一、前言
vLLM-Ascend 是 vLLM 项目的一个社区维护的硬件插件,专为华为昇腾(Ascend)NPU 设计,使 vLLM 能够无缝运行在昇腾硬件平台上。该项目遵循 vLLM 社区的硬件插件化设计原则,提供了高性能的大语言模型推理能力。
这篇文章的话我主要会带大家来熟悉一下vLLM-Ascend项目的结构,部署和配置。
主要特点:
- 支持主流开源模型,包括 Transformer、MoE、Embedding 和多模态模型
- 提供与 vLLM 兼容的 API 接口
- 针对昇腾 NPU 进行了性能优化
- 支持单节点和多节点部署
项目地址:https://github.com/vllm-project/vllm-ascend
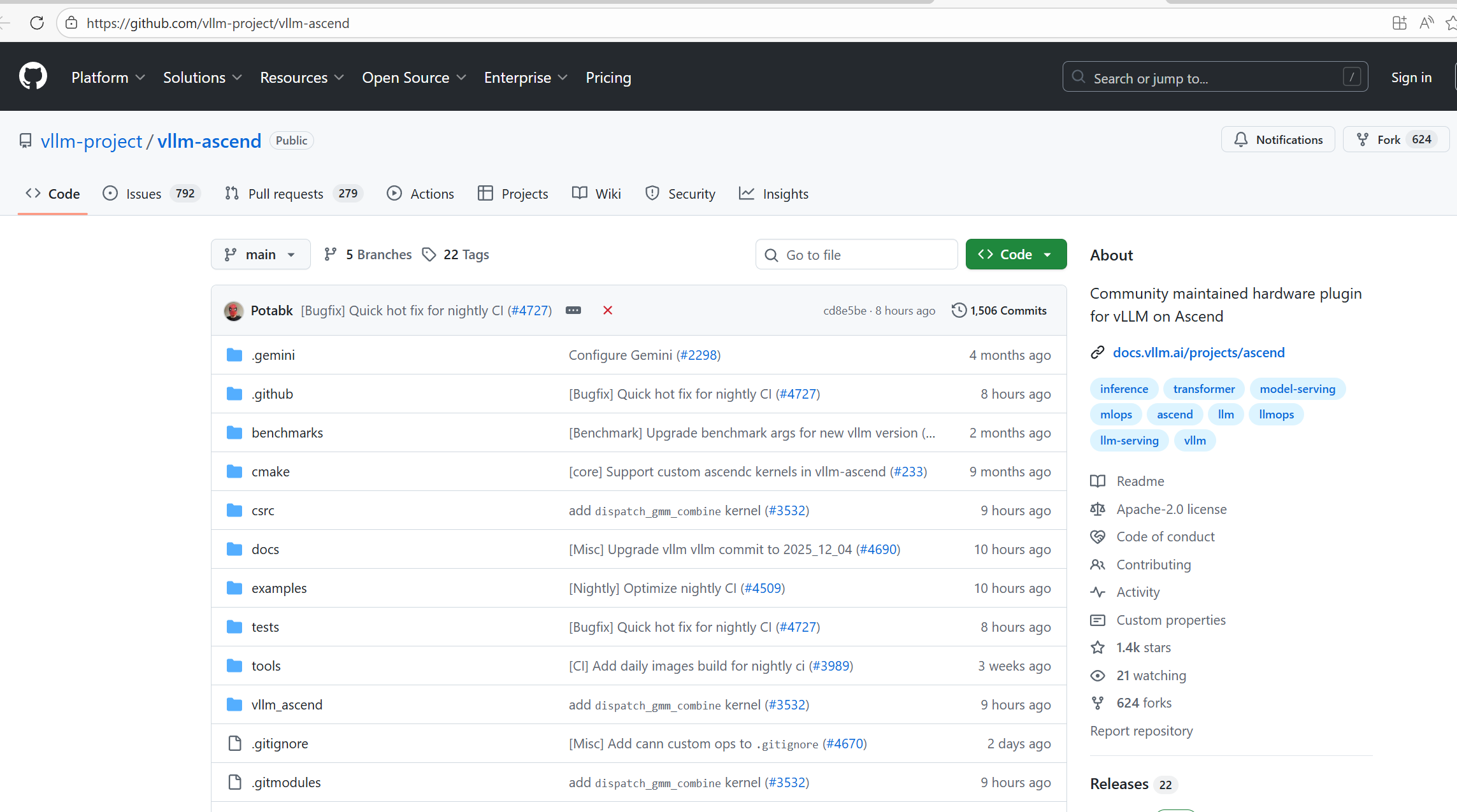
二、vLLM-Ascend 开源仓结构
我觉得学习一个新的项目最重要的,就是先弄清楚它的整体结构以及各模块的职责。只有把框架的组织方式在脑中建立起来,后续才能在调试、改代码或做二次开发时不至于迷失方向。vLLM-Ascend 的仓库结构相对简洁,核心逻辑主要围绕昇腾后端适配、算子补齐和调度接口扩展几部分展开。接下来我就带大家一块来看看vLLM-Ascend 开源仓结构。
核心代码实现
vllm_ascend/ 目录包含 Ascend NPU 适配的关键逻辑,例如 attention/ 下的 mla_v1.py、sfa_v1.py 实现注意力机制,torchair/ 下的 torchair_mla.py 负责 Torch 框架的适配,ops/attention.py 实现注意力计算等关键算子操作,eplb/core/policy/ 下的代码处理专家并行策略(如动态负载均衡)。
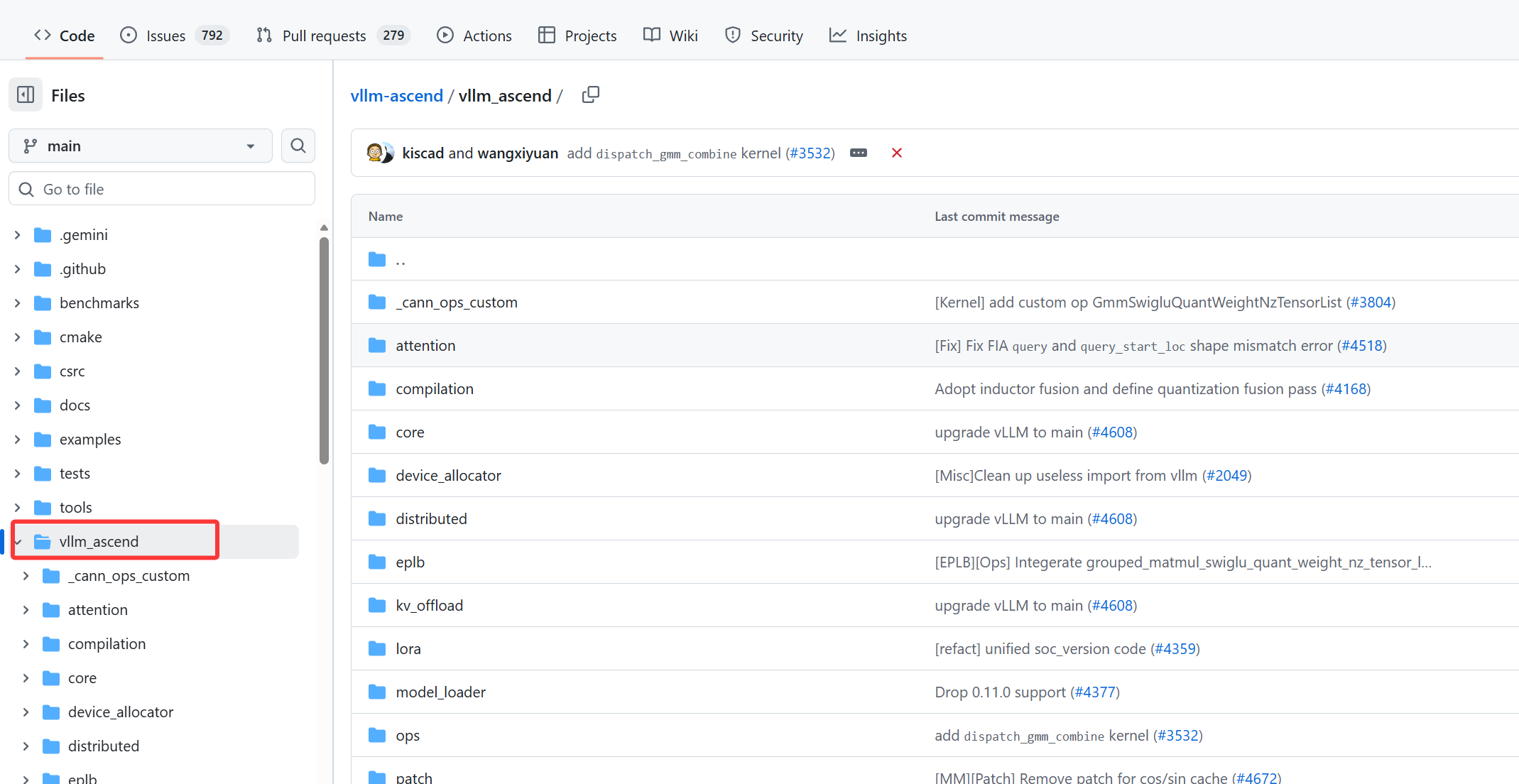
工具与辅助脚本
包括 collect_env.py 用于收集环境信息以辅助排查问题,format.sh 用于规范代码格式。csrc/ 目录包含 C++ 扩展代码,例如 tiling_base.h 处理算子分块逻辑,tools/ 下可能包含部署或调试相关工具。
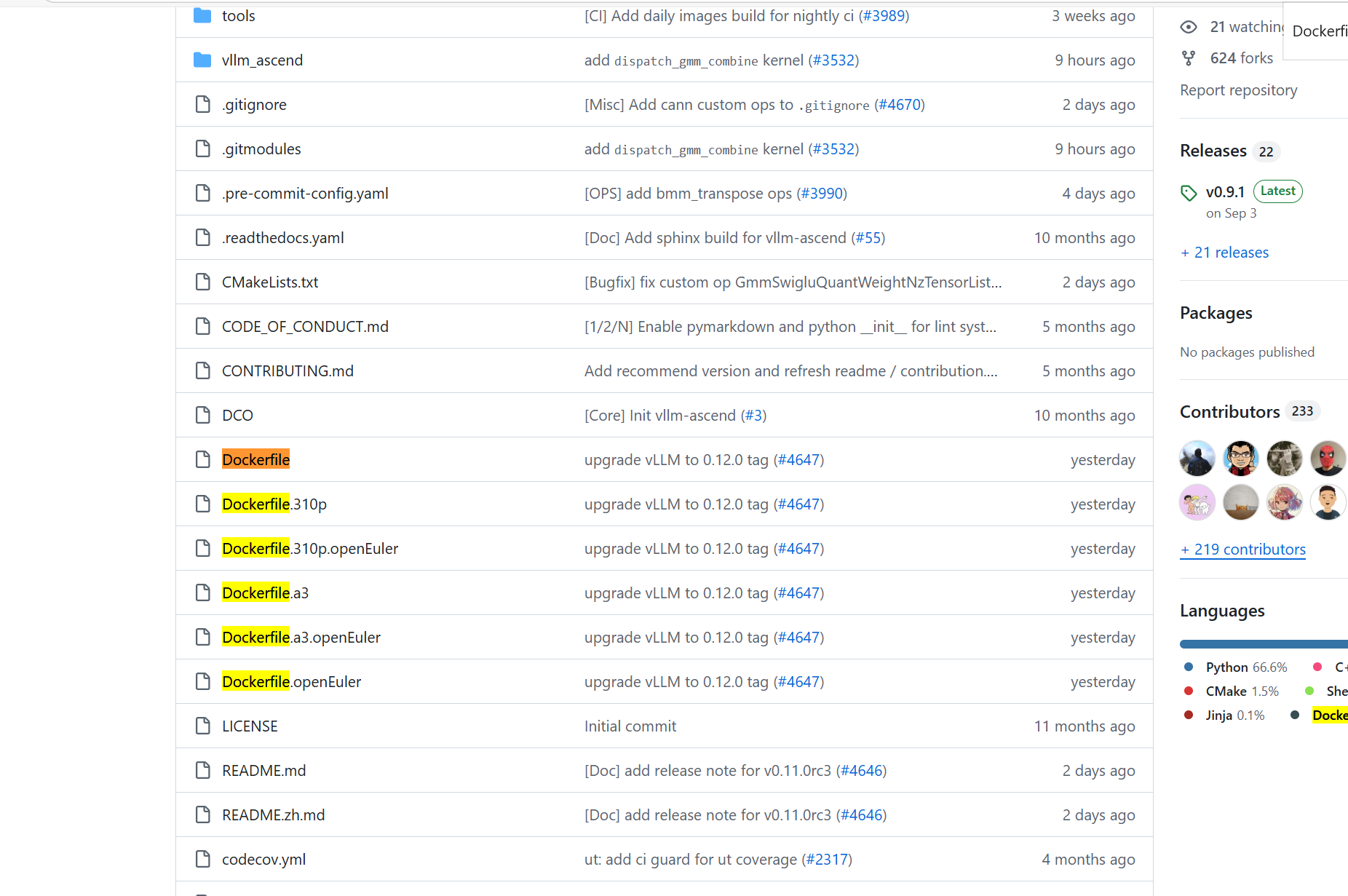
容器化部署配置
提供多个 Dockerfile(如 Dockerfile.310p、Dockerfile.a3 及对应 openEuler 版本),支持不同 Ascend 硬件和操作系统,简化环境搭建和部署流程。
性能与基准测试
benchmarks/ 目录下的脚本(如 ben_vocabparallelembedding.py)用于算子性能测试,帮助验证关键功能的计算效率。
版本与开发配置
.pre-commit-config.yaml 定义代码提交规范,mypy.ini 与 typos.toml 分别用于类型检查和拼写校验,requirements-*.txt 则细分了开发、lint 和运行依赖,保证开发环境一致性。
社区与规范文档
包含 CODE_OF_CONDUCT.md 明确社区行为准则,DCO 定义开发者贡献协议,.github/ 下提供 PR 模板和自动化工作流,规范贡献流程。
三、环境部署
在git仓库里面我们可以找到两个Readme文件,打开Readme文件我们就可以找到环境部署的具体流程了,使用官方给出的教程我们就能够快速的将环境部署好。
找到快速安装指南:
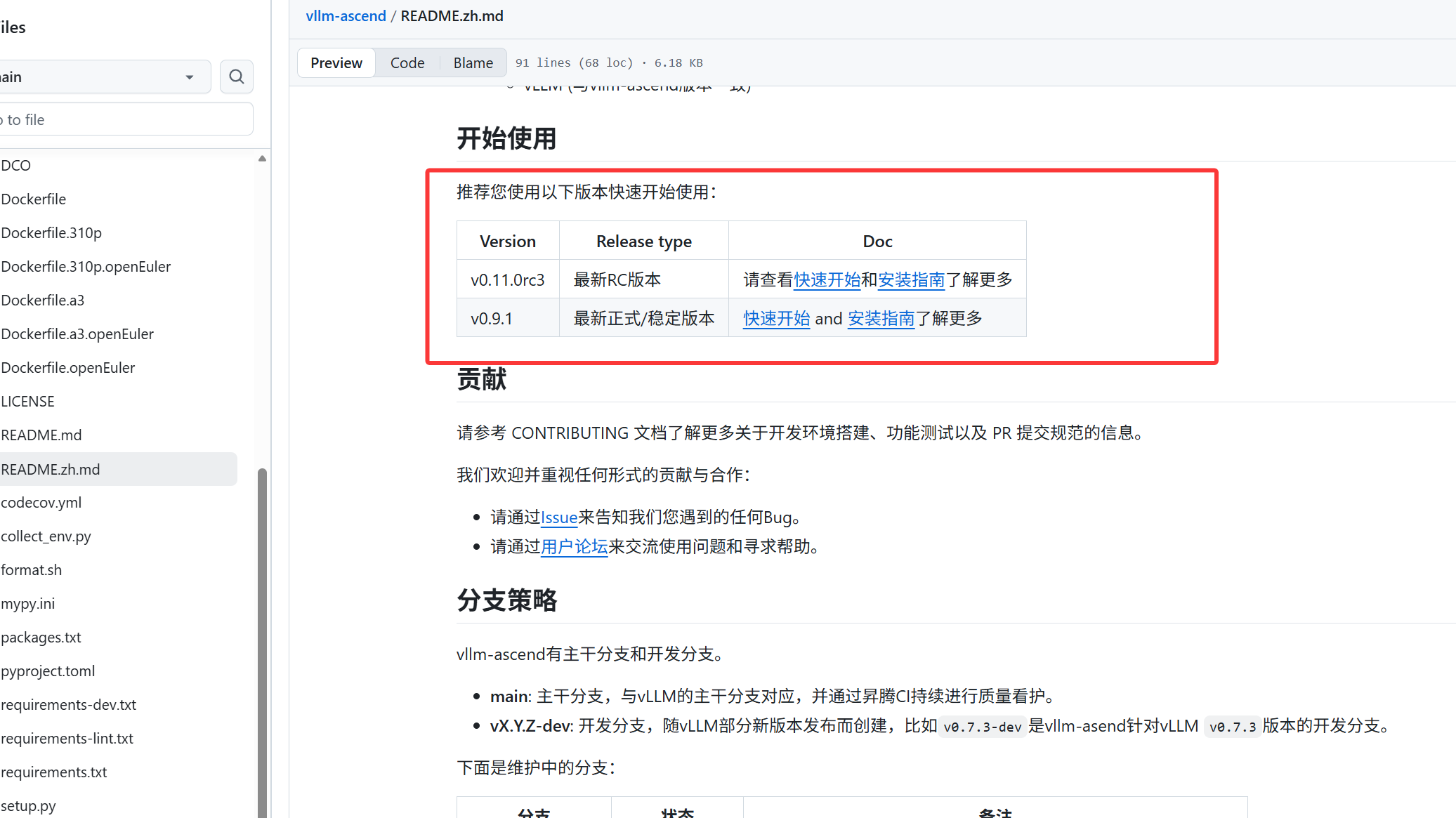
第一步我们需要先将Ascend环境搭建起来,在官网也可以找到对应的资料,安装起来也非常方便。
前置检查
-
确认昇腾 AI 处理器已安装:
lspci | grep 'Processing accelerators'
-
确认操作系统信息:
uname -m && cat /etc/lsb-release
-
确认 Python 版本:
python3 --version
注意:如果 Python 版本不符合要求(<3.10),请参考 3.1.4 节安装合适版本。
安装系统依赖
# 更新系统
apt-get update -y
# 安装基础依赖
sudo apt-get install -y gcc g++ make net-tools python3 python3-dev python3-pip创建驱动运行用户
# 检查 HwHiAiUser 用户是否存在
id HwHiAiUser
# 如果不存在,创建用户和组
sudo groupadd HwHiAiUser
sudo useradd -g HwHiAiUser -d /home/HwHiAiUser -m HwHiAiUser -s /bin/bash
# 将当前用户添加到 HwHiAiUser 组
sudo usermod -aG HwHiAiUser $USER安装昇腾驱动
# 下载驱动包
wget "https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Ascend%20HDK/Ascend%20HDK%2025.0.RC1.1/Ascend-hdk-910b-npu-driver_25.0.rc1.1_linux-x86_64.run"
# 赋予执行权限
chmod +x Ascend-hdk-910b-npu-driver_25.0.rc1.1_linux-x86_64.run
# 安装驱动
sudo ./Ascend-hdk-910b-npu-driver_25.0.rc1.1_linux-x86_64.run --full --install-for-all验证驱动安装:
npu-smi info安装昇腾固件
# 下载固件包
wget "https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Ascend%20HDK/Ascend%20HDK%2025.0.RC1.1/Ascend-hdk-910b-npu-firmware_7.7.0.1.231.run"
# 赋予执行权限
chmod +x Ascend-hdk-910b-npu-firmware_7.7.0.1.231.run
# 安装固件
sudo ./Ascend-hdk-910b-npu-firmware_7.7.0.1.231.run --full根据提示决定是否需要重启系统。安装成功后会显示:
Firmware package installed successfully!安装 Python 3.10
如果当前 Python 版本低于 3.10,需要安装 Python 3.10:
# 安装 Python 3.10
sudo apt-get install -y python3.10 python3.10-dev python3.10-venv python3-pip
# 设置 Python 3.10 为默认版本
sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.10 1
# 验证 Python 版本
python3 --version安装 CANN 工具包
-
安装 Python 依赖:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple attrs cython numpy==1.24.0 decorator sympy cffi pyyaml pathlib2 psutil protobuf==3.20 scipy requests absl-py
-
下载并安装 CANN:
下载 CANN 8.3.RC1 工具包
赋予执行权限
chmod +x Ascend-cann-toolkit_8.3.RC1_linux-x86_64.run
安装 CANN
./Ascend-cann-toolkit_8.3.RC1_linux-x86_64.run --full
-
设置 CANN 环境变量:
添加到 ~/.bashrc
echo "source /usr/local/Ascend/ascend-toolkit/set_env.sh" >> ~/.bashrc
立即生效
source ~/.bashrc
-
安装 CANN 内核:
下载 CANN 内核包
wget --header="Referer: https://www.hiascend.com/" https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/CANN/CANN 8.3.RC1/Ascend-cann-kernels-910b_8.3.RC1_linux-x86_64.run
赋予执行权限
chmod +x Ascend-cann-kernels-910b_8.3.RC1_linux-x86_64.run
安装内核包
./Ascend-cann-kernels-910b_8.3.RC1_linux-x86_64.run --install
-
安装 CANN NNAL:
下载 CANN NNAL 包
wget --header="Referer: https://www.hiascend.com/" https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/CANN/CANN 8.3.RC1/Ascend-cann-nnal_8.3.RC1_linux-x86_64.run
赋予执行权限
chmod +x Ascend-cann-nnal_8.3.RC1_linux-x86_64.run
安装 NNAL 包
./Ascend-cann-nnal_8.3.RC1_linux-x86_64.run --install
设置 NNAL 环境变量
echo "source /usr/local/Ascend/nnal/atb/set_env.sh" >> ~/.bashrc
source ~/.bashrc
vLLM-Ascend 安装
-
创建虚拟环境:
python3 -m venv vllm-ascend-env
source vllm-ascend-env/bin/activate -
安装系统依赖:
-
配置 pip 镜像:
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
配置额外索引(x86 机器必需)
pip config set global.extra-index-url "https://download.pytorch.org/whl/cpu/ https://mirrors.huaweicloud.com/ascend/repos/pypi"
安装 vLLM-Ascend
# 安装 vLLM-Ascend
pip install vllm-ascend验证安装
python -c "import vllm; print('vLLM version:', vllm.__version__)"如果大家更倾向于通过 Docker 来完成安装,也可以按照下面的步骤进行操作。使用容器的好处是环境独立、配置简单,不会影响到系统现有依赖。
-
安装 Docker:
apt-get update -y && apt-get install -y docker.io
启动 Docker 服务
sudo systemctl start docker
sudo systemctl enable docker -
配置 Docker 镜像加速:
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": [
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://mirrors.tuna.tsinghua.edu.cn"
]
}
EOF重启 Docker 服务
sudo systemctl daemon-reload
sudo systemctl restart docker -
拉取并运行 vLLM-Ascend 容器:
设置设备编号,根据实际情况调整
export DEVICE=/dev/davinci0
docker run --rm -it
--name vllm-ascend-container
--shm-size=1g
--device $DEVICE
--device /dev/davinci_manager
--device /dev/devmm_svm
--device /dev/hisi_hdc
-v /usr/local/dcmi:/usr/local/dcmi
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info
-v /etc/ascend_install.info:/etc/ascend_install.info
-v /root/.cache:/root/.cache
quay.io/ascend/vllm-ascend:v0.7.3-dev
bash -
在容器内验证安装:
python -c "import vllm; print('vLLM version:', vllm.version)"
多节点部署
vLLM-Ascend 支持多节点部署,用于构建大规模推理集群或应对更高的吞吐需求。多节点模式下,模型参数会按照一定策略在多台服务器之间分片或复用,各节点之间通过高速互联进行同步与通信。
验证节点间通信:
在实际进行多节点部署之前,最重要的基础工作就是确保各节点之间能够顺畅通信。如果节点之间网络不通、延迟过高,或者存在防火墙阻断,后续的分布式初始化都会直接失败。因此,在正式启动多节点推理服务之前,需要先完成基础的网络连通性检查。
-
获取节点 IP 地址:
ifconfig
-
跨节点 PING 测试:
在节点 1 上测试到节点 2 的连接
ping <节点 2 IP 地址>
验证部署
在完成环境安装后,可以通过一个最小可运行的示例脚本验证 vLLM-Ascend 是否能够正常加载模型、初始化昇腾 NPU,并成功执行推理任务。以下示例使用一个轻量级模型进行测试,便于快速确认环境是否正常。
创建测试脚本 simple_inference.py:
# simple_inference.py
from vllm import LLM, SamplingParams
def main():
# 创建 LLM 实例
llm = LLM(
model="facebook/opt-125m",
tensor_parallel_size=1,
gpu_memory_utilization=0.9,
trust_remote_code=True
)
# 设置采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.95,
max_tokens=100
)
# 输入文本
prompts = [
"Hello, my name is",
"The capital of France is"
]
# 生成文本
outputs = llm.generate(prompts, sampling_params)
# 输出结果
for i, output in enumerate(outputs):
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt}")
print(f"Generated text: {generated_text}")
print("=" * 50)
if __name__ == "__main__":
main()运行测试脚本:
python simple_inference.py输出结果:

四、基础配置
在构建或运行 vLLM-Ascend 之前,一些环境变量能够帮助你控制编译流程、优化运行效率、启用特性功能或调整底层组件路径。这些配置项在官方文档中也可以找到,但在实际使用中,经常需要根据硬件环境、编译器、CANN 版本或调试场景进行修改。
环境变量配置
官网提供的配置指南,我们按照提供的指南来进行配置就行了:
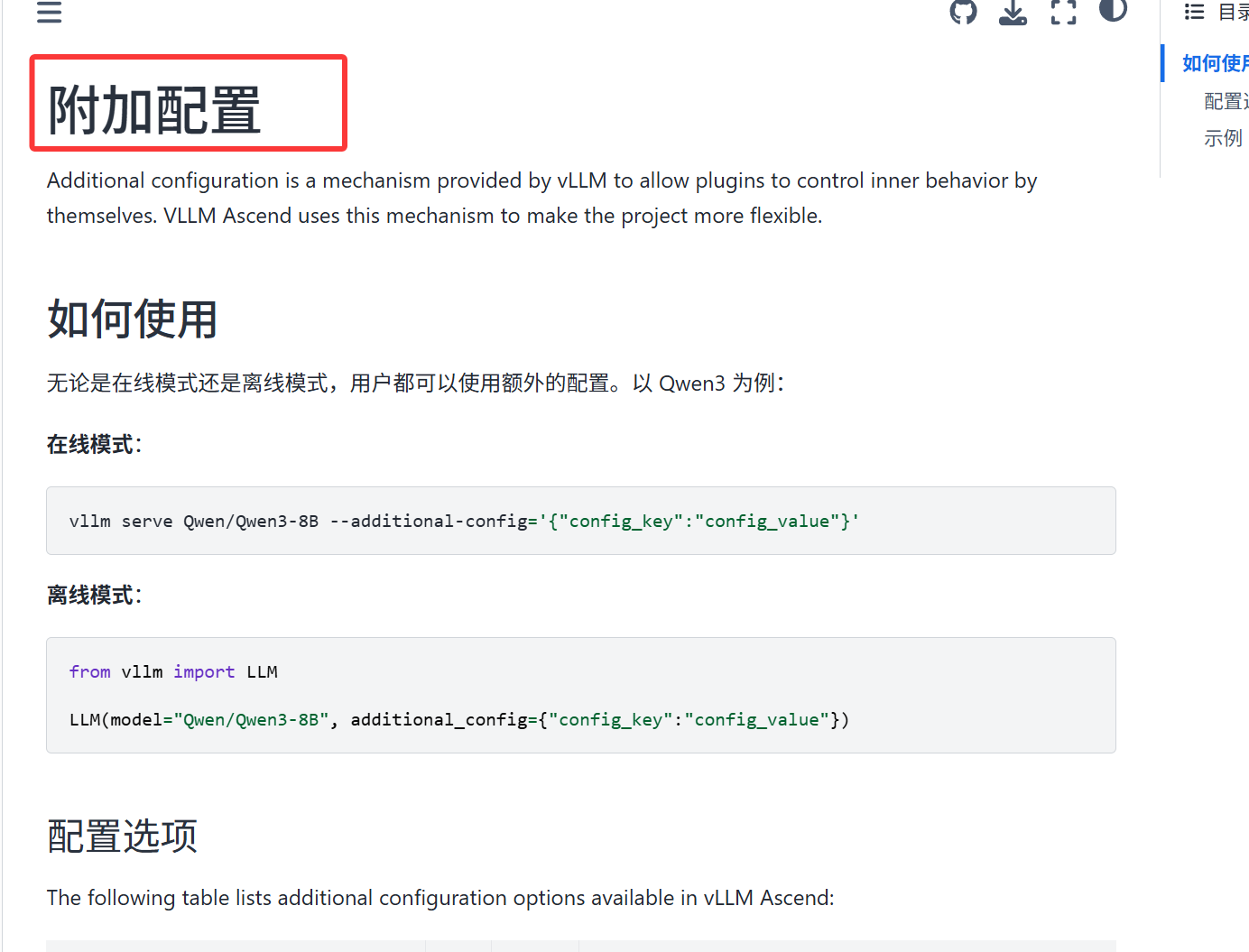
附加配置
vLLM 提供的附加配置(Additional Configuration) 机制,允许插件自主控制内部行为,vLLM Ascend 借助该机制提升了项目的灵活性。无论是在线服务模式还是离线调用模式,用户都可通过指定 additional_config 参数配置相关选项,适配不同模型(如 MoE 模型、DeepSeek 系列模型等)和业务场景(如推理性能优化、负载均衡、缓存量化等)。
五、总结
通过对 vLLM-Ascend 的学习和实践,你会发现这是一个设计规范、结构清晰、易于扩展的高性能推理插件。无论是单节点还是多节点部署,它都能够充分利用昇腾 NPU 的计算能力,为各种大语言模型提供稳定、高效的推理环境。
项目的模块划分非常明确:核心算子逻辑集中管理,辅助工具和性能基准脚本一目了然,Docker 容器化配置更是降低了环境搭建的复杂度。环境变量和附加配置机制让用户可以根据不同硬件和业务场景灵活调整运行参数,例如优化算子性能、控制缓存大小、启用负载均衡策略等。
在实际操作中,从驱动、固件、CANN 工具包,到 Python 环境,再到 vLLM-Ascend 的安装与测试,每一步都可以验证结果,确保推理环境稳定可靠。通过示例脚本快速测试模型加载和推理功能,能够让你对整个运行流程有直观的理解,并为后续的二次开发或性能优化打下坚实基础。
总的来说,掌握 vLLM-Ascend 的结构、部署与配置方法,不仅能让模型推理更高效,还能为你的开发和研究提供灵活的工具和清晰的路径。这对于希望在昇腾硬件上快速搭建高性能推理服务的人来说,是一个非常实用的参考和指南。