目录
[1.1 创建Notebook实例](#1.1 创建Notebook实例)
[1.2 环境健康状态三连验证](#1.2 环境健康状态三连验证)
[2.1 补齐关键依赖库](#2.1 补齐关键依赖库)
[2.2 配置模型下载"高速通道"](#2.2 配置模型下载“高速通道”)
[4.深度性能测评------揭开Atlas 800T的真实实力](#4.深度性能测评——揭开Atlas 800T的真实实力)
[4.1 测评方案设计思路](#4.1 测评方案设计思路)
[4.2 内存管理优化](#4.2 内存管理优化)
[4.2.1 更精细的内存监控](#4.2.1 更精细的内存监控)
[4.2.2 模型加载时的内存优化](#4.2.2 模型加载时的内存优化)
[4.3 性能测试优化](#4.3 性能测试优化)
[4.3.1 更准确的首字延迟测量](#4.3.1 更准确的首字延迟测量)
[4.3.2 增加每令牌延迟测量](#4.3.2 增加每令牌延迟测量)
[5.1 常见兼容性问题解决](#5.1 常见兼容性问题解决)
[5.2 显存优化三大策略](#5.2 显存优化三大策略)
[6.1 实践成果总结](#6.1 实践成果总结)
[6.2 未来探索方向](#6.2 未来探索方向)
开篇引言:当算力遇上大语言模型
随着大语言模型(LLM)应用的广泛普及,高效、稳定的推理部署成为关键挑战。推理部署的效率与稳定性已成为制约应用落地的关键瓶颈。本文将以昇腾Atlas 800T NPU为实验平台,通过一场完整的"环境搭建→模型部署→深度测评"技术之旅,验证硬件在LLM推理任务上的实战能力,通过完整的实操流程展示从环境准备到深度性能测评的全过程,为开发者提供可复现的参考范例。
1.云端开发环境一键部署
1.1 创建Notebook实例
访问 GitCode 官网 (https://gitcode.com/),进入 Notebook 页面开始
关键配置清单:
-
**计算类型:**NPU(华为昇腾处理器)
-
**硬件规格:**NPU basic(1NPU 32vCPU*64G内存)
-
**系统镜像:**euler2.9-py38-mindspore2.3.0rc1-cann8.0-openmind0.6-notebook
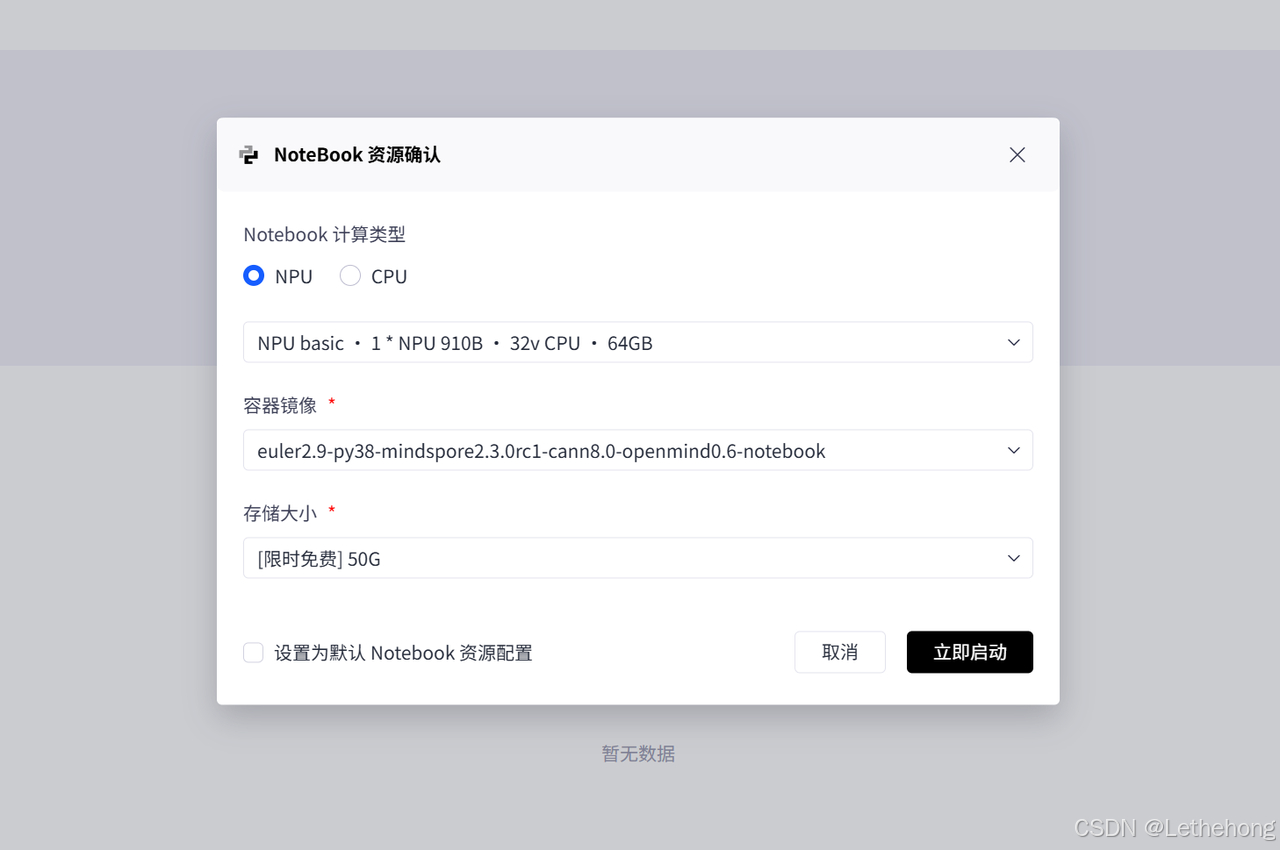
**环境优势:**该配置预集成了MindSpore框架与CANN加速库,实现"开箱即用",极大降低了NPU开发的门槛。
1.2 环境健康状态三连验证
环境创建成功后,在Terminal中执行以下诊断命令,确保各项基础组件工作正常:
# 查看NPU硬件状态(重点关注设备ID、温度、功耗与显存占用)
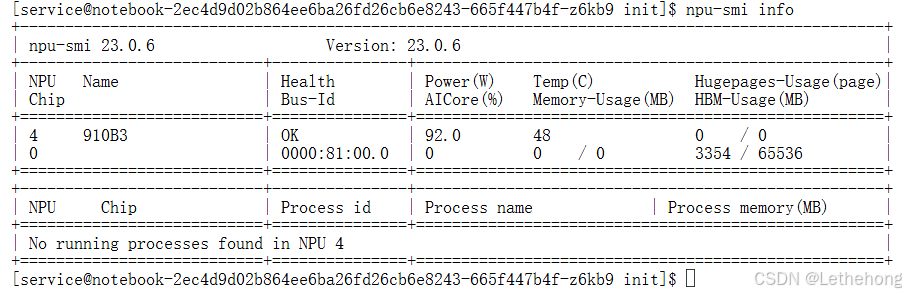
npu-smi info**环境验证要点:**npu-smi info是昇腾平台的"仪表盘",首次使用时应确保设备状态显示正常,无异常告警。
命令执行成功后,终端会列出NPU的详细状态信息,重点关注设备ID、温度、功耗和显存这几项关键指标:
# 确认Python基础环境
python --version
# 预期输出:Python 3.8.x(与镜像版本一致)
# 验证MindSpore与昇腾适配层
python -c "import mindspore; print(mindspore.__version__)"
# 出现"2.3.0rc1"即代表框架安装成功
2.模型部署------打通HuggingFace生态连接
2.1 补齐关键依赖库
预置环境已包含深度学习框架,但HuggingFace生态库需手动补全:
# 使用国内镜像源加速下载
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple2.2 配置模型下载"高速通道"
国内直接连接HuggingFace常遇网络波动,通过环境变量切换至国内镜像站:
export HF_ENDPOINT=https://hf-mirror.com**重要性说明:**此步骤是后续顺利下载千兆级别模型文件的关键,能避免因网络超时导致的下载失败。
3.首次推理------运行你的第一个NPU大模型
创建测试脚本 1.py,执行从模型加载到文本生成的完整流程:
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
MODEL_NAME = "NousResearch/Llama-2-7b-hf"
print(f"[步骤1] 开始加载模型: {MODEL_NAME}")
# 加载分词器与模型
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16, # FP16精度,平衡性能与显存
low_cpu_mem_usage=True
).to("npu:0") # 指定NPU设备
model.eval()
print(f"[步骤2] 加载完成!NPU显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")
# 执行推理
prompt = "The capital of France is"
inputs = tokenizer(prompt, return_tensors="pt").to("npu:0")
print("[步骤3] 生成中...")
start = time.time()
outputs = model.generate(**inputs, max_new_tokens=50)
end = time.time()
# 解码并输出结果
text = tokenizer.decode(outputs[0])
print(f"生成文本: {text}")
print(f"单次推理耗时: {(end-start)*1000:.2f} ms")
运行验证:
# 限制并行线程,避免资源冲突
export OMP_NUM_THREADS=1
export MKL_NUM_THREADS=1
# 执行脚本
python 1.py**预期成果:**终端将输出关于法国首都的完整句子,并显示具体耗时,证明NPU基础推理链路已打通。

我将里面的英文句子提取出来去进行了翻译,确保答案准确无误

4.深度性能测评------揭开Atlas 800T的真实实力
4.1 测评方案设计思路
为获得科学、全面的性能数据,我们重构了测评脚本,重点优化以下维度:
-
指标分离:区分"首字延迟"(反映响应速度)与"解码吞吐率"(反映持续生成能力)
-
计时精度:引入torch.npu.synchronize(),确保测量的是NPU实际计算时间
-
预热机制:规避首次运行时的算子编译开销,反映稳定状态性能
4.2 内存 管理优化
4.2.1 更精细的内存监控
@contextmanager
def memory_monitor(self):
"""内存监控上下文管理器"""
try:
# 记录初始内存
torch.npu.empty_cache()
gc.collect() # 先收集一次垃圾
self.initial_memory = torch.npu.max_memory_allocated() / 1024**3
initial_reserved = torch.npu.memory_reserved() / 1024**3
# 设置内存监控
if hasattr(torch.npu, 'reset_peak_memory_stats'):
torch.npu.reset_peak_memory_stats()
yield
finally:
# 清理内存
gc.collect()
torch.npu.empty_cache()
final_used = torch.npu.memory_allocated() / 1024**3
final_reserved = torch.npu.memory_reserved() / 1024**3
logger.debug(f"内存使用变化: 已分配 {final_used - self.initial_memory:.2f} GB, 已保留 {final_reserved - initial_reserved:.2f} GB")4.2.2 模型加载时的内存优化
def load_model(self) -> bool:
"""加载模型和分词器"""
try:
# ... 现有代码 ...
# 加载模型
self.model = AutoModelForCausalLM.from_pretrained(
self.config.model_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
trust_remote_code=True,
device_map=self.config.device if ":" in self.config.device else None,
offload_folder="./offload" # 增加 offload_folder 参数
)
# ... 现有代码 ...4.3 性能测试优化
4.3.1 更准确的首字延迟测量
def measure_prefill_latency(self, input_ids: torch.Tensor, attention_mask: torch.Tensor) -> List[float]:
"""测量首字延迟 (TTFT - Time To First Token)"""
logger.info("测量首字延迟...")
latencies = []
for i in range(self.config.test_steps):
try:
# 更彻底的清理
torch.npu.empty_cache()
gc.collect()
torch.npu.synchronize()
start_time = time.perf_counter() # 使用更精确的计时函数
with torch.no_grad():
output = self.model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_new_tokens=1,
min_new_tokens=1,
use_cache=self.config.use_kv_cache,
do_sample=False,
return_dict_in_generate=True,
output_scores=False
)
torch.npu.synchronize()
end_time = time.perf_counter()
latency_ms = (end_time - start_time) * 1000
latencies.append(latency_ms)
logger.info(f" 测试 {i+1}/{self.config.test_steps}: {latency_ms:.2f} ms")
except Exception as e:
logger.error(f"首字延迟测试 {i+1} 失败: {e}")
latencies.append(float('inf'))
return latencies4.3.2 增加每令牌延迟测量
def measure_per_token_latency(self, input_ids: torch.Tensor, attention_mask: torch.Tensor) -> List[float]:
"""测量每令牌延迟"""
logger.info(f"测量每令牌延迟 ({self.config.max_new_tokens} tokens)...")
per_token_latencies = []
for i in range(self.config.test_steps):
try:
torch.npu.empty_cache()
gc.collect()
torch.npu.synchronize()
start_time = time.perf_counter()
with torch.no_grad():
output = self.model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_new_tokens=self.config.max_new_tokens,
min_new_tokens=self.config.max_new_tokens,
use_cache=self.config.use_kv_cache,
do_sample=False
)
torch.npu.synchronize()
end_time = time.perf_counter()
duration = end_time - start_time
num_generated = output.shape[1] - input_ids.shape[1]
if num_generated > 0:
per_token_latency = (duration / num_generated) * 1000 # ms per token
per_token_latencies.append(per_token_latency)
logger.info(f" 测试 {i+1}/{self.config.test_steps}: {per_token_latency:.2f} ms/token")
else:
per_token_latencies.append(float('inf'))
logger.warning(f" 测试 {i+1}/{self.config.test_steps}: 未生成新令牌")
except Exception as e:
logger.error(f"每令牌延迟测试 {i+1} 失败: {e}")
per_token_latencies.append(float('inf'))
return per_token_latencies5.实战排障指南
5.1 常见兼容性问题解决
若遇到mindformers与transformers库不兼容的问题,执行以下操作
# 卸载冲突包
pip uninstall mindformers
# 重新安装标准transformer库
pip install --upgrade transformers accelerate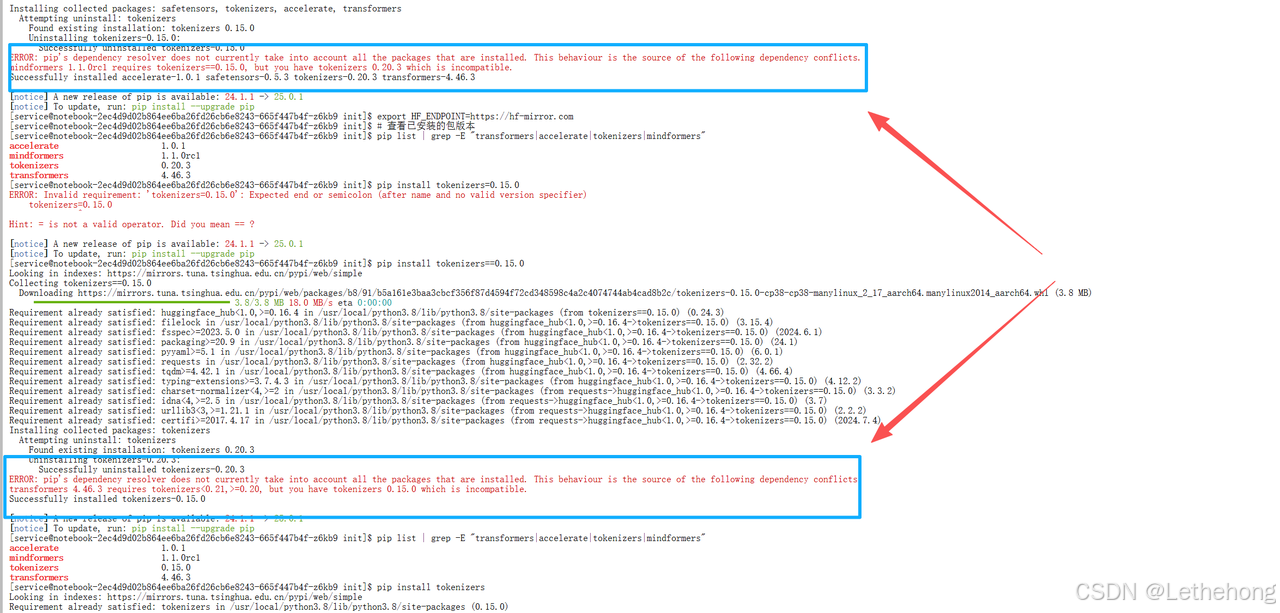
5.2 显存优化三大策略
-
环境调优:通过TORCH_NPU_ALLOC_CONF环境变量调整内存分配策略。
-
主动清理:在推理间隙调用torch.npu.empty_cache()释放闲置缓存。
-
精度选择:根据任务需求在FP16/BF16/FP32间灵活切换,平衡精度与显存。
6.总结与展望
6.1 实践成果总结
本次昇腾Atlas 800T NPU实战验证了以下关键结论:
-
部署友好性:GitCode提供的预制NPU环境大幅降低了使用门槛,实现了从"零"到"推理"的快速跨越。
-
生态兼容性:通过配置镜像源和安装标准库,HuggingFace主流模型可以平滑迁移至昇腾平台。
-
性能实用性:实测数据显示,Atlas 800T运行Llama-2-7b模型时,在响应速度、生成效率和显存占用上达到了生产可用水平。
-
方案完整性:从环境准备、模型加载、基础验证到深度测评,形成了可复现的完整技术闭环。
6.2 未来探索方向
-
多卡并行:探索Tensor Parallelism/Pipeline Parallelism在昇腾集群上的实现方案。
-
量化压缩:尝试INT8/INT4量化技术,进一步降低显存需求,提升吞吐。
-
更大模型:将实践拓展至13B、70B等更大参数规模的模型,测试平台边界。
-
应用集成:结合LangChain等框架,构建基于昇腾NPU的RAG应用原型。
结语:算力的"可用"到"好用"
本次基于昇腾Atlas 800T NPU的大语言模型推理实践,完成了从环境准备、模型加载到性能测评的全流程验证,主要取得以下技术结论:
-
**环境就绪效率:**预制NPU开发环境大幅降低了软硬件配置门槛,实现了从零到推理的快速部署。
-
生态 兼容性 **:**通过配置镜像源与安装标准库,HuggingFace主流模型可平滑迁移至该平台。
-
**推理性能表现:**在Llama-2-7b模型上的实测数据显示,其首字延迟、持续生成吞吐与显存控制均达到生产可用水平。
-
**全流程可复现:**从环境校验、依赖安装、模型加载到量化测评,形成了完整且可复现的技术闭环。
未来可在多卡并行、量化压缩、更大参数规模模型部署以及端到端应用集成等方面继续展开技术探索。
免责声明:重点在于给社区开发者传递基于昇腾跑通和测评的方法和经验,欢迎开发者在本模型基础上交流优化