`😊 @ 作者:Lion J`
`💖 @ 主页:
https://blog.csdn.net/weixin_69252724\`
`🎉 @ 主题:基于SpringBoot常用脱敏方案`
`⏱️ @ 创作时间:2025年12月10日`
数据脱敏
引言
1.1 编写的目的
在数据脱敏功能的落地过程中,开发团队往往面临"选型难、对比杂、场景多"的困惑。目前系统梳理四种主流脱敏手段(Jackson 注解式、AOP 拦截式、DTO 手动式、数据库sql脱敏)的核心机制、优缺点及适用场景,帮助开发者在安全合规、研发效率、运行性能之间做出快速且正确的技术决策,同时规避常见的明文泄露、脏数据、性能陷阱等风险,真正做到"++敏感数据看不见,业务系统照样转++"。
1.2 效果示意
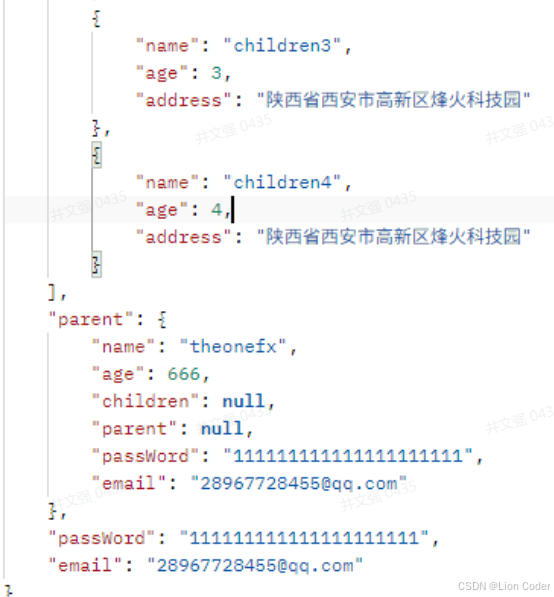
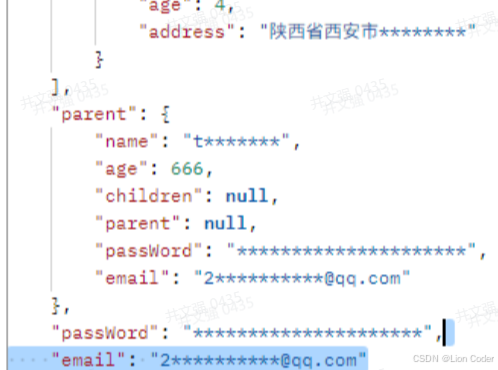
脱敏方式介绍
具体的脱敏方向大致分为两种
数据库层面
(应用层)返回前端之前序列化处理
数据库层面脱敏:
在数据库层面进行脱敏通常意味着在 写入数据库之前 或 获取数据库数据时 对敏感数据进行处理,++就像熟悉的MD5 密码加密++ 也是数据库脱敏的一种体现。
-
加密:对数据进行加密处理,使其在存储时不可读。
-
掩码:隐藏部分数据,如电话号码、身份证号等只显示部分信息。
数据库层面脱敏的优点是可以集中管理,并且通常更安全,因为敏感数据不会被未经处理就暴露给应用程序。
应用层面脱敏:
应用层脱敏是在数据从数据库抽出来,并且在发送给前端之前对其进行处理。这通常在业务逻辑层操作
- 脱敏对象的指定字段时调用自定义的工具类完成脱敏
3.1 Jackson + 自定义序列化器
- 概述
在将后端的对象返回前端之前, 会通过SpringMVC 的 默认Jackson 序列化器来实现数据的json化处理, 会根据字段类型查找对应的序列化器
利用这一扩展点,我们可以:
自定义一个通用脱敏序列化器(实现
JsonSerializer<String>+ContextualSerializer);在需要脱敏的字段上只加业务注解(如
@Desensitize(type = EMAIL));序列化阶段 Jackson 自动回调该序列化器,实时将明文替换为星号,再写入 JSON。
全程零业务代码侵入,规则集中维护,性能接近原生(序列化器被缓存),是对外 API 层最轻量、最统一的脱敏方案。
没有注解的去选择默认的序列器***(StringSerializer、IntSerializer...)***
- 原理
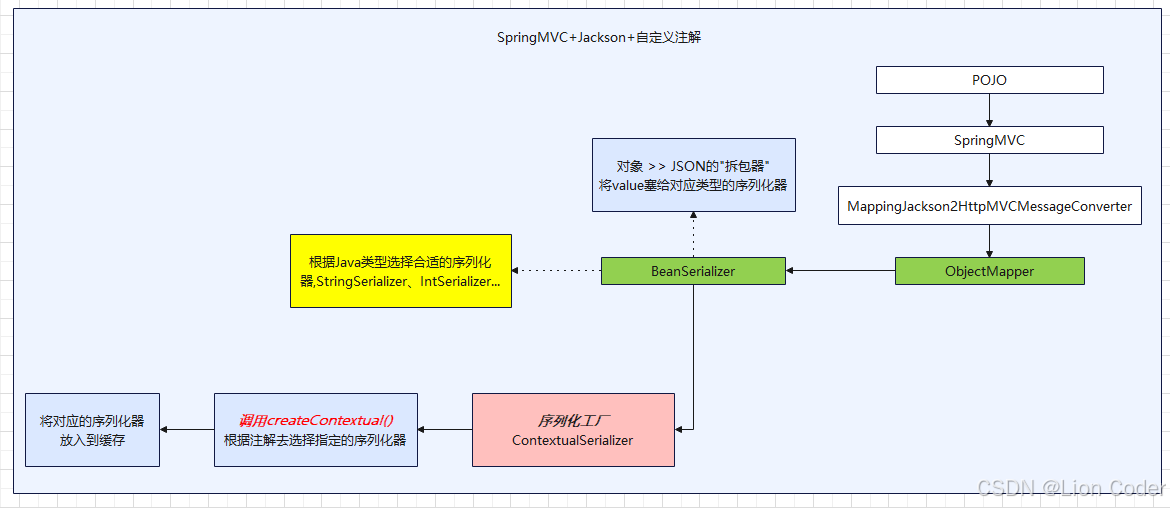
BeanSerializer 拆包器 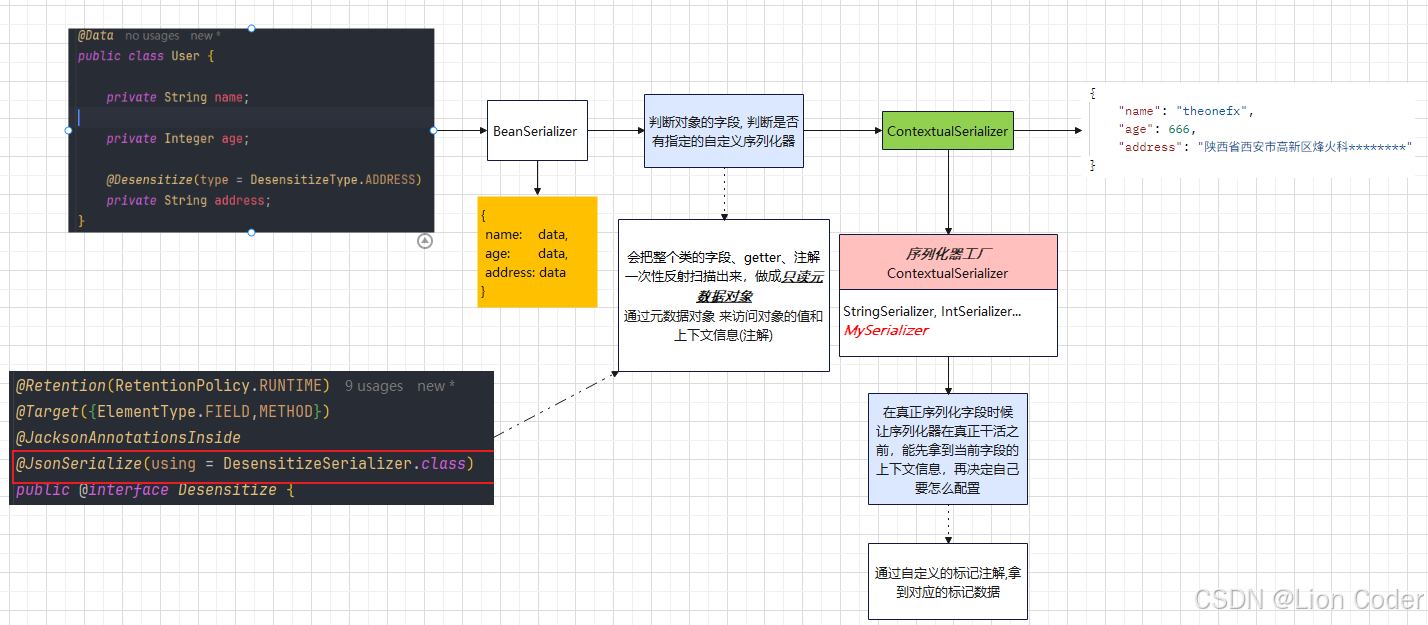
- 拓展
这种类型是以字段为粒度加注解, 那么只要在这个对象上加了注解, 就相当于把对象的字段标记了, ++在哪调用都得走自定义的++ ++序列化++ ++逻辑++
所以, 这里扩展一个 ++打标签++(标记)可以指定字段在某个接口脱敏, 不影响该字段在其他地方的正常展示
- 打标签的含义
++因为序列化是通过getter 方法来获取字段的,所以可以在getter上做文章++
*++
addMixIn++*的本质是:把"Mixin 接口/类"上的所有注解,原封不动地嫁接给目标实体类,但运行时仍然只出现目标实体类BCompany,Mixin 本身不会被实例化也不会出现在 JSON 里。
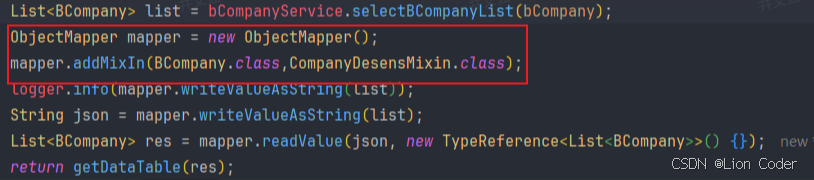
java
public interface CompanyDesensMixin {
@Desensitize(type = DesensitizeType.EMAIL)
String getEmail();
}3.2 AOP + 标记注解
- 概述
把"脱敏动作"从业务代码里抽出来,做成一个横切关注点;
在方法返回前端之前,立即调用统一脱敏处理器:通过反射按字段名遍历返回对象,将敏感字段就地替换为星号。 使用方式只用在目标字段上加一个自定义注解(包含脱敏类型),业务代码零变动,即可对任意复杂嵌套对象、集合、Map 完成脱敏。
该方案以"方法"为最小粒度,一次性配置即可让接口、日志、导出等多出口同时生效,但需承担 ++反射++ 遍历带来的 CPU 开销与循环引用风险
- 原理
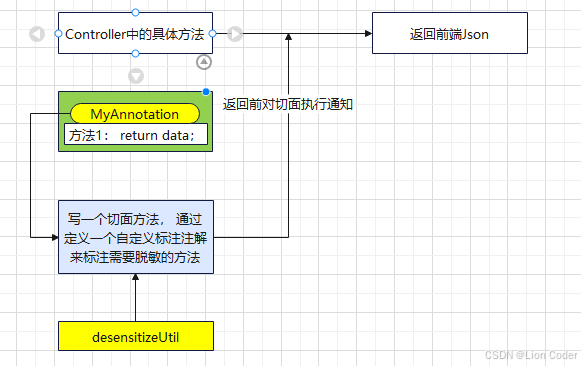
-
相关代码
java@Target(ElementType.FIELD) @Retention(RetentionPolicy.RUNTIME) public @interface Sensitive { SensitiveType value(); }java/** * 脱敏类型枚举 */ public enum SensitiveType { PHONE, // 手机号 ID_CARD, // 身份证 NAME, // 姓名 EMAIL, // 邮箱 BANK_CARD // 银行卡 }java/** * 深度脱敏AOP处理器 */ @Aspect @Component @Slf4j public class DeepSensitiveAspect { // 定义切点:拦截Controller层所有方法 @Pointcut("execution(* com.jing.springbootdemo.web.BasicController.user())") public void controllerPointcut() {} /** * 环绕通知:处理Controller层返回结果 */ @Around("controllerPointcut()") public Object aroundController(ProceedingJoinPoint joinPoint) throws Throwable { Object result = joinPoint.proceed(); long start = System.nanoTime(); Object res = processDeepSensitive(result); long end = System.nanoTime(); long cost = TimeUnit.NANOSECONDS.toMillis(end - start); log.info("Controller 通知总耗时 = {} ms | 签名 = {}", cost, joinPoint.getSignature().toShortString()); return res; } /** * 递归处理单个对象所有字段 */ private Object processObject(Object obj) { if (obj == null) { return null; } Class<?> clazz = obj.getClass(); try { // 获取所有字段(包括父类) List<Field> fields = getAllFields(clazz); for (Field field : fields) { field.setAccessible(true); // 检查是否有脱敏注解 Sensitive sensitive = field.getAnnotation(Sensitive.class); if (sensitive != null && field.getType() == String.class) { // 处理敏感字段 processSensitiveField(obj, field, sensitive); } else { // 递归处理嵌套对象 processNestedField(obj, field); } } } catch (Exception e) { log.warn("脱敏处理失败: {}", e.getMessage()); } return obj; } }
这里需要写一个递归处理对象,Map,集合(反射). 如果是多字段/深度嵌套的对象, 多层反射
3.3 DTO 手动脱敏
- 概述
没有任何注解、没有任何框架,就是最原始的
get/set时期的做法,++最原始最灵活++
-
代码
javapublic UserDTO toDTO(UserEntity entity) { UserDTO dto = new UserDTO(); // 1. 普通字段 dto.setUserName(desensitizeName(entity.getRealName())); // 2. 身份证号 dto.setIdCard(StrUtil.hide(entity.getIdCard(), 1, 17)); // 3. 手机 dto.setMobile(DesensitizedUtil.mobilePhone(entity.getMobile())); // 4. 邮箱 dto.setEmail(DesensitizedUtil.email(entity.getEmail())); return dto; } private String desensitizeName(String fullName) { if (fullName == null || fullName.length() < 2) return fullName; return fullName.charAt(0) + "*" + fullName.substring(fullName.length() - 1); }
这种灵活度最高,但是如果项目多处用到数据脱敏, 就要写很多重复的代码. 且及其不好维护
3.4 数据库脱敏
- 概述
数据库脱敏是指在数据离开数据库之前,通过 SQL 内置函数、视图、存储过程或商业插件,对敏感字段进行实时变形,使返回给应用、报表或第三方接口的数据不再包含完整明文,从而防止泄露、满足合规的一种服务端级保护手段。
sql
SELECT
id,
CONCAT(LEFT(phone, 3), '****', RIGHT(phone, 4)) AS phone,
CONCAT(LEFT(id_card, 6), '********', RIGHT(id_card, 4)) AS id_card,
CONCAT(LEFT(name, 1), '*', RIGHT(name, 1)) AS name,
CONCAT(LEFT(email, 4), '****', SUBSTRING(email, LOCATE('@', email))) AS email,
CONCAT(LEFT(bank_card, 4), '********', RIGHT(bank_card, 4)) AS bank_card
FROM users;通过SQL层面直接脱敏, ++SQL 复杂,维护成本高,无法动态控制++
|---------------|------------------------------------------------------|----------------------------|--------------------------------------------------|------------------------------------------|
| 方式 | 层面 | 改动 | 性能 | 灵活度 |
| jackson 自定义注解 | 实现自定义的序列化器, 走原有springMVC的流程,无侵入脱敏只用加注解, 添加脱敏方式只需要加枚举 | 自定义 序列化器和 注解 | 走原生,不用拷贝,不用反射, 效率高 | 以字段为粒度, 也可以通过给某个 方法里的指定字段脱敏,灵活度高 |
| aop+标注注解 | 以反射的方式, 在脱敏的方法上添加脱敏注解 | 不修改原有的实体,只用在需要脱敏的方法上添加标记注解 | 以反射方式进行, 遇见嵌套对象, 需要将所有字段循环反射判断是否需要脱敏, 多字段对象,影响性能 | 以方法为粒度, 通过调用工具类来脱敏, 工具类来决定哪个字段要脱敏, 灵活度不高 |
| DTO 手动脱敏 | 代码业务层面, 需要脱敏的位置,添加 pojo -> dto 的对象转换 | 需要给需要转化的对象新建dto对象 | 无反射,纯手动调用脱敏工具,效率高 | 灵活度最高,但是需要大量修改原有 的代码和编写重复代码, 维护成本高 |
| 数据库层面 | 通过sql直接将数据解决按 | 需要脱敏的地方添加sql, 添加mapper | 每行通过sql的字符串截断方法, 不能走索引 | 灵活度差, 该字段就要改sql, 需要脱敏 就要去改sql, 复用性最低 |
性能测试
综上所述, Jackson 与 AOP 反射切入的方式 比较合理, 适用于当前业务需求;
下面写两个这两种类型的 Demo 来进行性能测试
- 测试结论
执行结果 
可以看到Jackson的序列化性能是AOP方式的3~4倍
安全层面
jackson方式:
-
无锁、无并发问题
-
自定义的序列化器由springWeb自己管理
aop +标注注解:
- 对象如果层级嵌套多/字段多,需要手动写递归,占用大量栈空间
DTO 手动脱敏:
最原始,最安全(内存全是***,无内存残留数据)
数据库层面脱敏:
将脱敏逻辑转移到 SQL 查询出口,与业务逻辑完全解耦,依赖于SQL实现是安全等级最高的实现方式。
项目场景
对于有种情况, 在整个列表页面, 邮箱这种信息不想被一眼看到, 然后详情信息又想看见. 对于后端的实现, 用户这个数据模型肯定是一份, 不可能列表 和 详情页面各一个数据模型(对象).
这边肯定优先选择可以区分接口的方案
- 选择方案
jackson+自定义注解方式
-
自定义序列化处理器,springMVC 转化时(遇见自定义的注解) 直接调用自己的序列化处理器
-
只用在需要的脱敏字段上加注解
-
增加注解规则,只要更改注解工具
-
后期改字段名称,直接改名称