本文入选顶会SIGIR 2025
点击率预估任务通常会面临冷启动问题,即新用户因历史行为数据不足而难以进行准确预测。近期研究尝试通过编码器-解码器网络,基于活跃用户数据为冷启动用户生成虚拟行为表征。然而,现有方法存在两大缺陷:对活跃用户行为的编码技术过于简单化,且直接使用虚拟行为表征会导致用户兴趣表达受限、模型泛化能力不足。为解决这些问题,我们提出创新性的基于图同构网络的群体建模方法。该方案通过GIN网络有效捕捉用户-物品高阶交互关系,从而更精细地刻画用户多样化兴趣。结合群体建模策略,可显著减少嵌入构建偏差,增强模型泛化能力。我们在公开数据集和工业数据集上的实验表明,相较现有方法,新方案对活跃用户和冷启动用户均带来显著效果提升。
论文链接:dl.acm.org/doi/10.1145...
01 业务背景与问题表现
1、业务场景:京东广告推荐系统
在京东的在线广告推荐系统中,系统每天需要为数亿用户实时推送个性化广告。CTR(点击率)预测模型是核心模块,直接决定广告收入和用户体验。
核心目标:预测用户对某个广告的点击概率 P(y=1∣u,i)P(y=1∣u,i),从而排序并展示最可能被点击的广告。
2、冷启动问题(Cold Start Problem)的表现
冷启动问题是指推荐系统在缺乏用户-物品交互数据时,无法提供有效个性化推荐的困境。
| 用户类型 | 行为数据 | 问题表现 |
|---|---|---|
| 活跃用户(Warm User) | 有大量历史点击、浏览、收藏行为 | 模型可精准建模兴趣 |
| 冷启用户(Cold User) | 无/少历史行为、仅知基础属性(性别、年龄、地域) | 模型无法有效建模兴趣 → 推荐随机、点击率低、转化差 |
3、具体业务影响
新用户点击率低:因无行为数据,只能依赖统计特征,推荐"热门商品"或"默认广告",缺乏个性化。
用户体验差:用户看到"与我无关"的广告 → 产生反感、降低平台信任度。
模型评估偏差:传统模型在"全体用户"上AUC表现良好,但在"新用户"子集上显著下降。
关键痛点: "没有行为,就没有兴趣" ------ 但用户不能等行为积累后才被推荐。
02 问题抽象与动机提炼
1、零样本学习的核心思路
在缺乏交互数据的前提下,利用辅助信息(属性、内容、关系等)进行兴趣推断。"从千万个老用户的行为模式中,学习'属性→行为','行为→属性'的映射规则,然后用这个规则,基于用户的属性信息,为新用户生成一个'虚拟的但合理'的行为推断。"
场景设定
一位新用户"小李"刚注册京东App,仅提供以下属性信息:性别-女,年龄-28岁,城市-北京,设备-iPhone 15,从未点击、购买过任何商品------ 行为数据为0。
传统推荐系统看到她,只能推"全站热销":iPhone 17、AirPods、小米手环......
但系统中有多个与小李相似的活跃用户和其历史行为
用户A:性别-女,年龄-26岁,城市-北京,设备-iPhone16 ,历史点击- Apple Watch, 吹风机,扫地机器人......
用户B:性别-女,年龄-29岁,城市-北京,设备-iPhone16 ,历史点击- 运动服饰,网球拍......
基于这部分用户的历史兴趣,我们可以大致推断该类用户比较共同的兴趣范畴:她们生活在一线都市,注重生活品质与效率,偏好科技感强、能提升日常体验的智能家电,同时关注健康与自我管理。
零样本方法两大问题(论文动机来源):
| 缺陷 | 描述 | 问题 |
|---|---|---|
| 1. 行为编码过于简单 | 用Mean-Pooling等方式直接聚合行为序列,忽略高阶交互(如:用户A买过手机+耳机 → 可能也买充电宝) | 生成的虚拟行为嵌入信息稀疏、表达力弱 |
| 2. 直接使用虚拟嵌入 | 将生成的虚拟行为嵌入直接输入CTR模型,未做校正 | 与真实行为嵌入存在偏差→ 模型学到的是"噪声兴趣" |
核心洞察: 我们不需要"完美还原"个体行为,而是要找到一群相似的用户,用群体共识来校正个体偏差。
2、论文的抽象与动机提炼
| 核心问题 | 抽象问题 | 论文动机 |
|---|---|---|
| 数据层面 | 个体行为嵌入表达力不足 | → 引入GIN图网络,建模高阶、非线性用户-物品交互 |
| 建模层面 | 虚拟嵌入有偏差 | → 引入群体建模(Cohort Modeling) :不依赖个体,依赖群体共识 |
| 系统层面 | 无法在线部署,延迟高 | → 设计预计算+实时读取架构,兼顾精度与效率 |
核心动机: "用图神经网络生成虚拟行为表征,再用群体共识校正个体偏差,实现冷启动用户的群体智能推荐"
03 论文解法与实验方案
1、整体架构:GINCM(Graph Isomorphism Network-based Cohort Modeling) 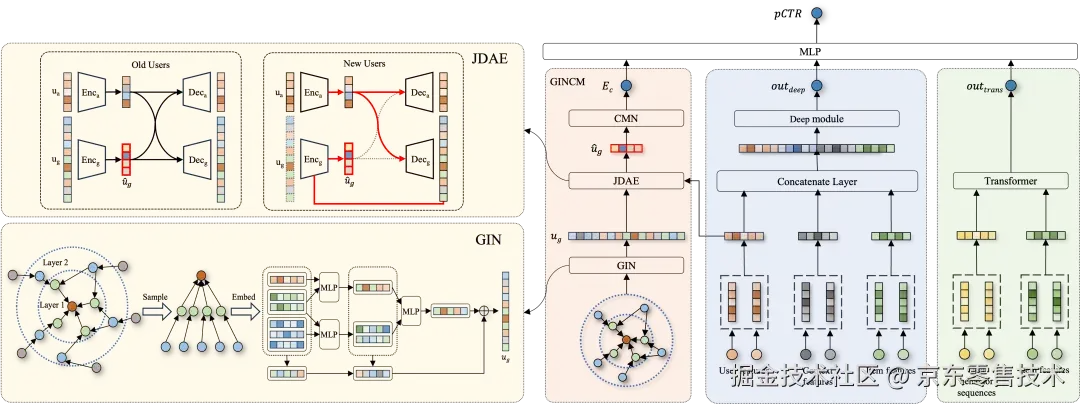
2、模型由三大模块协同工作
模块一:GIN-based Graph Encoder(高阶交互建模)
输入:用户-物品交互图(二部图),节点=用户/物品,边=点击/浏览
步骤:使用Graph Isomorphism Network (GIN)编码子图
◦GIN 相比GCN、GraphSAGE,GIN能捕捉更复杂的拓扑结构,能学习到更高级的用户-商品交互模式
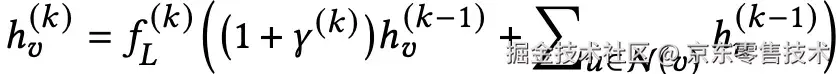
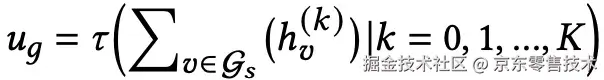 输出:聚合后的用户行为表征
输出:聚合后的用户行为表征
模块二:Joint Denoising Auto-Encoder(JDAE)------ 虚拟行为生成
目标:为冷启用户生成"虚拟行为嵌入"
输入:冷启用户的属性特征(如:性别=男,年龄=25,城市=北京)
结构:
编码器:将用户属性特征和用户行为特征都进行编码;
解码器:双向重建,用"行为"重建"属性" ,用"属性"重建"行为"•损失函数(式6):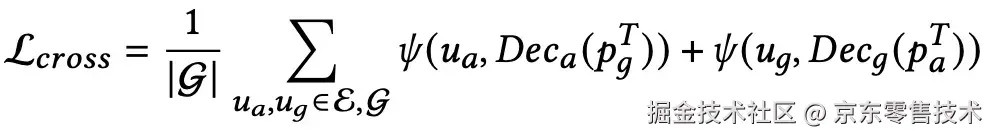
关键设计: 如果"25岁男性"能重建出"买手机+耳机"行为 → 说明模型学到真实模式 如果"买手机+耳机"能重建出"25岁男性" → 说明行为与属性强相关
模块三:Cohort Modeling Network(CMN)------ 群体共识校正
核心思想:以群体兴趣代替有偏的个体兴趣
步骤:
1、将生成的虚拟用户行为表征二值化(Binarization + STE)得到二进制码
2、STE(Straight-Through Estimator)允许反向传播通过二值化操作
3、每个二进制码代表一个群体(Cohort),如:1,0,1,0,0,1,0,0表示属于第1、3、6群体
4、对当前用户对应群体兴趣进行聚合
为什么有效? 即使生成的用户行为表征有偏差,只要它落在"相似群体"中,就能被群体中心拉回正轨。 群体像"平均值",能过滤噪声,提升鲁棒性。
3、实验方案与结果
数据集
| 类型 | 数据量 | 说明 |
|---|---|---|
| 公开数据集 | Amazon Reviews | 1.2M样本,标准benchmark |
| 工业数据集 | 京东广告系统 | 30亿样本,31天数据(前30天训练,最后1天测试) |
消融实验(Ablation)
| 模块 | 去除后新用户AUC | 结论 |
|---|---|---|
| 无GIN(用Mean Pooling) | ↓ 0.7321 | GIN对高阶交互建模非常重要 |
| 无JDAE(用默认向量) | ↓ 0.7112 | 虚拟行为生成效果优于直接用属性 |
| 无CMN(直接用虚拟嵌入) | ↓ 0.7145 | 群体校正比个体直接使用更鲁棒 |
在线部署与A/B测试
部署方式:
预计算:用户行为发生 → 图引擎实时构建子图 → GINCM计算并缓存
实时预测:精排阶段,直接读取缓存的 cohort embedding,无需重算图
结果:
CTR 提升 2.13%
RPM(千次展示收入)提升 2.13%