zookeeper: Apache Hadoop生态组件部署分享-zookeeper
hadoop:Apache Hadoop生态组件部署分享-Hadoop
hive: Apache Hadoop生态组件部署分享-Hive
hbase: Apache Hadoop生态组件部署分享-Hbase
impala:Apache Hadoop生态组件部署分享-Impala
spark: Apache Hadoop生态组件部署分享-Spark
sqoop: Apache Hadoop生态组件部署分享-Sqoop
kafak: Apache Hadoop生态组件部署分享-Kafka
一、hue编译
下载地址:https://github.com/cloudera/hue/tree/release-4.11.0
1.1 安装依赖
nginx
yum install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel gmp-devel1.2 执行编译
nginx
make apps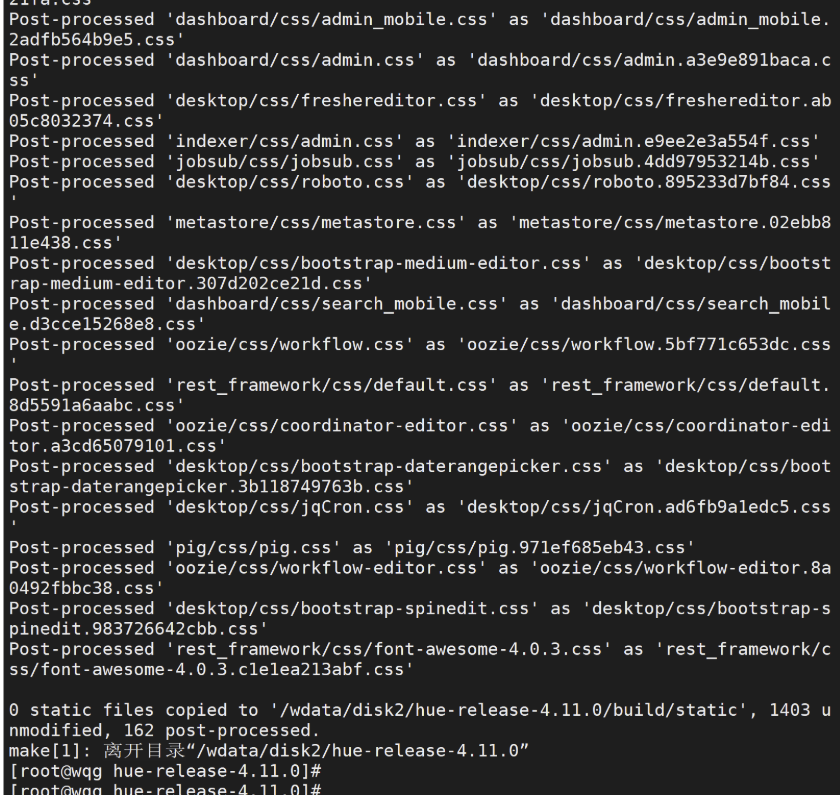
编译好之后打包发送到192.168.242.232机器上
二、hue部署
2.1 解压到指定路径
我这里是/opt/apache_v00/hue-release-4.11.0
2.2 配置pseudo-distributed.ini
vim /opt/apache_v00/hue-release-4.11.0/desktop/conf/pseudo-distributed.ini
ini
[desktop] http_host=192.168.242.232 http_port=8888 [[database]] engine=mysql host=192.168.242.230 port=3306 user=root password=123456 name=hue[hadoop] [[hdfs_clusters]] [[[default]]] fs_defaultfs=hdfs://nameservice1 webhdfs_url=http://192.168.242.230:9870/webhdfs/v1 #缺少此参数,hue hdfs路径无法打开 [[yarn_clusters]] [[[default]]] resourcemanager_host=192.168.242.231[beeswax] hive_server_host=192.168.242.230 hive_server_port=10000 hive_conf_dir=$HIVE_HOME/conf[impala] server_host=192.168.242.230 server_port=21050 use_sasl=false #默认为true,不设置为false, hue impala无法加载元数据
[zookeeper] [[clusters]] [[[default]]] host_ports=apache230.hadoop.com:2181,apache231.hadoop.com:2181,apache232.hadoop.com:21812.3 创建数据库
(192.168.242.230节点执行)
nginx
create database hue;2.4 初始化hue
在数据库中会创建表
bash
build/env/bin/hue syncdbbuild/env/bin/hue migrate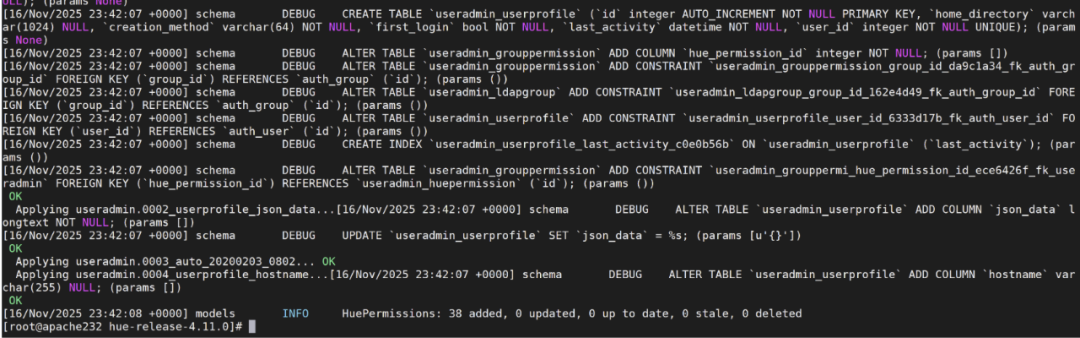
2.5 修改core-site.xml
在hdfs配置中对core-site.xml新增以下配置内容
xml
<property> <name>hadoop.proxyuser.hue.hosts</name> <value>*</value></property>
<property> <name>hadoop.proxyuser.hue.groups</name> <value>*</value></property>然后分发至其他hadoop节点以及hive配置文件中,并重启相关服务
2.5 启动hue
bash
build/env/bin/supervisor浏览器打开页面

由于这是您第一次登录,请选择任何用户名和密码。一定要记住这些,因为它们将成为您的Hue超级用户凭据。
2.6 验证hive
hive情况
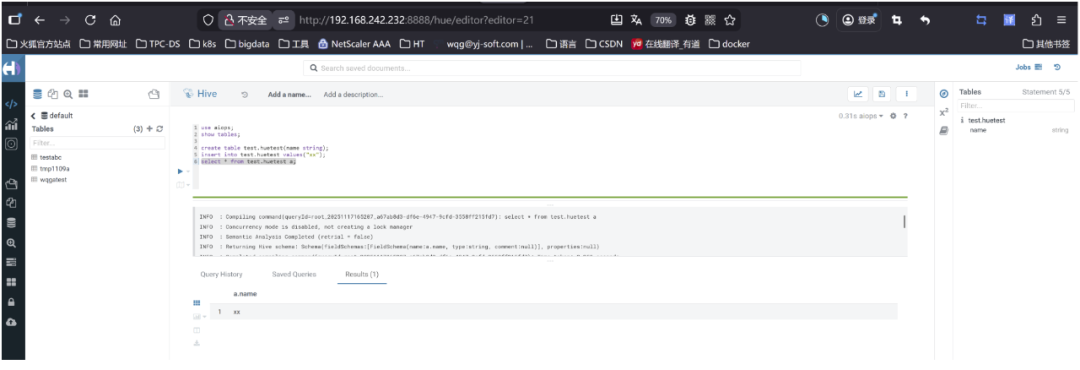
2.7 验证HDFS路径
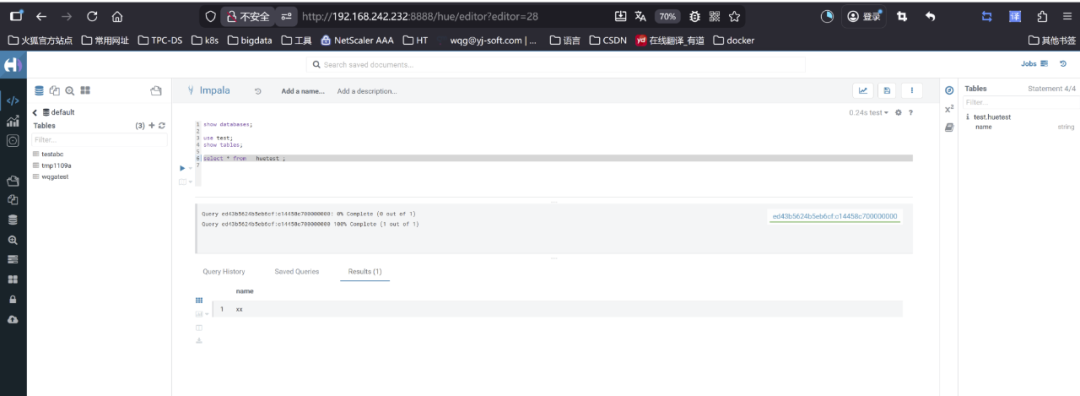
2.8 验证impala