1.摘要
扩散模型(Diffusion Models)作为当前最热门的生成模型之一,已彻底改变图像生成领域,本文从DDPM开始,逐步深入到Stable Diffusion和DiT架构。
扩散模型就像是一个"破坏-修复"的过程,想象一下你有一张美丽的图片,然后一点点地给它加上噪声,直到完全看不清原来的图片,然后让AI学会如何一步步把噪声去掉,重新还原出原始图片。这就是扩散模型的基本思路。
2. DDPM:扩散模型的奠基之作(2020年)
2.1 什么是DDPM?
DDPM(Denoising Diffusion Probabilistic Models)是扩散模型的开山鼻祖,由OpenAI团队在2020年提出,它的工作原理:
前向过程(加噪声) :从一张清晰的图片开始,逐步添加噪声,最终变成完全随机的噪声图。 反向过程(去噪声):训练AI学会如何一步步去除噪声,从随机噪声中重建出原始图片。
2.2 DDPM的模型结构详解
DDPM的核心是一个U-Net网络结构,U-Net详细架构如下图:
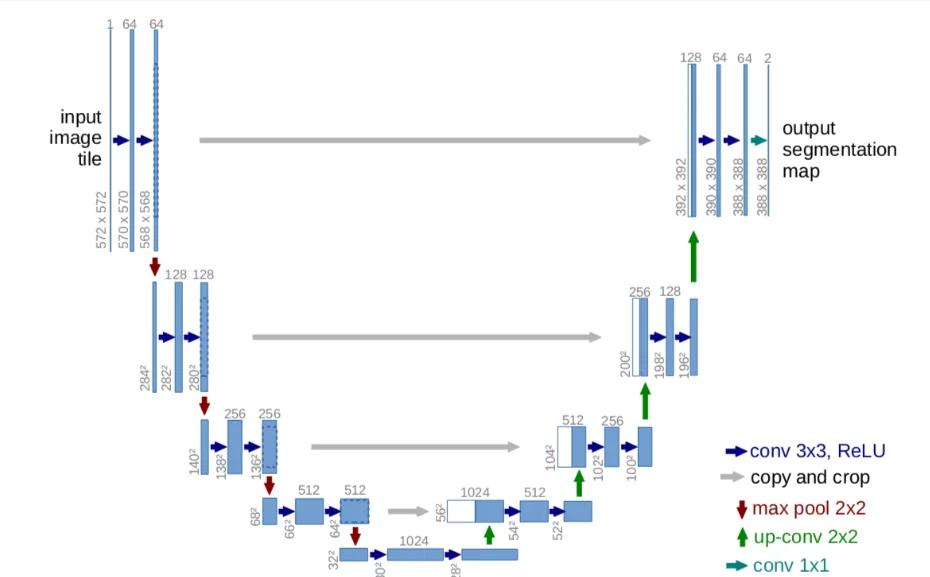
2.3 训练过程
DDPM需要训练很多轮次,每次告诉AI:"这是加了噪声的图片,这是原始图片,请你学会如何从噪声中恢复原图"。经过大量训练后,AI就学会了去噪技能。
2.4 推理过程
推理时,AI从完全随机的噪声开始,一步步"想象"出完整的图片。这个过程通常需要几十到几百步才能完成。
2.5 DDPM的特点
- 优点:生成质量高,理论基础扎实
- 缺点:训练和推理都很慢,通常需要1000步才能生成一张图片
- 应用场景:学术研究,为后续模型提供理论基础
3. Stable Diffusion:实用化的突破(2022年)
3.1 为什么需要Stable Diffusion?
DDPM虽然效果不错,但有个致命缺点:计算成本太高!一张512×512的图片需要在像素级别上进行扩散,计算量巨大。2022年,Stable Diffusion横空出世,解决了这个问题。
3.2 Stable Diffusion的创新
Stable Diffusion最大的创新是潜在空间扩散:
- 传统方法:直接在原始图像空间(如512×512像素)进行扩散
- Stable Diffusion:先将图像压缩到潜在空间(如64×64),在潜在空间进行扩散,最后再解压回原空间
这样计算量减少了约16倍,使得扩散模型变得实用起来。
3.3 文本到图像生成
Stable Diffusion另一个重要特性是支持文本到图像生成:
- 使用CLIP模型将文本转换为语义向量
- 在扩散过程中加入文本条件,指导图像生成
- 用户可以通过文字描述生成想要的图片
3.4 Stable Diffusion的意义
- 实用性强:可以在普通GPU上运行
- 开源免费:推动了AI绘画的普及
- 生态丰富:大量社区模型和插件
3. Stable Diffusion:实用化的突破(2022年)
3.1 为什么需要Stable Diffusion?
DDPM虽然效果不错,但有个致命缺点:计算成本太高!一张512×512的图片需要在像素级别上进行扩散,计算量巨大。2022年,Stable Diffusion横空出世,解决了这个问题。
3.2 Stable Diffusion的创新
Stable Diffusion最大的创新是潜在空间扩散:
- 传统方法:直接在原始图像空间(如512×512像素)进行扩散
- Stable Diffusion:先将图像压缩到潜在空间(如64×64),在潜在空间进行扩散,最后再解压回原空间
这样计算量减少了约16倍,使得扩散模型变得实用起来。
3.3 文本到图像生成
Stable Diffusion另一个重要特性是支持文本到图像生成:
- 使用CLIP模型将文本转换为语义向量
- 在扩散过程中加入文本条件,指导图像生成
- 用户可以通过文字描述生成想要的图片
3.4 Stable Diffusion的意义
- 实用性强:可以在普通GPU上运行
- 开源免费:推动了AI绘画的普及
- 生态丰富:大量社区模型和插件
4. DiT:拥抱Transformer时代(2023年)
4.1 为什么用Transformer?
随着Transformer在NLP领域的巨大成功,研究者们开始思考:能否用Transformer来改进扩散模型?2023年,DiT(Diffusion Transformer)应运而生,将纯Transformer架构引入扩散模型。
4.2 DiT的创新点
架构革新:
- 用Transformer替换传统的CNN架构
- 采用纯Transformer的骨干网络
- 更好的可扩展性和并行化能力
性能提升:
- 大模型展现更好的生成质量
- 训练稳定性显著提高
- 可扩展性更强
4.3 DiT vs 传统方法
| 特性 | 传统UNet | DiT |
|---|---|---|
| 架构 | CNN | Transformer |
| 可扩展性 | 中等 | 很好 |
| 训练稳定性 | 一般 | 很好 |
| 全局建模 | 需要多层 | 天然全局 |
5. 扩散模型发展时间线
2020年 - DDPM:奠定扩散模型理论基础
↓
2021年 - Improved DDPM:各种改进和优化
↓
2022年 - Stable Diffusion:实用化突破,潜在空间扩散
↓
2023年 - DiT:Transformer架构,可扩展性大幅提升
↓
2024年至今 - 各种变体和优化:蒸馏、量化、多模态等
5.1 技术演进路径
- DDPM (2020):基础理论,像素级扩散,计算成本高
- Latent Diffusion (2022):潜在空间扩散,大幅降低计算成本
- DiT (2023):Transformer架构,更好的可扩展性
5.2 DIT和Stable Diffusion模型区别
Stable Diffusion
- 架构:U-Net + 卷积神经网络
- 特点:在潜在空间工作,计算效率高
- 优势:成熟稳定,生态完善
- 缺点:架构相对传统,扩展性有限
DiT (Diffusion Transformer)
- 架构:纯Transformer架构
- 特点:将扩散过程完全用Transformer处理
- 优势:更好的扩展性,更容易scale up
- 缺点:计算量更大,需要更多资源
DiT参考了Stable Diffusion的思想,借鉴了扩散模型的基本框架,但将传统的U-Net架构替换为Transformer架构,这是架构层面的重大革新。
注:Stable Diffusion 就是 Latent Diffusion 的一个具体实现,Stable Diffusion = Latent Diffusion + 文本条件 + 稳定性优化
5.3 VIT模型和DIT模型关系
DiT是ViT思想在生成领域的成功应用,为什么这么说呢?DIT参考了ViT的思路将扩散模型由U-Net改用Transformer。
ViT (Vision Transformer, 2020年)
- 开创性工作:将Transformer架构首次成功应用于图像识别
- 基本思路:把图像切成小块(patch),当作"单词"输入Transformer
- 主要应用:图像分类任务
DiT (Diffusion Transformer, 2022年底)
- 继承关系:基于ViT的成功经验,将Transformer应用于扩散模型
- 核心创新:用Transformer替换传统的U-Net架构
- 主要应用:图像生成任务
相同点
- 都使用Transformer架构
- 都采用patch处理方式
- 都利用自注意力机制
- 都有良好的扩展性
不同点
| 方面 | ViT | DiT |
|---|---|---|
| 任务类型 | 图像分类 | 图像生成 |
| 输入 | 静态图像 | 噪声 + 时间步长 |
| 输出 | 分类标签 | 去噪后的图像 |
| 核心 | 特征提取 | 扩散过程建模 |
ViT优势
- 在分类任务上表现优异
- 训练相对简单
- 计算效率高
DiT优势
- 在生成任务上表现更好
- 扩展性更强
- 生成质量更高
6. 当前业界主流扩散模型
6.1 开源模型系列
Stable Diffusion系列:
- Stable Diffusion 1.x (2022):最初的版本,奠定了基础架构
- Stable Diffusion 2.x (2022):改进了CLIP模型,支持更大的图像尺寸
- Stable Diffusion XL (SDXL, 2023):更大的模型,更高的图像质量
- Stable Diffusion 3 (2024):最新的版本,进一步提升了生成质量
其他开源模型:
- DALL-E系列:OpenAI的文本到图像模型
- Imagen:Google的高质量扩散模型
6.2 不同场景的选择
学术研究:
- DDPM:理解扩散模型基础
- DiT:探索Transformer架构
商业应用:
- SDXL:平衡质量与效率
- 定制化模型:根据具体需求调整
6.3 当前主流(2024-2025年)
- Midjourney系列 - 基于改进的扩散模型
- DALL-E 3 - 结合多种技术的混合模型
- Stable Diffusion XL (SDXL) - SD的升级版
- Runway、Leonardo等平台 - 基于各种扩散模型变体
6.4 具体领域
- AI绘画:主要是Stable Diffusion变体 + 各家自研改进
- AI漫画:专门针对动漫风格优化的SD模型
- 商业应用:多基于Stable Diffusion开源生态
6.5 趋势变化
- 早期:Stable Diffusion为主流
- 现在:各大公司都在基于扩散模型开发私有模型
- 未来:DiT等Transformer架构可能成为新趋势
目前大多数应用仍基于Stable Diffusion生态,但高端应用开始采用DiT等新架构。未来可能会逐步向Transformer架构迁移。
7. 总结
扩散模型的发展历程体现了AI领域的快速迭代:
- DDPM (2020):奠定了理论基础,但计算成本高
- Stable Diffusion (2022):实现了实用化突破,潜在空间扩散
- DiT (2023):开启了Transformer时代,更好的可扩展性
这些模型不仅在技术上不断创新,也在实际应用中产生了巨大影响,从学术研究到商业产品,扩散模型正在重塑我们创造和处理视觉内容的方式。