1、数据集的作用
在LoRA微调过程中,train、valid 和 test 数据集是三个独立的角色,它们共同协作以确保模型训练的有效性并客观评估其最终表现。
| 数据集 | 主要作用与目的 | 发挥作用的关键时间节点 | 典型内容与注意事项 |
|---|---|---|---|
| 训练集 (train) | 核心学习材料 :用于模型参数的主训练与调整,是LoRA适配器学习知识的唯一来源。 | 贯穿整个训练过程:在每一个训练步(step)或轮次(epoch)中反复使用。 | 任务相关的指令-回答对、文本片段等。要求:质量高、规模大、有代表性。 |
| 验证集 (valid) | 实时考官与导航仪 : 1. 监控训练 :在训练中周期性评估模型在未见数据上的表现,实时绘制损失/准确率曲线。 2. 防止过拟合 :判断模型是学习泛化规律还是死记硬背训练集。 3. 超参调优:用于选择最佳训练轮次(早停)、学习率等超参数。 | 在训练过程中周期性使用 :在每个训练周期(如每N个step或每个epoch)结束时使用一次,不参与参数更新。 | 与训练集任务一致、但内容不同的数据。要求:与训练集同分布、无重叠。 |
| 测试集 (test) | 最终裁判 :在一切训练和调优结束后 ,对模型能力进行一次完全独立、客观的最终评估,反映其真实的泛化能力。 | 仅在全部训练彻底完成后,使用一次 。在确定最终模型前,绝对不允许用于任何训练或调优决策。 | 与训练/验证集任务一致、但内容不同的数据。要求:完全独立、仅用一次,模拟真实应用场景。 |
1.1 准备数据 → 训练与监控 → 最终评估
-
准备阶段 :将原始数据按一定比例(如
80:10:10或70:15:15)划分为互不重叠的三部分。 -
训练与监控阶段 :模型在
train集上学习;训练间隙在valid集上"考试",根据成绩决定是否早停或调整超参。 -
最终评估阶段 :训练完成后,选用在
valid集上表现最好的模型,在从未见过的test集上进行唯一一次最终测试,给出最可信的性能报告。
1.2 需要特别注意的误区:
-
严禁"数据泄露" :
valid和test的数据绝不能以任何形式混入train集,否则评估结果会过于乐观,失去指导意义。 -
区分
valid和test:valid集是训练过程的一部分 ,用于指导训练;test集是训练结束后的纯粹评估工具,不应影响任何训练决策。
2、验证集如何发挥"调整"作用
| 调整对象 | 验证集如何发挥作用 |
|---|---|
| 训练何时停止? | 这是最核心的调整。通过监控验证集损失/指标,实现早停:当验证集指标连续多次不再提升时,就停止训练。这直接决定了模型最终的参数状态,避免了在训练集上过拟合。 |
| 哪个模型最好? | 训练过程中会保存多个检查点(如每N轮保存一次)。最终选择的模型 ,不是训练到最后一步的模型,而是在验证集上表现最好的那个检查点。这选择了最优的参数快照。 |
| 超参数如何选? | 在正式训练前,可以用验证集进行超参数搜索 (如不同学习率、LoRA的rank值)。根据在验证集上的表现,选择最优的一组超参数组合,用于最终训练。 |
| 模型"健康"如何? | 通过对比训练集和验证集的损失曲线,可以诊断 模型状态: • 两者都下降 → 健康学习。 • 训练集下降,验证集上升 → 典型过拟合,需要调整(如增加正则化、减少训练轮次)。 |
2.1间接调整与信息泄漏
理解这一点,关键要区分 "直接调整" 和 "间接调整":
-
不进行"直接调整" :验证集的数据不参与梯度计算和反向传播。模型不会从这些数据中"学习"具体的知识或模式。这是它与训练集的根本区别。
-
但进行"间接调整" :我们根据验证集提供的"考试分数",做出了一系列影响全局的决策 (停止训练、选择模型、调整超参)。这些决策是基于验证集信息做出的,因此验证集实质上引导了训练的方向和最终结果。
正因为这种间接的引导作用,我们必须保证验证集的纯洁性:
-
严禁信息泄漏:验证集数据绝不能混入训练集,否则就相当于"考试前偷看了考题",评估结果会过于乐观,失去指导意义。
-
与测试集区分 :测试集(test set)是真正的"最终裁判",在所有调整结束后,只使用一次 ,用于给出最终的性能报告。在整个训练和调参过程中,绝对不能使用测试集
3、训练过程如何分析
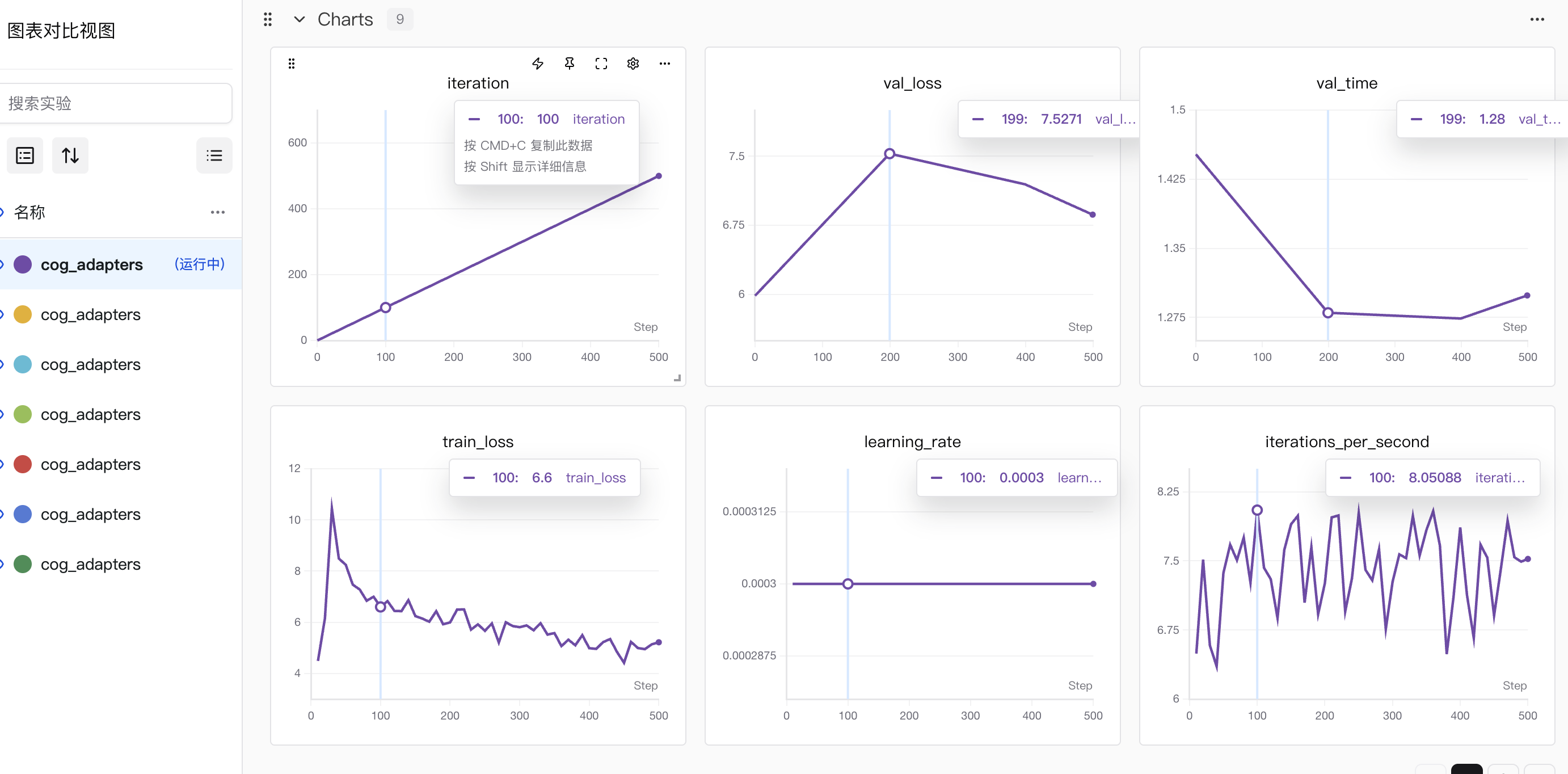
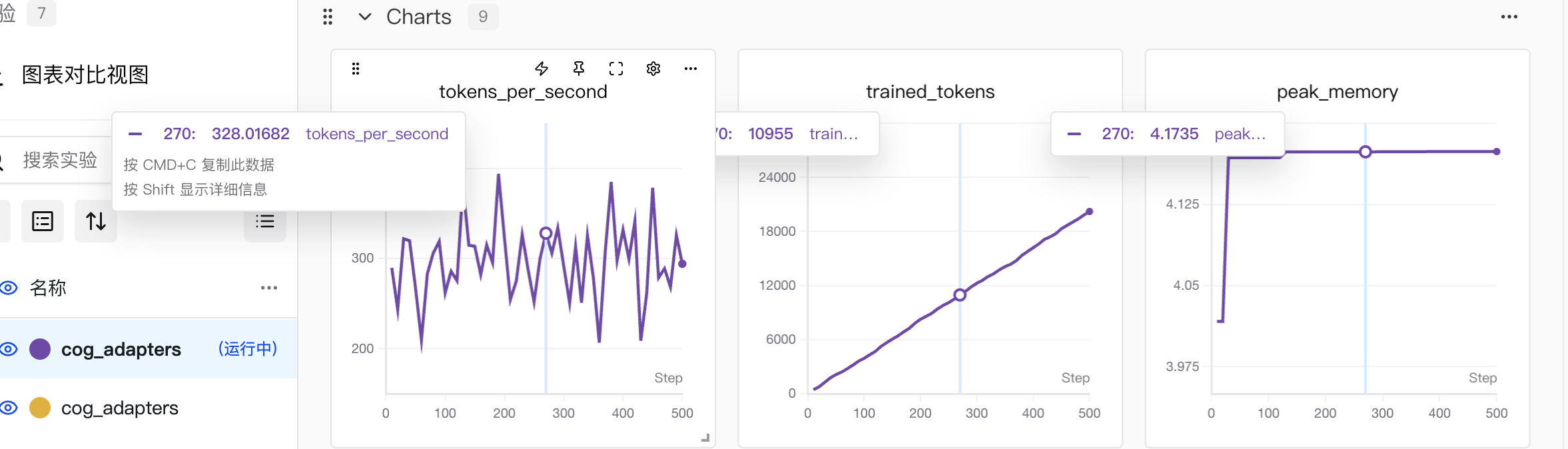
3.1 先明确各图表的核心含义
iteration:训练迭代步数(随训练推进持续增加,当前到 500 步左右)val_loss(验证损失):模型在验证集上的误差(越低越好)train_loss(训练损失):模型在训练集上的误差(越低越好)learning_rate(学习率):训练中参数更新的步长(这里保持 0.0003 稳定)val_time(验证耗时):每次验证的时间成本iterations_per_second(每秒迭代数):训练速度(数值越高,训练越快)tokens_per_second(每秒处理 token 数) :模型训练时的数据处理速度(数值越高,训练效率越高)。trained_tokens(已训练 token 总数):训练过程中累计处理的 token 量(随训练步数增加而增长,是训练 "工作量" 的体现)。peak_memory(峰值内存) :训练过程中 GPU/CPU 的最大内存占用(反映资源消耗情况)。
3.2 重点看「损失函数」的表现
| 指标名称 | 含义 | 分析核心要点 | 联动参考指标 |
|---|---|---|---|
train_loss(训练损失) |
模型在训练集上的预测误差 | 1. 趋势:是否随训练推进持续下降2. 稳定性:后期是否波动过大3. 收敛性:是否趋近稳定值 | iteration/trained_tokens(训练进度)、learning_rate(学习率) |
val_loss(验证损失) |
模型在验证集上的预测误差 | 1. 与train_loss的差距:差距过大→过拟合2. 趋势:是否先升后降 / 持续下降3. 最优值:是否出现明显的 "最低谷" |
train_loss(拟合差异)、val_time(验证耗时) |
3.3 损失函数常见异常情况的指标特征说明
1. 过拟合
- 核心表现 :
train_loss持续下降,但val_loss先降后升(或稳定在较高值) - 联动特征 :
train_loss和val_loss的差距越来越大trained_tokens(训练量)增加时,val_loss不再同步下降
- 判断依据:模型在训练集上拟合太好,但泛化到验证集的能力变弱
2. 收敛过慢
- 核心表现 :
train_loss/val_loss下降速度极缓,长时间停留在较高值 - 联动特征 :
learning_rate(学习率)过低(或全程未调整)iteration(步数)/trained_tokens(训练量)很大,但损失无明显变化
- 判断依据:模型参数更新步长太小,或训练数据量不足
3. 训练波动过大
- 核心表现 :
train_loss曲线剧烈上下波动(无稳定下降趋势) - 联动特征 :
learning_rate(学习率)过高tokens_per_second(处理速度)波动与损失波动同步
- 判断依据:参数更新步长太大,模型训练过程不稳定
4. 早停信号
-
核心表现 :
val_loss连续多步(如 10 步)不再下降,甚至轻微上升 -
联动特征 :
train_loss仍在下降(或已稳定)trained_tokens持续增加但val_loss无改善
-
判断依据 :模型已达到当前最优泛化能力,继续训练可能过拟合
异常类型 调参 / 优化建议 过拟合 1. 增大正则化强度(如 L2 正则、Dropout 比例)2. 减少模型参数规模(如缩小网络层数)3. 增加验证集数据量 / 做数据增强 收敛过慢 1. 适当提高初始 learning_rate(如从 0.0003 调至 0.001)2. 改用学习率调度器(如余弦退火)3. 增加训练数据量 / 延长训练步数训练波动过大 1. 降低 learning_rate(如从 0.001 调至 0.0005)2. 减小 batch size(避免单次更新幅度过大)3. 增加梯度裁剪(限制参数更新范围)早停信号 1. 触发早停机制(停止训练,保存当前最优模型)2. 微调学习率(如降低学习率后再训练几轮)3. 更换验证集分布(排除数据偏差)