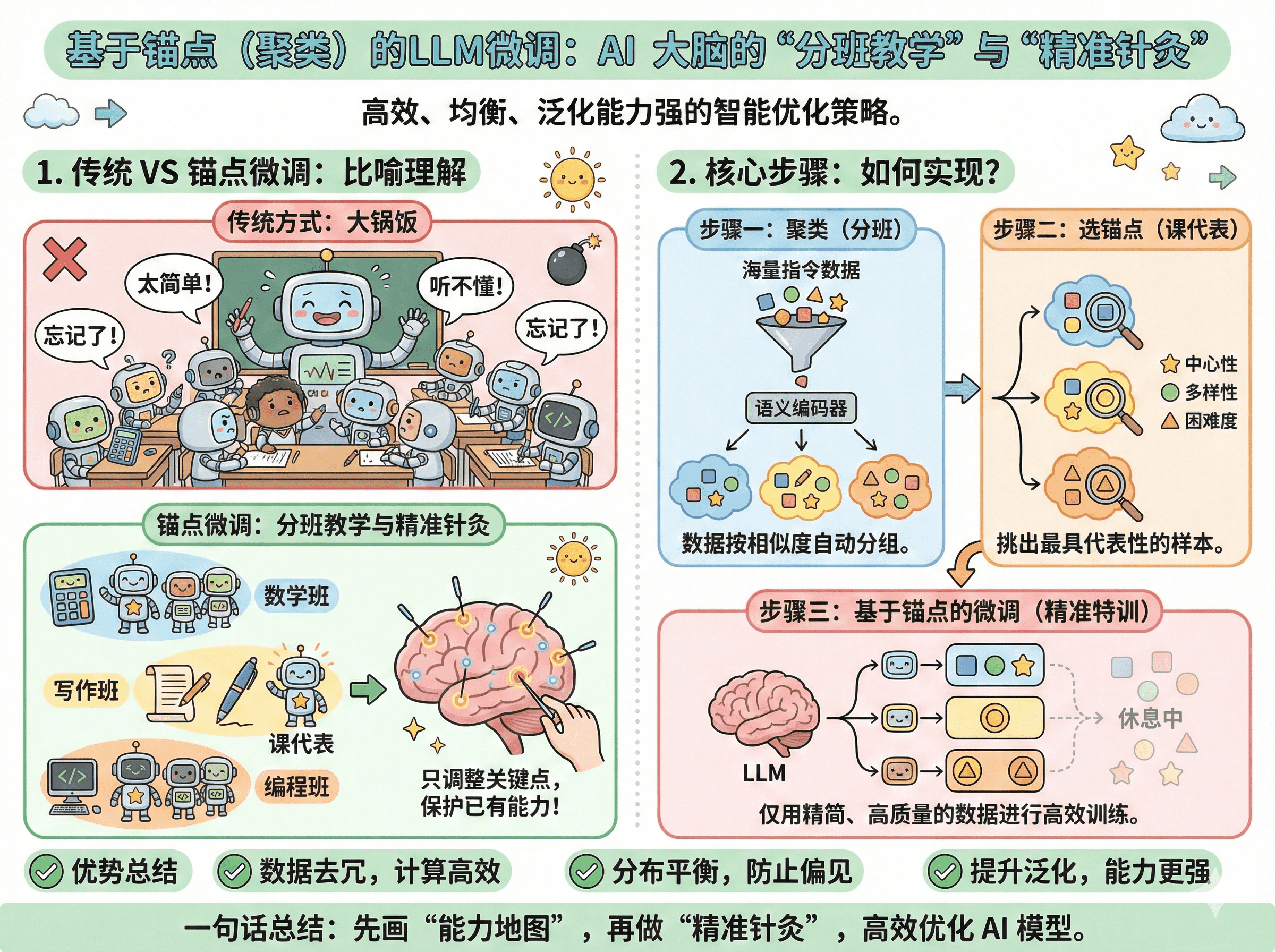
这是一种在大规模指令数据集上进行高效、高质量微调的策略。其核心思想是先对海量、多样的指令数据进行结构化分组,再选取最具代表性的样本进行微调,以避免数据冗余、平衡数据分布,并提升模型泛化能力。
比喻理解:
想象你要学习"世界美食"(微调模型),传统方法是给你一本包含十万道菜谱的厚书(全量数据),里面有很多重复或相似的菜。
基于锚点的方法则是:先让一位美食家(聚类算法)将这十万道菜按菜系(中、法、意、日等)和烹饪方式(烘焙、烧烤、蒸煮等)自动分成几百个类别(簇)。然后从每个类别中精心挑选出1-2道最经典、最能体现该类特色的招牌菜(锚点)。最后,你只需要学习这精选出来的几百道招牌菜,就能高效、系统地掌握世界美食的核心技艺与精髓,并能举一反三,创作出新菜品。