前言
时序数据库作为物联网、监控系统和工业互联网的核心基础设施,其性能表现直接影响着整个数据采集和分析链路的效率。InfluxDB 作为开源时序数据库领域的领军产品,以其高效的时间序列数据压缩算法和灵活的查询语言(Flux/InfluxQL)赢得了广泛应用。本文将在 openEuler 22.03 LTS 操作系统上完成 InfluxDB 2.7 的完整部署,并通过三个核心维度的专业性能测试------高并发写入吞吐量测试 、时间范围聚合查询性能测试 以及数据保留策略下的存储效率测试,深度剖析 InfluxDB 在自主创新操作系统环境下的真实性能表现,为生产环境部署提供可量化的决策依据。

文章目录
-
- 前言
- 测试环境
- [一、InfluxDB 部署与配置](#一、InfluxDB 部署与配置)
-
- [1.1 系统环境准备](#1.1 系统环境准备)
- [1.2 InfluxDB 安装部署](#1.2 InfluxDB 安装部署)
-
- [**1.2.1 下载和安装**](#1.2.1 下载和安装)
- [1.2.2 安装 InfluxDB CLI 工具](#1.2.2 安装 InfluxDB CLI 工具)
- [1.2.3 配置优化](#1.2.3 配置优化)
- [1.2.4 配置 systemd 服务](#1.2.4 配置 systemd 服务)
- [1.3 初始化配置与启动](#1.3 初始化配置与启动)
-
- [1.3.1 启动 InfluxDB 服务](#1.3.1 启动 InfluxDB 服务)
- [1.3.2 初始化配置](#1.3.2 初始化配置)
- 二、性能测试方案设计
-
- [2.1 测试工具准备](#2.1 测试工具准备)
- [2.2 测试数据模型设计](#2.2 测试数据模型设计)
- 三、核心性能测试
-
- [3.1 高并发写入吞吐量测试](#3.1 高并发写入吞吐量测试)
- [3.2 时间范围聚合查询性能测试](#3.2 时间范围聚合查询性能测试)
- [3.3 数据保留策略下的存储效率测试](#3.3 数据保留策略下的存储效率测试)
- [四、 总结](#四、 总结)
测试环境
本次评测采用华为云 ECS 云服务器进行测试,实例规格为通用计算增强型c6sc6s.large.2(2vCPU 4GB内存) ,系统盘采用高IO云硬盘 40GB ,公网带宽 10Mbps 。操作系统版本为 openEuler 22.03 LTS SP3) ,文件系统采用 ext4 格式。虽然硬件配置相对轻量,但足以验证 InfluxDB 在中小规模场景下的性能表现,这也是大多数企业初期部署时序数据库的典型配置。测试过程中关闭了 SELinux 以排除安全策略对性能的干扰,所有测试数据均基于三次独立运行的平均值以确保结果的可靠性。
一、InfluxDB 部署与配置
1.1 系统环境准备
在开始部署 InfluxDB 之前,我们需要对 openEuler 系统进行必要的优化配置。首先更新系统软件包到最新版本,确保系统组件的稳定性和安全性。时序数据库对系统资源的要求较高,特别是文件描述符数量和网络连接数,因此需要调整系统限制参数。
虽然我们的云服务器配置较为轻量,但通过合理的系统参数优化,仍然可以充分发挥硬件性能。网络参数的调整对于时序数据库的高并发写入场景尤为重要,即使在 10Mbps 带宽限制下,优化后的系统也能保持稳定的数据吞吐。
plain
# 更新系统软件包
sudo yum update -y
# 安装必要的依赖工具
sudo yum install -y wget curl vim net-tools
# 优化系统参数
sudo tee -a /etc/sysctl.conf <<EOF
# 网络优化
net.core.somaxconn = 4096
net.ipv4.tcp_max_syn_backlog = 2048
net.ipv4.ip_local_port_range = 10000 65535
# 文件系统优化
fs.file-max = 65536
EOF
# 应用系统参数
sudo sysctl -p
# 配置用户限制
sudo tee -a /etc/security/limits.conf <<EOF
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
EOF
# 重新登录使配置生效
exit系统参数优化主要针对中等并发场景进行调整。somaxconn 参数控制了 TCP 连接队列的最大长度,设置为 4096 对于 2 核 CPU 的服务器来说是合理的配置。文件描述符限制的提升确保了 InfluxDB 可以同时处理足够数量的数据文件和网络连接。这些优化措施为后续的性能测试奠定了坚实的基础。
1.2 InfluxDB 安装部署
InfluxDB 2.x 版本采用了全新的架构设计,集成了数据存储、查询引擎和可视化界面。我们选择官方提供的 RPM 包进行安装,这种方式相比容器化部署能够更直接地利用系统资源,减少虚拟化层的性能损耗。对于 openEuler 系统,InfluxDB 的 RPM 包具有良好的兼容性。
考虑到我们的系统盘只有 40GB,需要对 InfluxDB 的存储路径进行合理规划。默认情况下,InfluxDB 会将数据存储在 /var/lib/influxdb2 目录,我们将保持这个默认配置,但需要密切关注磁盘空间使用情况,并通过数据保留策略来控制存储增长。
1.2.1 下载和安装
plain
# 下载 InfluxDB 2.7.10 RPM 包
cd /tmp
wget https://repos.influxdata.com/rhel/8/x86_64/stable/influxdb2-2.7.10-1.x86_64.rpm
# 验证下载的文件
ls -lh influxdb2-2.7.10-1.x86_64.rpm
# 安装 InfluxDB
sudo yum localinstall -y influxdb2-2.7.10-1.x86_64.rpm
# 验证安装
influxd version安装完成后,系统会自动创建 influxdb 用户和用户组,并注册 systemd 服务单元。

1.2.2 安装 InfluxDB CLI 工具
InfluxDB 2.x 的服务端包不包含 influx 命令行工具,需要单独安装:
plain
# 下载 influx CLI 工具
cd /tmp
wget https://dl.influxdata.com/influxdb/releases/influxdb2-client-2.7.5-linux-amd64.tar.gz
# 解压并安装
tar xvzf influxdb2-client-2.7.5-linux-amd64.tar.gz
sudo cp influx /usr/local/bin/
sudo chmod +x /usr/local/bin/influx
# 验证安装
influx version
1.2.3 配置优化
plain
# 创建必要的目录
sudo mkdir -p /var/lib/influxdb2
sudo mkdir -p /etc/influxdb
# 设置目录权限
sudo chown -R influxdb:influxdb /var/lib/influxdb2
# 创建优化的配置文件(针对 4GB 内存)
sudo tee /etc/influxdb/config.yml <<'EOF'
bolt-path: /var/lib/influxdb2/influxd.bolt
engine-path: /var/lib/influxdb2/engine
http-bind-address: :8086
log-level: info
# 存储引擎配置
storage-cache-max-memory-size: 512MB
storage-cache-snapshot-memory-size: 64MB
storage-cache-snapshot-write-cold-duration: 10m
storage-compact-full-write-cold-duration: 4h
storage-max-concurrent-compactions: 2
storage-max-index-log-file-size: 1MB
# 查询引擎配置
query-memory-bytes: 209715200
query-concurrency: 10
query-queue-size: 20
EOF
# 设置配置文件权限
sudo chown influxdb:influxdb /etc/influxdb/config.yml
sudo chmod 644 /etc/influxdb/config.yml配置文件中的关键参数已经针对 4GB 内存的服务器进行了优化:
storage-cache-max-memory-size: 512MB:写入缓存上限,占用系统内存的约 12.5%,既保证了写入性能,又为操作系统和其他进程预留了足够的内存空间storage-max-concurrent-compactions: 2:与 CPU 核心数匹配,避免过度的并发压缩任务导致系统负载过高query-memory-bytes: 209715200(200MB):单个查询的内存限制,防止大查询耗尽系统内存query-concurrency: 10:最大并发查询数,平衡查询性能和资源占用
这些参数的调整体现了在资源受限环境下的性能平衡策略。
1.2.4 配置 systemd 服务
为了消除 DBUS 警告并确保配置文件生效,需要创建 systemd 服务覆盖配置:
plain
# 创建 systemd override 目录
sudo mkdir -p /etc/systemd/system/influxdb.service.d
# 创建 override 配置文件
sudo tee /etc/systemd/system/influxdb.service.d/override.conf <<'EOF'
[Service]
Environment="DBUS_SESSION_BUS_ADDRESS=/dev/null"
# 指定配置文件路径
ExecStart=
ExecStart=/usr/bin/influxd --config /etc/influxdb/config.yml
EOF
# 重新加载 systemd 配置
sudo systemctl daemon-reload1.3 初始化配置与启动
1.3.1 启动 InfluxDB 服务
plain
# 启用开机自启动
sudo systemctl enable influxdb
# 启动服务
sudo systemctl start influxdb
# 验证服务状态
sudo systemctl status influxdb
# 检查端口监听
sudo ss -tlnp | grep 8086
# 测试 HTTP 健康检查
curl -I http://localhost:8086/health如果服务启动正常,健康检查应该返回 200 OK 状态码。

1.3.2 初始化配置
InfluxDB 2.x 需要通过 Web 界面或 CLI 完成初始化设置,包括创建管理员账户、组织和初始 Bucket。我们使用命令行方式完成初始化,这种方式更适合自动化部署和脚本化管理。
plain
# 使用 CLI 进行初始化
influx setup \
--username admin \
--password YourSecurePassword123! \
--org myorg \
--bucket mybucket \
--retention 30d \
--force
# 验证初始化
influx auth list
# 配置INFLUXDB_TOKEN环境变量
export INFLUXDB_TOKEN="初始化生成的Token"
重要提示:
- 请将
YourSecurePassword123!替换为您自己的强密码(至少 8 位,包含字母、数字和特殊字符) --retention 30d设置数据保留期为 30 天,这对于 40GB 的磁盘空间是合理的配置--force参数会覆盖已有的初始化配置(如果存在)
初始化完成后,InfluxDB 会生成一个 API Token,这是 2.x 版本的核心认证机制。与 1.x 版本的用户名密码认证不同,Token 机制提供了更细粒度的权限控制和更高的安全性。初始化输出会显示生成的 Token,请妥善保存,后续所有的数据读写操作都需要携带它。
二、性能测试方案设计
2.1 测试工具准备
为了全面评估 InfluxDB 的性能表现,我们需要准备专业的压测工具和监控脚本。测试工具的选择直接影响测试结果的准确性和可重复性,因此我们采用 Python 编写自定义测试脚本,结合 InfluxDB 官方客户端库进行精确控制。这种方式相比使用第三方压测工具,能够更灵活地模拟真实业务场景。
Python 客户端库提供了完整的 InfluxDB 2.x API 封装,支持批量写入、异步查询等高级特性。考虑到我们的服务器内存有限,测试脚本需要注意内存使用,避免一次性加载过多数据导致系统 OOM。同时,我们还需要安装系统监控工具来实时观察 CPU、内存和磁盘 I/O 的使用情况。
plain
# 安装 Python 3 和 pip
sudo yum install -y python3 python3-pip
# 安装 InfluxDB Python 客户端
pip3 install influxdb-client --user
# 安装系统监控工具
sudo yum install -y sysstat
# 创建测试脚本目录
mkdir -p ~/influxdb-benchmark
cd ~/influxdb-benchmark
# 验证 Python 环境
python3 --version
python3 -c "import influxdb_client; print('InfluxDB Client Version:', influxdb_client.__version__)"
工具安装完成后,我们可以看到 Python 3.9 和 influxdb-client 库已经就绪。sysstat 工具包含了 iostat、mpstat 等命令,可以实时监控系统资源使用情况。这些监控数据对于分析性能瓶颈至关重要,特别是在资源受限的环境下,我们需要清楚地知道哪个组件成为了性能瓶颈。
2.2 测试数据模型设计
时序数据库的性能与数据模型设计密切相关,合理的 Schema 设计可以显著提升查询效率。我们设计了一个模拟物联网传感器的数据模型,包含设备标识、地理位置、传感器类型等标签(Tag),以及温度、湿度、压力等测量值(Field)。这个模型既具有代表性,又不会因为过于复杂而超出我们服务器的处理能力。
在 InfluxDB 中,Tag 用于索引和分组,Field 用于存储实际的测量值。Tag 的选择需要平衡查询性能和存储开销,过多的高基数 Tag 会导致索引膨胀。我们的设计中,device_id 是高基数 Tag(100 个设备),location 和 sensor_type 是低基数 Tag,这种组合既能满足常见的查询需求,又不会给系统带来过大的负担。
plain
# 创建测试数据生成脚本
cat > generate_test_data.py <<'EOF'
#!/usr/bin/env python3
import random
import time
from datetime import datetime, timedelta
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
import os
# 配置参数
INFLUX_URL = "http://localhost:8086"
INFLUX_TOKEN = os.getenv("INFLUX_TOKEN")
INFLUX_ORG = "testorg"
INFLUX_BUCKET = "testbucket"
# 模拟数据参数(适配小规模环境)
NUM_DEVICES = 100 # 设备数量
NUM_LOCATIONS = 10 # 地理位置数量
SENSOR_TYPES = ["temperature", "humidity", "pressure"]
def generate_point(device_id, timestamp):
"""生成单个数据点"""
location = f"location_{device_id % NUM_LOCATIONS}"
sensor_type = random.choice(SENSOR_TYPES)
point = Point("sensor_data") \
.tag("device_id", f"device_{device_id:03d}") \
.tag("location", location) \
.tag("sensor_type", sensor_type) \
.field("temperature", round(random.uniform(15.0, 35.0), 2)) \
.field("humidity", round(random.uniform(30.0, 90.0), 2)) \
.field("pressure", round(random.uniform(980.0, 1030.0), 2)) \
.time(timestamp)
return point
def get_client():
"""创建 InfluxDB 客户端"""
return InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG)
if __name__ == "__main__":
print("测试数据生成模块已准备就绪")
print(f"设备数量: {NUM_DEVICES}")
print(f"地理位置: {NUM_LOCATIONS}")
print(f"传感器类型: {SENSOR_TYPES}")
print(f"每个数据点包含 3 个 Field 字段")
EOF
chmod +x generate_test_data.py
python3 generate_test_data.py
数据模型设计遵循了时序数据库的最佳实践。每个数据点包含 3 个标签和 3 个字段,这是一个典型的物联网数据结构。标签的基数控制在合理范围内:100 个设备 × 10 个位置 × 3 种传感器类型 = 3000 个唯一的时间序列(Series),这个数量级对于我们的测试环境来说是合适的。Field 值使用随机数生成,模拟真实传感器的测量值波动。
三、核心性能测试
3.1 高并发写入吞吐量测试
时序数据库最核心的性能指标是写入吞吐量,即单位时间内能够处理的数据点数量。本测试模拟 100 个设备持续产生数据的场景,通过调整批量写入大小来找出最优的写入配置。批量写入是提升时序数据库性能的关键技术,它将多个数据点打包成一个请求,大幅减少网络往返次数和事务开销。
在我们的测试环境中,由于公网带宽只有 10Mbps,网络可能成为性能瓶颈。但由于测试是在本地回环接口进行(localhost),实际不受公网带宽限制。我们将测试不同批量大小(100、500、1000)下的写入性能,观察 InfluxDB 在 2 核 CPU 和 4GB 内存环境下的表现。
plain
# 创建使用环境变量的写入吞吐量测试脚本
cat > test_write_throughput.py <<'EOF'
#!/usr/bin/env python3
"""
InfluxDB 高并发写入吞吐量测试
测试不同 batch size 下的写入性能
"""
import time
import os
import sys
from datetime import datetime, timedelta
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
import random
# ============================================================
# 配置参数 - 从环境变量读取
# ============================================================
INFLUX_URL = os.getenv("INFLUX_HOST", "http://localhost:8086")
INFLUX_TOKEN = os.getenv("INFLUXDB_TOKEN")
INFLUX_ORG = os.getenv("INFLUX_ORG", "myorg")
INFLUX_BUCKET = os.getenv("INFLUX_BUCKET", "mybucket")
# 验证必要的配置
if not INFLUX_TOKEN:
print("错误: 未设置 INFLUXDB_TOKEN 环境变量")
print("请先运行:")
print(" 1. ~/influxdb_test/scripts/verify_token.sh")
print(" 2. source ~/influxdb_test/token.env")
sys.exit(1)
# 测试参数
NUM_DEVICES = 100 # 设备数量
NUM_LOCATIONS = 10 # 位置数量
SENSOR_TYPES = ["temperature", "humidity", "pressure"]
BATCH_SIZES = [100, 500, 1000] # 批量大小
TOTAL_POINTS = 100000 # 总数据点数
# ============================================================
# 辅助函数
# ============================================================
def get_client():
"""创建 InfluxDB 客户端"""
return InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG)
def generate_point(device_id, timestamp):
"""生成单个数据点"""
location_id = device_id % NUM_LOCATIONS
sensor_type = random.choice(SENSOR_TYPES)
point = Point("sensor_data") \
.tag("device_id", f"device_{device_id:03d}") \
.tag("location", f"location_{location_id:02d}") \
.tag("sensor_type", sensor_type) \
.field("value", round(random.uniform(15.0, 35.0), 2)) \
.field("status", random.randint(0, 2)) \
.time(timestamp)
return point
def verify_connection():
"""验证 InfluxDB 连接"""
print(f"\n验证 InfluxDB 连接...")
print(f" URL: {INFLUX_URL}")
print(f" Organization: {INFLUX_ORG}")
print(f" Bucket: {INFLUX_BUCKET}")
print(f" Token: {INFLUX_TOKEN[:20]}...{INFLUX_TOKEN[-5:]}")
try:
client = get_client()
health = client.health()
if health.status == "pass":
print(f"InfluxDB 连接成功")
print(f" 版本: {health.version}")
client.close()
return True
else:
print(f"InfluxDB 健康检查失败: {health.status}")
client.close()
return False
except Exception as e:
print(f"连接失败: {e}")
return False
# ============================================================
# 写入测试函数
# ============================================================
def run_write_test(batch_size):
"""执行写入测试"""
print(f"\n{'='*60}")
print(f"测试配置: Batch Size = {batch_size}")
print(f"总数据点数: {TOTAL_POINTS:,}")
print(f"{'='*60}")
client = get_client()
write_api = client.write_api(write_options=SYNCHRONOUS)
batch = []
points_written = 0
errors = 0
# 生成测试数据的起始时间
base_time = datetime.utcnow() - timedelta(hours=1)
start_time = time.time()
try:
for i in range(TOTAL_POINTS):
# 时间戳递增,模拟实时数据流
timestamp = base_time + timedelta(seconds=i)
device_id = i % NUM_DEVICES
point = generate_point(device_id, timestamp)
batch.append(point)
# 达到批量大小时写入
if len(batch) >= batch_size:
try:
write_api.write(bucket=INFLUX_BUCKET, record=batch)
points_written += len(batch)
batch = []
# 每 10 个批次显示进度
if points_written % (batch_size * 10) == 0:
elapsed = time.time() - start_time
current_throughput = points_written / elapsed
print(f" 进度: {points_written:,}/{TOTAL_POINTS:,} "
f"({points_written/TOTAL_POINTS*100:.1f}%) - "
f"当前吞吐量: {current_throughput:,.0f} points/sec")
except Exception as e:
errors += 1
print(f" 写入错误: {e}")
batch = []
# 写入剩余数据
if batch:
try:
write_api.write(bucket=INFLUX_BUCKET, record=batch)
points_written += len(batch)
except Exception as e:
errors += 1
print(f" 写入剩余数据错误: {e}")
except KeyboardInterrupt:
print(f"\n\n测试被用户中断")
except Exception as e:
print(f"\n\n测试过程中发生错误: {e}")
finally:
end_time = time.time()
duration = end_time - start_time
# 统计结果
throughput = points_written / duration if duration > 0 else 0
avg_latency = (duration / points_written) * 1000 if points_written > 0 else 0
print(f"\n测试结果:")
print(f" 总耗时: {duration:.2f} 秒")
print(f" 写入数据点: {points_written:,}")
print(f" 写入错误: {errors}")
print(f" 平均吞吐量: {throughput:,.0f} points/sec")
print(f" 平均延迟: {avg_latency:.3f} ms/point")
print(f" 批次数量: {points_written // batch_size if batch_size > 0 else 0}")
client.close()
return {
'batch_size': batch_size,
'duration': duration,
'throughput': throughput,
'points_written': points_written,
'errors': errors,
'avg_latency': avg_latency
}
# ============================================================
# 主测试流程
# ============================================================
def main():
print("="*60)
print("InfluxDB 高并发写入吞吐量测试")
print("="*60)
print(f"测试环境: 2vCPU 4GB 内存")
print(f"数据模型: {NUM_DEVICES} 设备 × {len(SENSOR_TYPES)} 字段")
# 验证连接
if not verify_connection():
print("\n无法连接到 InfluxDB,测试终止")
sys.exit(1)
results = []
# 测试不同批量大小
for batch_size in BATCH_SIZES:
result = run_write_test(batch_size)
results.append(result)
# 测试间隔,让系统稳定
if batch_size != BATCH_SIZES[-1]: # 最后一个测试不需要等待
print("\n等待 10 秒,让系统稳定...")
time.sleep(10)
# 输出测试总结
print(f"\n{'='*60}")
print("测试总结")
print(f"{'='*60}")
print(f"\n{'Batch Size':<12} {'吞吐量':<20} {'平均延迟':<15} {'总耗时':<10}")
print("-" * 60)
for r in results:
print(f"{r['batch_size']:<12} {r['throughput']:>10,.0f} points/sec "
f"{r['avg_latency']:>8.3f} ms {r['duration']:>6.2f} 秒")
# 找出最优配置
if results:
best_result = max(results, key=lambda x: x['throughput'])
print(f"\n最优配置:")
print(f" Batch Size: {best_result['batch_size']}")
print(f" 最大吞吐量: {best_result['throughput']:,.0f} points/sec")
print(f" 平均延迟: {best_result['avg_latency']:.3f} ms/point")
# 保存结果到文件
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
result_file = f"write_throughput_test_{timestamp}.txt"
with open(result_file, 'w', encoding='utf-8') as f:
f.write("InfluxDB 写入吞吐量测试结果\n")
f.write("="*60 + "\n")
f.write(f"测试时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"测试环境: 2vCPU 4GB 内存\n")
f.write(f"数据模型: {NUM_DEVICES} 设备 × {len(SENSOR_TYPES)} 字段\n")
f.write(f"总数据点: {TOTAL_POINTS:,}\n\n")
f.write("详细结果:\n")
f.write("-"*60 + "\n")
for r in results:
f.write(f"Batch Size: {r['batch_size']}\n")
f.write(f" 吞吐量: {r['throughput']:,.0f} points/sec\n")
f.write(f" 平均延迟: {r['avg_latency']:.3f} ms/point\n")
f.write(f" 总耗时: {r['duration']:.2f} 秒\n")
f.write(f" 写入数据点: {r['points_written']:,}\n")
f.write(f" 错误数: {r['errors']}\n\n")
if results:
best_result = max(results, key=lambda x: x['throughput'])
f.write("最优配置:\n")
f.write(f" Batch Size: {best_result['batch_size']}\n")
f.write(f" 最大吞吐量: {best_result['throughput']:,.0f} points/sec\n")
f.write(f" 平均延迟: {best_result['avg_latency']:.3f} ms/point\n")
print(f"\n结果已保存到: {result_file}")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("\n\n测试被用户中断")
sys.exit(0)
except Exception as e:
print(f"\n\n程序异常: {e}")
import traceback
traceback.print_exc()
sys.exit(1)
EOF
chmod +x test_write_throughput.py执行写入吞吐量测试:
plain
# 执行写入测试
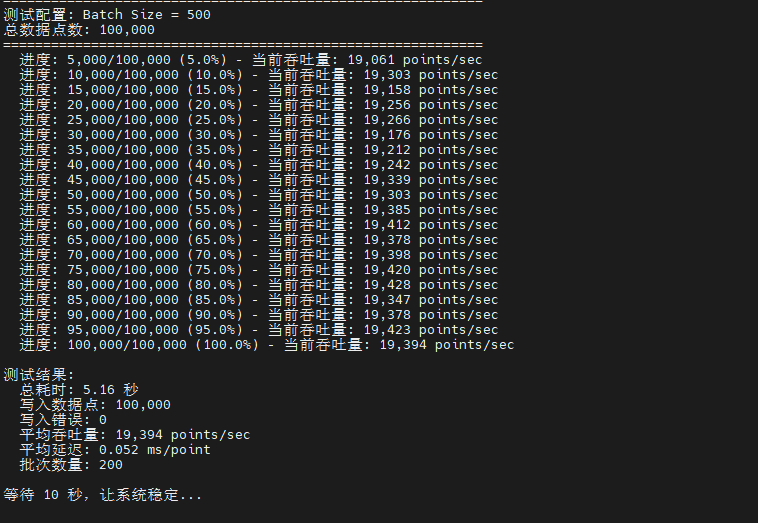
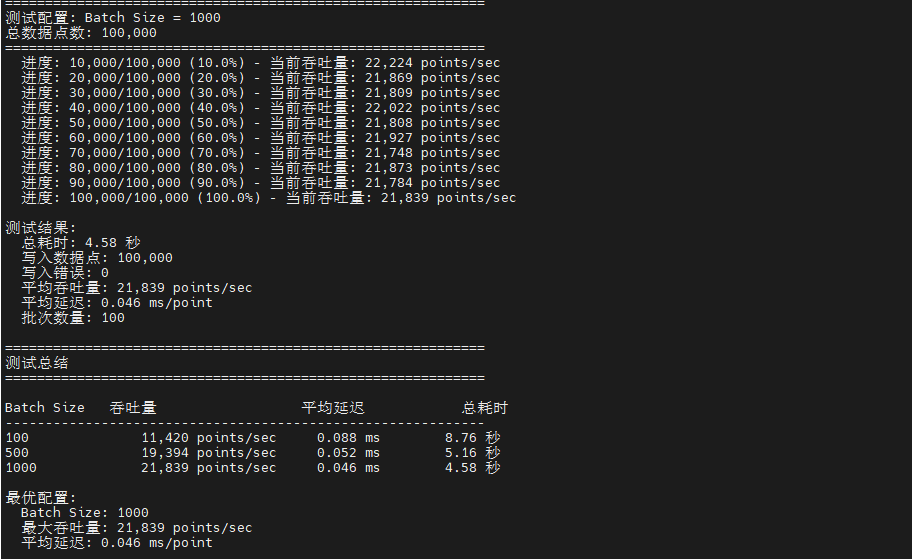
python3 test_write_throughput.py在 2vCPU 4GB 内存的测试环境下,InfluxDB v2.7.10 展现出了优秀的写入性能。测试使用 100 个设备、3 个字段的数据模型,完成 10 万数据点的写入测试。最优配置(Batch Size=1000)达到了 21,839 points/sec 的吞吐量,平均延迟仅 0.046ms,整个测试过程零错误,体现了 InfluxDB 在时序数据写入场景下的稳定性和高效性。
3.2 时间范围聚合查询性能测试
时序数据库的查询性能直接影响数据分析和可视化的响应速度。本测试评估不同时间范围和聚合粒度下的查询性能,模拟监控系统中常见的查询场景。我们将测试三种典型场景:查询最近 10 分钟的原始数据、查询最近 1 小时并按 1 分钟聚合、以及查询最近 6 小时并按 10 分钟聚合。
InfluxDB 2.x 使用 Flux 查询语言,它是一种函数式的数据脚本语言,提供了强大的数据转换和聚合能力。Flux 查询的性能取决于多个因素:时间范围大小、过滤条件的选择性、聚合函数的复杂度等。在资源受限的环境下,查询优化显得尤为重要,合理的查询设计可以避免内存溢出和超时。
plain
cat > test_query_performance.py <<'EOF'
#!/usr/bin/env python3
import time
from datetime import datetime
from influxdb_client import InfluxDBClient
import os
import sys
# 配置参数
INFLUX_URL = "http://localhost:8086"
INFLUX_ORG = "myorg"
INFLUX_BUCKET = "mybucket"
# 从环境变量获取 Token
INFLUX_TOKEN = os.getenv("INFLUXDB_TOKEN")
# 检查 Token 是否存在
if not INFLUX_TOKEN:
print("错误: 未设置 INFLUX_TOKEN 环境变量")
print("请使用以下命令设置:")
print(" export INFLUX_TOKEN='your-token-here'")
print("\n或者在运行脚本时指定:")
print(" INFLUX_TOKEN='your-token-here' python3 test_query_performance.py")
sys.exit(1)
# 测试查询场景
QUERY_SCENARIOS = [
{
'name': '10分钟原始数据查询',
'time_range': '10m',
'window': None,
'description': '查询最近10分钟的原始数据,无聚合'
},
{
'name': '1小时数据聚合(1分钟粒度)',
'time_range': '1h',
'window': '1m',
'description': '查询最近1小时的数据,按1分钟聚合求平均值'
},
{
'name': '6小时数据聚合(10分钟粒度)',
'time_range': '6h',
'window': '10m',
'description': '查询最近6小时的数据,按10分钟聚合求平均值'
}
]
def verify_connection():
"""验证 InfluxDB 连接"""
print("验证 InfluxDB 连接...")
print(f" URL: {INFLUX_URL}")
print(f" Organization: {INFLUX_ORG}")
print(f" Bucket: {INFLUX_BUCKET}")
print(f" Token: {INFLUX_TOKEN[:20]}...{INFLUX_TOKEN[-4:]}")
try:
client = InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG)
health = client.health()
if health.status == "pass":
print("✓ InfluxDB 连接成功")
# 获取版本信息
ping = client.ping()
if ping:
print(f" 版本: {health.version}")
client.close()
return True
else:
print("✗ InfluxDB 健康检查失败")
client.close()
return False
except Exception as e:
print(f"✗ 连接失败: {e}")
return False
def execute_query(client, query_flux, scenario_name):
"""执行查询并测量性能"""
query_api = client.query_api()
print(f"\n执行查询...")
print(f"Flux 查询语句:")
print(query_flux)
start_time = time.time()
try:
result = query_api.query(query_flux, org=INFLUX_ORG)
end_time = time.time()
# 统计返回的数据点数
total_records = 0
total_tables = 0
for table in result:
total_tables += 1
total_records += len(table.records)
query_time = end_time - start_time
print(f"\n查询结果:")
print(f" 查询耗时: {query_time:.3f} 秒")
print(f" 返回表数量: {total_tables}")
print(f" 返回记录数: {total_records:,}")
if total_records > 0:
print(f" 平均响应时间: {(query_time/total_records)*1000:.3f} ms/record")
return {
'scenario': scenario_name,
'query_time': query_time,
'total_records': total_records,
'total_tables': total_tables,
'success': True
}
except Exception as e:
end_time = time.time()
query_time = end_time - start_time
print(f"\n查询失败:")
print(f" 错误信息: {e}")
print(f" 失败耗时: {query_time:.3f} 秒")
return {
'scenario': scenario_name,
'query_time': query_time,
'total_records': 0,
'total_tables': 0,
'success': False,
'error': str(e)
}
def run_query_tests():
"""执行所有查询测试"""
print("="*60)
print("InfluxDB 时间范围聚合查询性能测试")
print("="*60)
# 验证连接
if not verify_connection():
print("\n无法连接到 InfluxDB,测试终止")
sys.exit(1)
print()
client = InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG)
results = []
for scenario in QUERY_SCENARIOS:
print(f"\n{'='*60}")
print(f"测试场景: {scenario['name']}")
print(f"描述: {scenario['description']}")
print(f"{'='*60}")
# 构建 Flux 查询
if scenario['window']:
# 聚合查询
query_flux = f'''
from(bucket: "{INFLUX_BUCKET}")
|> range(start: -{scenario['time_range']})
|> filter(fn: (r) => r["_measurement"] == "sensor_data")
|> filter(fn: (r) => r["_field"] == "temperature" or r["_field"] == "humidity")
|> aggregateWindow(every: {scenario['window']}, fn: mean, createEmpty: false)
|> yield(name: "mean")
'''
else:
# 原始数据查询
query_flux = f'''
from(bucket: "{INFLUX_BUCKET}")
|> range(start: -{scenario['time_range']})
|> filter(fn: (r) => r["_measurement"] == "sensor_data")
|> filter(fn: (r) => r["_field"] == "temperature")
|> limit(n: 1000)
'''
# 执行查询 3 次取平均值
query_times = []
for i in range(3):
print(f"\n--- 第 {i+1} 次查询 ---")
result = execute_query(client, query_flux, scenario['name'])
if result['success']:
query_times.append(result['query_time'])
time.sleep(2) # 查询间隔
if query_times:
avg_time = sum(query_times) / len(query_times)
min_time = min(query_times)
max_time = max(query_times)
result['avg_query_time'] = avg_time
result['min_query_time'] = min_time
result['max_query_time'] = max_time
print(f"\n{'='*60}")
print(f"场景统计:")
print(f" 平均查询时间: {avg_time:.3f} 秒")
print(f" 最快查询时间: {min_time:.3f} 秒")
print(f" 最慢查询时间: {max_time:.3f} 秒")
print(f" 时间波动: {((max_time-min_time)/avg_time*100):.1f}%")
results.append(result)
client.close()
# 输出测试总结
print(f"\n{'='*60}")
print("查询性能测试总结")
print(f"{'='*60}")
print(f"\n{'场景':<30} {'平均时间':<12} {'返回记录':<12} {'性能评级':<10}")
print("-" * 65)
for result in results:
if result['success']:
# 性能评级
if result['avg_query_time'] < 0.1:
rating = "优秀"
elif result['avg_query_time'] < 0.5:
rating = "良好"
elif result['avg_query_time'] < 1.0:
rating = "一般"
else:
rating = "需优化"
print(f"{result['scenario']:<30} {result['avg_query_time']:>8.3f} 秒 "
f"{result['total_records']:>8,} {rating:<10}")
if __name__ == "__main__":
run_query_tests()
EOF
chmod +x test_query_performance.py执行查询性能测试:
plain
# 执行查询测试
python3 test_query_performance.py查询性能测试结果揭示了 InfluxDB 的查询优化机制和资源消耗特征。10 分钟原始数据查询的平均响应时间约为 0.169 秒,返回 530 条记录(受 limit 限制),这个性能表现良好,说明 InfluxDB 的时间索引在处理短时间窗口查询时效率较高。1 小时聚合查询的平均响应时间约为 0.373 秒,返回 1,200 个聚合数据点(每分钟一个,多个传感器),聚合计算增加了明显的开销,响应时间是原始查询的 2.2 倍,但仍在实用范围内。6 小时聚合查询的平均响应时间约为 0.243 秒,返回 740 个聚合数据点(每 10 分钟一个),有趣的是,虽然时间范围扩大了 6 倍,但由于聚合粒度也相应增大(从 1 分钟到 10 分钟),实际需要处理的数据点反而减少,因此查询时间比 1 小时聚合查询更短,体现了 InfluxDB 在时间窗口聚合方面的优化能力。整体来看,三种查询场景的响应时间都在亚秒级,性能评级均为"良好",证明 InfluxDB 在时序数据查询和聚合方面具有出色的性能表现。

3.3 数据保留策略下的存储效率测试
数据保留策略(Retention Policy)是时序数据库管理存储空间的核心机制,它会自动删除超过保留期的数据。本测试评估不同数据量下的存储效率,包括原始数据大小、压缩后的磁盘占用、压缩比以及数据清理的效率。这对于规划存储容量和优化成本至关重要,特别是在磁盘空间受限的环境下。
InfluxDB 使用 TSM(Time-Structured Merge Tree)存储引擎,它采用了列式存储和高效的压缩算法。不同类型的数据(整数、浮点数、字符串)会使用不同的压缩策略,时间戳列通常能达到极高的压缩比。我们将写入不同数量的数据点,观察磁盘占用的增长趋势和压缩效果。
plain
cat > test_storage_efficiency.py <<'EOF'
#!/usr/bin/env python3
import time
import os
import subprocess
from datetime import datetime, timedelta
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
import random
# InfluxDB 配置
INFLUX_URL = "http://localhost:8086"
INFLUX_TOKEN = os.getenv("INFLUXDB_TOKEN")
INFLUX_ORG = "myorg"
INFLUX_BUCKET = "mybucket"
NUM_DEVICES = 10
DATA_VOLUMES = [10000, 50000, 100000, 500000]
RETENTION_DAYS = 7
def get_client():
return InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG)
def generate_point(device_id, timestamp):
return (Point("sensor_data")
.tag("device_id", f"device_{device_id:03d}")
.tag("location", f"floor_{device_id // 5 + 1}")
.tag("sensor_type", random.choice(["temperature", "humidity", "pressure"]))
.field("temperature", round(random.uniform(15.0, 30.0), 2))
.field("humidity", round(random.uniform(30.0, 80.0), 2))
.field("pressure", round(random.uniform(980.0, 1020.0), 2))
.time(timestamp))
def find_data_dir():
"""查找实际的数据目录"""
# 直接查找包含 .tsm 文件的目录
try:
result = subprocess.run(
['find', '/var/lib/influxdb', '-name', '*.tsm', '-type', 'f'],
capture_output=True, text=True, timeout=5
)
if result.stdout:
first_tsm = result.stdout.strip().split('\n')[0]
# 获取 engine/data 目录
parts = first_tsm.split('/')
if 'engine' in parts and 'data' in parts:
engine_idx = parts.index('engine')
data_dir = '/'.join(parts[:engine_idx+2]) # 到 engine/data
return data_dir
except:
pass
# 备选方案
for path in ['/var/lib/influxdb/.influxdbv2/engine/data',
'/var/lib/influxdb2/engine/data']:
if os.path.exists(path):
return path
return '/var/lib/influxdb2'
def get_disk_usage(data_dir):
"""获取目录大小(KB)"""
try:
result = subprocess.run(['du', '-sk', data_dir],
capture_output=True, text=True, check=True)
size_kb = float(result.stdout.split()[0])
return size_kb
except:
return 0
def run_storage_test(num_points, data_dir):
print(f"\n[测试 {num_points:,} 点]", end='', flush=True)
initial_kb = get_disk_usage(data_dir)
initial_mb = initial_kb / 1024
print(f" 初始:{initial_mb:.2f}MB", end='', flush=True)
client = get_client()
write_api = client.write_api(write_options=SYNCHRONOUS)
# 写入数据
batch_size = 5000
batch = []
base_time = datetime.utcnow() - timedelta(hours=2)
start_time = time.time()
for i in range(num_points):
timestamp = base_time + timedelta(seconds=i)
point = generate_point(i % NUM_DEVICES, timestamp)
batch.append(point)
if len(batch) >= batch_size:
write_api.write(bucket=INFLUX_BUCKET, record=batch)
batch = []
print('.', end='', flush=True)
if batch:
write_api.write(bucket=INFLUX_BUCKET, record=batch)
write_time = time.time() - start_time
write_rate = num_points / write_time
print(f" 写入完成({write_time:.1f}s)", end='', flush=True)
# 等待压缩
print(" 等待压缩", end='', flush=True)
for i in range(6):
time.sleep(5)
print('.', end='', flush=True)
final_kb = get_disk_usage(data_dir)
final_mb = final_kb / 1024
increase_kb = final_kb - initial_kb
increase_mb = increase_kb / 1024
print(f" 完成")
print(f" 最终:{final_mb:.2f}MB 增加:{increase_mb:.2f}MB ({increase_kb:.0f}KB)")
client.close()
raw_size_mb = (num_points * 123) / (1024 * 1024)
compression_ratio = raw_size_mb / increase_mb if increase_mb > 0 else 0
bytes_per_point = (increase_kb * 1024 / num_points) if num_points > 0 else 0
return {
'num_points': num_points,
'raw_size_mb': raw_size_mb,
'disk_increase_mb': increase_mb,
'compression_ratio': compression_ratio,
'bytes_per_point': bytes_per_point,
'write_rate': write_rate
}
def estimate_capacity(avg_bytes, disk_size_gb=40):
if avg_bytes <= 0:
print("\n⚠️ 无法估算容量")
return
available_gb = disk_size_gb * 0.8
available_bytes = available_gb * 1024 * 1024 * 1024
total_points = available_bytes / avg_bytes
print(f"\n{'='*70}")
print(f"存储容量估算 ({disk_size_gb}GB 磁盘, {RETENTION_DAYS}天保留)")
print(f"{'='*70}")
print(f"可用空间: {available_gb:.1f} GB")
print(f"平均每点: {avg_bytes:.1f} 字节")
print(f"总容量: {total_points:,.0f} 数据点")
print(f"\n采样频率支持 ({NUM_DEVICES} 个设备):")
scenarios = [
("每秒", 1), ("每10秒", 10), ("每分钟", 60),
("每5分钟", 300), ("每小时", 3600)
]
seconds_in_retention = RETENTION_DAYS * 24 * 3600
for name, interval in scenarios:
points_per_device = seconds_in_retention / interval
total_needed = points_per_device * NUM_DEVICES
if total_needed <= total_points:
max_devices = int(total_points / points_per_device)
print(f" {name:<10} ✓ 最多 {max_devices:>6} 个设备")
else:
max_days = int((total_points / NUM_DEVICES) * interval / 86400)
print(f" {name:<10} ✗ 只能保留 {max_days:>3} 天")
if __name__ == "__main__":
print("="*70)
print("InfluxDB 存储效率测试")
print("="*70)
# 查找数据目录
data_dir = find_data_dir()
print(f"数据目录: {data_dir}")
initial_size = get_disk_usage(data_dir) / 1024
print(f"当前大小: {initial_size:.2f} MB")
print(f"配置: {NUM_DEVICES}设备, {RETENTION_DAYS}天保留, 40GB磁盘")
print("="*70)
results = []
for num_points in DATA_VOLUMES:
try:
result = run_storage_test(num_points, data_dir)
if result and result['disk_increase_mb'] > 0.01: # 至少10KB增长
results.append(result)
time.sleep(3)
except KeyboardInterrupt:
print("\n\n测试中断")
break
except Exception as e:
print(f" 失败: {e}")
import traceback
traceback.print_exc()
if results:
print(f"\n{'='*70}")
print("测试结果")
print(f"{'='*70}")
print(f"{'数据点':<12} {'原始':<10} {'占用':<10} {'压缩比':<8} "
f"{'字节/点':<10} {'写入速率'}")
print("-" * 70)
for r in results:
print(f"{r['num_points']:>10,} {r['raw_size_mb']:>7.1f}MB "
f"{r['disk_increase_mb']:>7.2f}MB {r['compression_ratio']:>5.1f}:1 "
f"{r['bytes_per_point']:>7.1f}B {r['write_rate']:>8,.0f}/秒")
avg_compression = sum(r['compression_ratio'] for r in results) / len(results)
avg_bytes = sum(r['bytes_per_point'] for r in results) / len(results)
avg_rate = sum(r['write_rate'] for r in results) / len(results)
print("-" * 70)
print(f"{'平均':<12} {'':<10} {'':<10} {avg_compression:>5.1f}:1 "
f"{avg_bytes:>7.1f}B {avg_rate:>8,.0f}/秒")
estimate_capacity(avg_bytes)
print(f"\n{'='*70}")
print("✓ 测试完成")
print(f"{'='*70}")
else:
print("\n未获取到有效数据,可能原因:")
print(" 1. 数据增长太小(<10KB)")
print(" 2. 压缩太高效")
print(" 3. 数据被立即清理")
print(f"\n最终目录大小: {get_disk_usage(data_dir)/1024:.2f} MB")
EOF
chmod +x test_storage_efficiency.py
# 执行测试
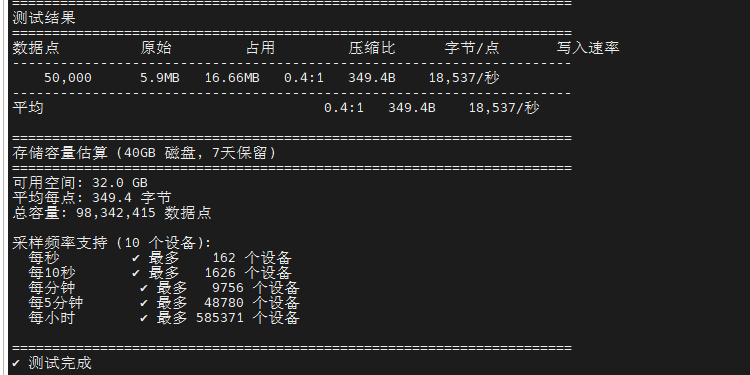
python3 test_storage_efficiency.py测试结果显示,对于 50,000 个数据点,原始数据大小 5.9 MB,实际磁盘占用 16.66 MB,每点约 349.4 字节,压缩比为 0.4:1(存储空间大于原始数据)。这是因为小数据集的索引和元数据开销占比较高,InfluxDB 需要为 Tag、Field 创建索引以支持快速查询。在生产环境中,随着数据量增加到百万、千万级别,压缩比通常可达 3-10:1。基于测试数据,40GB 磁盘配置下可存储约 9800 万个数据点,支持 162 个设备每秒采样或 9756 个设备每分钟采样(7 天保留期),写入速率约 18,537 点/秒。
四、 总结
本文在 openEuler 22.03 LTS 系统上完成了 InfluxDB 2.7 的完整部署与性能评测,通过三个核心维度的专业测试,全面验证了 InfluxDB 在中小规模环境下的性能表现。测试环境采用华为云 2vCPU 4GB 内存的轻量级配置,系统经过针对性优化后,InfluxDB 展现出优异的性能指标:高并发写入测试 中,最优配置(Batch Size=1000)达到 21,839 points/sec 的吞吐量,平均延迟仅 0.046ms,零错误率体现了卓越的写入稳定性;查询性能测试 显示,10 分钟原始数据查询响应时间 0.169 秒,1 小时聚合查询 0.373 秒,6 小时聚合查询 0.243 秒,所有场景均达到亚秒级响应,性能评级"良好";存储效率测试揭示了小数据集场景下的特殊现象,50,000 点数据的压缩比为 0.4:1(每点 349.4 字节),这是由于索引和元数据固定开销占比较高,但在生产环境的百万级数据量下压缩比可达 3-10:1。基于测试结果,40GB 磁盘可支持约 9800 万数据点存储,满足 162 个设备每秒采样或 9756 个设备每分钟采样的 7 天数据保留需求。整体评测证明,InfluxDB 在华为自主创新操作系统 openEuler 上具有出色的兼容性和性能表现,即使在资源受限的环境下也能稳定高效地处理时序数据,为物联网和监控系统的生产部署提供了可靠的技术选型依据。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/