仅用30%的参数规模,就能在陌生环境中实现72.5%的导航成功率,这个新框架正在重新定义视觉-语言导航的智能边界。
近日,深圳大学李坚强教授团队与深圳北理莫斯科大学等机构合作,提出了一个名为UNeMo的全新视觉-语言导航框架。该框架通过创新的多模态世界模型与分层预测反馈机制,首次让导航智能体不仅能看到当前环境,还能"预判"接下来可能看到的内容,从而做出更加智能的决策。

论文标题:UNeMo: Collaborative Visual-Language Reasoning and Navigation via a Multimodal World Model
这一成果已被人工智能顶会AAAI 2026收录,它有望大幅降低机器人导航的资源消耗,并在长距离、复杂场景中展现出卓越的稳健性。
现有瓶颈:语言推理与视觉导航为何"脱节"?
视觉-语言导航是具身人工智能的核心任务之一。它要求智能体仅凭摄像头看到的图像和一句如"请去卧室拿一本书"的自然语言指令,就能在完全陌生的家庭环境中自主移动到目标位置。
随着大语言模型的爆发,基于LLM的导航方法取得了一定进展,但研究者们很快发现了两个根本性瓶颈:
- 推理模态单一: 现有方法大多只让LLM进行"语言推理",缺乏对视觉环境未来状态的预判能力。这就像一个人蒙着眼听指令走路,只能走一步看一步,无法应对突然出现的障碍或岔路。
- 优化目标冲突: 传统的框架通常将"推理模块"(理解指令、规划路径)和"导航策略"(执行具体动作)分开训练。这导致两者适配性差,无法在动态环境中实现协同优化,形成了难以突破的性能天花板。
简单来说,"思考"和"行动"是割裂的,智能体无法在行动中学习,也无法根据行动结果实时调整思考策略。
UNeMo框架:双模块协同,打造"预判+决策"智能闭环
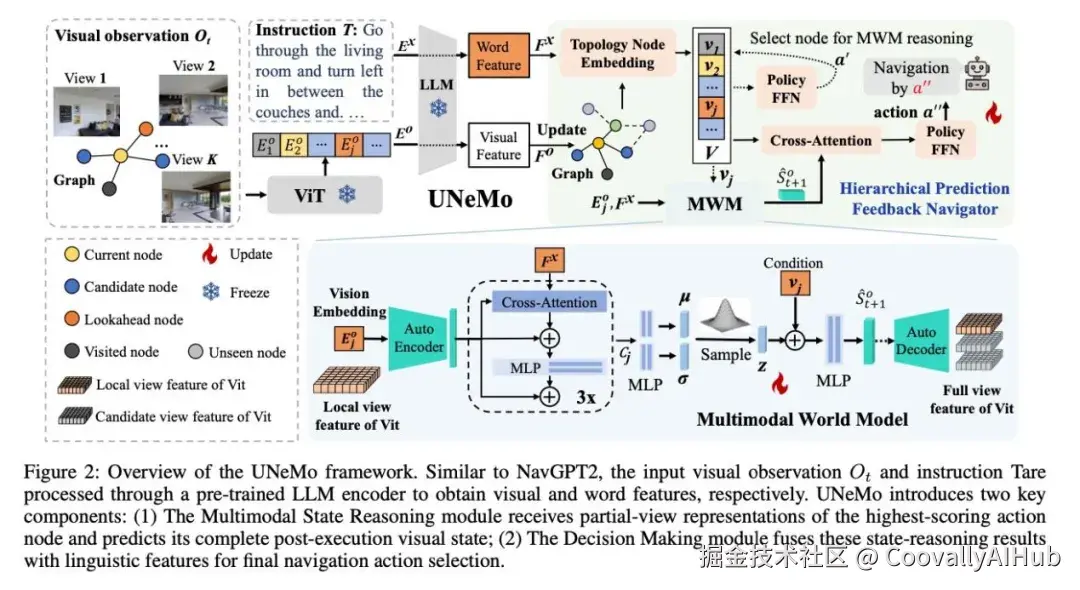
为了破解上述难题,研究团队提出了 UNeMo 框架。其核心突破在于构建了一个"多模态世界模型 + 分层预测反馈导航器" 的双向协同架构,将视觉状态推理与导航决策深度绑定。

- 多模态世界模型:让机器人拥有"想象力"
MWM的核心是一个条件变分自编码器。它的作用是接收当前的视觉画面、语言指令以及候选的下一步动作,通过跨注意力机制融合这些多模态信息,从而预测出执行该动作后可能看到的未来视觉状态。
这相当于为机器人装上了"预见之眼",让它能在行动前就对不同选择的结果进行模拟和评估。
更重要的是,MWM无需任何额外的标注数据。它通过导航决策的实际结果进行反向反馈,持续优化自己的预测精度,形成了一个自适应的进化循环。

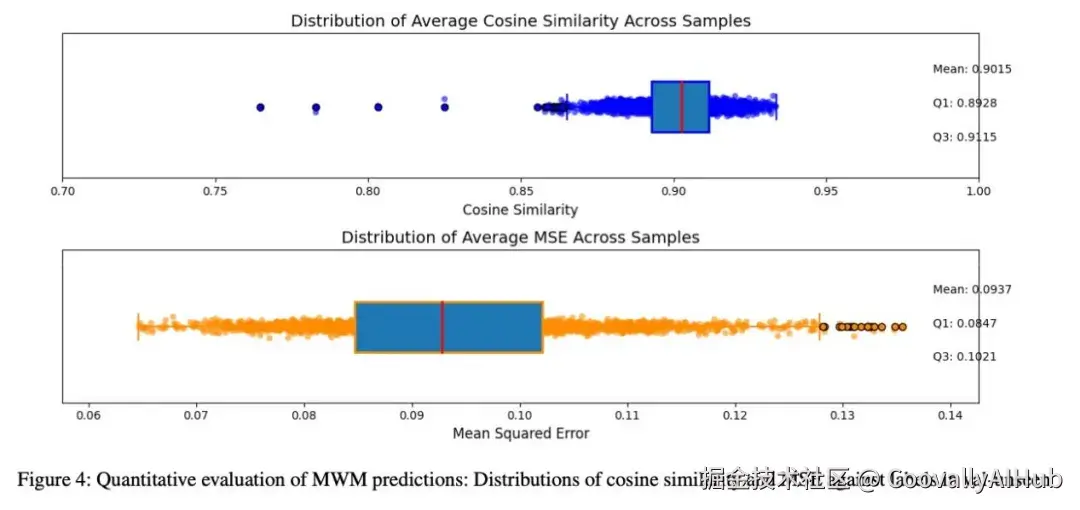
- 分层预测反馈导航器:从"粗选"到"精调"的两步决策
HPFN采用了一个高效的两阶段分层决策机制:
第一阶段(粗粒度规划):基于当前看到的图像和语言指令,快速生成一个初步的候选动作,锁定大致的导航方向。
第二阶段(细粒度修正):融入MWM预测的未来视觉状态,对初步动作进行优化和修正,最终输出精准的导航指令。
这个过程如同人类开车:先看路牌确定大致方向(粗选),再观察前方路面细节进行微调方向盘(精调),从而确保在复杂路况中稳健前行。
核心突破:"推理-决策"动态闭环,相互赋能
UNeMo架构最精妙之处,在于它构建了一个自我强化的动态闭环:
- 正向赋能: MWM的视觉预判为HPFN的导航决策提供了前瞻性信息,显著提升了决策的准确性和鲁棒性。
- 反向反馈: HPFN导航执行的实际结果(成功或失败),会实时反馈给MWM,帮助它修正和优化对未来状态的预测模型。
"思考"指导"行动","行动"的结果又反过来优化"思考"。 这种双向促进的机制,让智能体能在每一次导航任务中持续学习和迭代,从根本上解决了传统方法中推理与决策分离的核心痛点。
实验验证:效率与性能的双重飞跃
为了全面验证UNeMo的价值,团队进行了一系列严谨的实验。
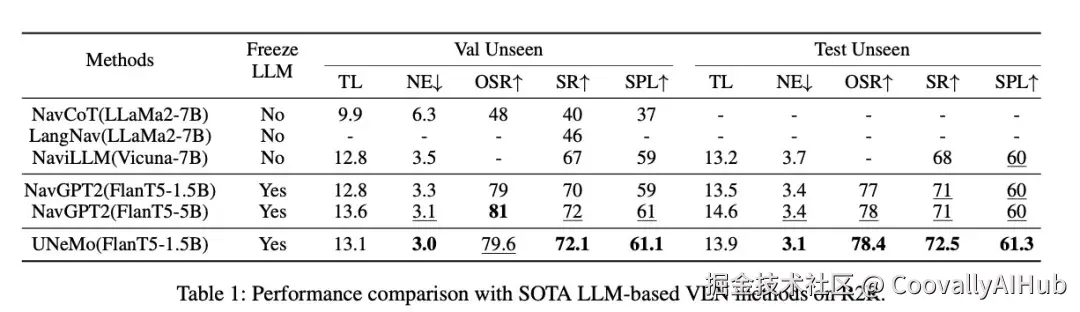
- 核心场景:以30%参数量,实现性能超越
在VLN基准数据集R2R上,UNeMo采用了参数量仅为1.5B的轻量级模型(FlanT5-1.5B),而主流方法NavGPT2则使用了5B参数模型。
结果令人惊喜:UNeMo在资源消耗上大幅降低------训练显存占用从27GB降至12GB(↓56%),推理速度从每步1.1秒提升至0.7秒(↑40%效率)。与此同时,在从未见过的测试环境中,其导航成功率(SR)达到72.5%,反而超越了NavGPT2的71%,真正实现了 "降本增效"。
- 复杂场景:长路径导航优势显著
在长距离导航任务中,UNeMo的优势被进一步放大。在路径长度≥7的复杂任务中,其导航成功率相比基线方法大幅提升5.6%,提升幅度是短路径任务的近5倍。这证明其"预判"机制能有效缓解长距离导航中的误差累积问题。
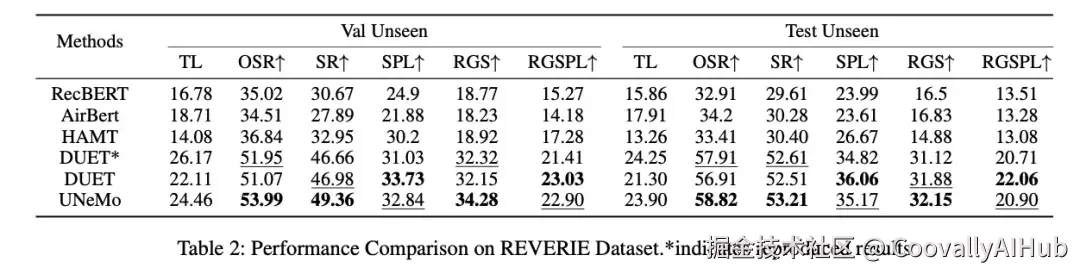
- 通用性强:跨基线、跨数据集均有效
团队还将UNeMo的核心架构迁移到不同的导航模型(如DUET)和不同的任务数据集(如REVERIE)上进行测试。结果显示,其性能均有稳定提升,证明了该协同训练架构具有强大的通用性和可拓展性,并非针对特定模型的"特化优化"。
结论
本文探讨了视觉语言导航(VLN)领域的关键挑战:现有基于大型语言模型的方法受限于视觉推理能力不足,且推理模块与导航策略之间存在优化割裂。我们提出UNeMo框架,通过多模态世界模型(MWM)与分层机制实现视觉状态推理与导航决策的协同优化。MWM通过联合预测视觉特征、语言指令及导航动作的后续视觉状态,促进跨模态推理。MWM与导航策略间的分层交互建立动态双向促进机制:MWM推理提升策略优化效果,策略决策反哺MWM推理精度。在R2R与REVERIE数据集的实验验证表明,UNeMo显著超越现有方法,有效提升视觉导航任务性能。本研究揭示了多模态世界建模与分层决策机制融合的潜力,为开发更稳健、更具适应性的VLN智能体开辟了新路径。依托Matterport3D真实世界数据,UNeMo显著缩小了仿真与现实的视觉差距。后续工作将扩展UNeMo至更复杂场景,并通过实体机器人部署验证其实际导航性能。
UNeMo框架的提出,为视觉-语言导航领域提供了一种高效、通用的新思路。它通过巧妙的协同架构设计,以更低的计算成本,实现了更高的导航性能,尤其在长轨迹、复杂环境中表现突出。
这项研究不仅推动了VLN领域的学术发展,更重要的是为家庭服务机器人、智能仓储AGV等实际应用场景的落地提供了更可行的技术方案。一个能够"预见未来"、并据此做出智能决策的机器人,无疑离我们的生活更近了一步。