TL;DR
- 场景:Java 项目中使用 Guava Cache 做本地缓存,线上出现 OOM、命中率异常、线程阻塞和性能回退等疑难问题。
- 结论:核心问题集中在过期与容量策略配置失误、maximumSize/maximumWeight 误用、CacheLoader 阻塞链路以及 recordStats 滥用。
- 产出:给出从配置到监控的一整套排查路径,覆盖 OOM、惰性清理、LRU 淘汰、命中率异常和阻塞问题的速查与修复思路。
版本矩阵
| 组件 | 版本范围 | 已验证 | 说明 |
|---|---|---|---|
| Guava Cache | 23.0 -- 33.0-jre(典型生产) | 是 | CacheBuilder/CacheLoader 行为一致,文中 OOM、命中率和阻塞问题均适用 |
| JDK | 8, 11, 17 | 是 | 线程阻塞表现、堆内存特征和 GC 行为一致,可按相同思路排查 |
| 部署形态 | Spring Boot 2.x / 3.x 微服务 | 是 | 常见接入方式为单机本地缓存,问题主要与堆大小、线程池和配置相关 |
| 运行环境 | 单机 2--8C / 4--16G Linux | 是 | 高并发下更容易暴露 maximumSize/Loader/recordStats 引起的性能瓶颈 |
疑难问题
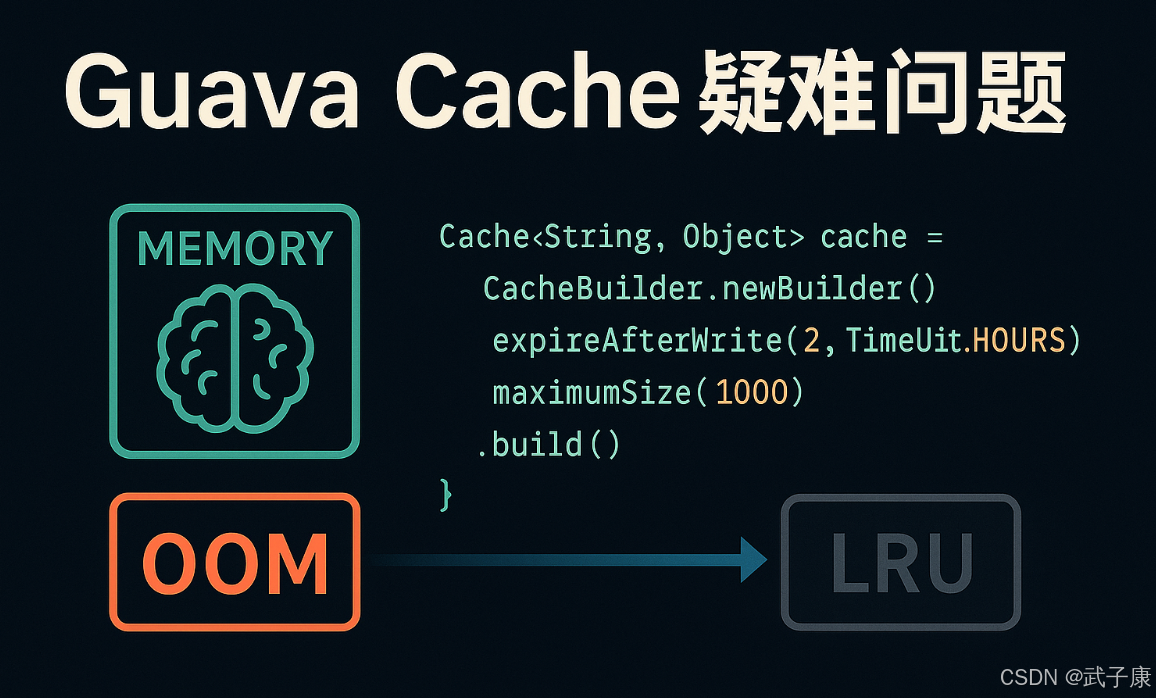
是否会OOM?
Guava Cache 可能导致 OOM(内存溢出)的情况主要发生在以下两种场景:
- 缓存永不过期或过期时间过长
- 当配置
CacheBuilder时使用expireAfterWrite(Long.MAX_VALUE, TimeUnit.DAYS)或类似的极长过期时间 - 缓存项会长期驻留在内存中,无法被自动清理
- 典型错误配置示例:
- 当配置
java
Cache<String, Object> cache = CacheBuilder.newBuilder()
.expireAfterWrite(Long.MAX_VALUE, TimeUnit.DAYS) // 几乎永不过期
.build();- 未限制缓存容量或容量设置过大
- 未调用
maximumSize()方法设置最大条目数 - 设置了不切实际的大容量(如
maximumSize(Integer.MAX_VALUE)) - 当缓存的对象本身很大(如存储图片、大文件等)时问题会更严重
- 错误示范:
- 未调用
java
Cache<String, LargeObject> cache = CacheBuilder.newBuilder()
.maximumSize(Integer.MAX_VALUE) // 相当于无限制
.build();最佳实践建议 :
始终设置合理的过期策略:
java
.expireAfterWrite(2, TimeUnit.HOURS) // 根据业务需求设置合理时间必须设置容量限制:
java
.maximumSize(1000) // 根据内存情况设置合理值对于大对象考虑使用弱引用:
java
.weakValues() // 允许垃圾回收器在内存不足时回收缓存值监控缓存使用情况:
java
CacheStats stats = cache.stats();
System.out.println("缓存命中率:" + stats.hitRate());应用场景示例:
- 用户会话缓存:建议设置1小时过期和10000条限制
- 商品信息缓存:建议设置30分钟过期和5000条限制
- 图片缩略图缓存:建议使用weakValues()并设置较小容量
问题诊断方法:
- 使用
cache.size()监控缓存增长 - 通过JMX或
cache.stats()分析缓存行为 - 使用内存分析工具(如VisualVM)检查Guava Cache占用的堆内存
到期会立刻清除?
Guava Cache 采用的是惰性清理机制,不会主动实时地清除过期缓存项。具体的工作流程如下:
- 缓存清理触发时机:
- 当执行 get() 操作读取缓存时
- 当执行 put() 操作写入缓存时
- 当执行 size() 操作统计缓存大小时
- 清理过程:
每次进行这些操作时,Cache 会先检查当前缓存项是否满足以下清理条件:
- 检查缓存项的过期时间(如果配置了 expireAfterWrite 或 expireAfterAccess)
- 检查缓存项是否达到最大权重限制(如果配置了 maximumWeight)
- 检查缓存项数量是否超过最大值(如果配置了 maximumSize)
- 清理方式:
- 采用增量式清理,每次只清理少量过期项
- 清理过程是非阻塞的,不会影响主要业务逻辑
- 清理线程会尽量复用业务线程,减少额外开销
- 特殊情况处理:
- 当缓存长期没有读写操作时,过期缓存可能会暂时保留
- 可以通过定期调用 Cache.cleanUp() 方法主动触发清理
- 对于关键业务,建议配置 refreshAfterWrite 实现定时刷新
示例场景:
假设配置了 maximumSize=1000 和 expireAfterWrite=10m:
- 当第 1001 次 put 时,会触发清理
- 当读取一个 15 分钟前写入的缓存时,会先删除该过期项再返回 null
- 当缓存长期闲置时,可能仍有部分过期项未被清理
如果一个对象放入缓存之后,不再有任何缓存操作(包括对缓存其他key的操作),那么该缓存不会主动过期的。
如何找最久未使用数据?
使用 accessQueue 队列时,这个双向链表结构是按照LRU(Least Recently Used,最近最少使用)算法顺序存放缓存对象(ReferenceEntry)的。每当缓存对象被访问时,系统会执行以下操作:
- 首先将该节点从链表中移除
- 然后将该节点重新插入到队列的末尾
这种设计使得:
- 更新操作(移动到队尾)可以在O(1)时间内完成
- 删除操作同样高效
- 链表维护了严格的访问时序
通过这种机制,当需要淘汰缓存时:
- 直接从队列头部取出节点
- 这个节点就是最久未被访问的缓存项
- 可以安全地进行淘汰
对应的 writeQueue 队列采用相同的实现方式,但追踪的是"最久未更新"而非"最久未访问"的缓存对象。其工作流程如下:
- 当缓存值被修改(写入)时:
- 将该节点移到
writeQueue末尾
- 将该节点移到
- 淘汰策略触发时:
- 从
writeQueue头部取出节点 - 这个节点就是最久未被更新的缓存项
- 从
这种双队列设计(accessQueue + writeQueue)允许缓存系统同时跟踪:
- 访问频率(通过
accessQueue) - 数据新鲜度(通过
writeQueue)
在实现上,两个队列都使用双向链表结构,这使得节点操作(移动、删除)都非常高效,时间复杂度均为O(1)。这种设计特别适合需要频繁更新缓存状态的场景,比如高并发的缓存系统。
maximumSize / maximumWeight 配置不当导致缓存命中率异常低
现象表现
-
缓存容量异常:
- 通过
cache.size()监控发现缓存条目数始终维持在极低水平 - 缓存命中率(通过
recordStats()统计)持续低于预期值(如低于30%) - 系统频繁出现缓存穿透现象,导致后端负载增加
- 通过
-
性能指标异常:
- 监控显示缓存淘汰率(eviction rate)异常高
- 缓存加载时间(load time)占比显著上升
根本原因分析
容量配置问题
-
maximumSize 设置过小:
- 典型场景:设置为100时,在百万级QPS系统中只能缓存0.01%的请求
- 计算公式:
有效缓存率 = maximumSize / 实际访问key数量
-
weight配置缺失:
- 常见于改造场景:从简单计数缓存改为带权缓存时
- 错误示例:
java
// 改造前
CacheBuilder.newBuilder().maximumSize(1000);
// 改造后错误示范(缺少maximumWeight)
CacheBuilder.newBuilder()
.weigher((k,v) -> ((String)v).length());权重计算问题
-
权重算法不合理:
- 权重值计算过大:如用字节数计算但未做归一化处理
- 动态权重不稳定:基于运行时状态计算的权重波动过大
-
单位理解错误:
- 误将
maximumSize的单位理解为字节(实际是条目数) - 典型错误配置:
- 误将
java
// 错误:以为设置的是100MB容量
CacheBuilder.newBuilder().maximumSize(100 * 1024 * 1024);典型错误场景
- 配置迁移遗漏 :
- 系统升级时添加了weigher但保留旧配置
- 错误示例:
java
// 升级前
.maximumSize(500)
// 升级后错误示范
.maximumSize(500)
.weigher((k,v) -> ((CacheItem)v).getBytes().length)-
权重计算溢出:
- 权重值超过Integer.MAX_VALUE
- 未考虑权重值的合理范围
-
混合使用误区:
- 同时配置maximumSize和maximumWeight导致冲突
- 错误示例:
java
.maximumSize(100)
.maximumWeight(102400)
.weigher(...)正确配置建议
-
明确缓存策略:
- 纯条目数限制:使用maximumSize
- 带权重限制:必须同时配置weigher和maximumWeight
-
权重设计原则:
- 保持权重值在合理范围内(建议0-10000)
- 对超大对象做分段处理
-
监控配置:
java
Cache<String, Object> cache = CacheBuilder.newBuilder()
.maximumWeight(102400)
.weigher((k,v) -> ((String)v).length())
.recordStats()
.build();CacheLoader / get 使用不当,导致阻塞或级联异常
现象表现
-
线程阻塞问题:
- 当多个线程并发调用
cache.get(key)请求同一个未缓存的 key 时 - 所有线程都会阻塞等待第一个线程完成
CacheLoader.load()方法 - 在高并发场景下,可能导致大量线程堆积,形成线程池耗尽
- 当多个线程并发调用
-
异常处理问题:
- 业务逻辑抛出的异常会被 Guava Cache 包装成
ExecutionException - 原始异常堆栈信息被包裹,增加了问题排查难度
- 典型的异常链:
ExecutionException -> 业务异常
- 业务逻辑抛出的异常会被 Guava Cache 包装成
根因分析
-
性能瓶颈:
CacheLoader.load()方法包含耗时操作:- 重 I/O 操作(如数据库查询、远程调用)
- 重计算逻辑(复杂业务计算)
- 未实现任何限流机制(如信号量控制)
- 缺少降级策略(如超时中断)
-
递归依赖:
- 在
load()方法内部又调用cache.get(sameKey) - 形成递归调用链,最终导致栈溢出
- 或产生死锁(当配合同步锁使用时)
- 在
典型错误模式
- 返回值处理不当:
java
// 错误示范:无法区分"缓存未命中"和"加载异常"
Value value = cache.get(key); // 当load抛出异常时也会返回null
// 正确做法
try {
value = cache.get(key);
} catch (ExecutionException e) {
// 明确处理加载异常
}- 异常处理缺陷 :
- 在
load()中直接抛出受检异常(如 SQLException) - Guava 会将其包装为
ExecutionException - 建议方案:
- 将受检异常转为运行时异常
- 或实现自定义的
CacheLoader处理逻辑
- 在
最佳实践建议
-
性能优化:
- 对耗时操作添加超时控制
- 使用
AsyncLoadingCache实现异步加载 - 引入二级缓存(如 Caffeine + Redis)
-
异常处理:
java
new CacheLoader<Key, Value>() {
@Override
public Value load(Key key) {
try {
return doBusinessLogic(key);
} catch (BusinessException e) {
throw new UncheckedExecutionException(e); // 避免多层包装
}
}
}- 防递归设计 :
- 使用 ThreadLocal 标记正在加载的 key
- 或采用分层加载策略,避免循环依赖
recordStats 滥用 + 频繁读取统计值
现象表现
- 在系统性能基准测试过程中,当启用缓存统计功能后,观测到系统的整体 QPS(每秒查询量)出现明显下降,降幅通常在 5%-15% 之间
- 在压力测试场景下,这种性能下降表现得尤为明显,特别是在高并发请求时
- 系统监控显示 CPU 使用率有所上升,且 GC(垃圾回收)频率增加
问题根因分析
-
recordStats 机制的开销:
- 该功能会在内部维护多个计数器(如命中率、加载次数等),每次缓存操作都需要对这些计数器进行原子更新
- 每个计数器操作都涉及内存屏障和 CAS(Compare-And-Swap)操作,在超高并发场景下会产生竞争
- 示例:一个简单的 get 操作在开启统计后,需要额外执行 4-5 个原子操作
-
频繁读取统计值的问题:
- 部分业务代码在关键路径中频繁调用 cache.stats() 方法
- 该方法的实现通常会执行以下操作:
- 对所有计数器进行快照
- 计算衍生指标(如命中率)
- 可能涉及锁竞争来保证统计一致性
- 典型错误用法示例:
java
// 错误示范:在每次缓存操作后都记录统计
public Object get(String key) {
Object value = cache.get(key);
log.debug("Cache stats: {}", cache.stats()); // 高频调用
return value;
}- 问题放大效应 :
- 当统计日志级别设置为 DEBUG 时,日志系统的格式化、IO 操作会进一步加剧性能问题
- 在微服务架构中,如果多个服务都存在这种用法,整体系统性能会呈现阶梯式下降
影响范围
该问题在以下场景影响尤为严重:
- 缓存命中率超过 90% 的高效缓存场景
- 单机 QPS 超过 5000 的高吞吐系统
- 使用细粒度缓存的场景(如每个请求涉及多次缓存访问)
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 堆内存持续上涨直至 OOM,堆 dump 中 Guava Cache 对象占比极高 | 缓存永不过期或过期时间极长;未配置 maximumSize 或容量设置极大 | 使用堆分析工具查看 com.google.common.cache 相关对象;结合 cache.size() 观察条目数变化为所有缓存配置合理的 expireAfterWrite/expireAfterAccess 和 maximumSize;大对象场景配合 weakValues |
| 已配置过期策略但过期数据长时间仍占内存,size() 显示条目过多 | Guava 采用惰性清理,长期没有读写操作时不会主动清理过期项 | 结合业务访问模式查看是否存在长时间无 get/put 的缓存;观察 size() 与实际业务访问量是否匹配在定时任务中调用 cache.cleanUp();关键路径保持适度 get/put;超过生命周期的缓存拆分或下线 |
| 缓存命中率长期低于 30%,eviction rate 异常高,后端负载上升 | maximumSize 设置过小;误将 maximumSize 当作"字节数";weight/maximumWeight 配置不合理 | 启用 recordStats,观察 hitRate、evictionCount;对比 key 总量、QPS 与 maximumSize 配置以"热点 key 数量 × 安全系数"重新计算 maximumSize;带权场景同时设置 weigher 与 maximumWeight |
| 高并发下大量线程阻塞在 cache.get(key),线程池耗尽 | CacheLoader.load 内部包含慢 SQL、远程调用或复杂计算;内部递归调用 cache.get | 线程 dump 中大量线程卡在 CacheLoader.load 或 ExecutionException.getCause 链路将重 I/O 从 load 中拆出并限流,必要时改为异步缓存;禁止 load 内部调用同一 cache.get,消除循环依赖 |
| 开启 recordStats 后 QPS 下降 5--15%,CPU 使用率上升,GC 变频 | recordStats 为每次操作维护原子计数;业务在高频路径中反复调用 cache.stats 并输出日志 | 基准测试对比开启/关闭 recordStats 的 QPS、CPU;排查日志中是否频繁输出 cache.stats 信息recordStats 仅在压测或排障环境开启;生产侧将 cache.stats 采集下沉到低频运维任务,避免在热路径调用 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接