⭐ 深度学习入门体系(第 2 篇): 为什么神经网络一定需要激活函数?
------用生活例子讲懂"非线性的意义"
这是整个深度学习体系里最容易被忽略、但也最关键的概念之一。
如果你真正理解了"为什么激活函数是必须的",你对神经网络的理解水平会立即提升一个层级。
文章目录
- [⭐ 深度学习入门体系(第 2 篇): 为什么神经网络一定需要激活函数?](#⭐ 深度学习入门体系(第 2 篇): 为什么神经网络一定需要激活函数?)
- [🧠 一、先说结论(人话版本)](#🧠 一、先说结论(人话版本))
- [🥱 二、没有激活函数的网络能力有多弱?(生活类比)](#🥱 二、没有激活函数的网络能力有多弱?(生活类比))
- [📈 三、那有激活函数会怎样?(仍然类比开车)](#📈 三、那有激活函数会怎样?(仍然类比开车))
- [🔍 四、从数学角度看:激活函数带来"非线性"](#🔍 四、从数学角度看:激活函数带来“非线性”)
- [🍜 五、再用一个特别接地气的生活类比](#🍜 五、再用一个特别接地气的生活类比)
- [⚡ 六、激活函数到底提供了什么能力?](#⚡ 六、激活函数到底提供了什么能力?)
- [🛠 七、常见激活函数怎么选?(工程角度的人话总结)](#🛠 七、常见激活函数怎么选?(工程角度的人话总结))
-
-
- [1. ReLU(深度学习默认选择)](#1. ReLU(深度学习默认选择))
- [2. Sigmoid(经典但现在少用)](#2. Sigmoid(经典但现在少用))
- [3. Tanh(对称,但仍会饱和)](#3. Tanh(对称,但仍会饱和))
- [4. GELU(Transformer 的好伙伴)](#4. GELU(Transformer 的好伙伴))
-
- [🧠 八、为什么非要每层都放激活函数?](#🧠 八、为什么非要每层都放激活函数?)
- [🏁 九、小结:激活函数的本质意义就两个字](#🏁 九、小结:激活函数的本质意义就两个字)
- [🔜 下一篇](#🔜 下一篇)
🧠 一、先说结论(人话版本)
如果没有激活函数,神经网络会变成:
一个再深也没用的线性模型。
不管你堆 10 层、100 层、1000 层网络,只要没有激活函数,它就会等价于:
输出 =(一堆矩阵乘一堆矩阵)× 输入也就是:
整个网络就只剩一层线性变换。
完全无法解决任何复杂问题。
🥱 二、没有激活函数的网络能力有多弱?(生活类比)
我们用一个特别贴近生活的类比,保证你听完永远忘不了。
类比:没有激活函数的神经网络就像"永远直着走的车"
想象你有一辆车,它只能执行:
- 向前开(乘法)
- 向后开(减法)
- 调整速度(加权)
但它没有方向盘。
你再会开车也没用,你永远只能沿着一条直线走。
这就是没有激活函数的神经网络:
- 会加
- 会减
- 会乘
- 运算很快
- 但永远只能拟合直线关系
你让它识别猫狗?识别图像?理解语音?
对不起,它只会"直线思考"。
📈 三、那有激活函数会怎样?(仍然类比开车)
激活函数(ReLU、Sigmoid、Tanh......)的加入,就相当于:
你终于有了方向盘,可以左转右转了。
于是:
- 你能绕弯
- 能掉头
- 能适应复杂道路
- 能走不同路线解决不同需求
模型的能力从"一条死直线",变成了"可以构建任意复杂的曲线"。
这就是激活函数的意义。
🔍 四、从数学角度看:激活函数带来"非线性"
线性变换本质上就是:
y = Ax + b你堆多少层,还是这个形式:
y = A₃(A₂(A₁x + b₁) + b₂) + b₃数学上,这就是:
y = A_total x + b_total还是线性的。
加个激活函数会怎样?
像这样:
y = A₂(ReLU(A₁x + b₁)) + b₂ReLU 不是线性函数,所以:
整个网络终于变成"非线性函数"。
可以拟合任何复杂模式(根据通用逼近定理)。
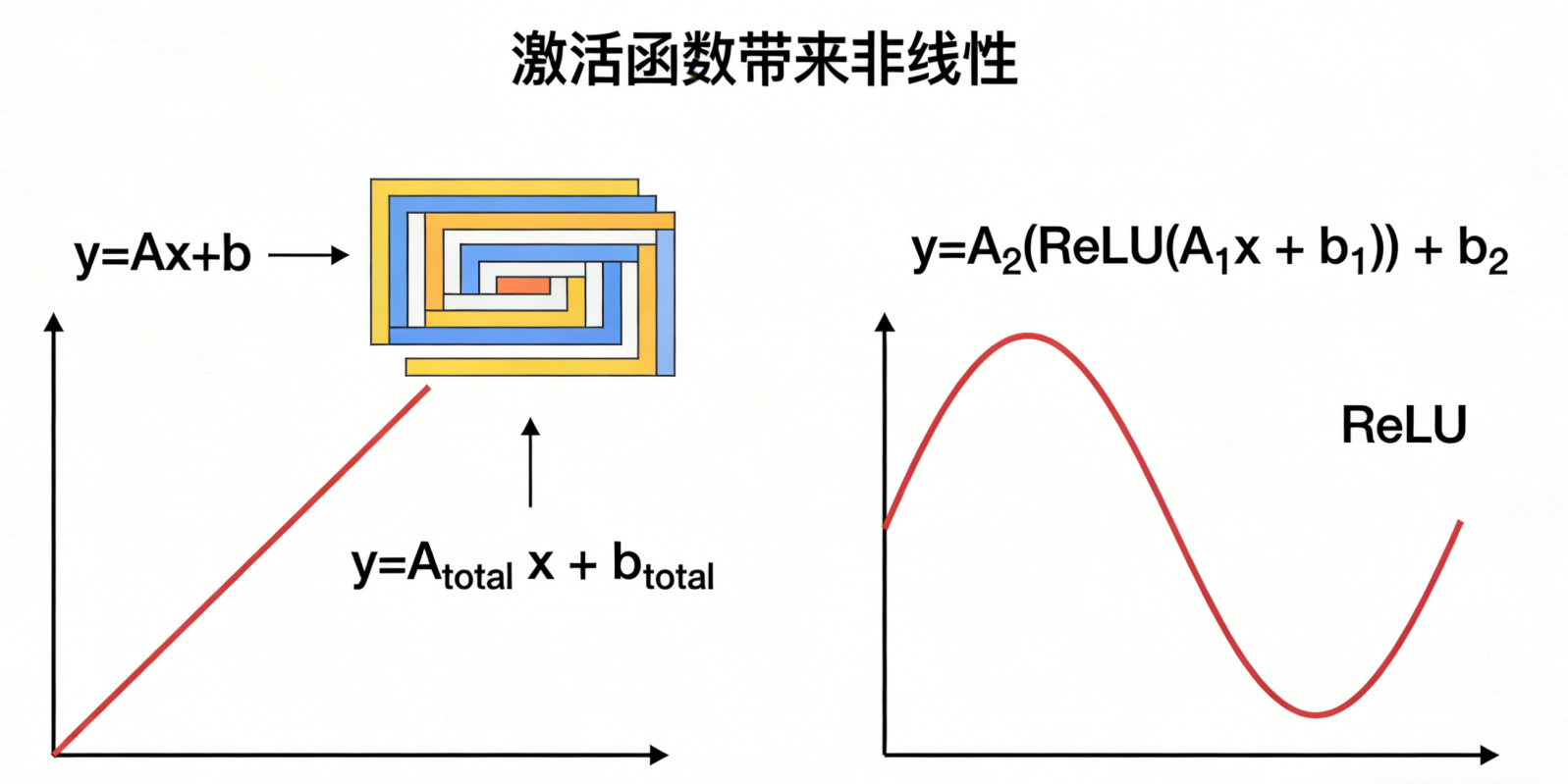
这就是神经网络能做图像识别、语音识别、翻译的根本原因。
🍜 五、再用一个特别接地气的生活类比
假设你开餐厅,你的菜价只取决于:
- 原料成本(线性)
- 人工成本(线性)
那么你的菜价永远是:
菜价 = a × 成本 + b × 人工但是现实中并不是这样:
- 菜品风格会影响价格(非线性)
- 店铺选址影响价格(非线性)
- 评价高可以翻倍(非线性)
- 对某些明星菜你可以溢价(非线性)
也就是说:
现实世界绝大多数现象本质上是非线性的。
如果神经网络无法表达非线性,它基本就废了。
⚡ 六、激活函数到底提供了什么能力?
专业一点总结:
| 能力 | 来自激活函数 | 意义 |
|---|---|---|
| 非线性能力 | ReLU / Sigmoid / Tanh | 能拟合复杂任务 |
| 层的表达能力 | 出现"功能不同"的层 | 多层网络才真正变得有意义 |
| 梯度传播的多样性 | 梯度不再是单一线性 | 网络能稳定学习复杂模式 |
| 揭示特征层级 | 从"边缘"→"纹理"→"物体" | 深度学习最强的部分 |
要点很简单:
没有激活函数,深度学习无法深,也无法学。
🛠 七、常见激活函数怎么选?(工程角度的人话总结)
下面给你一个工程上非常实用的选择指南:
1. ReLU(深度学习默认选择)
特点:
- 简单
- 稳定
- 计算快
- 大部分任务表现最好
适用于:
- CNN
- MLP
- Transformer
使用最多的激活函数,没有之一。
2. Sigmoid(经典但现在少用)
特点:
- 会饱和,梯度趋近 0(训练慢)
- 但适合表示"概率"
适用于:
- 二分类输出层
- 部分概率建模场景
3. Tanh(对称,但仍会饱和)
比 Sigmoid 好,但也有梯度消失问题。
常见但不是主流。
4. GELU(Transformer 的好伙伴)
优点:
- 输出更平滑
- 性能略好于 ReLU
- GPT/BERT 都用它
适用于:
- NLP
- 大模型
🧠 八、为什么非要每层都放激活函数?
有人可能会问:
"我是不是只要最后一层有激活就行?"
答案是:不行。
如果中间层没有激活函数:
- 所有层依然线性组合
- 再深的网络也等于一层
- 整个网络没有层级结构
你训练的时候会发现:
- 准确率根本上不去
- 特征图全是线性变化
- 模型基本"什么也没学到"
所以:
只要你想让网络有"深度",
激活函数必须在每个隐藏层出现。
🏁 九、小结:激活函数的本质意义就两个字
非线性。
这两个字让:
- 多层网络真正变成"深度"
- 神经网络可以模拟复杂函数
- 视觉、语音、NLP 等任务成为可能
- 网络具备表达不同特征的能力
如果把深度学习比作一栋大楼:
- 权重是钢筋
- 网络层是楼层
- 损失函数是建筑图纸
- 反向传播是施工队
- 激活函数是结构设计中让楼能"弯折、承重、抗压"的关键节点
没有激活函数,这栋楼根本无法建成。
🔜 下一篇
《深度学习入门体系(第 3 篇):反向传播到底是怎么工作的?------用"找丢失的钱包"讲懂梯度下降》