(1)Java集合架构
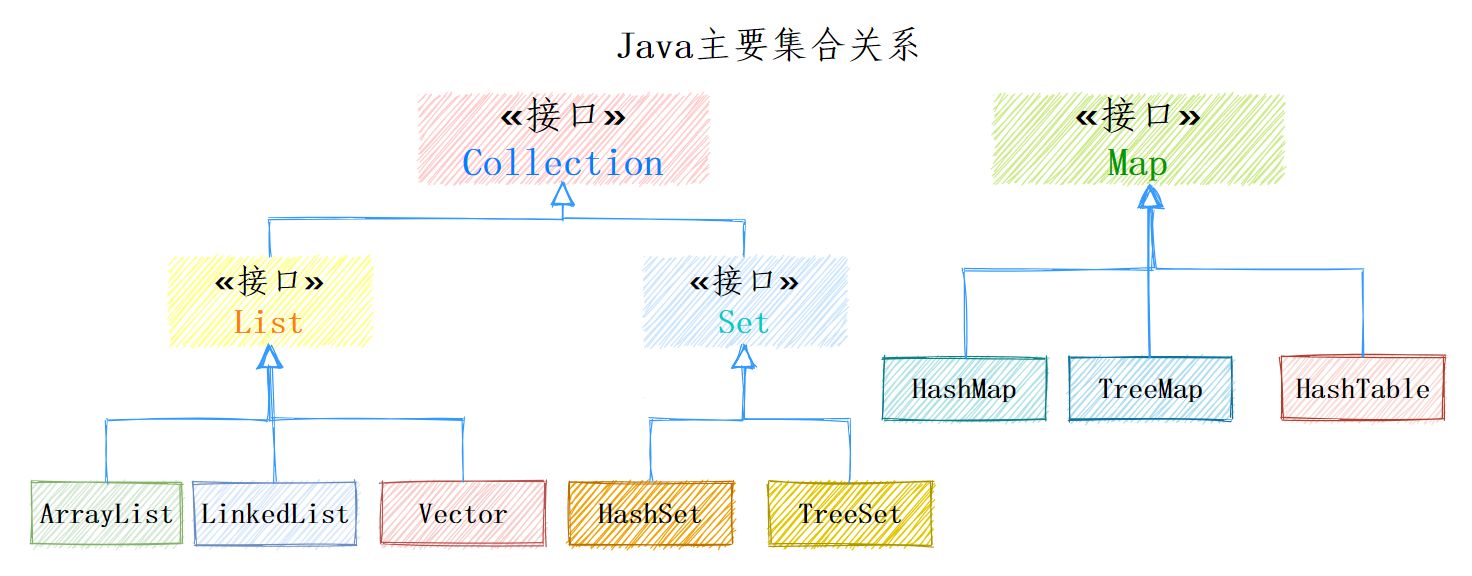
参看博客:单列集合Collection中的常用方法
(2) ArrayList 和 Vector 的区别
(1)线程安全:ArrayList 是线程不安全的,Vector 是线程安全的,线程安全的实现是通过 Synchronized 实现,效率低,不推荐使用;
(2)扩容长度:ArrayList 每次扩容50%,Vector 每次扩容一倍;
(3)ArrayList 和 LinkedList 有什么区别?
(1)底层实现:ArrayList 是长度可变的数组,LinkedList 是双向链表;
(2)随机访问:ArrayList 实现了 RandomAccess 接口,支持随机访问,LinkedList 不支持;
(3)内存占用:ArrayList 占用一块连续的内存空间,LinkedList 内存空间不连续;
(4)元素存储:ArrayList 是预先定义好的数组,会有未使用的空间,有空间浪费;LinkedList 每个节点需要存指针,会占用更多的空间;
(5)使用场景:多数情况,ArrayList 适用于频繁查询元素的场景,LinkedList 适用于频繁增加/删除元素的场景;
另外,LinkedList 实现了 Deque 接口,可作为队列结构使用。这是 ArrayList 不具备的。
(4)ArrayList 的扩容机制了解吗?
(1)使用ArrayList的add()添加元素时,方法内会传三个参数,分别是当前添加的元素,底层创建的数组elementData和size,
(注:size不是elementData的实际长度,而是数组存储的最后一位元素的下标,也就是存入元素的个数)
(2)方法内,会先判断size是否等于elementData.length,是则表示数组已存满,则调用扩容方法 grow(),否则直接存入元素,size+1,
(3) 扩容方法grow()中会调用grow重载方法,参数是size+1,size+1即为目前所需要的最小容量,
(4)在 grow() 的重载方法内进行扩容,实际上是对原数组的拷贝(Arrays.copyOf),新数组的长度会调用 newCapacity() 方法,
(5)newCapacity() 方法决定了新数组的长度,方法内,对原数组长度 * 1.5,与所需的最小容量比较,够用则按照这个来扩容,不够用,则返回所需的最小容量,就是以实际所需容量为准。
另外,值得注意两点,
(1)源码中,扩容后的长度返回前有个判断,判断该值是否大于 Integer 最大值 - 8,大于则返回 Integer 最大值,就是说 ArrayList 能存储的元素最多就是 Integer 的最大值。
(2)elementData 用 transient 修饰,表示不能被序列化,好处是:更安全,序列化效率高,序列化后的文件更小。
参看博客:ArrayList源码分析
(5)如何保证 ArrayList 线程安全?
有以下五种方法,
(1)用 collections.SynchronizedList(arrayList);
(2)用 CopyOnWriteArrayList();
(3)自定义类,类里建一个 ArrayList 对象,然后创建 ArrayList 对应的方法,方法内调用 ArrayList 对象的方法,在方法上或代码块加锁来保证线程安全;
(4)自定义类,继承 ArrayList 类,重写对应的方法并加锁;
(5)使用 Vector,也是通过给方法上加锁来实现的;
(6)能说一下 HashMap 的数据结构吗?
数组+链表(JDK1.8 以前),数组+链表+红黑树(JDK1.8 以后)
当该位置的链表长度大于 8,并且数组长度大于 64 时,该位置的所有元素会由链表转为红黑树结构;
(7)你对红黑树了解多少?为什么不用二叉树 / 平衡树?
二叉树在极端情况下会蜕变成线性结构,这种情况下,HashMap 结构等于没有变化,也没有优化,
平衡树是严格平衡树,要求树高度差不能大于 1,在增加或删除节点时,根据不同的情况,旋转的次数比红黑树多,
而红黑树引入了节点颜色等一系列规则,在规则内,添加或删除节点,最多只需要旋转 2 次,相较于平衡树,效率高,开销小。
但平衡树因为高度平衡,查询效率更高。
(8)HashMap 的 put() 流程
(1)HashMap 的 put() 方法,会调用 putVal() 方法,该方法有三个参数,key 的 hash 值,key,value,
(注:key 的 hash 值,是调用了 hash() 方法,方法内对 key 哈希码,与 key 哈希码无符号右移 16 位后的值做了异或运算)
(2)putVal() 方法内,首先判断 table 是否为空或者长度是否为 0,是则先调用 resize() 方法,table 是 HashMap 底层创建的 Node 数组,长度始终为 2 整数幂,
(3)根据 key 的 hash 值与 table 的长度计算出元素要插入的下标,
(4)判断 table 中该下标位置是否有元素,没有元素则直接插入元素,
(5)如果该位置已经有元素,则判断 key 是否相等,相等则直接覆盖,
(6)如果 key 不存在,且该位置为红黑树结构,则调用红黑树的插入方法,插入元素,
(7)否则,则该位置为链表结构,遍历链表插入元素,同时判断链表长度是否大于 8 &&数组长度大于 64,符合条件则转为红黑树结构,
(8)最后判断数组长度是否达到扩容条件,达到则进行扩容。
(9)为什么 HashMap 的容量始终为 2 整数幂?
因为在计算元素插入的下标时,使用的方式是 table 长度 - 1 与 hash 值进行与运算(&),
这种方法在 table 长度为 2 的整数幂的情况时,等同于 hash 值 % table 长度,这种方式对于计算机更高效。
也就是人为创造了这样的条件,用空间资源换时间资源,提高效率。
如果初始化 HashMap,new HashMap<>容量设置为17,会怎么处理?
HashMap 底层的数组会扩容到 32 (就是最接近 2 的整数幂的一个数)
(10)为什么 HashMap 链表转红黑树的阈值为 8 呢?
当阈值为 8 时,发生碰撞概率为 0.00000006,是一个非常低的概率。
链表转为红黑树,是一个比较消耗资源的操作,设置为 8 就足够了。
Less than 1 in ten million.(概率小于千万分之一)
(11)扩容在什么时候开始?为什么扩容因子是 0.75?
当 HashMap 中的元素数量大于总容量的 0.75 倍是开始扩容。
0.75 这是一个经验值, 是平衡空间成本和时间成本得出的。
-
设置过大,数组空余的位置少,发生哈希碰撞的概率高;
-
设置过小,数组空余还很多就触发扩容,原来的元素需要rehash;
(12)扩容机制了解吗?
当底层数组 table 中的元素数量大于长度的 0.75 倍时,会扩容到 2 倍长度,
原来元素的位置要么不变,要么为当前位置 + 加上扩容的长度。
(13)jdk1.8 对 HashMap 主要做了哪些优化呢?为什么?
(1)结构上:由数组+链表转为了数组+链表+红黑树,引入了红黑树,提高查询效率;
(2)插入方式:由头插法转为了尾插法,减少了死锁的概率;
(3)扩容方式:由先扩容再插入元素,转为了先插入元素再扩容,减少了冗余判断;
(14)HashMap 和 HashTable 的区别?
(1)线程安全:HashTable 线程安全的,是通过在方法上加 synchronized 实现的,HashMap 线程不安全;
(2)元素要求:HashTable 不允许元素的键、值为 null,HashMap 允许键为 null,但只允许有 1 个,允许多个不同键的值为 null;
(3)扩容长度:HashTable 长度不要求为 2 的整数幂,HashMap 长度必须是 2 的整数幂;
现在不建议使用 HashTable,保证线程安全,可以考虑使用 ConcurrentMap。
(15)分段锁
分段锁,在 JDK1.7 的 ConcurrentMap 中采用,对整个桶数组进行了分割分段(Segment),
每把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,不会存在锁竞争,提高了并发访问效率。
(默认分配 16 个 Segment,比 HashTable 效率最多高16倍)
到 JDK8 时,废弃了 Segment 的设计,直接用了 Node 数组 + 链表 + 红黑树的数据结构实现,
并发控制使用了synchronized 和 CAS 操作,整体看下来就像是优化过且线程安全的 HashMap。