【中间件面试题】Mysql、Redis、MQ、ES、计算机网络
- Mysql
-
- 1、MySQL中的事务隔离级别?
- 2、什么是数据库范式,为什么要反范式?
- 3、binlog、redolog和undolog区别?
-
- [3.1 redolog日志](#3.1 redolog日志)
- [3.2 undolog日志](#3.2 undolog日志)
- [3.3 binlog日志介绍](#3.3 binlog日志介绍)
- [3.4 binlog与redo log对比](#3.4 binlog与redo log对比)
- 4、可能导致索引失效的情况?
- 5、MySQL主从复制的过程?
- 6、如何解决mysql的深分页问题?
- Redis
-
- 1、介绍一下Redis的集群模式?
- 2、介绍一下Redis的持久化机制?
- 3、介绍一下Redis事务机制?
- [4、Redis 的过期策略是怎么样的?](#4、Redis 的过期策略是怎么样的?)
- 5、Redis为什么这么快?
- 6、什么是热Key问题,如何解决热key问题?
- 7、什么是大Key问题,如何解决?
- 8、什么是缓存击穿、缓存穿透、缓存雪崩?
- RocketMQ
- RocketMQ
- RabbitMQ
- ES
- 计算机网络
Mysql
1、MySQL中的事务隔离级别?
对于数据库中相同部分的数据,如果2个事务同时进行操作的话,可能会有数据并发问题。在不保证串行执行的基础上,主要有以下4种数据并发问题(1写3读):
- 脏写
- 脏读
- 不可重复读
- 幻读
针对上面的数据并发问题:1写3读,数据库设立了4种隔离级别。隔离级别越高,数据库的并发性能就越差。由于脏写问题是一个严重的问题,因此这4种隔离级别都解决了脏写问题:
- 读未提交
- 读已提交
- 可重复读
- 串行化
参考链接:https://blog.csdn.net/xueping_wu/article/details/151652054
2、什么是数据库范式,为什么要反范式?
范式(Normal Form )是数据库设计时遵循的一种规范,不同的规范遵循不同的范式。范式可以避免数据冗余,减少数据库的空间,减轻维护数据完整性的麻烦。
- 第一范式(1NF):
属性不可分割。即每个属性都是不可分割的原子项。 - 第二范式(2NF):
联合主键不能存在部分依赖。满足第一范式,并且不存在部分依赖,即非主属性必须完全依赖于主属性。(主属性即主键,完全依赖是针对于联合主键的情况,非主键列不能只依赖于联合主键的一部分)。 - 第三范式(3NF):
非主键字段不能存在传递依赖。满足第二范式,并且不能存在传递依赖。即非主属性不能与非主属性之间有依赖关系,非主属性必须直接依赖于主属性。
等级越高的范式设计出来的表越多,查询存在多表连接时较为耗时。这时可以考虑使用反范式。即用空间来换时间,把数据冗余在多个表中,查询时可以减少表之间的关联。
参考文章:【数据库三大范式和反范式】
3、binlog、redolog和undolog区别?
3.1 redolog日志
InnoDb存储引擎在更新数据时,并不会直接刷新到磁盘上,这样效率和速度都很低。而是会顺序IO写入到redolog日志中,即数据从缓冲池(buffer pool)刷入到redo日志中,该事务就算提交成功了。即使此时数据库系统崩溃了,数据库重启的时候,系统也能从redo日志中将刚刚那次事务的变更刷入到磁盘中。同时由于redo日志时顺序写入,因此速度要比随机IO快很多。
因此,redolog日志保证了事务的持久性,数据库崩溃恢复时,可读取redolog日志,保证事务的原子性和一致性。
3.2 undolog日志
undolog日志主要有2个作用:
作用1:回滚数据
回滚数据时逻辑上地将数据回滚到事务开始前,实际磁盘页上的数据是进行了变更的 。
比如执行insert之前,会写一条delete的语句到undo日志中,一旦事务回滚,则会执行这条delete语句。
作用2:MVCC
InnoDb存储引擎中的MVCC是通过undo日志实现的。当用户读取一行记录时,若该记录已被其他未提交事务占用,当前事务可以通过undo日志读取改行记录之前版本的信息,从而实现了非锁定的读取。
所以,redo日志和undo日志不是正向和反向的关系,他们都属于数据库事务的一种恢复操作,只是解决的问题不同而已。redo日志针对的是事务写过程中,在保证数据持久性的基础上,提升了事务提交的速度。undo日志针对的是事务需要回滚时,能保证数据一致性。
3.3 binlog日志介绍
binlog即binary log,二进制日志文件,记录了数据库所有的DDL和DML等数据库更新事件的语句。它以事件形式记录并保存在二进制文件中,通过这些信息,可以再现数据更新操作的全过程。
binlog主要应用场景:
数据恢复:如果mysql数据库意外停止,可以通过二进制日志文件来查看用户执行了哪些操作,可以根据二进制日志文件中的记录来恢复数据库服务器。数据复制:由于日志的延续性和时效性,master把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
因此mysql数据库的数据备份、主备、主主、主从都离不开binlog,需要依靠binlog来同步数据,保证数据一致性。
3.4 binlog与redo log对比
- redo log 是
物理日志,记录内容是"在某个数据页上做了什么修改",属于innodb存储引擎层产生的。 - binlog 是
逻辑日志,记录内容是语句的原始逻辑,属于mysql server层。 - 他们都属于持久化的保证,但是
侧重点不同:
redo log让innodb存储引擎拥有崩溃恢复能力,持久化保障的的是单台机器 。
binlog保证了mysql集群架构的数据一致性,持久化保障的是多台机器。
参考链接:
主从复制简介
Mysql数据库Redo日志和Undo日志的理解
4、可能导致索引失效的情况?
- 索引列参与了计算。
- 对索引列进行函数操作。
- 隐式类型转换。原理同对索引列进行函数操作。
- 使用OR。如果使用OR的话,并且OR的两边存在<或者>的时候,就会索引失效;如果OR两边都是=判断,并且两个字段都有索引,那么也是可以走索引的。
- like操作。"jack%"和"jack%is"这两种可以走索引,但是如果是"%jack%"和"%jack"就没办法走索引了
- 不等于比较。
- is not null
- order by。当进行order by的时候,如果数据量很小,数据库可能会直接在内存中进行排序,而不使用索引。
- in。使用in的时候,有可能走索引,也有可能不走,一般在in中的值比较少的时候可能会走索引优化,但是如果选项比较多的时候,可能会不走索引。
参考链接:https://blog.csdn.net/xueping_wu/article/details/151652054
5、MySQL主从复制的过程?
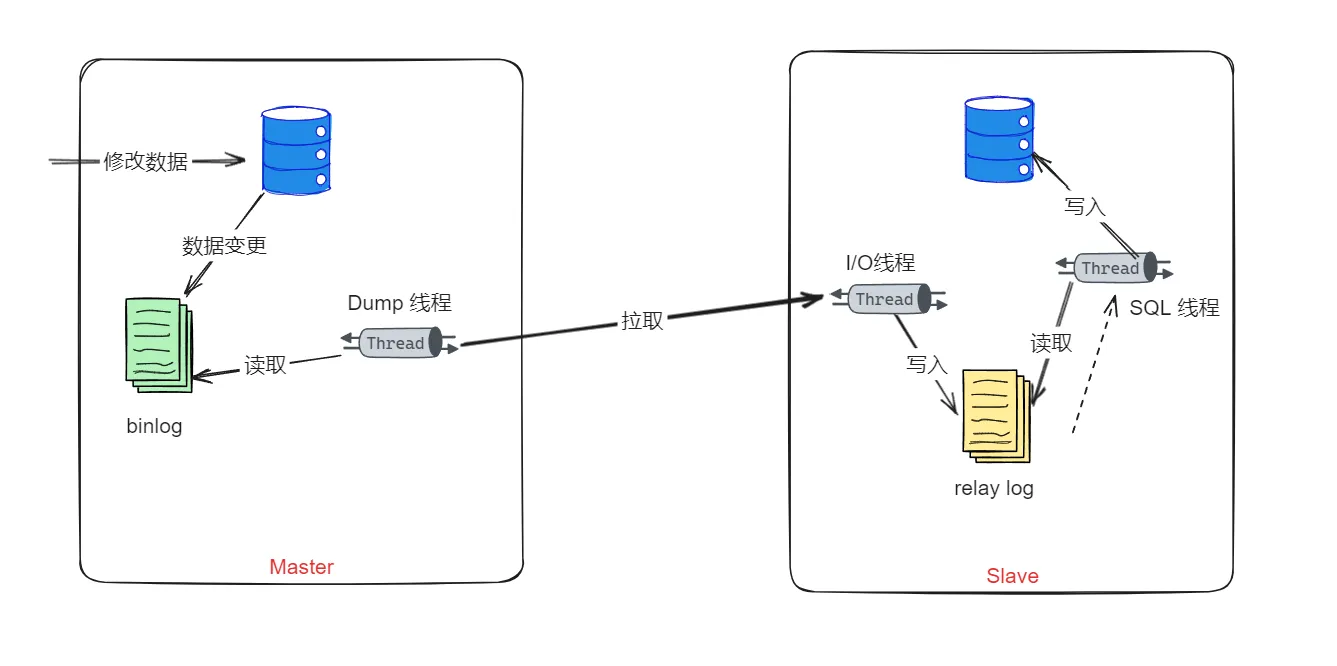
1、从服务器在开启主从复制后,会创建出两个线程:I/O线程和SQL线程
2、从服务器的I/O线程,会尝试和主服务器建立连接,相对应的,主服务中也有一个binlog dump线程, 是专门来和从服务器的I/O线程做交互的。
3、从服务器的I/O线程会告诉主服务的dump线程自己要从什么位置开始接收binlog
4、主服务器在更新过程中,将更改记录保存到自己的binlog中,根据不同的binlog格式,记录的内容可能不一样。
5、在dump线程检测到binlog变化时,会从指定位置开始读取内容,然后会被slave的I/O线程把他拉取过去。
6、从服务器的I/O线程接收到通知事件后,会把内容保存在relay log中。
7、从服务器还有一个SQL线程,他会不断地读取他自己的relay log中的内容,把他解析成具体的操作,然后写入到自己的数据表中。
参考链接:主从复制简介
6、如何解决mysql的深分页问题?
在一个SQL查询语句的顺序中,limit其实是在最后执行的,也就是说,在做完筛选、分组、排序等操作之后,最后进行的limit。因为它是对最终结果集的限制。所以在执行完其他所有操作后,才应用 LIMIT,从而确保查询返回的结果集已经是经过完整处理的。
还有就是,limit的查询中,如果是像 LIMIT 10000, 100 这种形式 ,他会先查询出全部数据(10000+100),然后丢弃前面的结果,再返回需要的部分。 这也是为什么深分页很慢的原因。
可以使用一个子查询来获取限定条件下的一小部分主键id,这部分 id 对应于我们分页的目标区域。然后,使用这些 id 在主查询中获取完整的行数据。
假如我们这样一条SQL:
sql
SELECT c1, c2, cn... FROM table WHERE name = "jack" LIMIT 1000000,10可以基于子查询进行优化,如以下SQL:
sql
SELECT c1, c2, cn...
FROM table
INNER JOIN (
SELECT id
FROM table
WHERE name = "jack"
ORDER BY id
LIMIT 1000000, 10
) AS subquery ON table.id = subquery.id参考链接:https://blog.csdn.net/xueping_wu/article/details/151707135
Redis
1、介绍一下Redis的集群模式?
1、主从模式是Redis最简单的集群模式。这个模式解决了单点故障的问题,将数据复制到多个副本。当主节点发生故障时,可以将一个从节点升级为主节点,实现故障转移,但是需要手动实现。
2、哨兵模式是在主从复制的基础上加入了哨兵节点。哨兵节点是一种特殊的Redis节点,用于监控主节点和从节点的状态。当主节点发生故障时,哨兵节点可以自动进行故障转移,选择一个合适的从节点升级为主节点,并通知其他从节点和应用程序进行更新。通常需要部署多个哨兵节点,以确保故障转移的可靠性。
3、Redis Cluster是Redis中推荐的分布式集群解决方案。它将数据自动分片到多个节点上,每个节点负责一部分数据。 每个分片都有一个主节点和多个从节点。主节点负责处理写操作,而从节点负责复制主节点的数据并处理读请求。Redis Cluster能够自动检测节点的故障。当一个主节点失去连接或不可达时,Redis Cluster会尝试将该节点标记为不可用,并从可用的从节点中提升一个新的主节点。
4、Redis Cluster将整个数据集划分为16384个槽,每个槽都有一个编号(0~16383),集群的每个节点可以负责多个hash槽,客户端访问数据时,先根据key计算出对应的槽编号,然后根据槽编号找到负责该槽的节点,向该节点发送请求。
参考链接:https://blog.csdn.net/xueping_wu/article/details/151993212
2、介绍一下Redis的持久化机制?
1、RDB是将Redis的内存中的数据定期保存到磁盘上,以防止数据在Redis进程异常退出或服务器断电等情况下丢失。
2、AOF是将Redis的所有写操作追加到AOF文件(Append Only File)的末尾,从而记录了Redis服务器运行期间所有修改操作的详细记录。当Redis重新启动时,可以通过执行AOF文件中保存的写操作来恢复数据。如果Redis刚刚执行完一个写命令,还没来得及写AOF文件就宕机了,那么这个命令和相应的数据就会丢失了。但是他也比RDB要更加靠谱一些。
3、AOF和RDB各自有优缺点,为了让用户能够同时拥有上述两种持久化的优点, Redis 4.0 推出了 RDB-AOF 混合持久化。在开启混合持久化的情况下,AOF 重写时会把 Redis 的持久化数据,以 RDB 的格式写入到 AOF 文件的开头,之后的数据再以 AOF 的格式追加的文件的末尾。
参考链接:https://blog.csdn.net/xueping_wu/article/details/151993212
3、介绍一下Redis事务机制?
Redis是支持事务的,他的事务主要目的是保证多个命令执行的原子性,即要在一个原子操作中执行,不会被打断。
需要注意的是,Redis的事务是不支持回滚的。从 Redis 2.6.5 开始,服务器将会在累积命令的过程中检测到错误。然后,在执行 EXEC 期间会拒绝执行事务,并返回一个错误,同时丢弃该事务。如果事务执行过程中发生错误,Redis会继续执行剩余的命令而不是回滚整个事务。
参考链接:https://blog.csdn.net/xueping_wu/article/details/151993212
4、Redis 的过期策略是怎么样的?
Redis 的过期策略采用的是定期删除和惰性删除相结合的方式。
1、定期删除:Redis 默认每隔 100ms 就随机抽取一些设置了过期时间的 key,并检查其是否过期,如果过期才删除。定期删除是 Redis 的主动删除策略,它可以确保过期的 key 能够及时被删除,但是会占用 CPU 资源去扫描 key,可能会影响 Redis 的性能。
2、惰性删除:当一个 key 过期时,不会立即从内存中删除,而是在访问这个 key 的时候才会触发删除操作。惰性删除是 Redis 的被动删除策略,它可以节省 CPU 资源,但是会导致过期的 key 始终保存在内存中,占用内存空间。
参考链接:https://blog.csdn.net/xueping_wu/article/details/151993212
5、Redis为什么这么快?
Redis 之所以如此快,主要有以下几个方面的原因:
- 基于内存:Redis 是一种基于内存的数据库,数据存储在内存中,数据的读写速度非常快,因为内存访问速度比硬盘访问速度快得多。
- 单线程模型:Redis 使用单线程模型,这意味着它的所有操作都是在一个线程内完成的,不需要进行线程切换和上下文切换。这大大提高了 Redis 的运行效率和响应速度。
- 多路复用 I/O 模型:Redis 在单线程的基础上,采用了I/O 多路复用技术,实现了单个线程同时处理多个客户端连接的能力,从而提高了 Redis 的并发性能。
- 高效的数据结构:Redis 提供了多种高效的数据结构,如哈希表、有序集合、列表等,这些数据结构都被实现得非常高效,能够在 O(1) 的时间复杂度内完成数据读写操作,这也是 Redis 能够快速处理数据请求的重要因素之一。
- 多线程的引入:在Redis 6.0中,为了进一步提升IO的性能,引入了多线程的机制。采用多线程,使得网络处理的请求并发进行,就可以大大的提升性能。多线程除了可以减少由于网络 I/O 等待造成的影响,还可以充分利用 CPU 的多核优势。
参考链接:https://blog.csdn.net/xueping_wu/article/details/151993842
6、什么是热Key问题,如何解决热key问题?
同一个时间点上,Redis中的同一个key被大量访问,这样的Key可以成为热Key。
解决热Key的方式:
1、根据经验,提前预测。对可能出现的热Key做方案。
2、多级缓存。增加本地缓存,对热点数据提前返回。
3、热Key拆分,不同节点保存一部分数据,最后汇总或者降级只返回一部分数据。
参考链接:https://blog.csdn.net/xueping_wu/article/details/152005205
7、什么是大Key问题,如何解决?
一个Key的值很大,或者Key对应的value占用空间很多,则称为大Key。
大Key的定义:对于 String 类型的 Value 值,值超过 5MB;对于 Set 类型或者List类型的 Value 值,含有的成员数量为 10000 个。
如何解决:
1、拆分大Key:在业务代码中,将一个big key有意的进行拆分,比如根据日期或者用户尾号之类的进行拆分。使用小键替代大键可以有效减小存储空间。
2、通过合理的设置缓存TTL,避免过期缓存不及时删除而增大key大小。
3、将大键转移存放在数据库中。
参考链接:https://blog.csdn.net/xueping_wu/article/details/152005205
8、什么是缓存击穿、缓存穿透、缓存雪崩?
1、缓存击穿
是指当某一key的缓存过期时,大并发量的请求同时访问此key,瞬间击穿缓存服务器直接访问数据库,让数据库处于负载的情况。
解决方式有2个:一个是访问数据库之前加互斥锁,保证获取锁的线程才能访问数据库,否则需要阻塞。第二个是异步任务定时更新缓存,在缓存失效前进行更新。
2、缓存穿透
是指缓存服务器中没有缓存数据,数据库中也没有符合条件的数据,导致业务系统每次都绕过缓存服务器查询下游的数据库,缓存服务器完全失去了其应有的作用。
解决方式有2个:一个是缓存空值,缓存中查到的是空值而不是null,说明之前已经查过了,就不会再查数据库了。第二个是使用布隆过滤器(Bloom Filter),可以判断出哪些值是一定不存在的。
3、缓存雪崩
是指当大量缓存同时过期或缓存服务宕机,所有请求的都直接访问数据库,造成数据库高负载,影响性能,甚至数据库宕机。
解决方式可以设置不同的过期时间,可以把不同的key过期时间设置成不同的, 并且通过定时刷新的方式更新过期时间。
参考链接:https://blog.csdn.net/xueping_wu/article/details/152005205
RocketMQ
参考链接:https://blog.csdn.net/xueping_wu/article/details/152077959?spm=1001.2014.3001.5501
1、Kafka的架构是怎么样的?
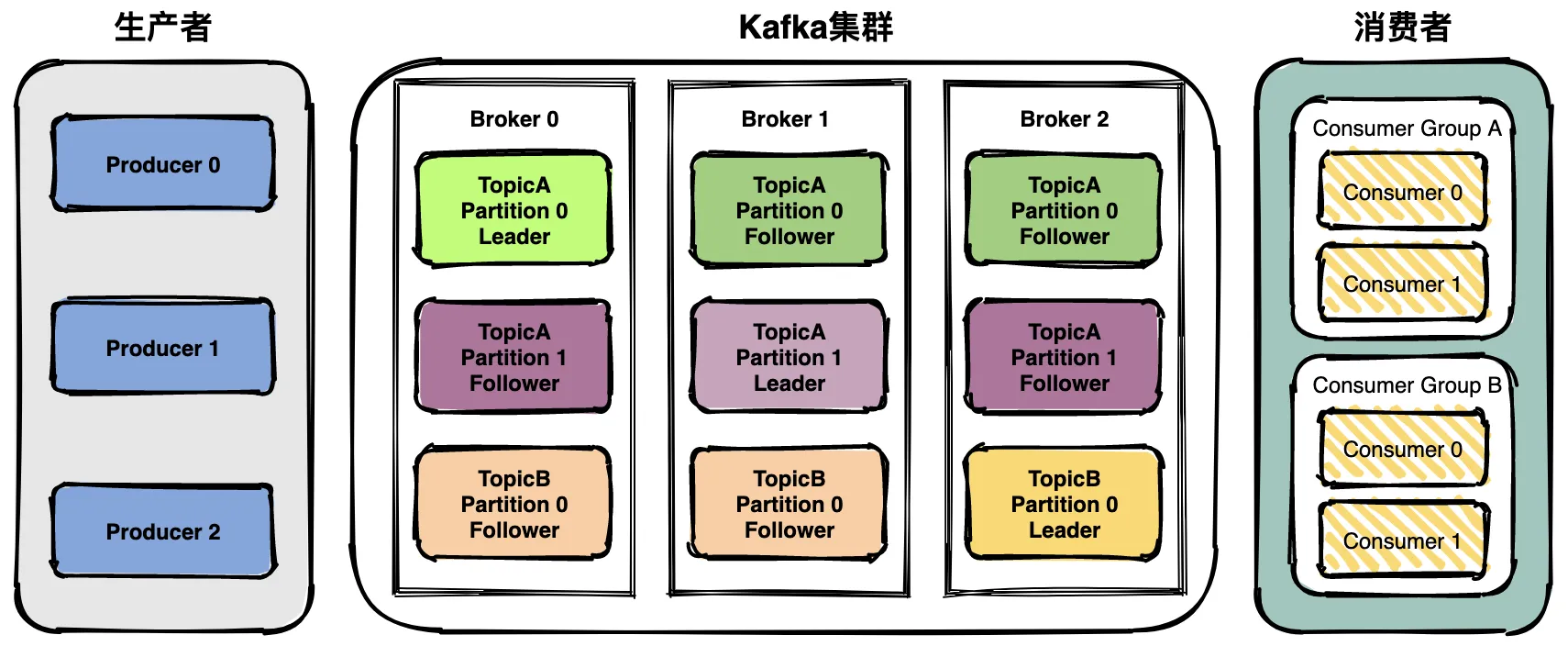
Kafka主要由生产者、kafka集群、消费者组成。
Kafka集群是由多个Broker组成的分布式系统,每一个broker中存放某一个topic的leader partition,该topic的副本partition分布在其他broker中,通过将Topic分成多个Partition,可以实现提升吞吐量、负载均衡、以及增加可扩展性。
2、Kafka如何保证消息不丢失?Kafka能否100%保证消息不丢失?
如何保证消息不丢失:
生产者角度,通常会建议使用producer.send(msg, callback)方法,这个方法支持传入一个callback,我们可以在消息发送时进行重试。其次是ack确认机制配置为需要leader和副本都确认接收成功才进行确认。
broker角度,通过持久化机制和副本机制,来保证消息不丢失。
消费者角度,确认消息处理成功后,再手动提交偏移量。
Kafka不能100%保证消息不丢失,主要原因是在生产者发送消息后,broker集群发生崩溃后,可能导致消息丢失。
如果生产者在发送消息之后,Kafka的集群发生故障或崩溃,而消息尚未被完全写入Kafka的日志中,那么这些消息可能会丢失。虽然后续有可能会重试,但是,如果重试也失败了呢?如果这个过程中刚好生产者也崩溃了呢?那就可能会导致没有人知道这个消息失败了,就导致不会重试了。
3、Kafka如何确保不重复消费?
消费者可以通过手动提交消费位移来控制消息的消费情况。通过手动提交位移,消费者可以跟踪自己已经消费的消息,确保不会重复消费同一消息。
另外可以借助Kafka的Exactly-once消费语义配置,通过引入了事务,消费者使用事务来保证消息的消费和位移提交是原子的。
4、Kafka如何实现顺序消费?
Kafka的消息是存储在指定的topic中的某个partition中的。并且一个topic是可以有多个partition的。同一个partition中的消息是有序的,但是跨partition,或者跨topic的消息就是无序的了。实现顺序消费,有以下2个方式:
1、在一个topic中,只创建一个partition,这样这个topic下的消息都会按照顺序保存在同一个partition中,这就保证了消息的顺序消费。
2、发送消息的时候指定partition,如果一个topic下有多个partition,那么我们可以把需要保证顺序的消息都发送到同一个partition中,这样也能做到顺序消费。
5、Kafka的事务消息是怎样的?
在Kafka中,事务消息可以确保一组生产或消费操作要么全部成功,要么全部失败,以保证消息处理的原子性。也就是说,他的作用是保证一组消息要么都成功,要么都失败。
只不过,通常在分布式系统中,我们通常说的事务消息,如RocketMQ的事务消息保证的是本地事务和发MQ能作为一个原子性,即要么一起成功,要么一起失败。
所以,Kafka的事务消息只保证他自己的消息发送的原子性。而RocketMQ的事务消息是保证本地事务和发消息的原子性。
RocketMQ
参考链接:https://blog.csdn.net/xueping_wu/article/details/152165937?spm=1001.2014.3001.5501
1、RocketMQ的架构是怎么样的?
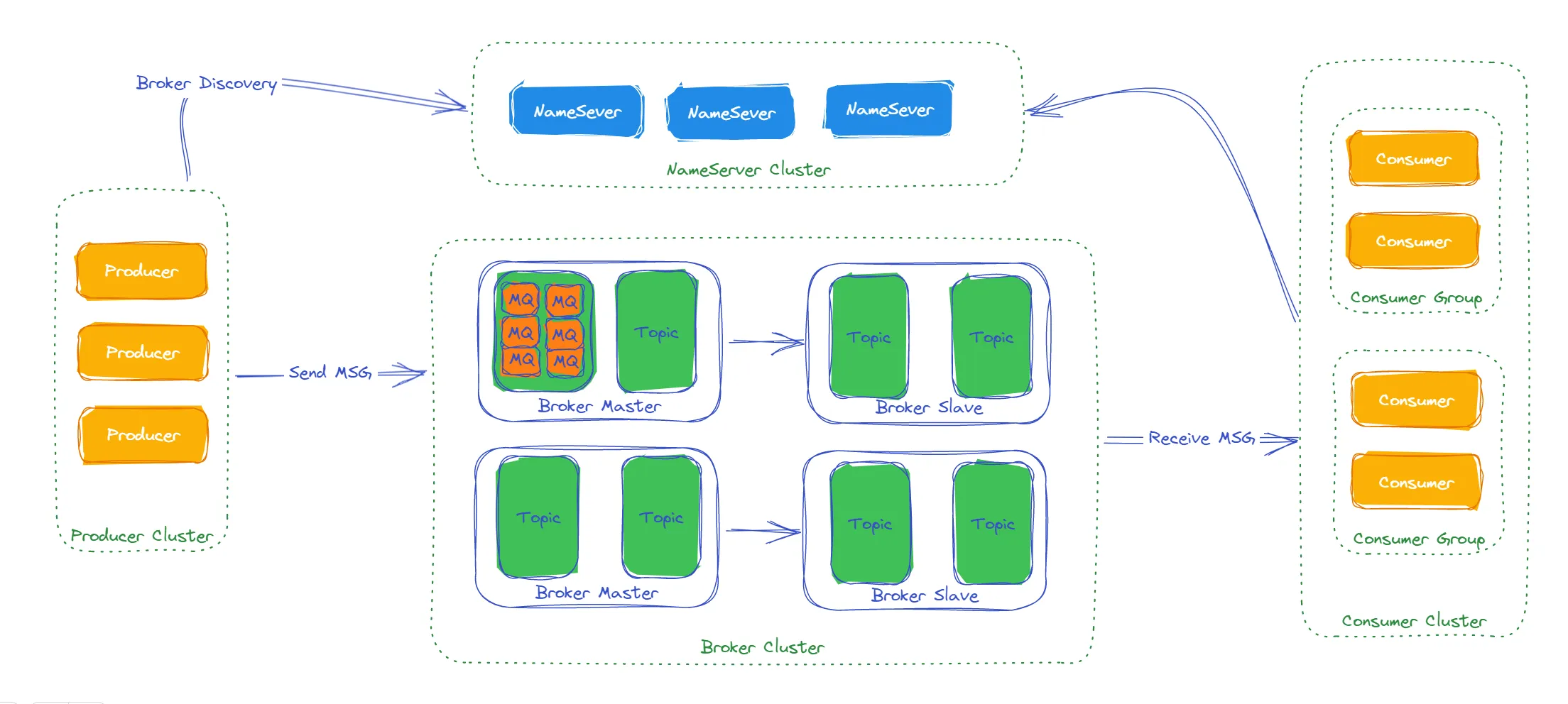
RocketMQ主要由NameServer、Broker、Producer和Consumer组成。
NameServer是RocketMQ的路由和寻址中心,它维护了Broker和Topic的路由信息,提供了Producer和Consumer与正确的Broker建立连接的能力。NameServer还负责监控Broker的状态,并提供自动发现和故障恢复的功能。
Broker可以包含多个topic,每一个topic中可以包含多个mq队列。
RocketMQ的消费主要有2种方式,一种是广播消费,一种是集群消费,集群消费模式下,一条消息被任意消费者消费,就会提交偏移量。
2、RocketMQ如何保证消息不丢失?RocketMQ能否100%保证消息不丢失?
如何保证消息不丢失,可以从生产者、broker、消费者3个角度看:
生产者角度,可以使用同步发送和异步发送,异步发送需要在失败回调中做好重试。需要将消息保存机制修改为同步刷盘,这样,Broker会在同步请求中把数据保存在磁盘上,确保保存成功后再返回确认结果给生产者。
broker角度,Broker 通常采用一主多从部署方式,并且采用配置同步复制的方式,即Master在将数据同步到Slave节点后,再返回给生产者确认结果。
消费者角度,确认消息处理成功后,再手动提交偏移量。
RocketMQ和Kafka一样,都不能100%保证消息不丢失,主要原因是在生产者发送消息后,broker集群发生崩溃,可能导致消息丢失。
如果生产者在发送消息之后,Kafka的集群发生故障或崩溃,而消息尚未被完全写入Kafka的日志中,那么这些消息可能会丢失。虽然后续有可能会重试,但是,如果重试也失败了呢?如果这个过程中刚好生产者也崩溃了呢?那就可能会导致没有人知道这个消息失败了,就导致不会重试了。
3、RocketMQ如何确保不重复消费?
消费者确认消费成功后,再发送消费成功给broker。同时针对消费处理超时、网络抖动导致的重复发送消息问题,需要在消费者端做好幂等。
4、RocketMQ如何实现顺序消费?
和Kafka只支持同一个Partition内消息的顺序性一样,RocketMQ中也提供了基于队列(分区)的顺序消费。即同一个队列内的消息可以做到有序,但是不同队列内的消息是无序的!
站在生产者角度,根据选择发送到哪个队列中。站在消费者角度,需要选择有序消费模式。
为了保证有序消费,需要三次加锁:
1、先锁定Broker上的MessageQueue,确保消息只会投递到唯一的消费者
2、消费者对本地的MessageQueue加锁,确保只有一个线程能处理这个消息队列
3、对存储消息的ProcessQueue加锁(broker中的topic加锁),确保在重平衡的过程中不会出现消息的重复消费。
5、RocketMQ的事务消息是怎样的?
在发送事务消息时,首先向RocketMQ Broker发送一条"half消息"(即半消息),半消息将被存储在Broker端的事务消息日志中,但是这个消息还不能被消费者消费。
接下来,应用程序通过执行本地事务来确定是否要提交该事务消息。如果本地事务执行成功,就会通知RocketMQ Broker提交该事务消息,使得该消息可以被消费者消费;否则,就会通知RocketMQ Broker回滚该事务消息,该消息将被删除,从而保证消息不会被消费者消费。
RabbitMQ
参考链接:https://blog.csdn.net/xueping_wu/article/details/152256859?spm=1001.2014.3001.5501
1、RabbitMQ的架构是怎样的?
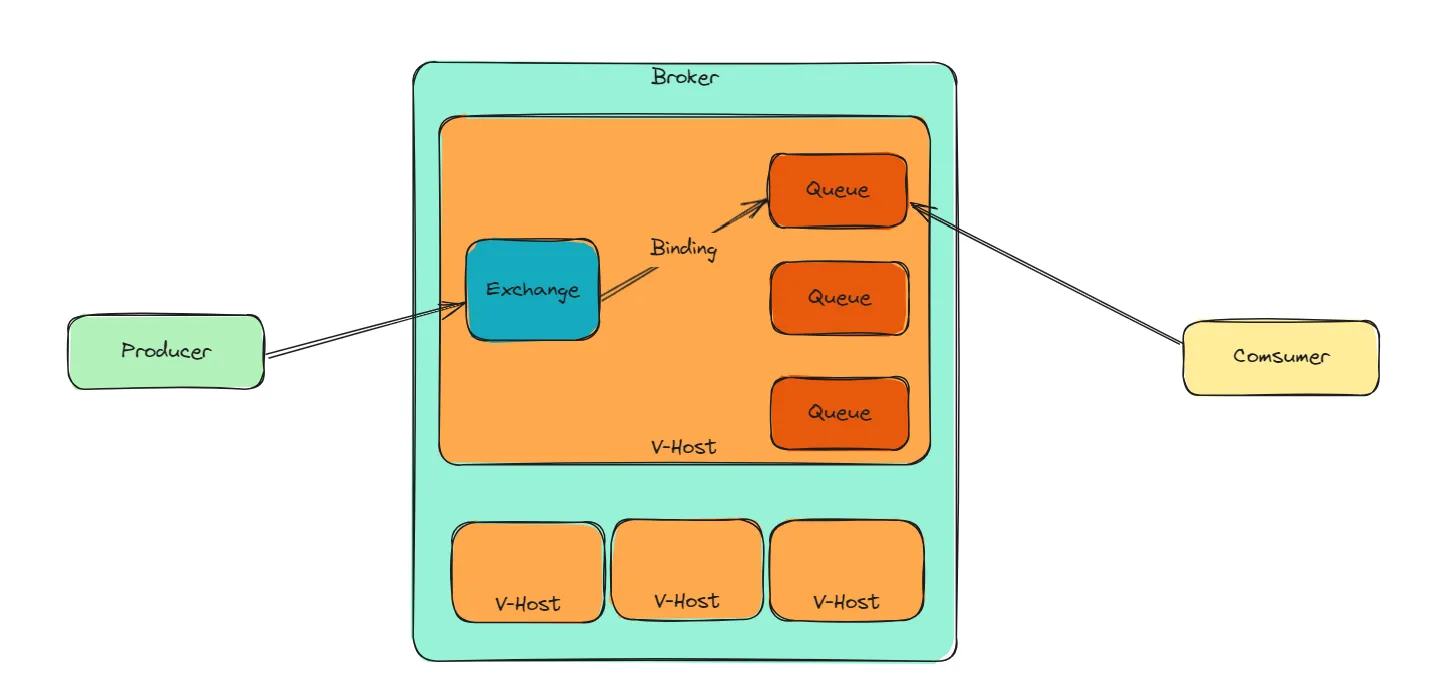
RabbitMQ主要由生产者、虚拟主机、消费者组成,虚拟主机中包含交换器、队列和绑定关系。
RabbitMQ一共有6种工作模式(消息分发方式),分别是简单模式、工作队列模式、发布订阅模式、路由模式、主题模式以及RPC模式。
集群模式主要有2种模式:
1、普通集群模式。将 RabbitMQ 实例部署到多台服务器上,多个实例之间协同工作,共享队列和交换机的元数据。在这种模式下,创建的Queue,它的元数据(配置信息)会在集群中的所有实例间进行同步,但是队列中的消息只会存在于一个 RabbitMQ 实例上,而不会同步到其他队列。这种方式在高可用上有一定的帮助,不至于一个节点挂了就全都挂了。但是也还有缺点,至少这个实例上的数据是没办法被读写了。
2、镜像集群模式。每一台RabbitMQ都像一个镜像一样,存储的内容都是一样的。这种模式下,Queue的元数据和消息数据不再是单独存储在某个实例上,而是集群中的所有实例上都存储一份。这样每次在消息写入的时候,就需要在集群中的所有实例上都同步一份,这样即使有一台实例发生故障,剩余的实例也可以正常提供完整的数据和服务。
2、RabbitMQ如何保证消息不丢失?RabbitMQ能否100%保证消息不丢失?
1、生产者角度。通过confirm机制,在消息到达交换器和队列后,分别返回ack结果。
2、mq角度。一个是对队列、交换器都设置为持久化。第二个是发送消息时将消息的deliveryMode设置为持久化,此时队列中的消息才会持久化到磁盘。
3、消费者角度。消费者处理消息成功后向MQ发送ack回执,MQ收到ack回执后才会删除该消息,这样才能确保消息不会丢失。
虽然我们通过发送者端进行异步回调、MQ进行持久化、消费者做确认机制,但是也没办法保证100%不丢,因为MQ的持久化过程其实是异步的。即使我们开了持久化,也有可能在内存暂存成功后,异步持久化之前宕机了,那么这个消息就会丢失。
如果想要做到100%不丢失,就需要引入本地消息表,来通过轮询的方式来进行消息重投。
3、RabbitMQ如何确保不重复消费?
RabbitMQ的消息消费是有确认机制的,正常情况下,消费者在消息消费成功后,会发送一个确认消息,消息队列接收到之后,就会将该消息从消息队列中删除,下次也就不会再投递了。
但是如果存在网络延迟的问题,导致确认消息没有发送到消息队列,导致消息重投了,是有可能的。所以,当使用RabbitMQ的时候,消费者端自己也需要做好幂等控制来防止消息被重复消费。
4、RabbitMQ如何实现顺序消费?
根据路由键将消息路由到指定队列,队列对应多个消费者。通过 basicQos(1) 保证每个消费者一次只处理一条消息,做到顺序消费的同时,保证消费能力。
5、RabbitMQ的事务消息是怎样的?
RabbitMQ的事务机制,允许生产者将一组操作打包成一个原子事务单元,要么全部执行成功,要么全部失败。事务提供了一种确保消息完整性的方法,但需要谨慎使用,因为它们对性能有一定的影响。
因为事务机制是同步的,提交一个事务之后会阻塞在那儿,但是 confirm机制是异步的,发送一个消息之后就可以发送下一个消息,RabbitMQ 接收了之后会异步回调confirm接口通知这个消息接收到了。一般在生产者这块避免数据丢失,建议使用用 confirm 机制。
ES
参考链接:https://blog.csdn.net/xueping_wu/article/details/152410509?spm=1001.2014.3001.5501
1、什么场景下会使用es?
1、搜索引擎
电商网站的商品搜索、站内搜索、模糊查询、全文检索服务。
2、非关系型数据库
业务宽表(数据库字段太多,查询太慢,索引没有办法再做优化)
,数据库做统计查询。
3、大数据近实时分析引擎
4、日志分析
2、什么是倒排索引?
倒排索引的结构与传统的索引结构相反,传统的索引结构是由文档构成的,每个文档包含了若干个词汇,然后根据这些词汇建立索引。而倒排索引是由词汇构成的,每个词汇对应了若干个文档,然后根据这些文档建立索引。
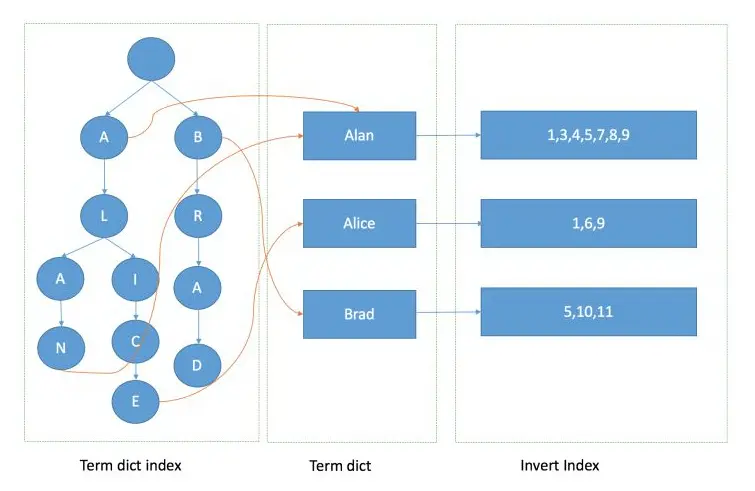
3、什么是ElasticSearch的深度分页问题?如何解决?
在Elasticsearch中进行分页查询通常使用from和size参数。发起一个带有分页参数的查询时,ES需要遍历所有匹配的文档直到达到指定的起始点(from),然后返回从这一点开始的size个文档。
**深度分页需要数据库在内存中维护大量的数据,并对这些数据进行排序和处理,这会消耗大量的CPU和内存资源。随着分页深度的增加,查询响应时间会显著增加。**在某些情况下,这可能导致查询超时或者系统负载过重。这就是深度分页问题。
search_after 是 Elasticsearch 中用于实现深度分页的一种机制。与传统的分页方法(使用 from 和 size 参数)不同,search_after 允许你基于上一次查询的结果来获取下一批数据,这在处理大量数据时特别有效。
在第一次查询时,需要定义一个排序规则,不需要指定 search_after 参数。下一次查询时就可以带上search_after参数,不需要处理每个分页请求中所有先前页面上的数据。这大大减少了处理数据的工作量。
计算机网络
1、为什么TCP握手建立链接可以3次,而挥手关闭连接需要4次?
TCP 握手的时候,接收端发送 SYN+ACK 的包是将一个 ACK 和一个 SYN 合并到一个包中,所以减少了一次包的发送,三次完成握手。
对于四次挥手,因为 TCP 是全双工通信,在主动关闭方发送 FIN 包后,接收端可能还要发送数据,不能立即关闭服务器端到客户端的数据通道,所以也就不能将服务器端的 FIN 包与对客户端的 ACK 包合并发送,只能先确认 ACK,然后服务器待无需发送数据时再发送 FIN 包,所以四次挥手时必须是四次数据包的交互。
2、HTTP各个版本之间的区别?
HTTP/1.0
1、HTTP/1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接。由于TCP连接的建立需要三次握手,是很耗费时间的一个过程。所以,HTTP/1.0版本的性能比较差。
HTTP/1.1
1、为了解决1.0中短连接的问题,HTTP/1.0引入了持久连接。所谓的持久连接就是:在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。引入了持久连接之后,在性能方面,HTTP协议有了明显的提升,基本可以用于日常使用,这也是这一版本一直延用至今的原因。
HTTP/2
1、HTTP/2做了大量优化改进,性能上有了显著提升。同时请求 379 张图片,HTTP/1.1加载用时4.54s,HTTP/2加载用时1.47s。
2、在HTTP/2中,在应用层(HTTP2.0)和传输层(TCP或者UDP)之间加了一层:二进制分帧层。在二进制分帧层中, HTTP/2 会将所有传输的信息分割为更小的消息和帧(frame),并对它们采用二进制格式的编码。
这是HTTP2中最大的改变。HTTP2之所以性能会比HTTP1.1有那么大的提高,很大程度上正是由于这一层的引入。
3、解决了HTTP队头阻塞问题。
HTTP/1.1通过管道化保持持久连接,但是管道连接要求服务端必须按照与请求相同的顺序回送HTTP响应。这也就意味着,如果一个响应返回发生了延迟,那么其后续的响应都会被延迟,直到队头的响应送达。这就是所谓的HTTP队头阻塞。
HTTP/2废弃了管道化的方式,而是创新性的引入了帧、消息和数据流等概念。客户端和服务器可以把 HTTP 消息分解为互不依赖的帧,然后乱序发送,最后再在另一端把它们重新组合起来。因为没有顺序了,所以就不需要阻塞了,就有效的解决了HTTP队头阻塞的问题。
HTTP/2虽然解决了HTTP 队头阻塞的问题。HTTP/2仍然存在TCP队头阻塞的问题,那是因为HTTP/2其实还是依赖TCP协议实现的。
TCP传输过程中会把数据拆分为一个个按照顺序排列的数据包,这些数据包通过网络传输到了接收端,接收端再按照顺序将这些数据包组合成原始数据,这样就完成了数据传输。但是如果其中的某一个数据包没有按照顺序到达,接收端会一直保持连接等待数据包返回,这时候就会阻塞后续请求。这就发生了TCP队头阻塞。
HTTP/3
HTTP/3为了解决TCP队头阻塞问题,改成了基于QUIC协议实现。QUIC协议一种完全基于UDP的协议,虽然UDP是不可靠传输协议,但是QUIC在UDP的基础上做了些改造,使得他提供了和TCP类似的可靠性。它提供了数据包重传、拥塞控制、调整传输节奏以及其他一些TCP中存在的特性。