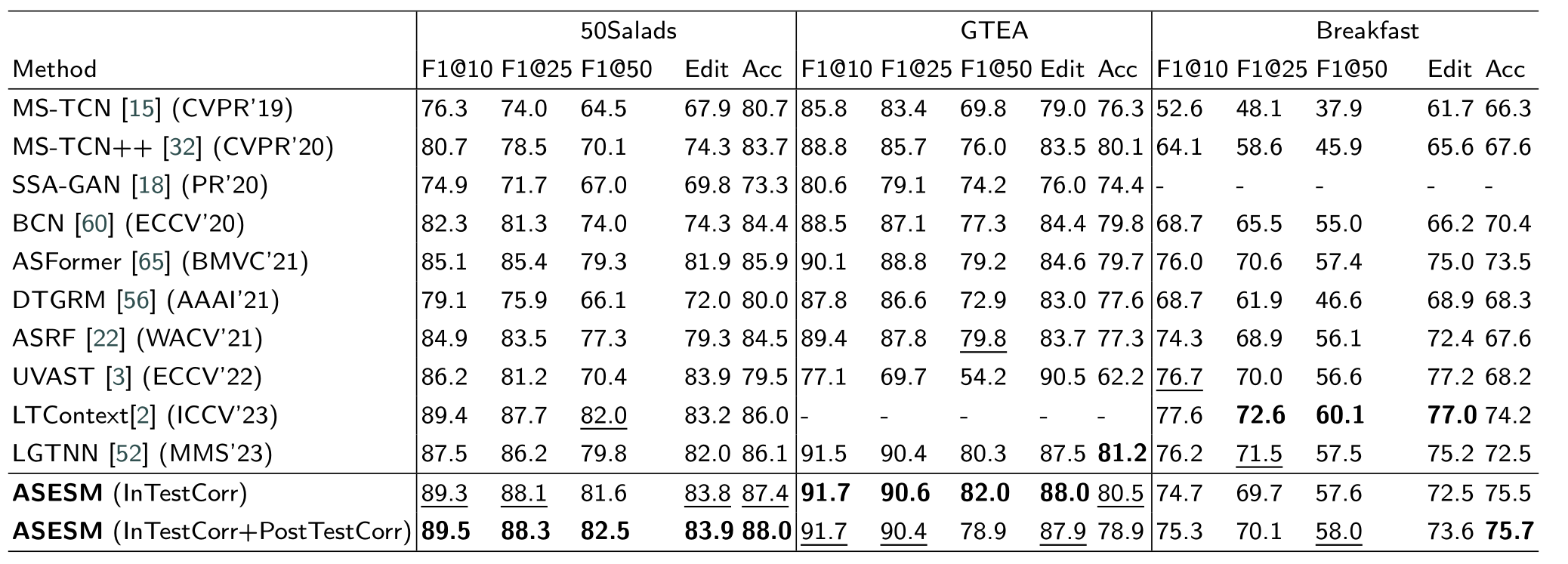
表2:监督学习方法使用边界优化和平滑作为后处理对ASFormer模型的提升,数据集是50Salads的不同split
结论:使用边界优化和平滑会提升ASFormer模型的表现,特别是两种方法同时被引用于后处理时
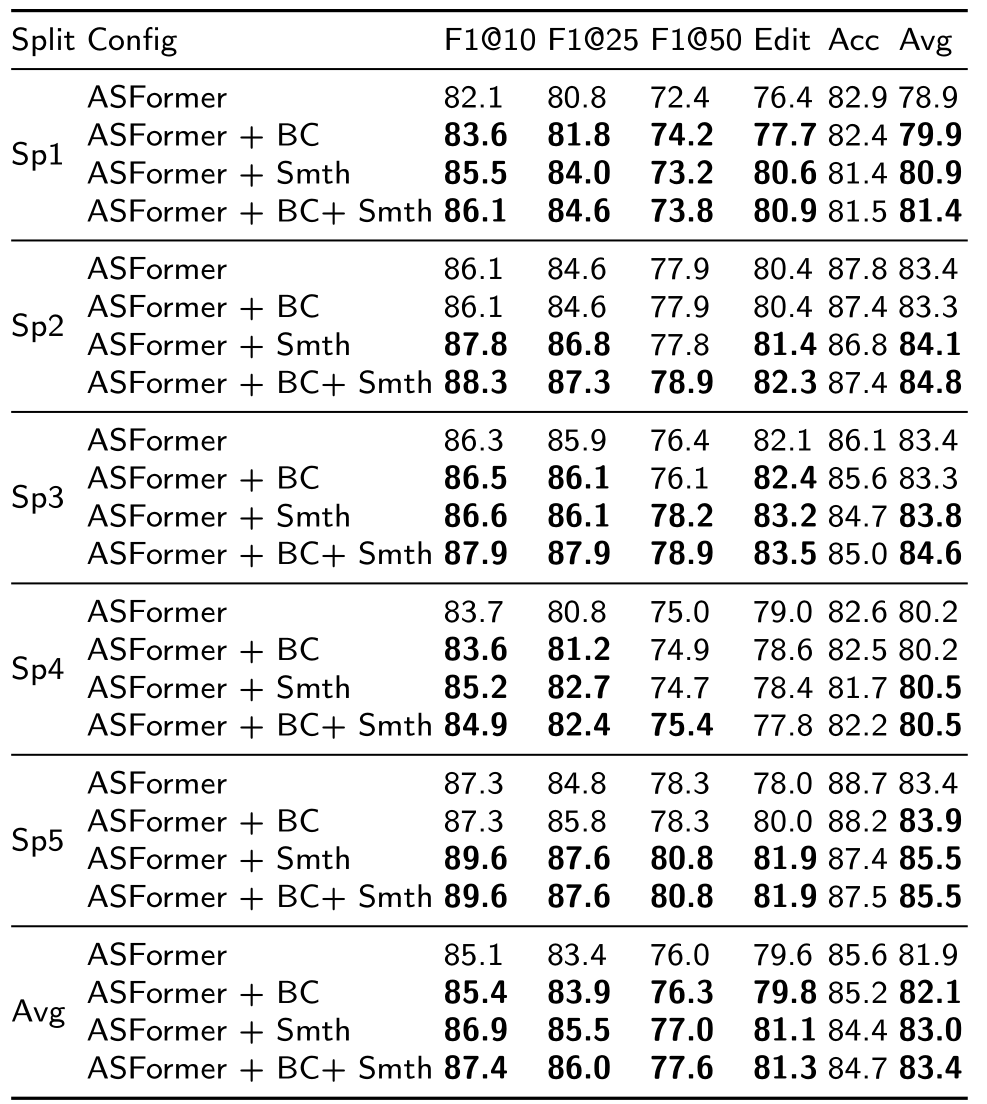
表3:无监督检测-校正算法与现有的无监督方法在50Salads和breakfast数据集上的对比
结论:ASESM无监督模型效果优于其他模型
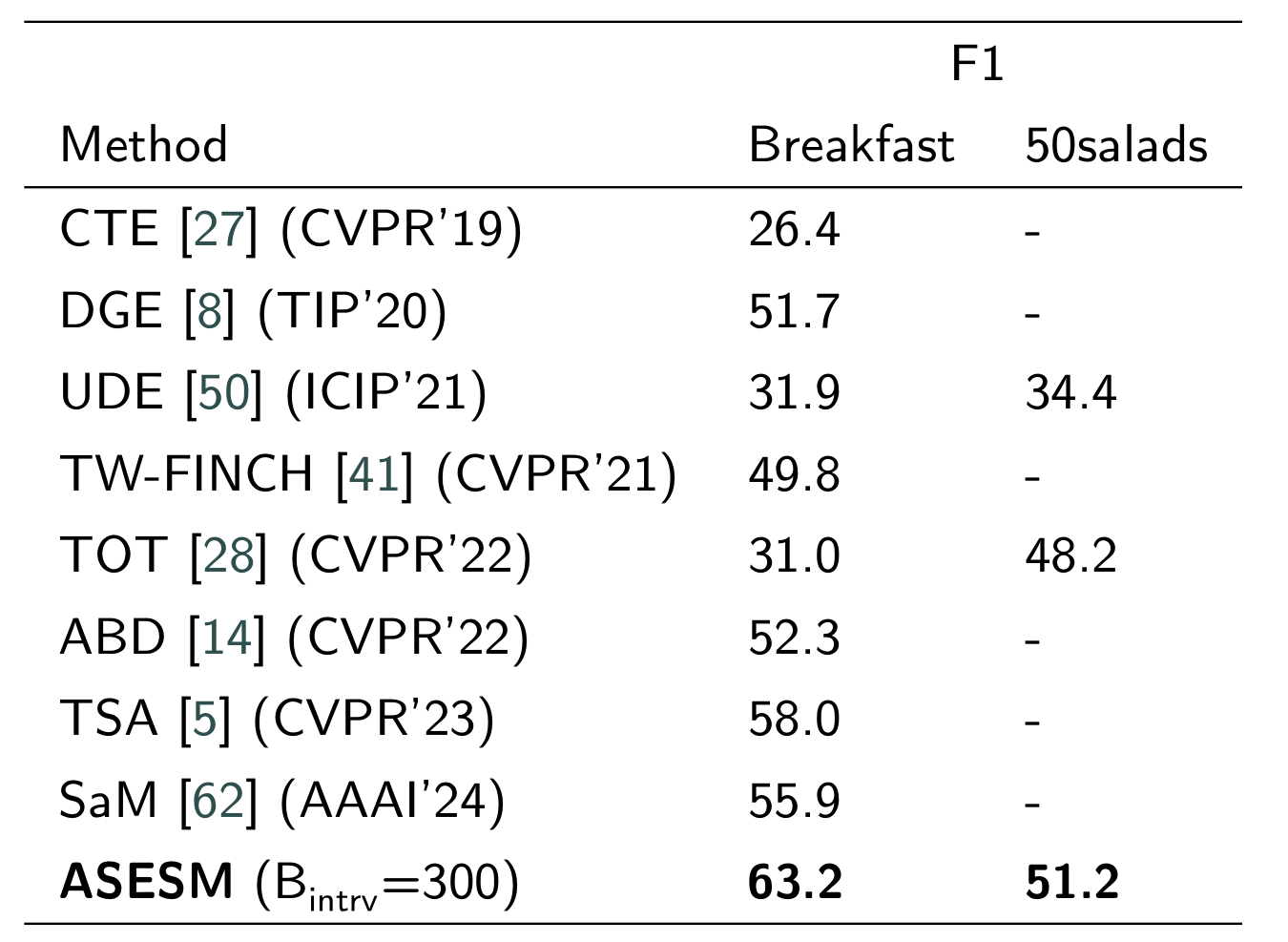
表4:无监督检测-校正算法对比5%和10%标签数据的半监督模型在50Saolads和GTEA数据集上取得的效果
结论:当半监督模型使用5%标签数据训练时,无监督模型明显领先;当半监督模型使用10%标签数据训练时,无监督在50Salads上ASESM效果更好,在GTEA数据集效果略差
4.消融实验
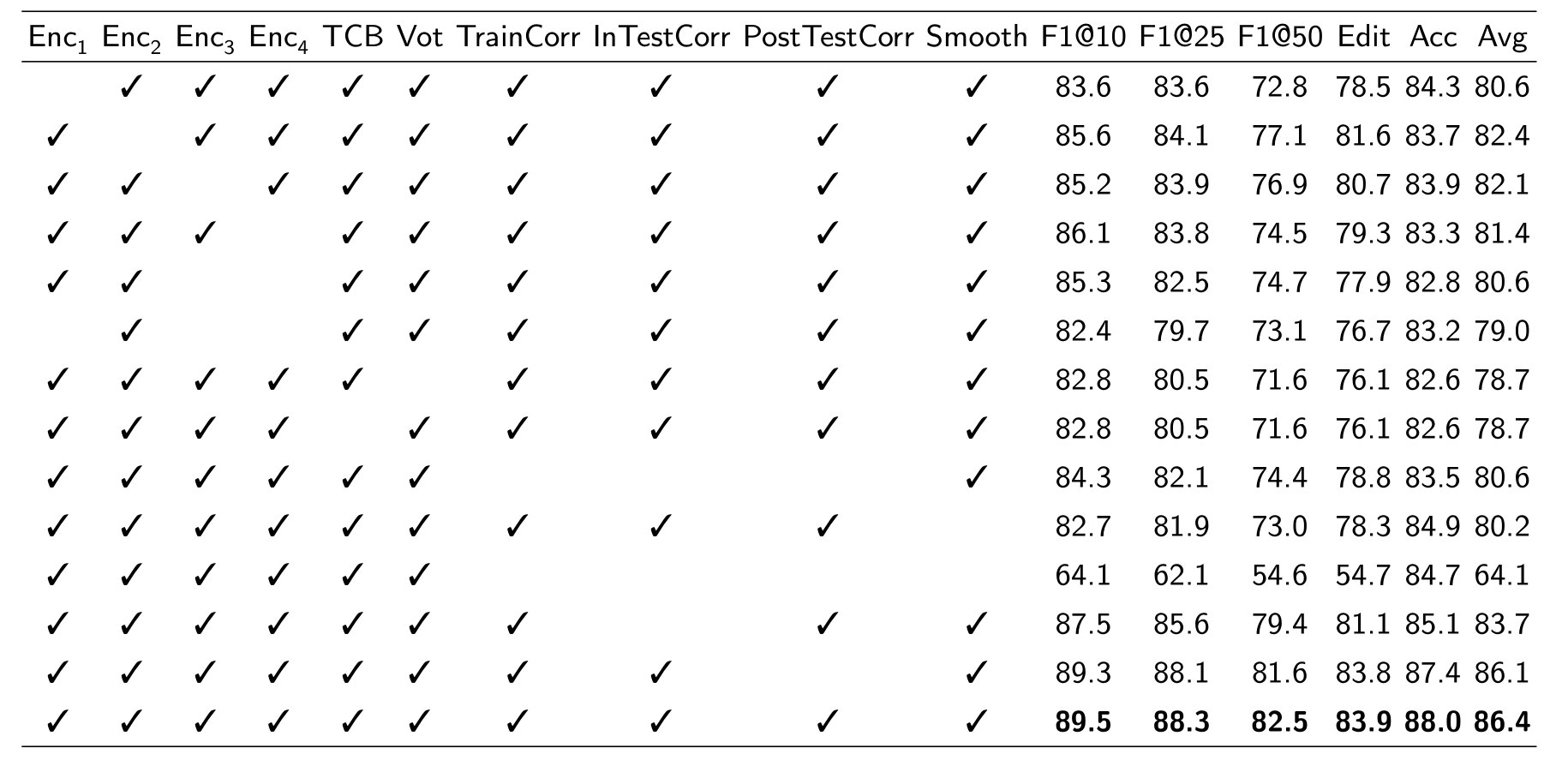
评估监督框架中每个组成部分的效果
数据集:50Salads数据集的Split1
结论:
- 每一个编码器都是有贡献的,他们的组合效果对于实现高性能至关重要
- 投票阶段在增强模型稳定性的方面起着重要作用
- TCB对于捕获逐帧预测序列内的时间依赖性是必不可少的
- 边界校正在训练期间会起到更显著的影响,在后处理阶段省略这一步造成的影响更小
- 在省略所有的边界处理和平滑会导致最差的表现
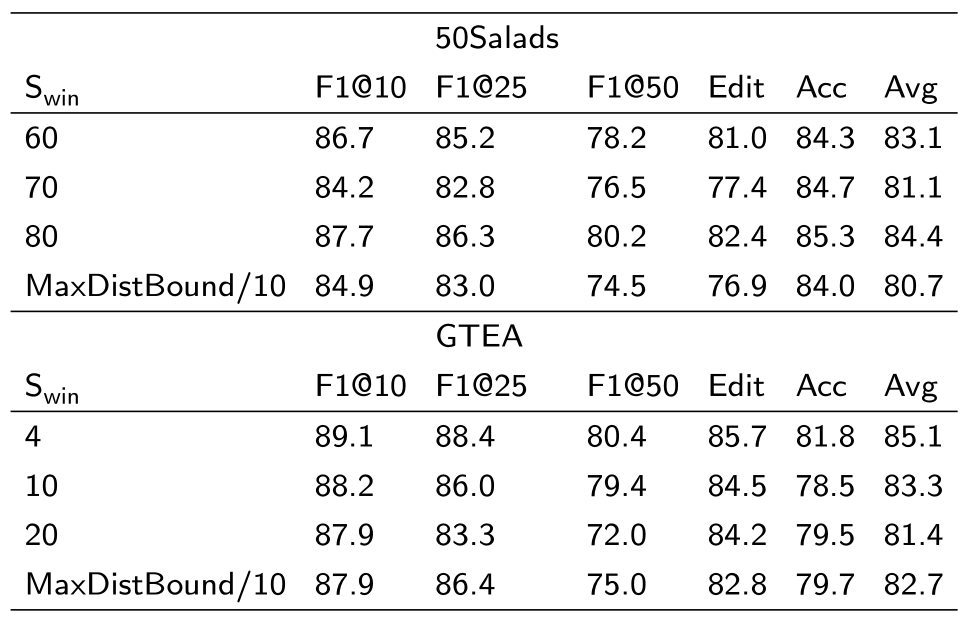
监督模型中平滑窗口大小的影响
数据集:50Salads数据集和GTEA数据集的Split1
结论:
- 在50Salads数据集上,Swin=80S_{win}=80Swin=80取得了最好的效果,将窗口增大与减小均会降低性能
- 使用自动生成的窗口大小性能较低
- 在GTEA数据集上,Swin=4S_{win}=4Swin=4效果最好,自动窗口的效果低于固定窗口
- 动作更多的视频需要更大的窗口
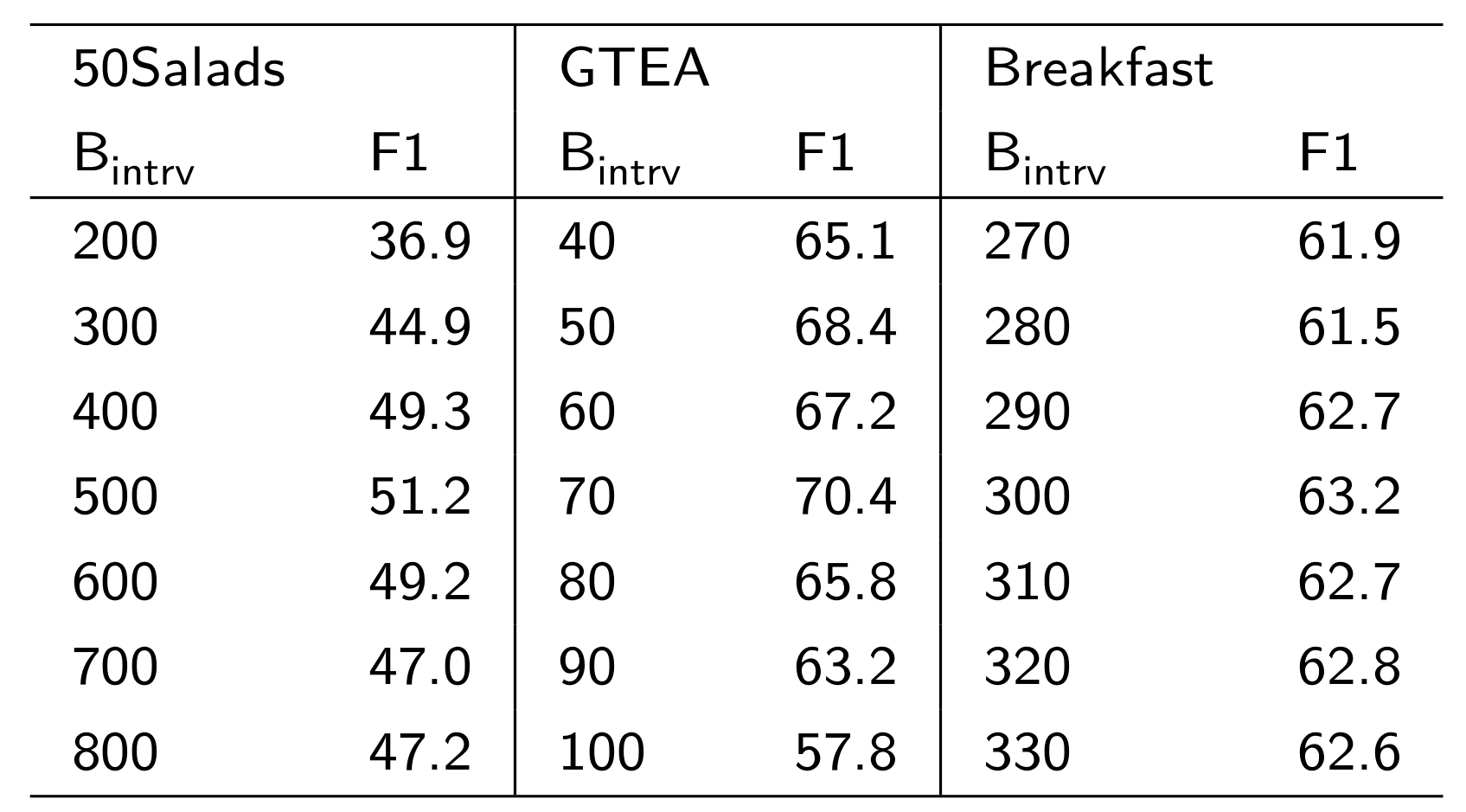
边界区间阈值对无监督分割模型的影响
结论:
- 在50Salads数据集上,Bintrv=500B_{intrv}=500Bintrv=500取得最好的效果
- 在GTEA数据集上,Bintrv=70B_{intrv}=70Bintrv=70取得最好的效果
- 在Breakfast数据集上,Bintrv=300B_{intrv}=300Bintrv=300取得最好的效果
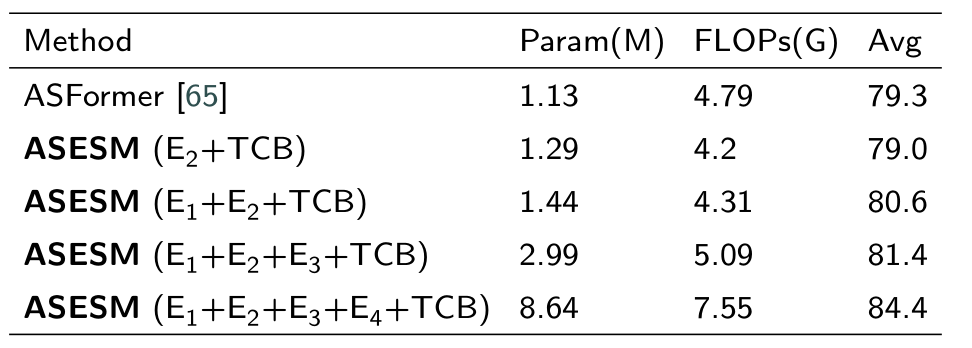
5.复杂度计算
数据集:50Salads数据集的Split1
结论:
- 只使用Encoder2+TCBEncoder_2+TCBEncoder2+TCB的ASESM模型性能略低于ASFormer模型
- 当使用多个Encoder+TCBEncoder+TCBEncoder+TCB时,模型的参数与运算增加,但是性能也会高于ASFormer模型
6.结论
- ASESM模型通过将显示相似性评估纳入学习过程来提高性能
- ASESM模型的监督学习架构利用多分辨率帧级特征、通过多个变压器编码器进行处理、通过逐帧相似性投票进行精确的初始预测。