在火语言 RPA 爬取网页数据时,很多新手只知道用「获取多元素信息属性值」「获取单元素信息属性值」逐个抠取数据?其实面对网页表格类数据时,用「表格数据提取」组件也是不错的选择!不用逐行逐列手动定位元素,不用反复配置属性值,一键就能抓取整表数据。今天就以爬取 10 页蔬菜价格为例,手把手拆解「表格数据提取」组件,新手也能轻松搞定多页表格数据采集~

一、案例功能概述
自动爬取 https://www.jnmarket.net/fruitsvegetables/dailyprice/vegprice 10 页蔬菜价格表格数据,汇总到 Excel;
二、流程核心逻辑
核心逻辑:打开浏览器→访问网页→创建全局表格→循环爬10页数据(提取→写入全局表格→翻页)→导出Excel→关闭浏览器→Excel后处理(打开→删列/插列→写表头→整理数据→保存)
三、详细操作步骤
(一)数据爬取
组件1,打开浏览器 ,选择浏览器类型

组件2,浏览网页 ,输入网址URL:https://www.jnmarket.net/fruitsvegetables/dailyprice/vegprice

组件3,表格打开或新建 ,新建空表格,用于存储表格数据,这里我们把新建的表格输出到变量全局表格,用于后续写入表格数据
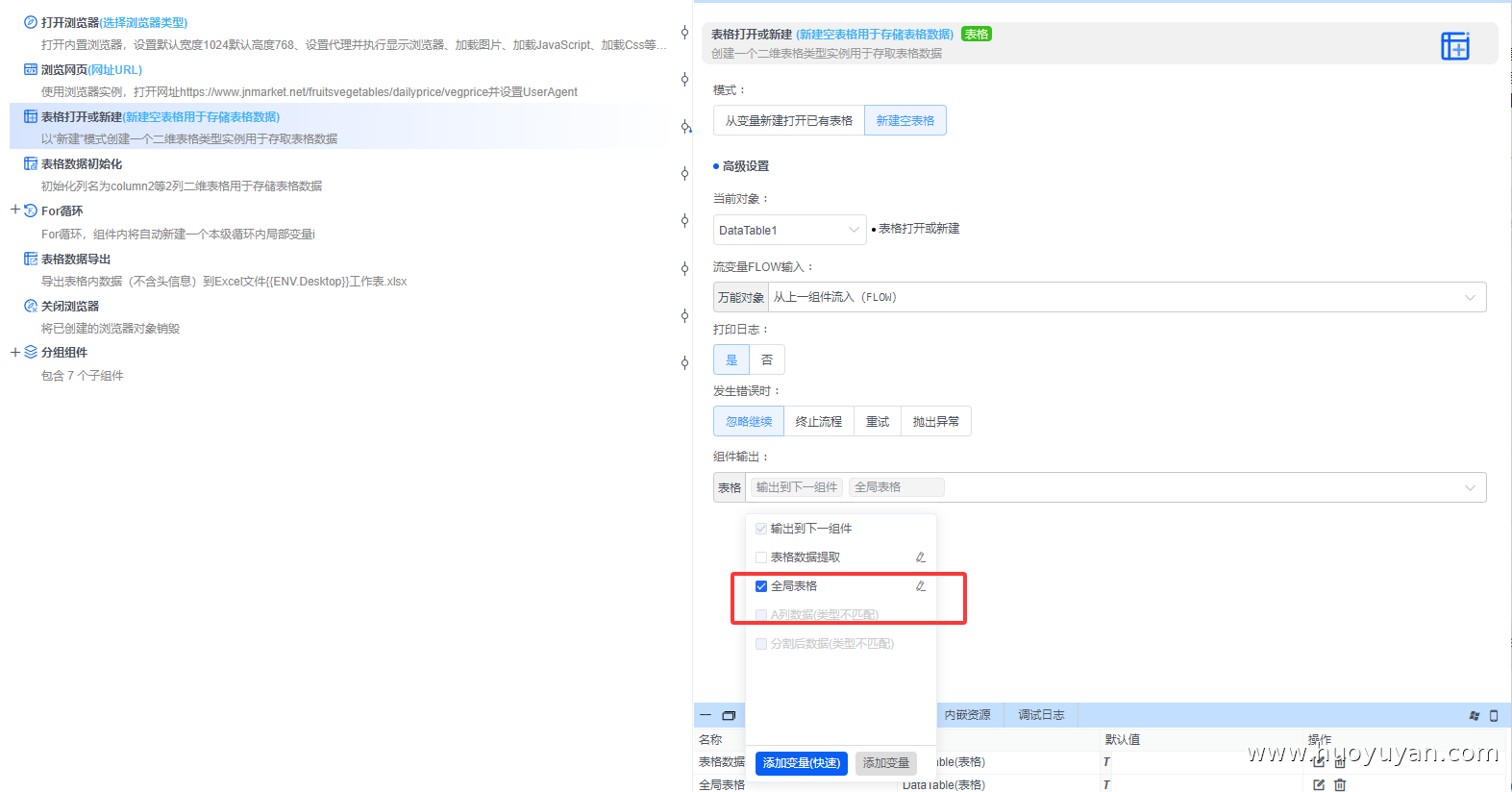
组件4,表格数据初始化 ,初始化表格,这里初始化2列(具体设置两列在组件6详细说明)
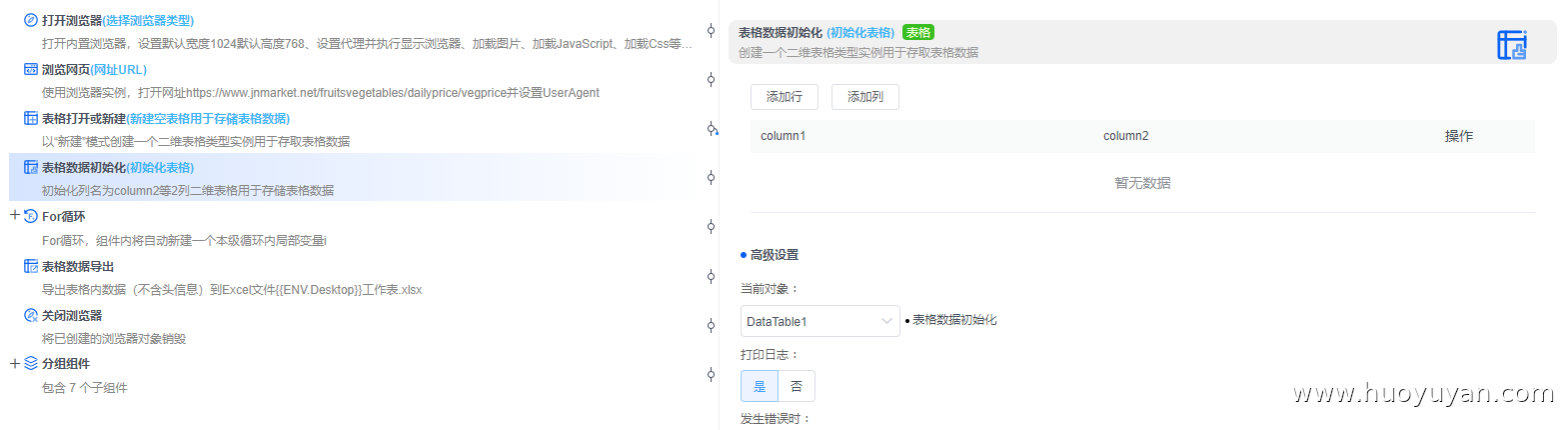
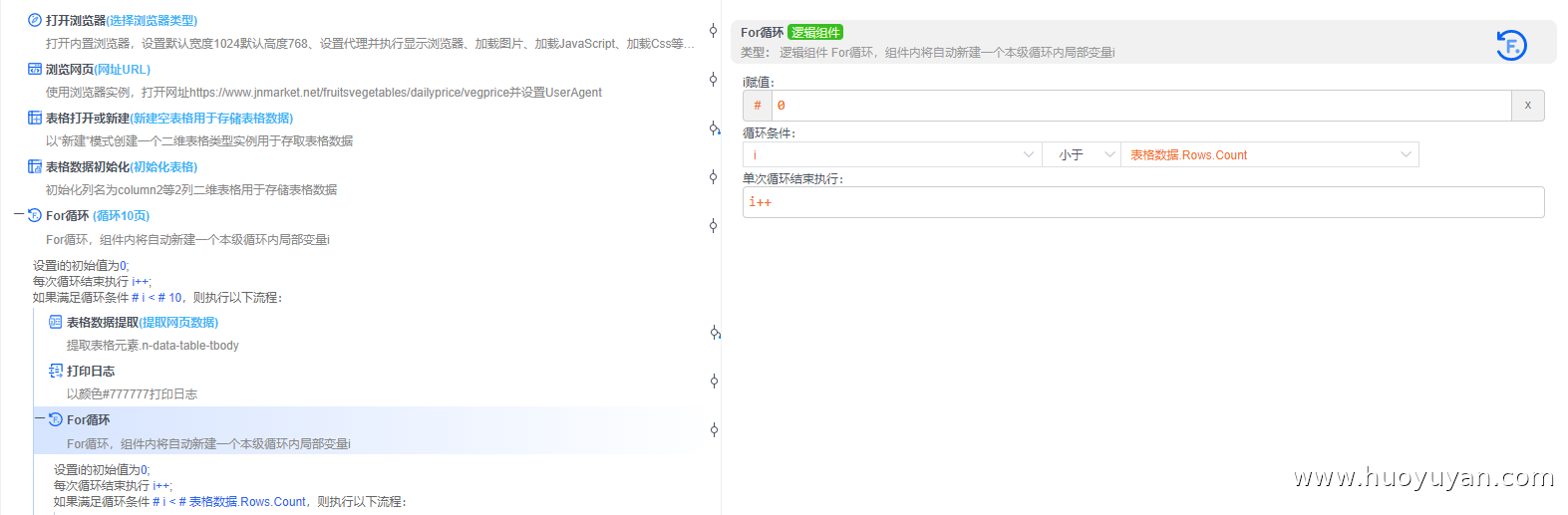
组件5,For循环 ,因为这里采集10页数据,所以这里循环条件为:i<10

组件5.1,表格数据提取 ,通过自带的选择元素工具设置提取配置自动获取表格数据,输出到变量表格数据
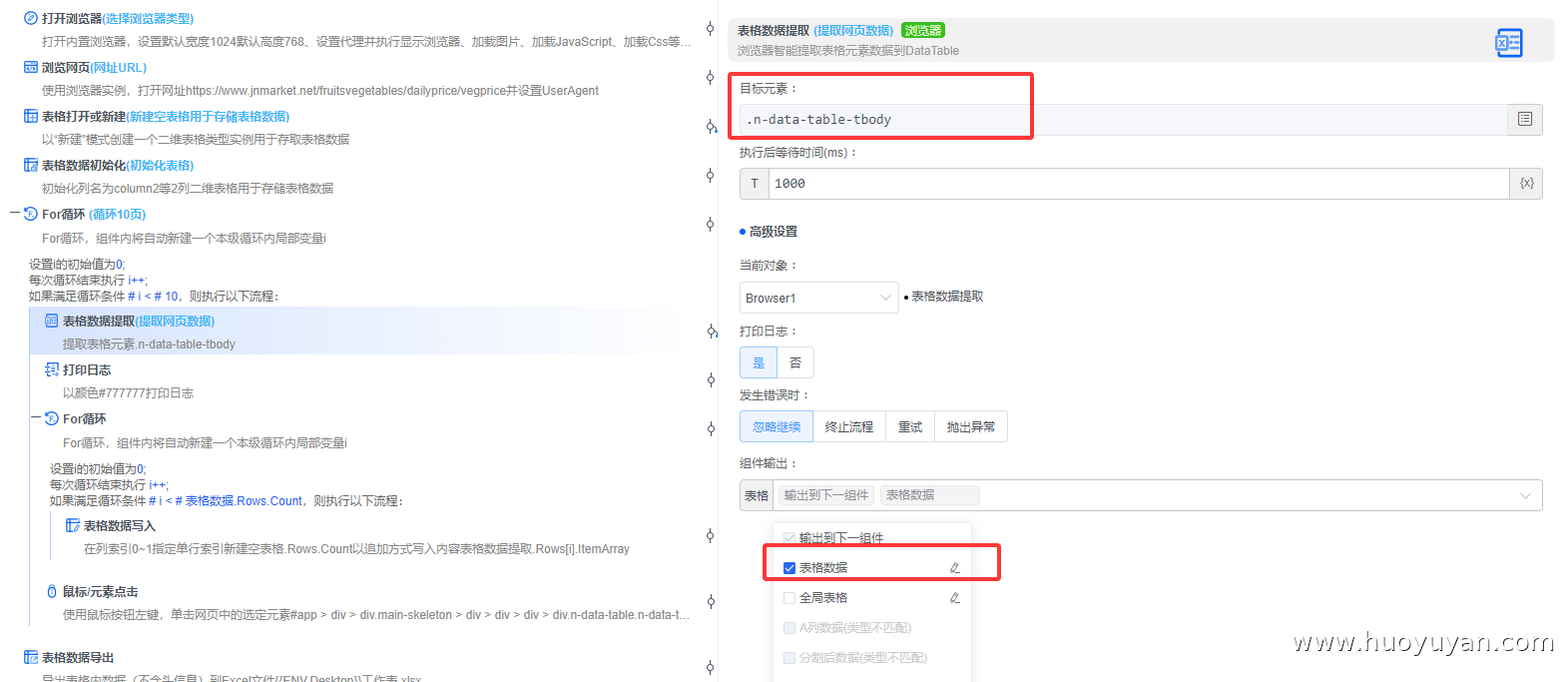
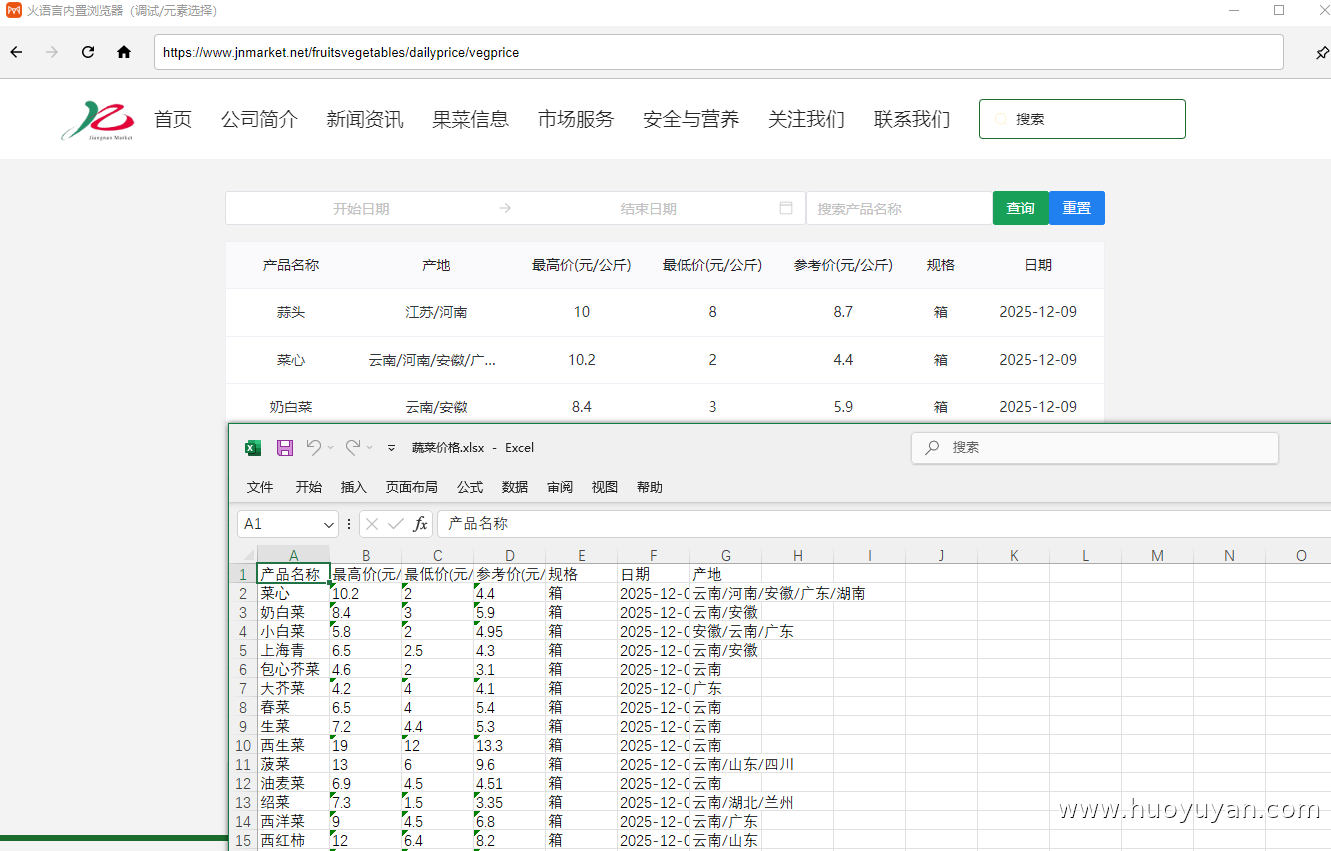
提取的时候发现该网站的表格,产品名称,最高价,最低价,参考价,规格,日期提取到一列, 核心原因是网页表格的 HTML 结构不是 "标准多列表格",导致「表格数据提取」组件把整行内容识别成了 "单个单元格";这里将网页的数据自动提取到两列,后续可以使用「字符串分割成列表」,来分割表格数据。
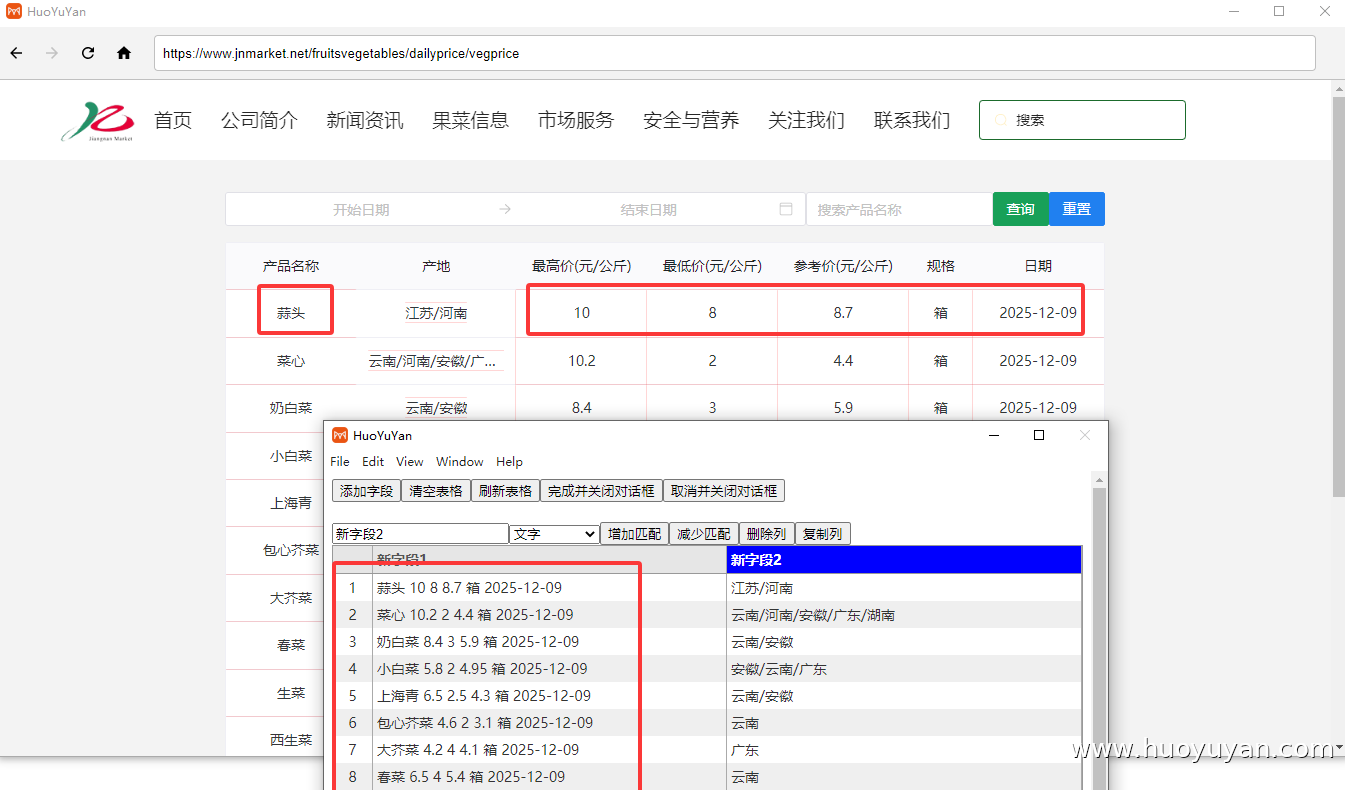
组件5.2,打印日志 ,拖拽「打印日志」到「表格数据提取」下方,验证数据提取结果
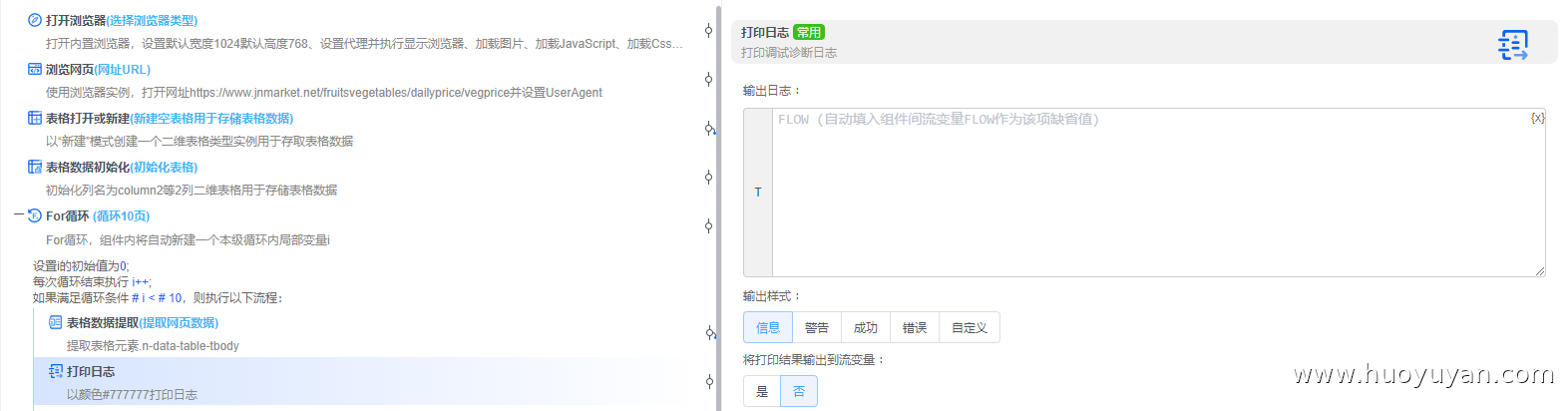
组件5.3,For循环 ,循环表格数据的总行数,写入表格i<表格数据.Rows.Count
(参见https://www.huoyuyan.com/community/detail.html?id=386 )
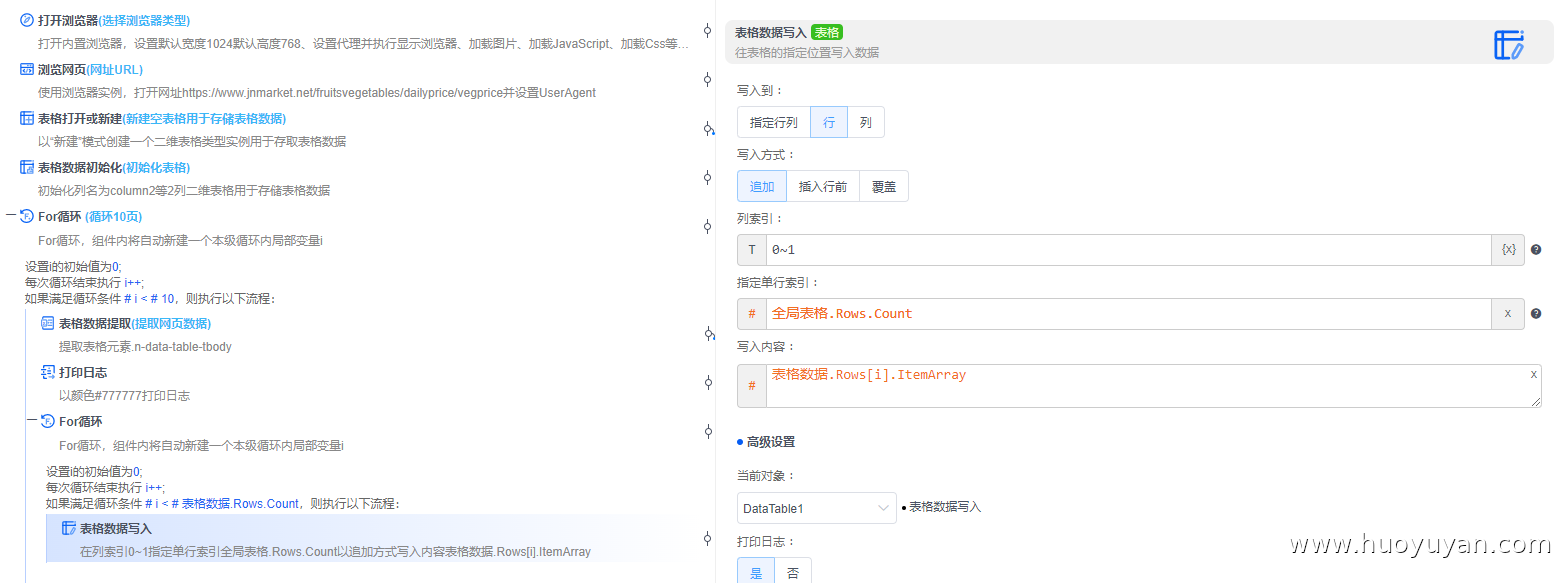
组件5.3.1,表格数据写入 ,将表格数据按行追加写入
列索引:0~1,列索引从O开始,支持同时操作多列,格式为逗号分隔或波浪线连续列,如:1,2,3或0~3,n表示倒数第n列
指定单行索引:全局表格.Rows.Count,作为 "下一行写入位置"(表格有 N 行,下一行就写第 N 行,无需手动加 1!总行数本身就是下一行的索引,行索引从 0 开始)
写入内容:表格数据.Rows[i].ItemArray,「表格数据提取」得到的临时表格变量,定位临时表格里的第 i 行(i 从 0 开始),提取该行的纯数据(过滤格式 / 样式)
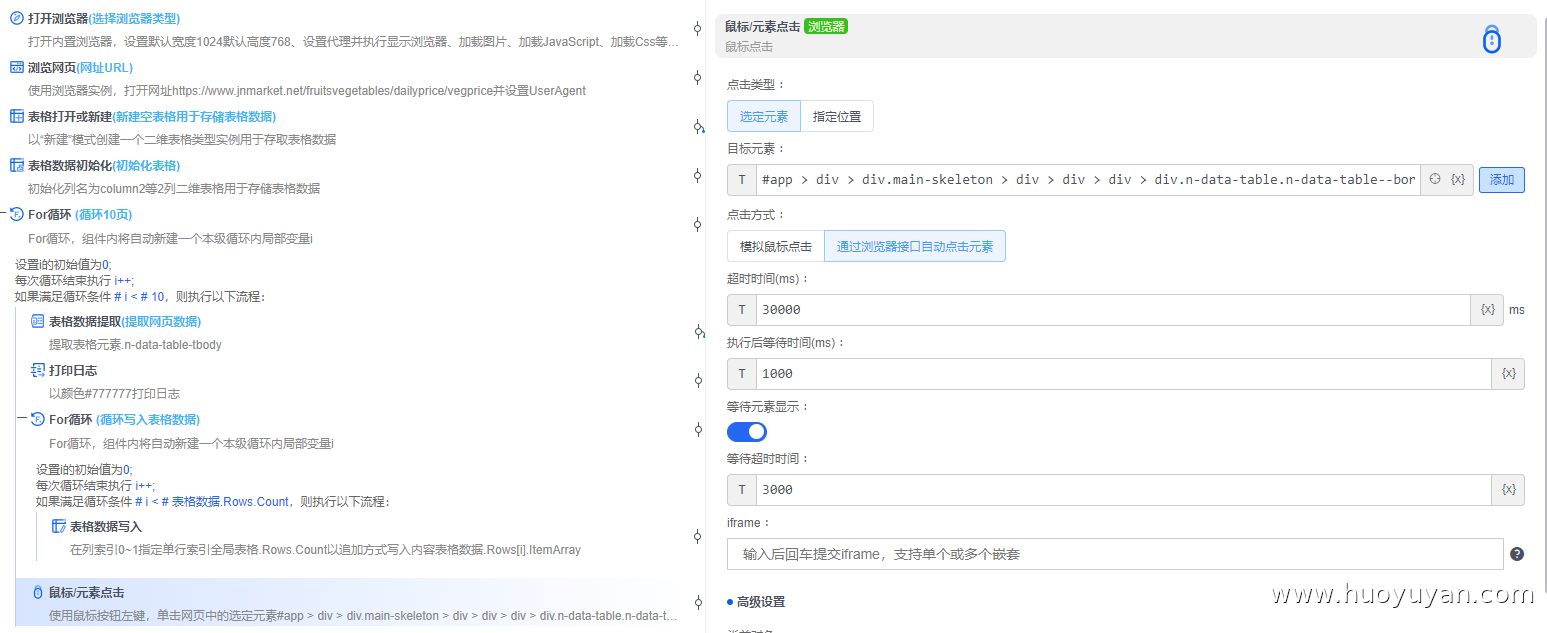
组件5.4,鼠标/元素点击 ,点击下一页
组件6,表格数据导出 ,将数据导出本地
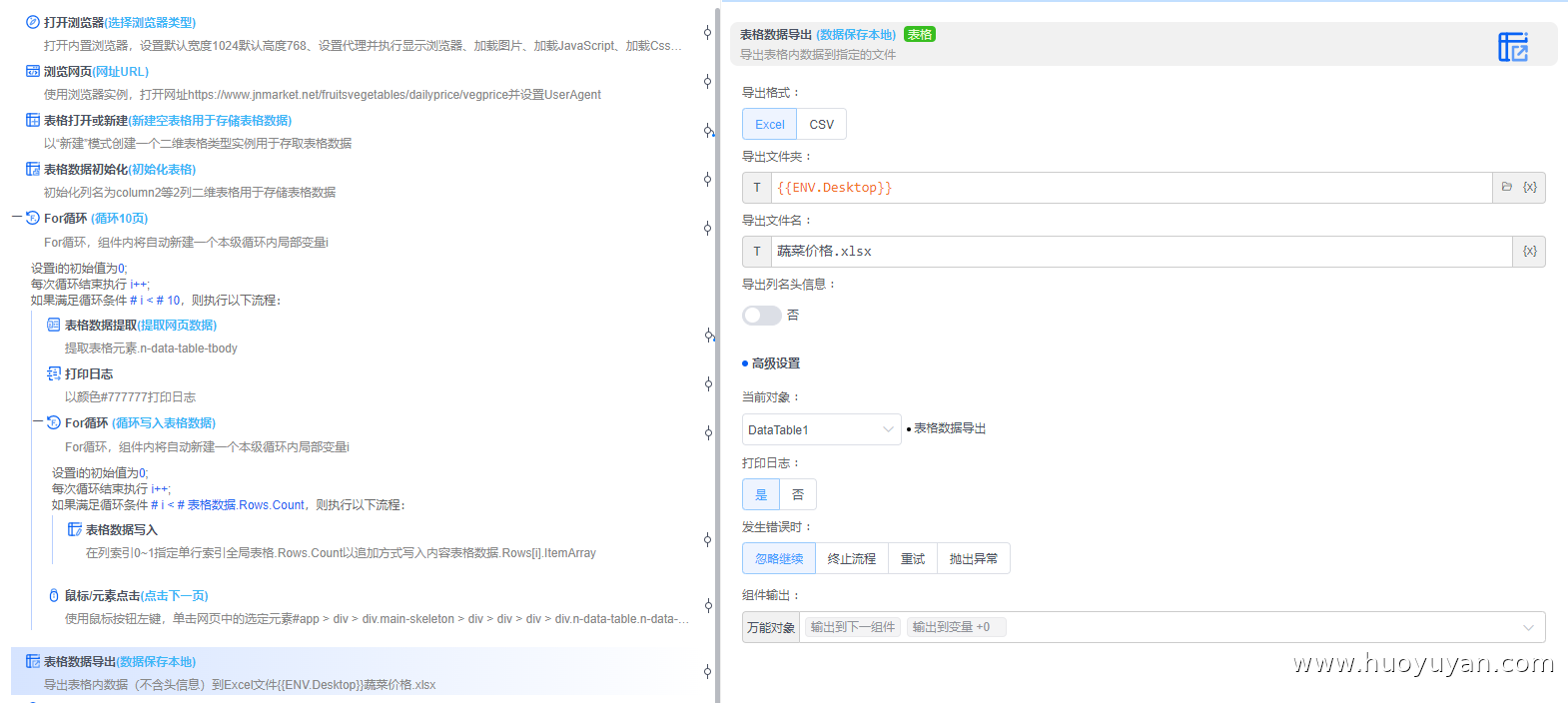
组件7,关闭浏览器
(二)Excel 自动化后处理
可以参考之前的案例:https://www.huoyuyan.com/community/detail.html?id=353

下面调试该脚本,获取采集结果:
「表格数据提取」完整脚本分享:
分享: https://www.huoyuyan.com/share.html?key=eyJhdXRvQ29kZSI6IkZhbHNlIiwia2V5IjoiMjVkZDc2MGI0NDg1NDhmMDhhNGJjNjY1NGEzOGZkYzQifQ== 提取码: X5Pf