重要的事情说三遍:
有简历修改、职业规划、技术咨询、论文代写、就业培训等需求的,可关注主页并私信我额!!!
有简历修改、职业规划、技术咨询、论文代写、就业培训等需求的,可关注主页并私信我额!!!
有简历修改、职业规划、技术咨询、论文代写、就业培训等需求的,可关注主页并私信我额!!!
一、项目需求分析及架构设计
1.大数据离线项目需求分析
某新闻资讯平台,每天都会有大量用户访问应用,此时会产生大量的用户访问日志,为了优化平台内容、提升用户体验,并评估广告效果及平台整体表现,从而实现网站流量的有效增长和用户活跃度的提升,我们需要利用大数据技术统计以下用户指标:
(1)PV(页面浏览量)是衡量网站被访问页面数量的重要指标,反映了网站的流量情况;
(2)UV(独立访客数)则衡量了网站的真实用户数量,体现了用户的参与度与忠诚度。
通过综合分析PV和UV数据,可以全面了解平台的流量趋势和用户行为特征,为网站运营者提供决策依据。
2.大数据仓库项目需求分析
在信息爆炸的时代,新闻资讯行业对数据的需求日益迫切。为满足新闻资讯业务对数据深度挖掘与高效利用的需求,我们启动了新闻资讯数仓项目。本项目旨在构建数据采集平台,实施数据仓库分层建模,并为新闻资讯运营提供全面数据支持。通过精准的数据分析,助力新闻资讯业务决策优化,提升用户体验,推动业务持续增长。接下来,我们以新闻资讯用户行为数据为例来阐述项目需求分析,为项目的成功实施奠定坚实基础。
(1)数据采集平台建设
构建一个能够高效、准确地从各业务源头采集数据的平台,确保数据的完整性、一致性和实时性。在前面的章节中,我们已经完成了数据采集平台的搭建,这里就不再赘述。
(2)数据仓库分层建模
设计并实施数据仓库的分层架构,包括ODS层、DWD层、DWS层和ADS层,以优化数据存储、查询和分析性能。在ADS层中,根据业务需求,建立用户、新闻、流量等主题的数据模型,实现数据的结构化存储和高效访问。
(3)新闻资讯运营数据支持
1)用户主题
活跃用户评论占比分析:统计活跃用户在评论中的占比,深入了解用户参与度,为优化用户互动体验提供依据。
男女新闻关注度Topn分析:分别统计男女各自对新闻的关注度,列出Topn条新闻,揭示性别差异对新闻偏好的影响,为内容策划提供指导。
2)新闻主题
类别新闻点赞次数Topn分析:统计各类别新闻的点赞次数,列出Topn条新闻,评估新闻类别的受欢迎程度,为新闻内容优化提供参考。
平台新闻收藏次数Topn分析:统计各平台新闻的收藏次数,列出Topn条新闻,分析不同平台的用户偏好,为新闻分发策略提供依据。
每日新闻互动数据统计:统计每日新闻的点赞、收藏和转发次数,实时监控新闻的用户互动情况,为新闻运营提供数据支持。
3)流量主题
每日新闻资讯点击率分析:统计每日新闻资讯的点击率,评估新闻资讯的吸引力和用户关注度,为内容推荐提供数据支持。
页面访问时长Topn分析:统计单个页面的平均访问时长,列出Topn个页面,分析用户对页面内容的兴趣和停留时间,为页面优化提供指导。
页面加载性能分析:统计所有页面加载时间的平均值、最大值和最小值,评估网站性能和用户体验,为网站优化提供数据支持。
3.大数据实时项目需求分析
在当前数字化信息爆炸的时代,新闻资讯平台作为信息传播的重要渠道,每天承载着大量的新闻内容发布与用户互动。为了优化新闻内容推送策略、提升用户粘性,并深入了解新闻话题的热度分布及用户阅读习惯,我们亟需利用大数据技术对新闻话题的相关数据进行统计分析。具体需求如下:
(1)统计新闻话题曝光总量:评估新闻内容传播广度,优化内容布局和推送策略。
(2)统计新闻话题点击排行榜:展示用户偏好,指导新闻选题策划、内容创作及个性化推荐。
(3)统计不同时段新闻话题点击排行榜:把握用户不同时段的阅读需求,精准推送新闻内容,调整发布时间策略。
通过以上分析,为平台运营提供数据支撑,推动内容质量、用户体验及流量增长持续优化。
4.大数据推荐系统项目需求分析
在当前数字化信息爆炸的背景下,新闻资讯平台需要精准推送以满足用户个性化需求。本项目的需求分析如下:
- 运用大数据与机器学习技术,构建并持续优化用户兴趣模型,精准捕捉用户兴趣变迁,为个性化推荐奠定基础。
- 不断更新用户兴趣模型,调整新闻资讯推荐列表,确保每位用户获取高度贴合其兴趣的新闻资讯,增强阅读体验与满意度。
通过上述措施,不仅提升新闻资讯内容的传播效率与用户黏性,还为平台运营提供坚实数据支撑,促进内容质量、用户体验及流量的持续优化,引领新闻资讯平台迈向个性化推荐的新高度。
5.大数据可视化项目需求分析
系统核心功能涵盖新闻资讯列表展示、个性化推荐、数据实时大屏、数据仓库驾驶舱等四大模块。新闻资讯列表支持关键词搜索,满足高效浏览需求;推荐模块基于用户画像实现智能分发,提供个性化与全局热点内容;数据实时大屏通过动态排名与实时仪表盘,直观呈现舆情热点与趋势,构建完整的新闻舆情分析体系;数据仓库驾驶舱整合全维度历史与实时数据,通过多层级主题看板以及智能OLAP分析,支撑战略决策与运营优化,实现舆情实时监控与热点追踪的一站式深度分析。
(1)新闻列表展示
- 多维度展示:支持按新闻标题、新闻作者、发布时间、发布平台以及评论数来展示。
- 搜索功能:基于新闻资讯关键词的模糊搜索,支持实时响应查询结果。
- 分页加载:应对大规模数据场景,前端分页组件与后端分页查询协同优化性能。
(2)个性化推荐模块
- 用户定向推荐:基于预计算的推荐结果(如协同过滤结果),为登录用户推荐个性化新闻资讯列表。
- 默认推荐策略:基于全局热播结果,为未登录用户推荐热门新闻资讯列表。
(3)数据实时大屏
- 热点新闻Top10:按新闻资讯点击量、热度值动态排名。
- 新闻话题总量:仪表盘动态实时展示新闻资讯话题总量。
- 各时段热点新闻Top10:按各个时间段的新闻资讯点击量、热度值动态排名。
(4)数据仓库驾驶舱
- 全局数据总览:顶部展示新闻资讯总收藏数、点赞数、转发数、PV、UV以及页面平均、最大、最小加载时间等核心指标。
- 多维度分布分析:双饼图组合展示新闻资讯曝光/点击转化占比以及冷启动用户/普通用户/活跃用户的评论行为分布;热力地图渲染全国用户地理分布。
- 时序行为洞察:柱状图动态展示24小时内各个新闻资讯点击量Top10;折线图动态展示24小时内各个时间段新闻资讯点击量Top10。
二、大数据系统整体架构设计
一般情况下,一个完备的全堆栈大数据平台涵盖数据采集、数据存储、实时处理、批处理、数据服务与数据应用等若干个重要环节,而且针对具体的项目还需要根据具体的需求来确定。从新闻资讯项目的需求可以看出,该系统的具体架构设计如下图所示。

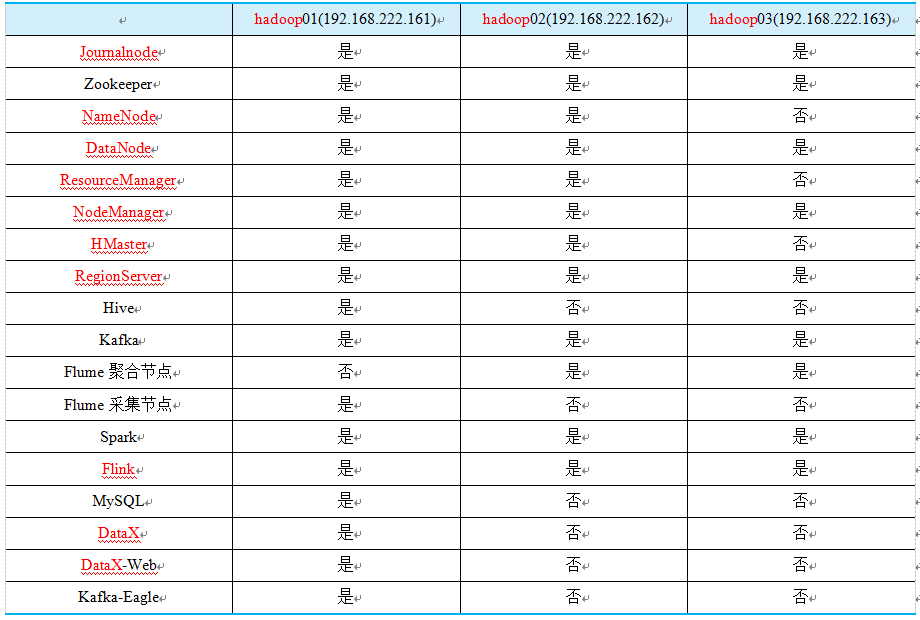
系统架构从下至上,第1层是数据源,数据源一般主要有两种数据类型,一种是日志文件数据,另一种是关系型数据库数据。第2层是采集层,Flume用来采集日志文件数据,DataX用来采集关系型数据库中的数据。第3层是存储层,Flume实时采集数据写入Kafka,然后用于实时计算,Flume实时采集数据写入HBase,然后用于离线计算,无论实时计算还是离线计算,如果最终的结果数据集比较小,都可以存入MySQL数据库,反之可以写入HBase数据库。第4层是计算层,MapReduce可以做离线计算,但由于MapReduce模型不灵活,编程成本高,这里可以使用Hive集成HBase做离线计算或者直接可以基于Hive构建离线数据仓库,Flink或Spark可以消费Kafka中的数据做实时计算。在生产环境中,MapReduce、Hive、Spark以及Flink等作业一般都运行在YARN集群中。第5层是服务层,数据经过处理之后,就需要为外部提供服务了。通俗地说,数据服务就是将处理后的数据提供给请求方,不同的数据供给方式将服务与不同的数据应用,常规的数据服务包含数据API、传输接口以及消息队列。第6层是应用层,在数据服务的支撑下,用户可以根据自己的需求进行即席查询,也可以通过H5+Echart实现数据可视化,还可以实现个性化推荐系统。在项目系统架构设计中,Zookeeper协调各个技术组件,IDEA基于Maven构建大数据项目进行业务代码的开发。
三、架构设计及数据流程设计
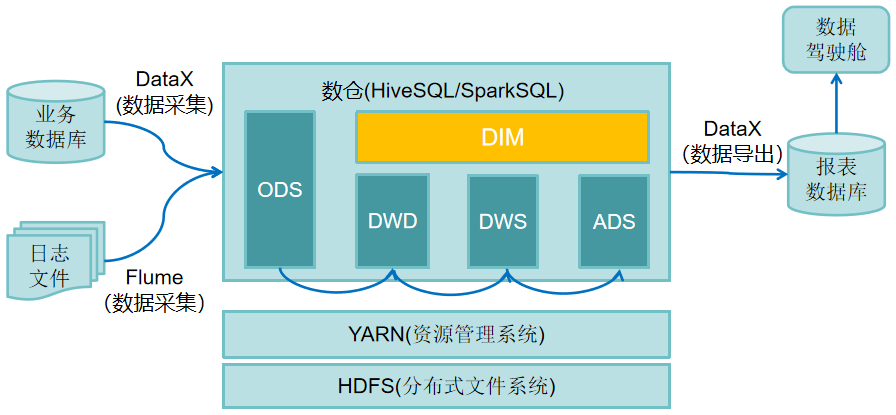
1. 数据仓库架构及数据流程设计
在数据仓库架构及数据流程设计中,首先,Flume负责采集日志文件数据,DataX负责采集数据库表数据,并将数据同步到大数据平台中,接着可以通过Hive工具分层构建数据仓库的ODS层、DWD层、DWS层以及ADS层,然后通过DataX将汇总数据导入报表数据库,最后应用层读取MySQL数据库制作数据仓库驾驶舱。数据仓库架构及数据流程设计如下图所示。
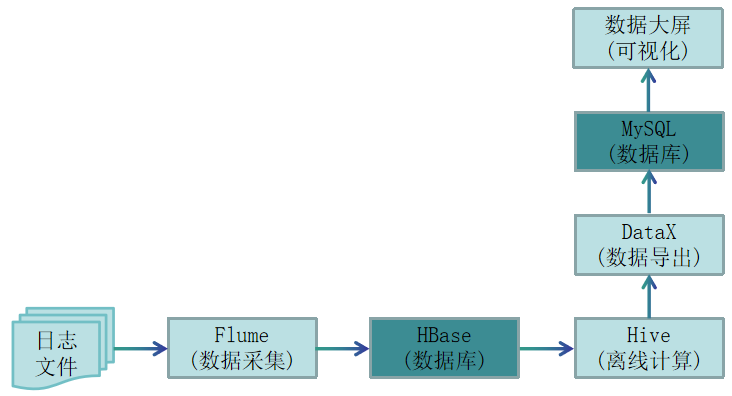
2. 离线计算架构及数据流程设计
在离线计算架构及数据流程设计中,首先,可以通过Flume实时采集日志数据到HBase数据库,然后通过Hive外部表映射到HBase,接着基于Hive进行大数据离线分析,再然后通过DataX工具将离线分析结果导入MySQL数据库,最后应用层读取MySQL数据实现数据大屏展示。离线计算架构及数据流程设计如下图所示。
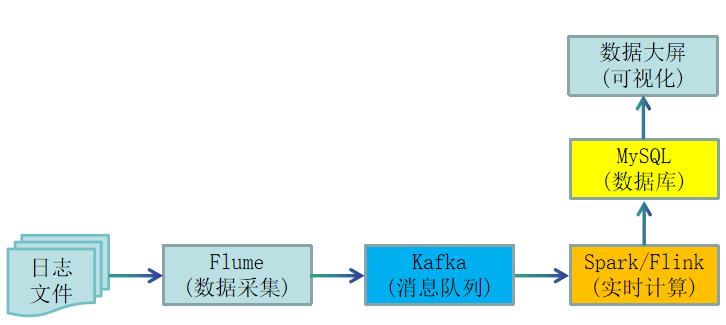
3. 实时计算架构及数据流程设计
在实时计算架构及数据流程设计中,首先,可以通过Flume实时采集日志数据到Kafka消息队列,接着可以通过Spark Streaming或Flink DataStream对数据进行实时分析,然后实时分析结果可以写入MySQL数据库,最后应用层读取MySQL数据实现数据实时大屏。实时计算架构及数据流程设计如下图所示。
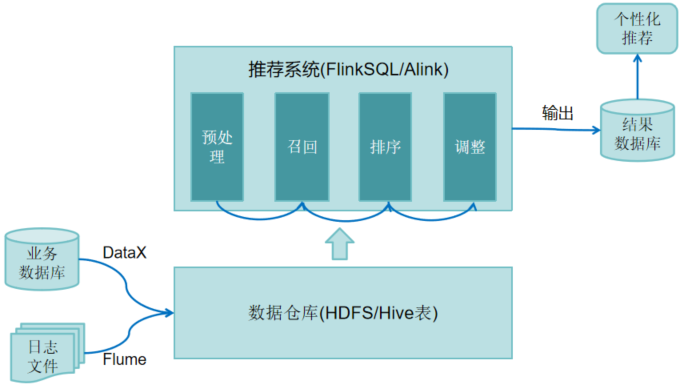
4. 推荐系统架构及数据流程设计
在推荐系统架构及数据流程设计中,首先,FlinkSQL读取Hive表对数据进行预处理,并将数据处理成ALS、LR等算法训练模型所需格式,然后基于ALS模型、全局热门、分群热门召回推荐结果,接着使用LR模型对召回结果集进行排序并筛选出最终的推荐结果集,再然后结合普通用户和冷启动用户调整推荐结果集,最后将推荐结果存入MySQL数据库作为个性化推荐系统使用。推荐系统架构及数据流程设计如下图所示。
四、大数据平台规划
大数据平台规划涉及硬件平台的搭建。在实际工作环境中,公司可以选择使用物理服务器、阿里云、腾讯云等不同的方式来搭建大数据平台。
五、新闻资讯大数据可视化
1.新闻资讯列表展示
在浏览器中输入地址:http://yj.news.net/,在系统首页的下方展示了新闻资讯列表信息如下图所示。新闻资讯列表可以分页进行加载,也可以按照关键词进行检索。

2.个性化推荐
在系统首页的中间,滚动展示了给每个用户推荐的新闻资讯列表信息如下图所示。当用户没有登录时,系统会给用户展示全局热门新闻;当用户登录之后,系统会给每个用户推荐个性化新闻。

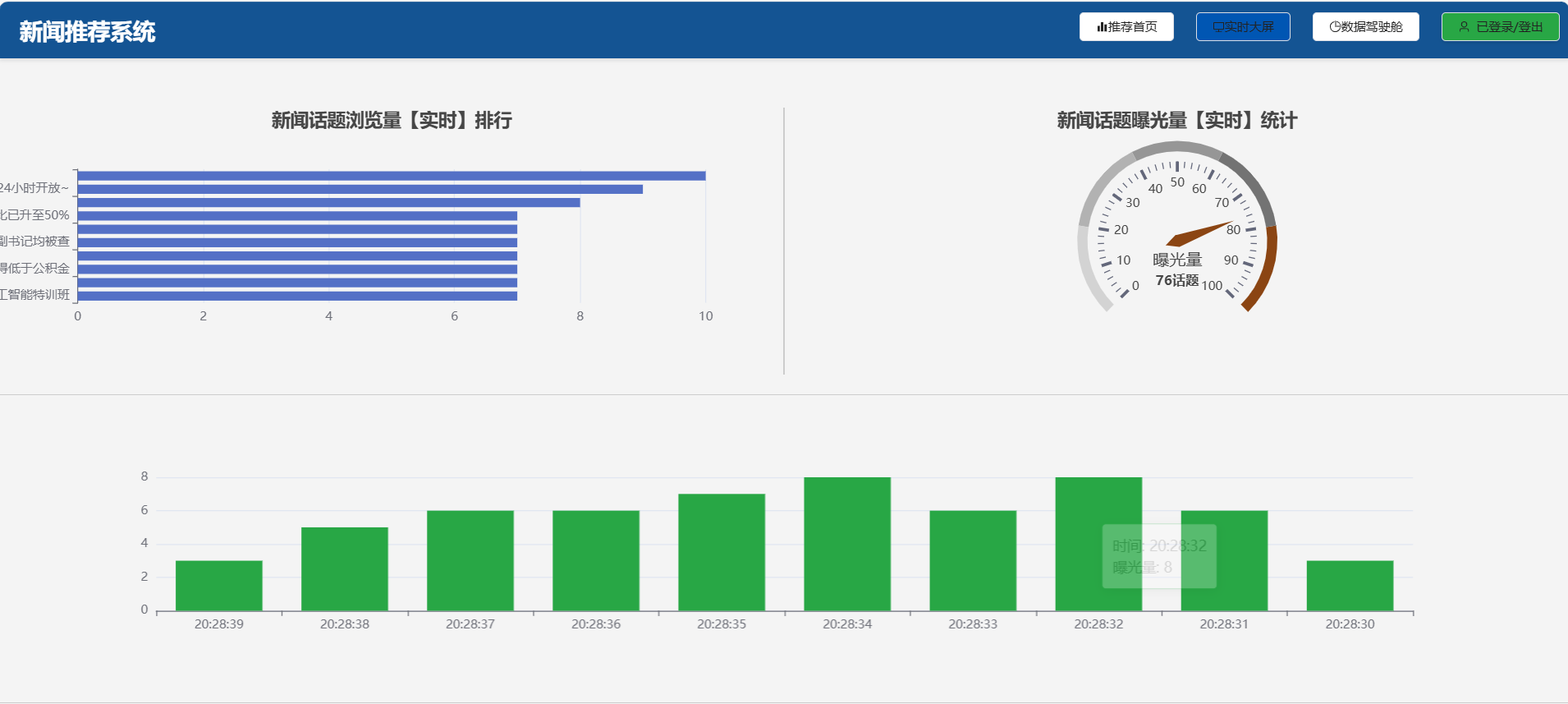
3.数据大屏展示
在系统首页右上方,点击"前往数据大屏"按钮,即可展示新闻资讯数据大屏如下图所示。数据大屏包含了新闻资讯总量数据、新闻资讯热门排行榜以及每个时段新闻数量排行榜。
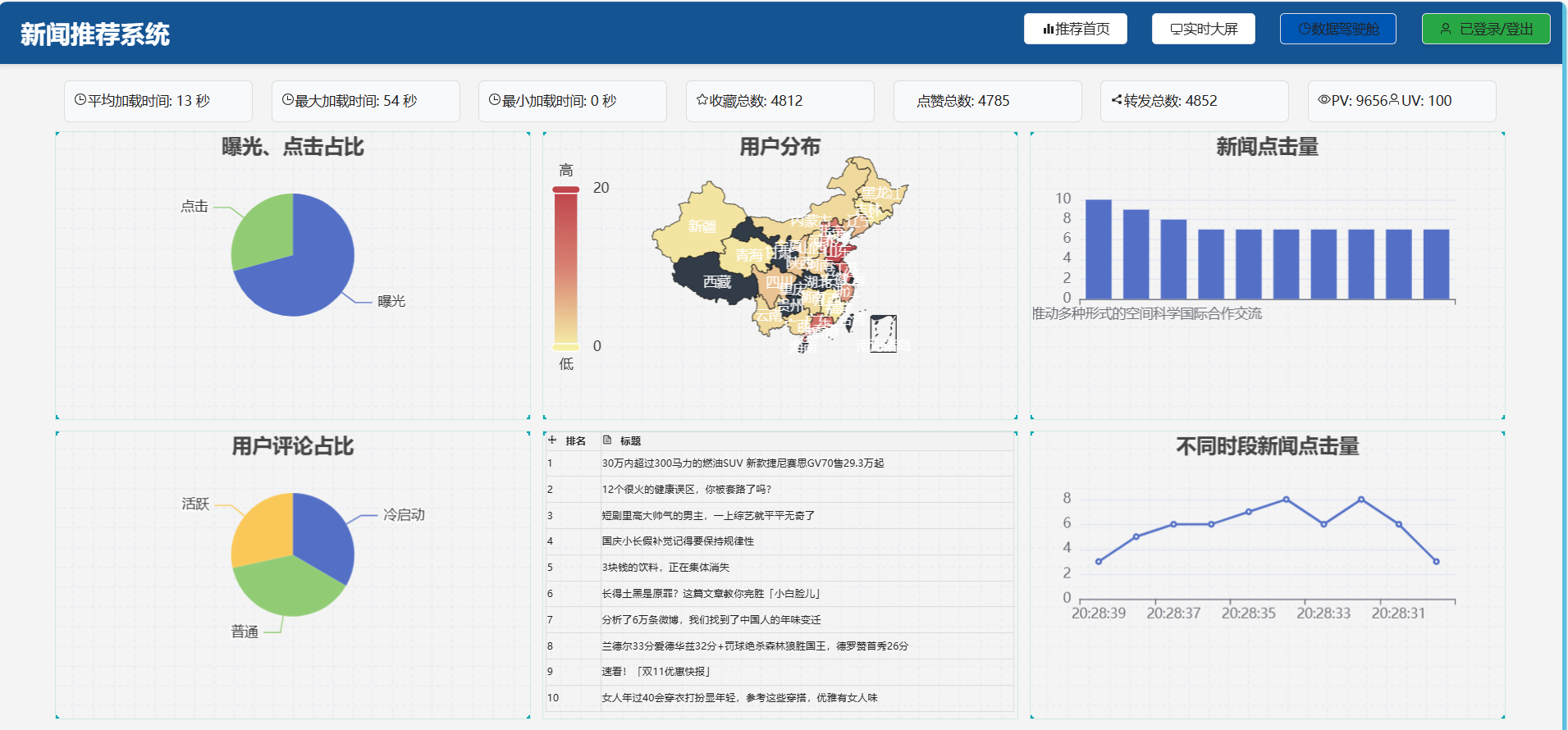
4.数据仓库驾驶舱
在系统首页右上方,点击"数据仓库驾驶舱"按钮,即可展示数据仓库驾驶舱如下图所示。数据仓库驾驶舱展示了新闻资讯互动汇总数据、曝光与点击数据、活跃用户评论数据、用户分布地图、新闻点击排行榜、各时段新闻点击排行榜以及全局热门新闻资讯列表等信息。
六、写在最后
本项目提供完整安装包、完整集群配置文件、完整项目数据集、集群脚本、数据库建表SQL、完整工程源码、完整课程PPT、完整课程集群word文档。