目录
[1.1 回车/换行:](#1.1 回车/换行:)
[1.2 那么咱们再来看一个例子:](#1.2 那么咱们再来看一个例子:)
[1.3 一个程序打开默认有三个文件流:](#1.3 一个程序打开默认有三个文件流:)
3.1以上代码中的fflush(stdout)是什么?有什么作用吗?如果说不写这个会怎么样呢?以及为什么会有两个进度条版本?Process版本与FlushProcess版本有什么区别吗?
[3.2 为什么旋转指示器要与时间有关,而不是与进度有关?那为什么process函数中的旋转指示器是与进度相关的?为什么回调函数的旋转指示器与进度无关,与时间有关?](#3.2 为什么旋转指示器要与时间有关,而不是与进度有关?那为什么process函数中的旋转指示器是与进度相关的?为什么回调函数的旋转指示器与进度无关,与时间有关?)
[3.3 回调函数中不是有int i = 0; for(; i < cnt; i++) processbuffi = STYLE;这个嘛?怎么进度还可能是突然的来回跳呢?难道与你传的参数有关?具体什么关系?](#3.3 回调函数中不是有int i = 0; for(; i < cnt; i++) processbuff[i] = STYLE;这个嘛?怎么进度还可能是突然的来回跳呢?难道与你传的参数有关?具体什么关系?)
1.前言:
那么咱们在讲进度条之前,必须得先知道的一些知识:
1.1 回车/换行:
这个其实是两个动作:回车就是换到下一行的开头。也就是\r。但是换行是换到下一行,就是\n,但是编译器一般会把\r\n合并为一个\n。所以,回车换行其实是两个动作。
那么刷新缓冲区有两种方式:1.\n 2.进程结束会自动刷新缓冲区
1.2 那么咱们再来看一个例子:
cpp
1.printf("hello world\r\n");
sleep(2)
2.printf("hello world");
sleep(2);第一个是打印完hello world后,程序2秒后会结束。
而第二个是先停2s,之后再打印,是因为1.printf打印hello world时,会先将这个缓存起来。没有打印到显示器,看不到是因为缓存起来了,所以说你才看不到。
2.之后,程序结束之后,缓存区间会重新刷新,所以2s后会显示。
3.而\r\n或者\n,会按照行为单位进行刷新缓存区间
显示器刷新数据是按照行刷新的。\r\n或者\n。(这个其实就是刷新)
程序运行结束的时候,缓冲区内部数据,会被自动刷新。
看下面的这张图片:缓冲区在内存里:
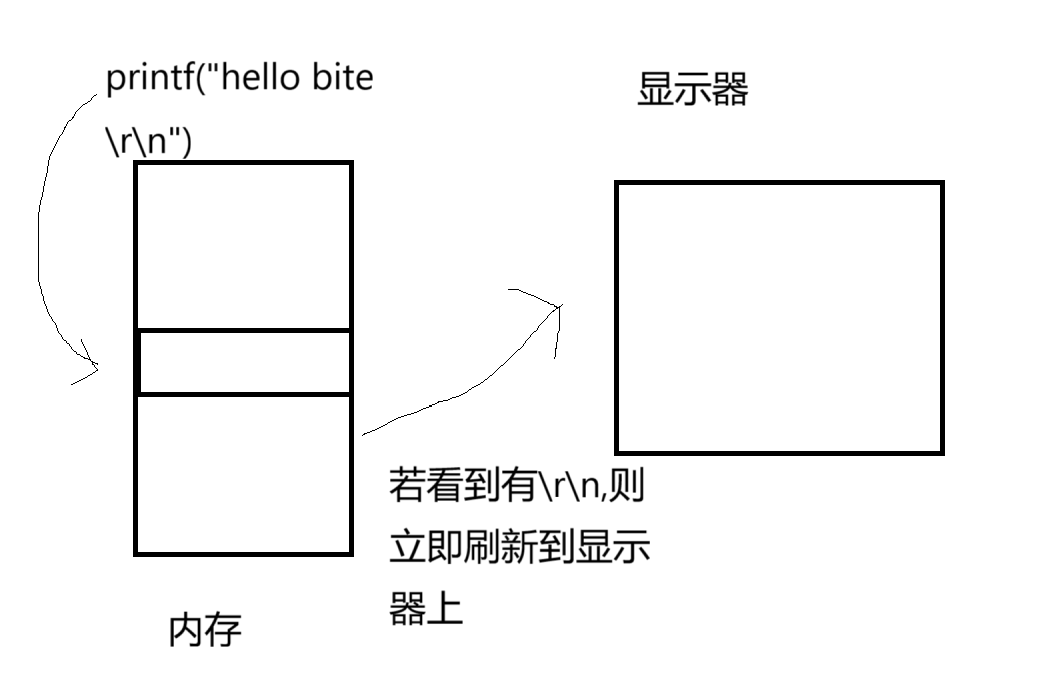
1.3 一个程序打开默认有三个文件流:
stdin,stdout,stderr
即标准输入 ,标准输出,标准错误
那么咱们通常强制刷新的话,就使用fflush(stdout)
\r可确保你每次光标都在同一个位置,从而进行数据加载。
1.usleep:单位是:microsecond:微秒。就是1s等于10的6次方微秒。
例如:5s=500 0000
你想想,5s打印完这个,即while(100)
usleep(50000)。4个0即可,所以你要再循环100呢。
2.例如,%-100d,这个-的意思是:左对齐,若是没有这个,例如:

而这个100是你打印的这个所占的宽度而已。
2.开始代码:
好,那么一开始的话,咱们的准备工作已经做完了,那么接下来,咱们先来看一段进度条代码初始版本:
cpp
void Process()
{
const char *lable = "|/-\\";
int len = strlen(lable);
char processbuff[SIZE];
memset(processbuff, '\0', sizeof(processbuff));
int cnt = 0;
while(cnt <= 100)
{
printf("[%-100s] [%d%%][%c]\r", processbuff, cnt, lable[cnt%len]);
fflush(stdout);
processbuff[cnt++] = STYLE;
usleep(30000);
}
printf("\n");
}好,那么咱们先来分析一下这段代码:
这是一个简单的进度条演示函数,不依赖于具体的下载数据,自己从0%到100%递增。
定义旋转指针和进度条数组。
循环从0到100,每次增加1。
每次循环更新进度条数组,打印进度条,并休眠30000微秒(0.03秒)。
使用
\r回车符覆盖上一次打印,实现动态更新。循环结束后打印换行。
那么其实这个进度条代码你实现的是非常平滑的动态更新的效果。并没有那种磕磕绊绊的效果。
那么咱们接下来看一下真正的需要传输下载数据的代码:
process.h:
cpp
#pragma once//这是一个预处理指令,确保头文件只被包含一次,防止重复定义。
#include <stdio.h>
// version1
void Process();//版本1的进度条函数,它是一个简单的演示,不依赖具体下载数据,自己从0%到100%递增。
void FlushProcess(double total, double curr); // 更新进度, 按照下载进度,进行更新进度条。
//这是一个回调函数,用于根据下载的总量和当前已下载量来更新进度条。process.c:
cpp
//这个函数用于显示下载进度条,它根据传入的总大小和当前已下载大小来计算进度。
#include "process.h"
#include <string.h>
#include <unistd.h>
#define SIZE 101
#define STYLE '='
void FlushProcess(double total, double curr) // 更新进度, 按照下载进度,进行更新进度条
{
if(curr > total)//确保当前进度不超过总大小。
curr = total;
double rate = curr / total * 100; // 1024.0 , 512.0 -> 0.5 -> 50.0//计算当前进度百分比。
int cnt = (int)rate; // 50.8 , 49.9 -> 50, 49//将百分比转换为整数,用于表示进度条中已完成的等号数量。
char processbuff[SIZE];//定义一个大小为101的字符数组,用于存储进度条字符串(100个等号加上一个空字符)。
memset(processbuff, '\0', sizeof(processbuff));//将数组初始化为全空字符。
//使用循环将前cnt个字符赋值为STYLE(即'='),表示已完成的进度。
int i = 0;
for(; i < cnt; i++)
processbuff[i] = STYLE;
static const char *lable = "|/-\\";//定义一个静态的旋转指针字符串,用于在进度条旁边显示一个旋转的动画,表示程序正在运行。
static int index = 0;//静态变量,用于记录当前旋转指针的位置。
// 刷新
printf("[%-100s][%.1lf%%][%c]\r", processbuff, rate, lable[index++]);
//%-100s:左对齐,宽度为100的字符串,这样进度条会从左边开始填充等号,右边用空格填充。
//%.1lf%%:显示百分比,保留一位小数。
//%c:显示旋转指针中的当前字符。
//\r:回车符,将光标移回行首,这样下一次打印会覆盖当前行,实现动态更新。
index %= strlen(lable);//确保index在旋转指针字符串的长度内循环。
fflush(stdout);//刷新标准输出,确保立即显示。因为通常标准输出是行缓冲的,而这里没有换行符,所以需要手动刷新。
if(curr >= total)//如果当前进度大于等于总进度,打印一个换行符,表示进度条完成。
{
printf("\n");
}
}
// version1: 能够使用吗??
// 说明原理
void Process()
{
const char *lable = "|/-\\";
int len = strlen(lable);
char processbuff[SIZE];
memset(processbuff, '\0', sizeof(processbuff));
int cnt = 0;
while(cnt <= 100)
{
printf("[%-100s] [%d%%][%c]\r", processbuff, cnt, lable[cnt%len]);
fflush(stdout);
processbuff[cnt++] = STYLE;
usleep(30000);
}
printf("\n");
}那么通过这个你可以看出来process与flushprocess的区别:
1.这是一个自增的演示版本,不依赖实际下载数据
2.每30ms自动增加1%的进度
main.c:
cpp
#include "process.h"
#include <unistd.h>
#include <time.h>
#include <stdlib.h>
//全局变量gtotal和speed:在代码中并未使用,可以忽略。
double gtotal = 1024.0;
double speed = 1.0;
// 函数指针类型
typedef void (*callback_t)(double, double);//定义函数指针类型callback_t,指向一个接受两个double参数(总大小和当前大小)并无返回值的函数。
// 1.0 4.3
double SpeedFloat(double start, double range) // [1.0 3.0] -> [1.0, 4.0]//SpeedFloat函数用于生成一个随机的下载速度增量。它接受一个起始值和一个范围,返回一个在[start, start+range)之间的随机浮点数。这里将范围分成整数部分和小数部分,整数部分用rand()取模,小数部分直接加上。
{
int int_range = (int)range;
return start + rand()%int_range + (range - int_range);
}
// cb: 回调函数
//DownLoad函数:模拟下载过程。
//使用srand(time(NULL))初始化随机数种子。
//从0开始累计下载量curr,每次增加一个随机值(通过SpeedFloat生成)。
//在每次增加后,调用回调函数cb更新进度条。
//如果当前下载量超过总大小,则设置为总大小,调用一次回调函数,然后退出循环。
//每次循环休眠30000微秒(0.03秒),模拟下载时间。
void DownLoad(int total, callback_t cb)
{
srand(time(NULL));
double curr = 0.0;
while(1)
{
if(curr > total)
{
curr = total; // 模拟下载完成
cb(total, curr); // 更新进度, 按照下载进度,进行更新进度条
break;
}
cb(total, curr); // 更新进度, 按照下载进度,进行更新进度条
curr += SpeedFloat(speed, 20.3); // 模拟下载行为
usleep(30000);
}
}
//main函数:依次模拟四个不同大小的下载任务,每个任务都调用DownLoad函数,并传入FlushProcess作为回调函数来显示进度条。
int main()
{
printf("download: 20.0MB\n");
DownLoad(20.0, FlushProcess);
printf("download: 2000.0MB\n");
DownLoad(2000.0, FlushProcess);
printf("download: 100.0MB\n");
DownLoad(100.0, FlushProcess);
printf("download: 20000.0MB\n");
DownLoad(20000.0, FlushProcess);
return 0;
}那么咱们的下载模拟逻辑是什么呢?
-
初始化随机数生成器
-
循环模拟下载过程
-
每次循环:
-
检查是否完成
-
调用回调函数更新进度条
-
增加随机下载量
-
暂停30ms模拟网络延迟
-
Makefile:
cpp
BIN=process//指定生成的可执行文件名为process。
CC=gcc//指定编译器为gcc。
SRC=$(wildcard *.c)//获取当前目录下所有.c文件。
OBJ=$(SRC:.c=.o)//将SRC中的.c文件替换为.o文件,得到目标文件列表。
$(BIN):$(OBJ)//可执行文件依赖于所有.o文件,链接这些.o文件生成可执行文件。
$(CC) -o $@ $^
%.o:%.c//每个.o文件依赖于同名的.c文件,编译.c文件生成.o文件。
$(CC) -c $<
.PHONY:clean//删除可执行文件和所有.o文件。
clean:
rm -f $(BIN) $(OBJ)
以上就是我对于这个进度条代码的看法以及想法,那么咱们接下来再来看一下有一些细节问题:
3.一些细节问题:
3.1以上代码中的fflush(stdout)是什么?有什么作用吗?如果说不写这个会怎么样呢?以及为什么会有两个进度条版本?Process版本与FlushProcess版本有什么区别吗?
fflush(stdout) 是一个标准C库函数,用于强制刷新标准输出流(stdout)的缓冲区。
作用机制
标准输出的缓冲机制:
-
全缓冲:当输出到文件时,通常采用全缓冲,缓冲区满时才实际写入
-
行缓冲 :当输出到终端时,通常采用行缓冲,遇到换行符
\n或缓冲区满时刷新 -
无缓冲:标准错误流(stderr)通常无缓冲
如果不写 fflush(stdout) 会怎样?
cpp
// 问题示例:没有fflush的情况
printf("[%-100s][%.1lf%%][%c]\r", processbuff, rate, lable[index++]);
// 这里没有fflush(stdout)
usleep(30000);会出现的问题:
-
-
进度条不实时更新
-
由于使用的是回车符
\r而不是换行符\n -
行缓冲机制不会自动刷新,输出会停留在缓冲区中
-
用户可能长时间看不到进度更新
-
-
进度条"跳跃式"显示
-
缓冲区积累多个进度状态
-
当缓冲区满或程序结束时才一次性显示
-
失去了平滑的动画效果
-
-
3.视觉体验差距:
# 可能看到的输出: [==================================================][50.0%][|] # 突然跳到 [============================================================][100.0%][-] # 中间过程完全看不到
实际演示对比:
有fflush(stdout):
[================= ][17.0%][|] # 立即显示 [========================= ][25.0%][/] # 30ms后更新 [================================= ][33.0%][-] # 平滑过渡
无fflush(stdout):
# 长时间空白... # 突然显示完成 [============================================================][100.0%][/]
3.2 void FlushProcess(double total, double curr) { if(curr > total) curr = total; double rate = curr / total * 100; int cnt = (int)rate; char processbuffSIZE; memset(processbuff, '\0', sizeof(processbuff)); // 填充进度条 for(int i = 0; i < cnt; i++) processbuffi = STYLE; static const char *lable = "|/-\\"; static int index = 0; // 单次显示 printf("%-100s%.1lf%%%c\r", processbuff, rate, lableindex++); index %= strlen(lable); fflush(stdout); if(curr >= total) printf("\n"); }这段代码为什么要单独定义一个static变量?有什么意义呢?以及为什么要单独定义一个index?
void Process() { const char *lable = "|/-\\"; int len = strlen(lable); char processbuffSIZE; memset(processbuff, '\0', sizeof(processbuff)); int cnt = 0; while(cnt <= 100) { printf("%-100s %d%%%c\r", processbuff, cnt, lablecnt%len); fflush(stdout); processbuffcnt++ = STYLE; usleep(30000); } printf("\n"); }为什么这个里面就是下标与计数用的是同一个?为什么第一个就不可以?依据是什么?
static 的语义:
-
使变量的生命周期延长到整个程序运行期间
-
使变量的作用域仍限于当前函数内
-
变量在多次函数调用间保持其值不变
如果不使用 static 会怎样?
cpp
// 错误版本:没有static
void FlushProcess(double total, double curr)
{
const char *lable = "|/-\\"; // 每次调用都重新初始化
int index = 0; // 每次调用都从0开始
printf("[%-100s][%.1lf%%][%c]\r", processbuff, rate, lable[index++]);
// ...
}问题效果:
[=======][25.0%][|] // 第一次调用,显示'|' [========][30.0%][|] // 第二次调用,又显示'|' [=========][35.0%][|] // 第三次调用,还是'|' // 旋转指示器永远停留在'|',不会旋转!
使用 static 的正确效果:
cpp
static int index = 0; // 只在第一次调用时初始化为0
printf("[%-100s][%.1lf%%][%c]\r", processbuff, rate, lable[index++]);
index %= strlen(lable); // 循环:0,1,2,3,0,1,2,3...正确效果:
[=======][25.0%][|] // index=0 → '|' [========][30.0%][/] // index=1 → '/' [=========][35.0%][-] // index=2 → '-' [==========][40.0%][\] // index=3 → '\' [===========][45.0%][|] // index=0 → '|' (循环)
为什么两个版本的下标使用方式不同?
Process 版本的分析
cpp
void Process()
{
const char *lable = "|/-\\";
int len = strlen(lable);
char processbuff[SIZE];
memset(processbuff, '\0', sizeof(processbuff));
int cnt = 0;
while(cnt <= 100)
{
printf("[%-100s] [%d%%][%c]\r", processbuff, cnt, lable[cnt%len]);
fflush(stdout);
processbuff[cnt++] = STYLE;
usleep(30000);
}
printf("\n");
}为什么这里可以用 cnt%len?
关键原因:Process 是连续执行的
-
单次函数调用 :整个进度条动画在一次函数调用中完成
-
连续递增 :
cnt从0到100连续递增,没有中断 -
时间连续性:每次循环间隔30ms,保证动画流畅
执行流程:
第1次循环: cnt=0 → lable[0%4]=lable[0]='|' 第2次循环: cnt=1 → lable[1%4]=lable[1]='/' 第3次循环: cnt=2 → lable[2%4]=lable[2]='-' 第4次循环: cnt=3 → lable[3%4]=lable[3]='\' 第5次循环: cnt=4 → lable[4%4]=lable[0]='|' ...
FlushProcess 版本的分析
为什么不能用进度值作为下标?
cpp
// 错误想法:用进度值作为旋转指示器下标
printf("[%-100s][%.1lf%%][%c]\r", processbuff, rate, lable[(int)rate % strlen(lable)]);问题分析:
-
进度与时间脱节:
-
进度值反映的是任务完成度 ,不是时间流逝
-
快速任务:进度很快,旋转指示器转得飞快
-
慢速任务:进度很慢,旋转指示器几乎不动
-
实际效果问题:
// 假设下载速度很快 DownLoad(100.0, FlushProcess); // 快速完成 // 可能的效果: [==][2.0%][|] // rate=2 → 2%4=2 → '-' [====][4.0%][|] // rate=4 → 4%4=0 → '|' [======][6.0%][/] // rate=6 → 6%4=2 → '-' // 旋转混乱,没有规律!
多个下载任务:
cpp
DownLoad(20.0, FlushProcess); // 小文件,快速
DownLoad(2000.0, FlushProcess); // 大文件,慢速-
小文件:进度变化快 → 旋转快
-
大文件:进度变化慢 → 旋转慢
-
用户体验不一致
还有几个可能比较棘手的问题,也算是细节上的问题吧,就是关于用户体验方面的:
3.2 为什么旋转指示器要与时间有关,而不是与进度有关?那为什么process函数中的旋转指示器是与进度相关的?为什么回调函数的旋转指示器与进度无关,与时间有关?
- 心理预期原理
用户对旋转指示器的心理预期:
-
旋转速度 = 程序"正在工作"的视觉反馈
-
应该保持恒定节奏,给用户稳定的心理预期
如果与进度相关的问题:
// 进度相关的旋转(错误示例)
=======25.0%\| // 转得慢
=====================50.0%/ // 转得快
==================================75.0%- // 转得飞快
用户会困惑:"为什么有时候转得快,有时候转得慢?程序出问题了吗?"
- 任务独立性原则
cpp
// 不同大小的下载任务
DownLoad(20.0, FlushProcess); // 小文件,快速完成
DownLoad(20000.0, FlushProcess); // 大文件,慢速完成进度相关的旋转问题:
-
小文件:进度变化快 → 旋转飞快(像疯了)
-
大文件:进度变化慢 → 旋转缓慢(像卡住了)
-
用户体验不一致
时间相关的旋转优势:
-
所有任务:相同的旋转速度
-
用户获得一致的视觉反馈
- 信息分离原则
进度条应该传达两种独立信息:
| 信息类型 | 传达内容 | 应该由什么控制 |
|---|---|---|
| 完成度 | 任务完成了多少 | 实际进度数据 |
| 活跃状态 | 程序是否在运行 | 时间 |
// 正确:信息分离
====================20.0%\| // 完成度低,但程序活跃
==================================80.0%\| // 完成度高,程序同样活跃
// 错误:信息混淆
====================20.0%\| // 完成度低,程序"看起来"不活跃
==================================80.0%/ // 完成度高,程序"看起来"活跃
为什么Process函数可以用进度相关的旋转?
Process函数的特殊性:
-
单一执行环境
cppvoid Process() // 一次性执行完毕 { while(cnt <= 100) // 连续循环,不会中断 { // 使用cnt%len作为下标 ✅ usleep(30000); // 固定时间间隔 } } -
固定时间间隔
-
每次循环都是30ms
-
进度与时间线性相关
-
cnt本质上是伪装的时间计数器
-
-
演示目的
-
不需要处理真实的工作负载
-
进度增长是均匀的
-
进度与时间完全同步
-
实际对比:
Process函数(进度相关但效果正确):
时间: 0ms 进度: 0% 旋转: | (0%4=0)
时间: 30ms 进度: 1% 旋转: / (1%4=1)
时间: 60ms 进度: 2% 旋转: - (2%4=2)
时间: 90ms 进度: 3% 旋转: \ (3%4=3)
时间: 120ms 进度: 4% 旋转: | (4%4=0)
→ 实际上还是时间驱动,因为进度与时间线性相关!
FlushProcess(如果进度相关就出问题):
时间: 0ms 进度: 10% 旋转: / (10%4=2) ← 突然开始!
时间: 30ms 进度: 25% 旋转: | (25%4=1)
时间: 60ms 进度: 35% 旋转: - (35%4=3)
时间: 90ms 进度: 40% 旋转: | (40%4=0)
→ 旋转混乱,没有时间规律!
回调函数场景的特殊性
回调函数的调用模式:
cpp
void DownLoad(int total, callback_t cb)
{
double curr = 0.0;
while(1)
{
cb(total, curr); // 回调频率可能变化!
curr += SpeedFloat(speed, 20.3); // 增量随机
usleep(30000);
}
}关键问题:回调间隔可能不均匀
-
网络波动导致下载速度变化
-
系统负载影响回调频率
-
不同的任务有不同的回调模式
如果旋转与进度相关的问题场景:
// 场景1:网络卡顿
=======25.0%\| // 正常速度
=======25.0%\| // 卡住了,进度不变,旋转停止!
=======25.0%\| // 用户以为程序死了
// 场景2:网络爆发
=======25.0%\| // 正常
=====================50.0%/ // 突然很快,旋转跳跃
时间相关旋转的优势:
// 无论进度如何,旋转保持恒定
=======25.0%\| // 正常速度,旋转持续
=======25.0%/ // 卡住了,但旋转继续 → 程序还在工作!
=======25.0%- // 用户知道程序没死,只是卡住了
=====================50.0%\\ // 网络恢复,旋转依然稳定
设计哲学总结
Process函数:理想世界的进度条
-
假设一切完美:固定间隔、线性进度
-
进度与时间完全同步 → 可以用进度控制旋转
-
适合教学演示
FlushProcess函数:现实世界的进度条
-
面对真实环境:网络波动、负载变化
-
进度与时间可能脱节 → 必须用时间控制旋转
-
提供稳定的用户体验反馈
3.3 回调函数中不是有int i = 0; for(; i < cnt; i++) processbuffi = STYLE;这个嘛?怎么进度还可能是突然的来回跳呢?难道与你传的参数有关?具体什么关系?
这个是有关进度跳跃的问题:
代码执行流程分析
当前的填充逻辑:
cpp
double rate = curr / total * 100; // 比如:25.6%
int cnt = (int)rate; // 截断为25
char processbuff[SIZE];
memset(processbuff, '\0', sizeof(processbuff));
for(int i = 0; i < cnt; i++)
processbuff[i] = STYLE; // 填充25个等号问题在于:进度值的来源
下载模拟中的进度计算
看DownLoad函数:
cpp
void DownLoad(int total, callback_t cb)
{
srand(time(NULL));
double curr = 0.0;
while(1)
{
if(curr > total) {
curr = total;
cb(total, curr);
break;
}
cb(total, curr); // 回调显示进度
curr += SpeedFloat(speed, 20.3); // 关键在这里!
usleep(30000);
}
}SpeedFloat函数的问题:
cpp
double SpeedFloat(double start, double range) // [1.0 3.0] -> [1.0, 4.0]
{
int int_range = (int)range; // range=20.3 → int_range=20
return start + rand()%int_range + (range - int_range);
// 返回:1.0 + [0-19] + 0.3 = [1.3, 20.3] 之间的随机数
}产生进度跳跃的具体场景
场景1:小文件下载(total=20.0)
// 第1次回调:curr = 0 + 15.7 = 15.7
rate = 15.7 / 20.0 * 100 = 78.5%
cnt = 78
显示:填充78个等号78.5%某个旋转字符
// 第2次回调:curr = 15.7 + 18.2 = 33.9 → 但33.9 > 20.0
if(curr > total) curr = total; // curr被截断为20.0
rate = 20.0 / 20.0 * 100 = 100%
cnt = 100
显示:填充100个等号100.0%下一个旋转字符
用户看到的效果:===============================================================================\]\[78.5%\]\[\|
====================================================================================================\]\[100.0%\]\[/
→ 从78%直接跳到100%!
场景2:大文件下载中的随机波动// 假设total=1000.0
// 第n次回调:curr=245.3
rate = 245.3 / 1000.0 * 100 = 24.53%
cnt = 24
显示24个等号
// 第n+1次回调:curr=245.3 + 1.5 = 246.8
rate = 246.8 / 1000.0 * 100 = 24.68%
cnt = 24 // 还是24!
显示24个等号(进度条长度没变)
// 第n+2次回调:curr=246.8 + 19.8 = 266.6
rate = 266.6 / 1000.0 * 100 = 26.66%
cnt = 26
显示26个等号
用户看到的效果:========================24.5%\| // 停留
========================24.6%/ // 还是24个等号
==========================26.6%- // 突然跳到26个等号
→ 进度条长度"跳跃式"增长!
问题的根本原因
- 进度条分辨率问题
-
进度条只有100个位置(0-100%)
-
但实际进度是浮点数,有更高精度
-
(int)rate导致精度丢失
- 随机增量的大小波动
SpeedFloat返回[1.3, 20.3]的随机值:
-
小增量:可能不足以让
cnt增加 -
大增量:可能让
cnt增加多个单位
- 边界截断问题
如场景1所示,小文件容易因超额下载导致进度直接跳到100%
验证你的观察
你说"回调函数中不是有for循环填充吗?",确实如此,但问题在于:
cnt的值本身就在跳跃!
// 假设连续几次回调:
回调1: curr=15, rate=15%, cnt=15 → 显示15个=
回调2: curr=17, rate=17%, cnt=17 → 显示17个= ← 正常增长
回调3: curr=35, rate=35%, cnt=35 → 显示35个= ← 突然跳跃!
回调4: curr=36, rate=36%, cnt=36 → 显示36个= ← 又正常了
那么最后的最后,再来看一眼代码吧:
4.代码总结:
process.h:
cpp
#pragma once
#include <stdio.h>
// version1
void Process();
void FlushProcess(double total, double curr); // 更新进度, 按照下载进度,进行更新进度条。process.c
cpp
#include "process.h"
#include <string.h>
#include <unistd.h>
#include<stdio.h>
#define SIZE 101
#define STYLE '='
void FlushProcess(double total, double curr) // 更新进度, 按照下载进度,进行更新进度条
{
if(curr > total)
curr = total;
double rate = curr / total * 100; // 1024.0 , 512.0 -> 0.5 -> 50.0
int cnt = (int)rate; // 50.8 , 49.9 -> 50, 49
char processbuff[SIZE];
memset(processbuff, '\0', sizeof(processbuff));
int i=0;
for(; i < cnt; i++)
processbuff[i] = STYLE;
static const char *lable = "|/-\\";
static int index = 0;//全局变量,使这个index不会每次都从0开始刷新。使得用户每次看到的很平滑
printf("[%-100s][%.1lf%%][%c]\r", processbuff, rate, lable[index++]);//回车符,将光标移回行首 ,这样下一次打印会覆盖当前行,实现动态更新。并且不可以使用\n,因为确保在同一行,由于不能使用换行符,所以说得在下面加一个强制刷新> 缓冲区的,否则,你的printf就只能等程序结束了才能打印出来
index %= strlen(lable);
fflush(stdout);
if(curr >= total)
{
printf("\n");
}
}
void process()
{
const char *lable = "|/-\\";
int len = strlen(lable);
char processbuff[SIZE];
memset(processbuff, '\0', sizeof(processbuff));
int cnt = 0;
while(cnt <= 100)//等于100的时候也得打印,否则就不打印100这个进度条了
{
printf("[%-100s] [%d%%][%c]\r", processbuff, cnt, lable[cnt%len]);
fflush(stdout);
processbuff[cnt++] = STYLE;
usleep(30000);
}
printf("\n");
}main.c:
cpp
#include "process.h"
#include <unistd.h>//因为有usleep函数
#include <time.h>
#include <stdlib.h>
double gtotal = 1024.0;
double speed = 1.0;
// 函数指针类型(Flushprocess)
typedef void (*callback_t)(double, double);
//
// // 1.0 4.3
double SpeedFloat(double start, double range) // [1.0 3.0] -> [1.0, 4.0]
{
int int_range = (int)range;
return start + rand()%int_range + (range - int_range);//返回的是一个区间内的随机值
//人眼之所以看的好像进度条并没有很大的跳转,是因为你的随机数的范围就很小,就是1.0到20.3这个范围内,对于100MB的文件
//可能看着有较大的出入,但是对于特别大的文件,你看着就是很顺滑的进度条。
}
void DownLoad(int total, callback_t cb)
{
srand(time(NULL));//这个是为了方便SpeedFloat函数里面的随机数的使用
double curr = 0.0;
while(1)
{
if(curr > total)
{
curr = total; // 模拟下载完成
cb(total, curr); // 更新进度, 按照下载进度,进行更新进度条
//cb其实指向的就是Flushprocess,其实就是Flushprocess(total,curr)
break;
}
cb(total, curr); // 更新进度, 按照下载进度,进行更新进度条
curr += SpeedFloat(speed, 20.3); // 模拟下载行为,模仿进度条的随机跳转
usleep(30000);//模仿网络卡顿
}
}
int main()
{
printf("download: 20.0MB\n");
DownLoad(20.0, FlushProcess);
printf("download: 2000.0MB\n");
DownLoad(2000.0, FlushProcess);
printf("download: 100.0MB\n");
DownLoad(100.0, FlushProcess);
printf("download: 200.0MB\n");
return 0;
} Makefile:
cpp
BIN=process
CC=gcc
SRC=$(wildcard *.c)
OBJ=$(SRC:.c=.o)
$(BIN):$(OBJ)
$(CC) -o $@ $^
%.o:%.c
$(CC) -c $<
.PHONY:clean
clean:
rm -f $(BIN) $(OBJ)好了,今天的文章到此为止.......