接着上篇博客中提到的机器学习需要了解的一些库,上文讲了numpy库和pandas库。
在了解matplotlib库和sklearn库前我们先补充一些pandas库中dataframe的常见用法,在后面机器学习中会经常用到。
一、pandas中的dataframe补充
1.dataframe常见操作
1)
python
"""DataFrame(数据框)就是excel表(多个Series的拼接)"""
import pandas as pd
df_1 = pd.DataFrame({'age':[10,11,12],
'name':['tim', 'tom', 'rose'],
'income':[100,200,300]},
index=['lisi', 'zhangsan', 'wangwu'])
print(df_1)
"""dataframe的属性"""
#行索引
df_1.index
#列名
df_1.columns
#值
df_1.values
df_1 = pd.DataFrame({'age':[10,11,12],
'name':['tim', 'tom', 'rose'],
'income':[100,200,300]})
print(df_1)
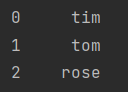
print(df_1.name)第一个print
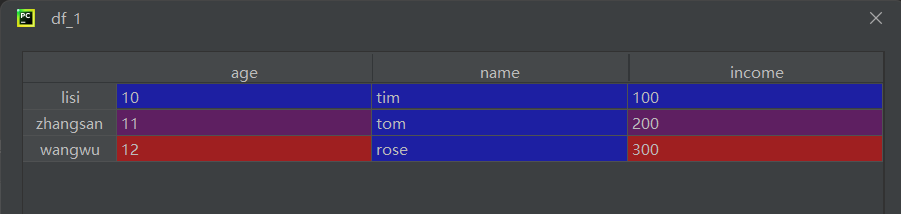
第二个print:
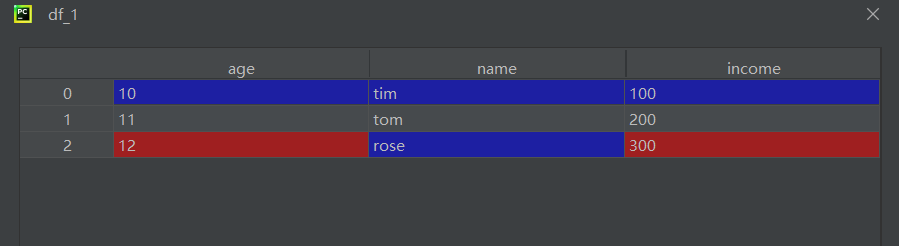
第三个print:也就是name列的信息
2)
python
import pandas as pd
dic = {'name': ['kiti', 'beta', 'peter', 'tom'],
'age': [20, 18, 35, 21],
'gender': ['f', 'f', 'm', 'm']}
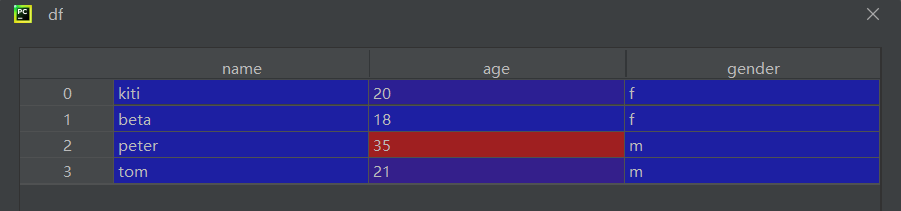
df = pd.DataFrame(dic)
print(df)
"""根据年龄这一列,进行排序【升序和降序】"""
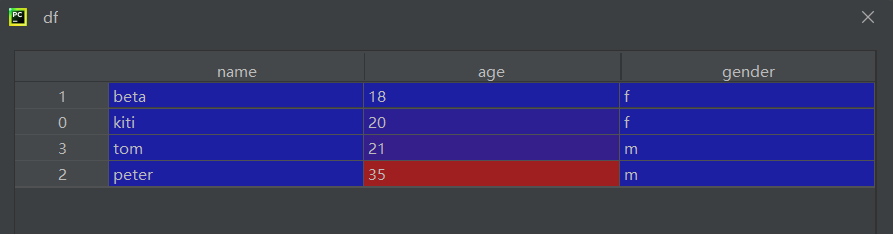
df = df.sort_values(by=['age'])
print(df)
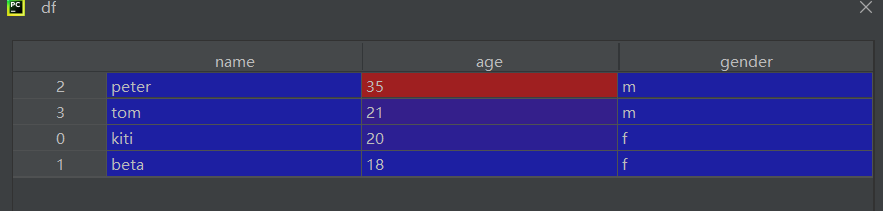
df = df.sort_values(by=['age'], ascending=False)
print(df)
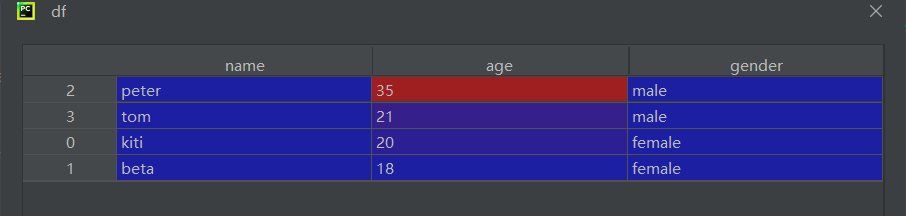
"""值替换"""
a = df['gender']
b = a.replace(['m', 'f'], ['male', 'female'])
df['gender'] = b
print(df)第一个print:
第二个print和第三个:
false降序,不写默认true升序,注意这里一列排序改变,该行其他数据也跟着移动
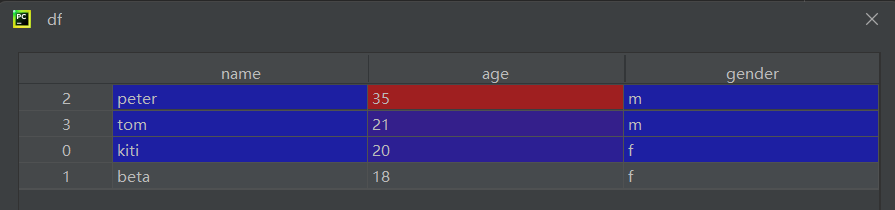
第四个print:第一张是替换前的表格
2.数据框查询的2种方法
python
"""loc()iloc()"""
import pandas as pd
import numpy as np
#生成指定日期
# datas = pd.date_range('20180101', periods=5)#产生一个时间数据,5个
df = pd.DataFrame(
np.arange(30).reshape(5,6),index=['20180101','20180102','20180103','20180104','20180105'],
columns=['A','B','C','D','E','F'])#在三十内产生数字组成五行六列
print(df)
"""loc()方法df.loc[x, y]【标签索引】"""
#打印某个值
print(df.loc['20180103', 'B'])#20180103行的b列
#打印某列值
print(df.loc[:,'B'])#全部行的b列
print(df.loc['20180103':,'B'])#20180103到最后一行的b列
print(df.loc['20180103':,['B', 'D']])#20180103行到最后一行的b和d列
#打印某行值
print(df.loc['20180101', :])#20180101行的全部列
#打印某些行
print(df.loc['20180103':,:])
"""iloc()方法 位置索引"""
#获取某个数据
print(df.iloc[1,2])
#获取某列
print(df.iloc[:,2])
#获取某几列
print(df.iloc[:,[1,3]])
#获取某行
print(df.iloc[1,:])
#获取某些行
print(df.iloc[[1,2,4],:])首先输出df表格
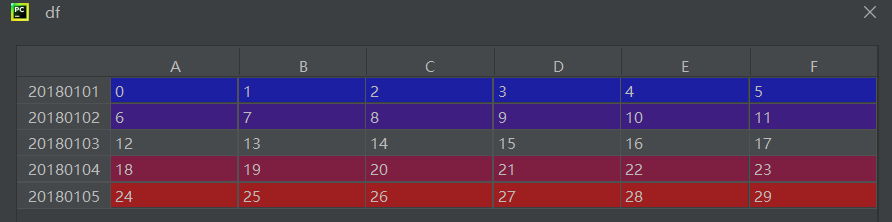
后面索引和上文中数组的选取是一样的,只不过这里有一个loc和iloc区别
loc是根据行名列名进行选取的,iloc是根据索引号,冒号是全部信息,逗号是和
3.简单操作dataframe
其他操作:
行名我们不设置的时候,是自动填充0,1,2,3......
python
import pandas as pd
df = pd.DataFrame(
{'age':[10,11,12],
'name':['tim', 'tom', 'rose'],
'income':[100,200,300]},
index=['person1', 'person2', 'person3'])
print(df)
"""修改列名"""
a= df.columns
df.columns = range(0, len(df.columns))
print(df.columns)
"""修改行名"""
print(df.index)
df.index = range(0,len(df.index))
print(df.index)
"""增加一列"""
#在最后添加一列
df['pay'] = [20, 30, 40]
print(df)
"""增加一行"""
df.loc['person4', ['age', 'name', 'income']] = [20, 'kitty', 200]
print(df)#要添加上行名,否则表格会乱
"""访问DataFrame"""
#访问某列
print(df.name)
a = df.name
b = df['name']
#访问某些列
print(df[['age', 'name']])
#访问行
print(df[0:2])
#使用loc访问
print(df.loc[['person1', 'person3']])
#访问某个值
print(df.loc['person1', 'name'])
"""删除"""
#直接在原数据上删除
del df['age']
print(df)
#删除列
data = df.drop('name', axis=1, inplace=False)
# 表示从 DataFrame df 中删除名为 'name' 的列
# axis=1 表示删除的是列(如果是 axis=0 则表示删除行)
# inplace=False 表示不直接在原 DataFrame 上修改,而是返回一个删除了 'name' 列的新 DataFrame
print(data)
#删除行删除列都可以用drop
df.drop('person3', axis=0, inplace=True)#这里的ture代表在原表上进行,false就不再原表上进行
import pandas as pd
import numpy as np
datas = pd.date_range('20180101',periods=5)
df1 = pd.DataFrame(np.arange(30).reshape(5,6),index=datas,columns=['A','B','C','D','E','F'])
print(df1)二、matplotlib库
matplotlib库是用来画图的第三方库,数据可视化,需要先下载,调用的pyplot是生成一个绘画板
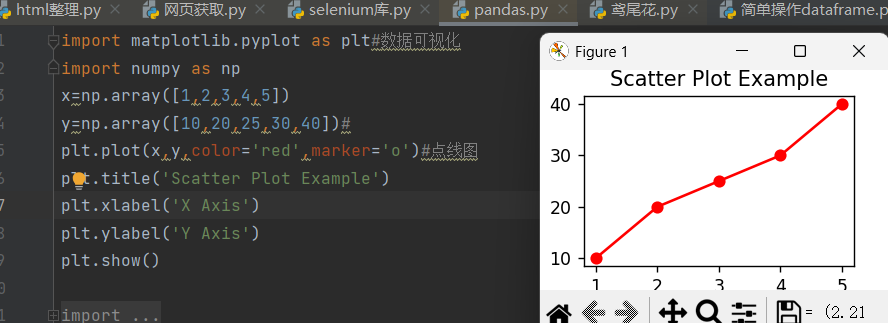
1.有数组x和数组y,plot中参数color就是线的颜色,marker就是点的形状,此外其他参数还有,linestyle='-'线形,linewidth='2'线宽,markersize=8标记点的大小
下面xlabel和ylabel就是给横轴和纵轴取名
最后用show展示出
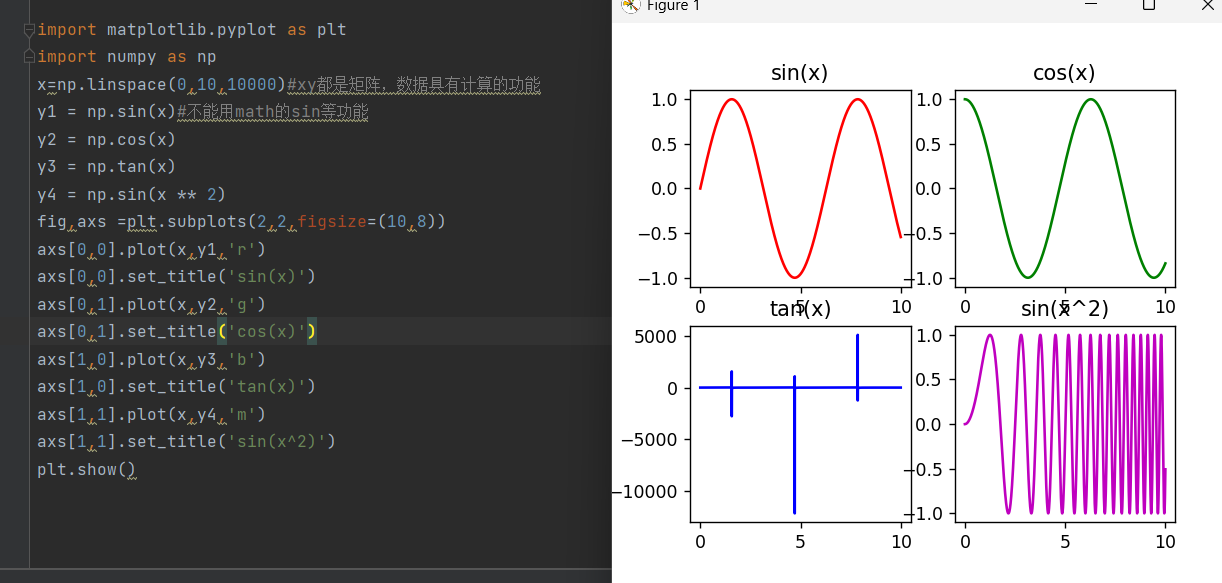
2.画数学函数
这里可以把绘画板分隔成四份,fig,axs中fig是画布,axs是子图坐标轴的数组
也就是说四个区域分别是0,0,0,1,1,0,1,1,这些就是axs
'r','g','b','m',是颜色,这里把color省略了
title就是给子图取名字
三、sklearn库
用来做数据分析和预测建模的第三方库,是python的机器学习库,需要先下载,为了以后学习方便,这边我下载的是1.0.2版本
下载的时候要写全名,scikit-learn
用scikit-learn其实就已经进入了机器学习。