大家好,我是小肥肠!今天我们搞点真正的黑科技,挑战一下大模型的"记忆极限"。针对AI写长文容易"失忆"的顽疾,我用 n8n + MemMachine 打造了一套"永不忘词"的无限长篇小说工作流。从大纲设定到自动连载,字数无上限,剧情不崩坏,一键直达飞书。想让你的 AI 进化成能写百万字的"网文大神"吗?码住这篇教程,带你零门槛实操起飞!
1. 效果演示
上周我写了一个写小说的工作流,很多读者反馈能不能突破篇幅限制,短篇小说不够看的。为了解决这个痛点,我基于 MemMachine 实现了这个可以突破大模型上下文限制的 n8n 无限长篇小说工作流。做出来以后在群里内测,反馈相当不错。
现在的工作流一共为两部分:
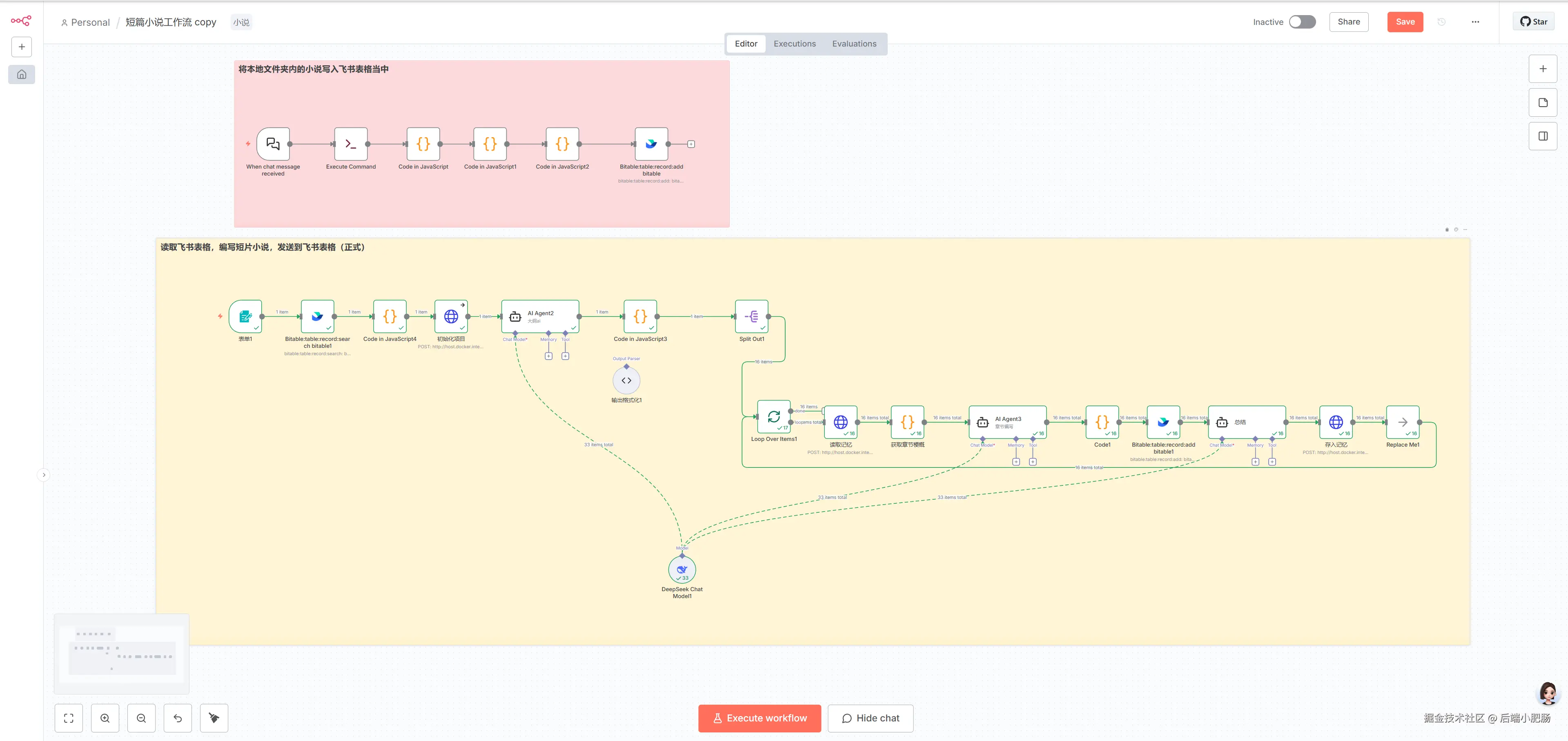
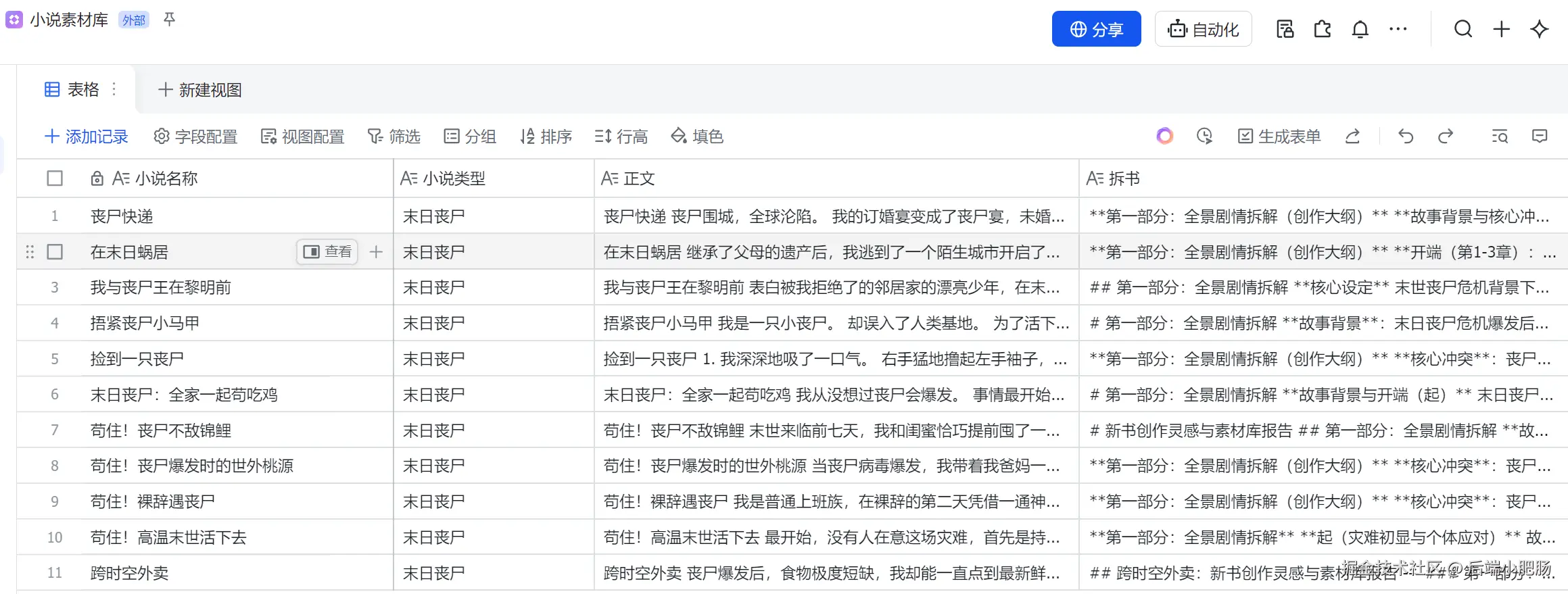
第一部分是将本地小说录入飞书素材库。有了这一步,我们就可以基于自定义素材,编写任意领域风格的小说。
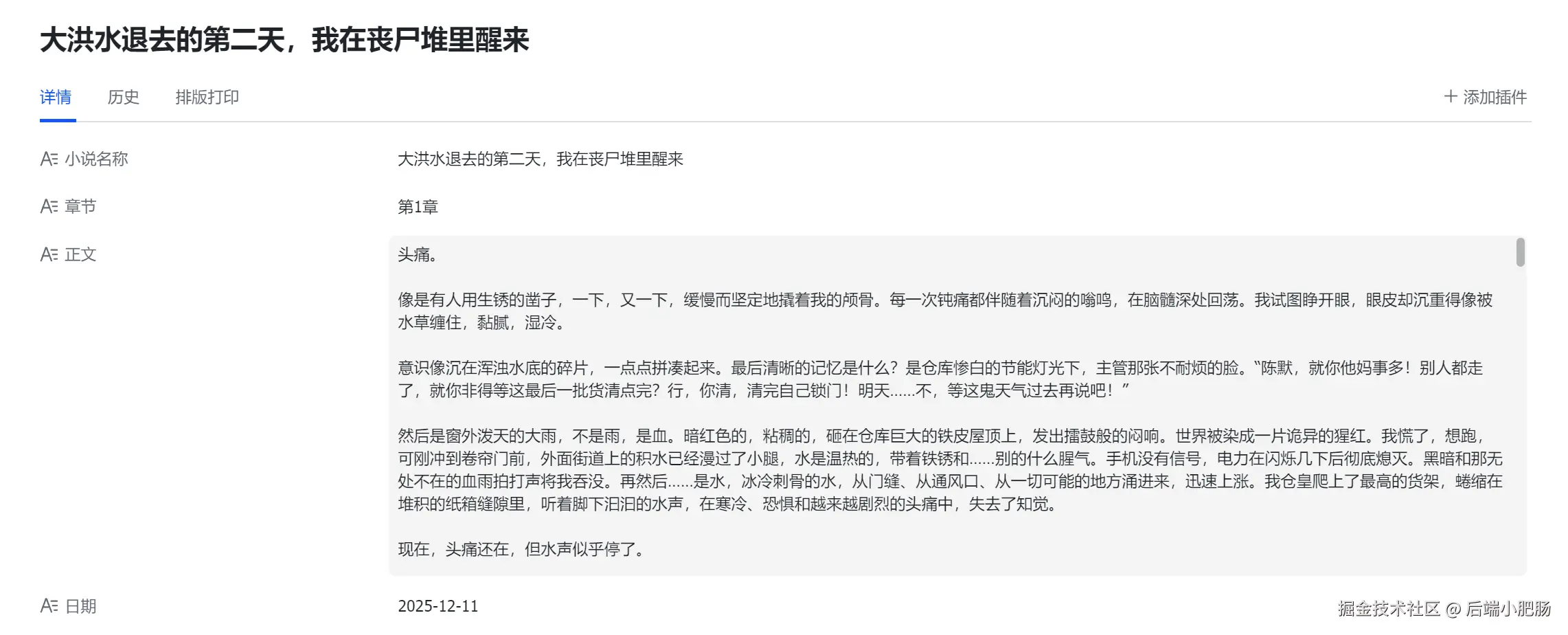
第二部分 是读取素材库中的小说作为参考配合MemMachine 记忆库编写长篇小说,下图中写了整整16章。
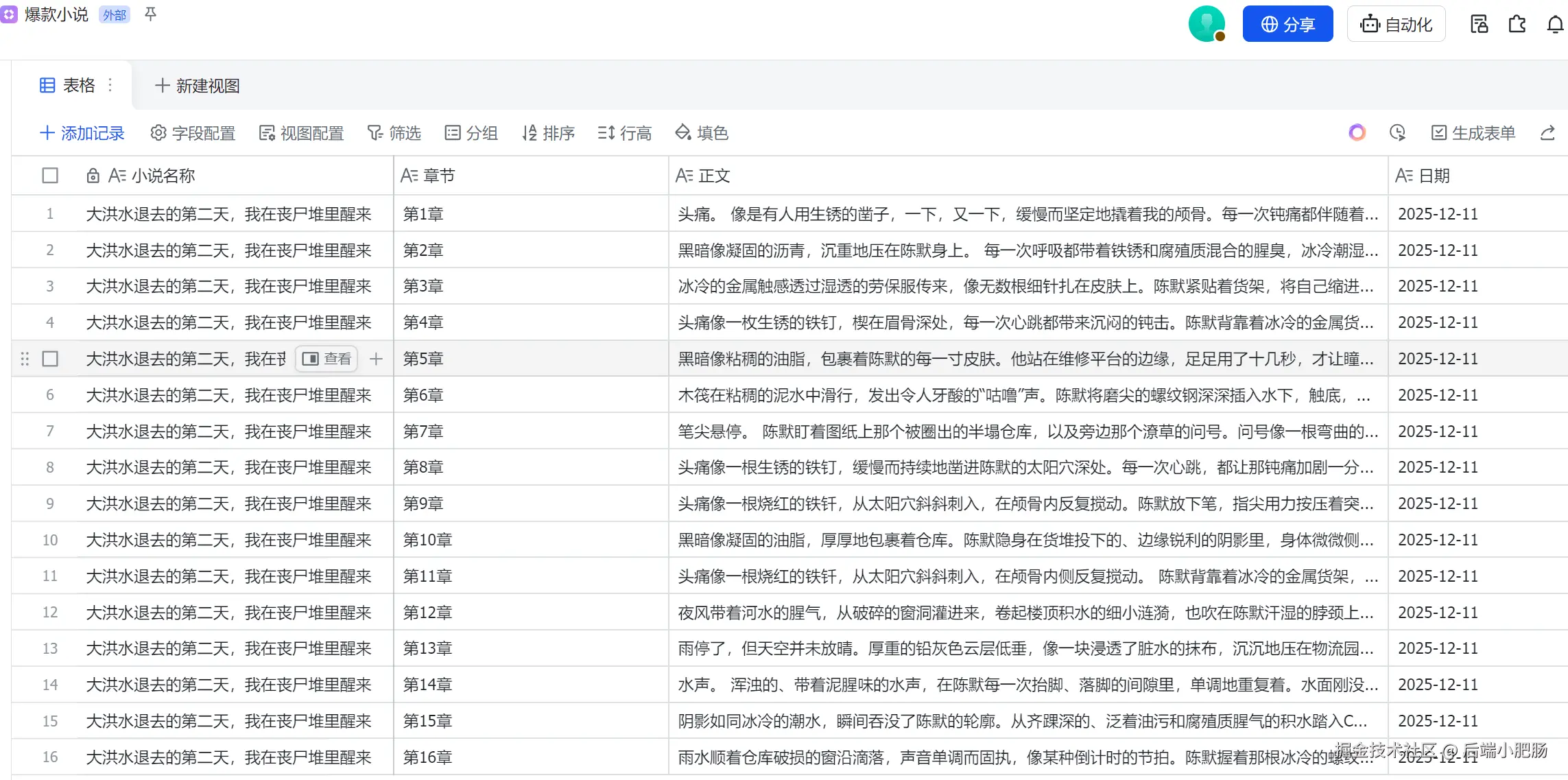
每章的字数在2000---3000字,远远突破了大模型上下文限制。
接下来就正式开始这个硬核工作流的搭建~
2. 工作流架构剖析和前置准备
2.1 长篇小说工作流架构说明
长篇小说工作流主要依赖于MemMachine来存储章节的记忆,每写完一章会将这章的内容存入记忆库,下一章的编写可依赖这一章的内容。

2.2 基于Docker部署MemMachine
MemMachine 是一个开源的AI 智能体通用记忆层(Universal Memory Layer) 项目。简单来说,它的目标是解决大语言模型(LLM)通常存在的失忆问题(即无状态),让 AI 智能体能够像人一样拥有长期记忆、个性化认知和上下文理解能力。
现在的 AI 虽然聪明但非常健忘,一旦关闭对话窗口或者换一个模型,它就会把你以前说过的话和你的个人喜好忘得一干二净。MemMachine 就是为了解决这个问题而设计的一个外挂大脑,它能像一个超级记事本一样,自动把你的聊天记录、习惯偏好(比如我不吃香菜)和历史事件永久存储下来。
这样做最大的好处是,AI 拥有了长期记忆。哪怕你过段时间再回来,或者换用了不同公司的 AI 模型,只要连上这个系统,AI 就能立刻想起来你是谁以及你们之前的交情,不需要你重复啰嗦。它让 AI 从一个每次见面都要重新认识的陌生人,变成了一个真正懂你、记得你一切过往的老朋友。
源码地址: github.com/MemMachine/...
进入页面后我们就可以用git clone或下载压缩包的形式来下载源码了,源码下载完后项目的目录如下图。
只需要配置好.env、docker-compose.yml、configuration.yml这三个文件就可以基于Docker顺利部署MemMachine在本地了。
MemMachine 部署也很简单,只需要在文件路径输出cmd,在弹出的命令提示符中输入docker compose up -d即可完成部署。
部署后可访问http://localhost:8080/docs,看到如下界面即为成功。
3. 工作流搭建
这个小说工作流和原来的一样,唯一的区别是加了MemMachine 记忆写入和读取逻辑。这里就不再从头开始搭建,只讲差异部分,需要看从0开始的搭建步骤可以去看通吃网文投稿+AI漫剧版权!我用 n8n+飞书搭了个"万字爆款小说流水线"
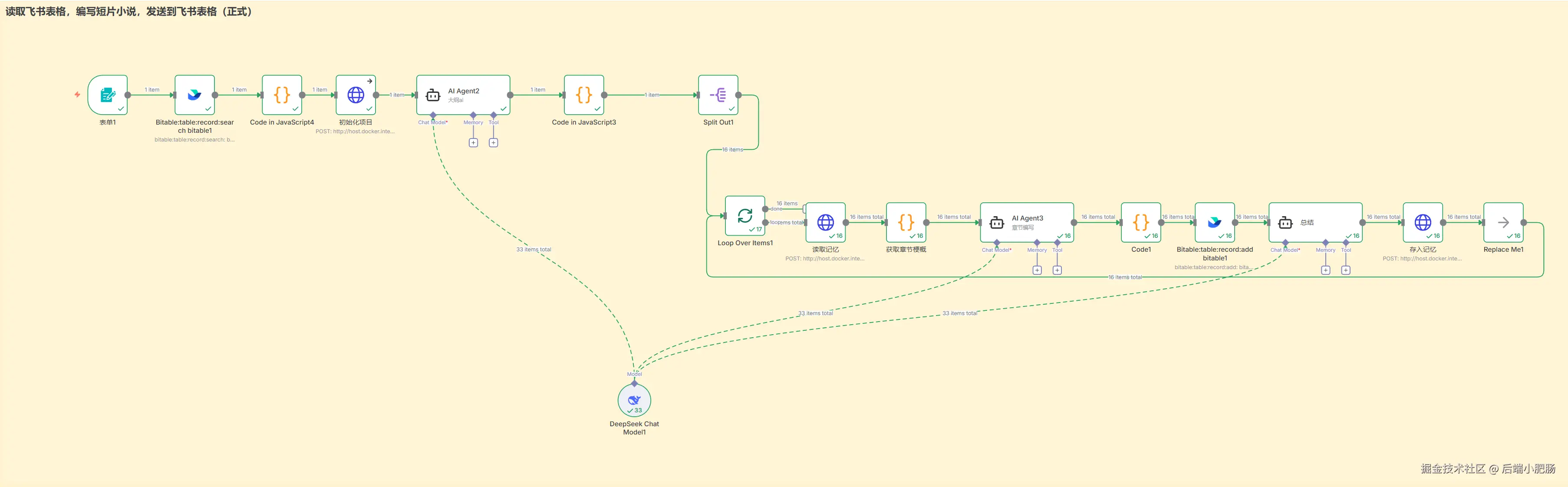
长篇小说工作运行流程如下:
-
表单提交小说主题和领域内容
-
根据用户提交表单中的小说领域去飞书素材库中找到对应小说素材作为写作参考
-
结合小说素材,用户提供的主题编写小说的大纲和章节梗概列表(数组形式)
-
初始化一个MemMachine project,获得一个project_id
-
进入循环开始编写章节内容
-
根据project_id从MemMachine 获取上一章节的内容
-
根据前期提要,大纲和本章节的梗概编写本章节的详细内容
-
写入章节内容到飞书表格
-
总结本章节的内容,以project_id为标识写入MemMachine
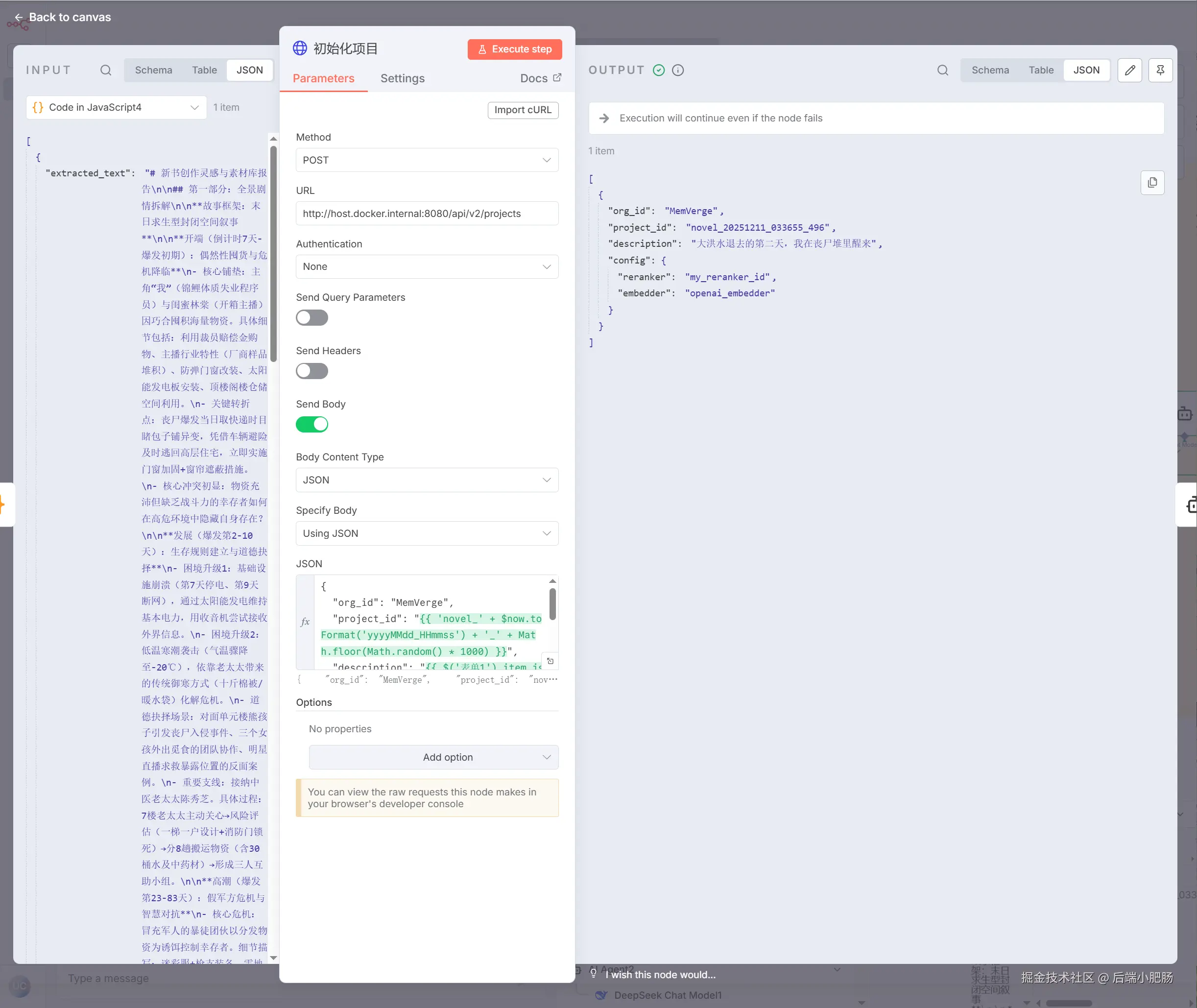
初始化项目(HTTP Request): 这个节点位于编写大纲节点的前面,它的作用是在MemMachine 中新建一个project,后续编写的章节内容会存入到project中。
跟之前的小说工作流比,这个工作流的变动主要在章节编写部分,故本文的节点搭建讲解主要围绕章节编写部分展开:

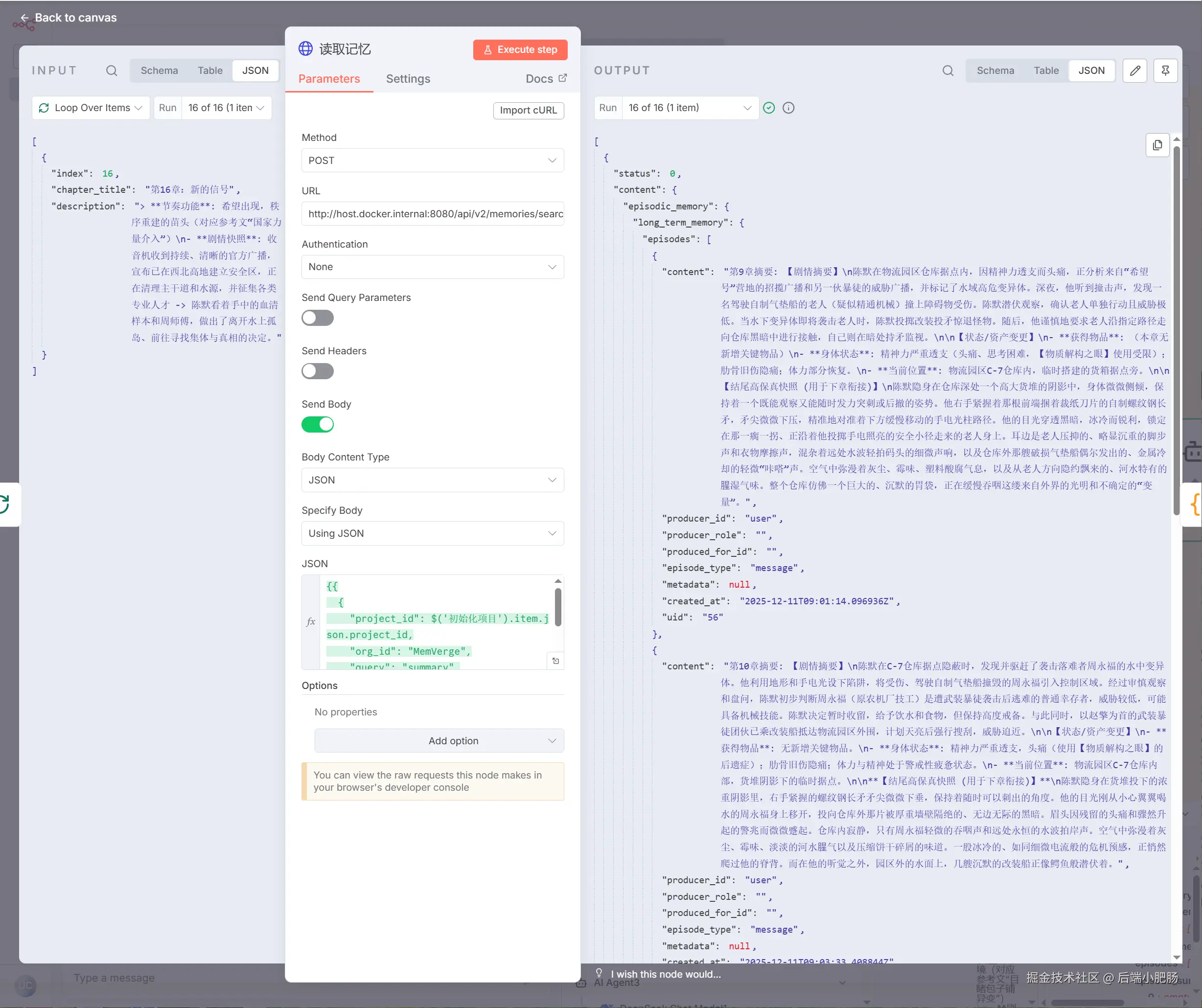
读取记忆(HTTP Request): 这个节点的作用是根据project_id ,获取对应project 中存储的记忆。举个例子,如果当前章数为3 ,那么就会从project中 获取前2章的数据,如果当前章数为1则返回空数据。
获取章节梗概(Code inJavaScript):读取记忆(HTTP Request)节点出来后点击【+】新增Code inJavaScript节点。 它的作用是从前置所有章节列表中取出最后一章的章节内容。如读取记忆(HTTP Request) 节点传入了2章数据,那么这个节点就会获取第2章数据。
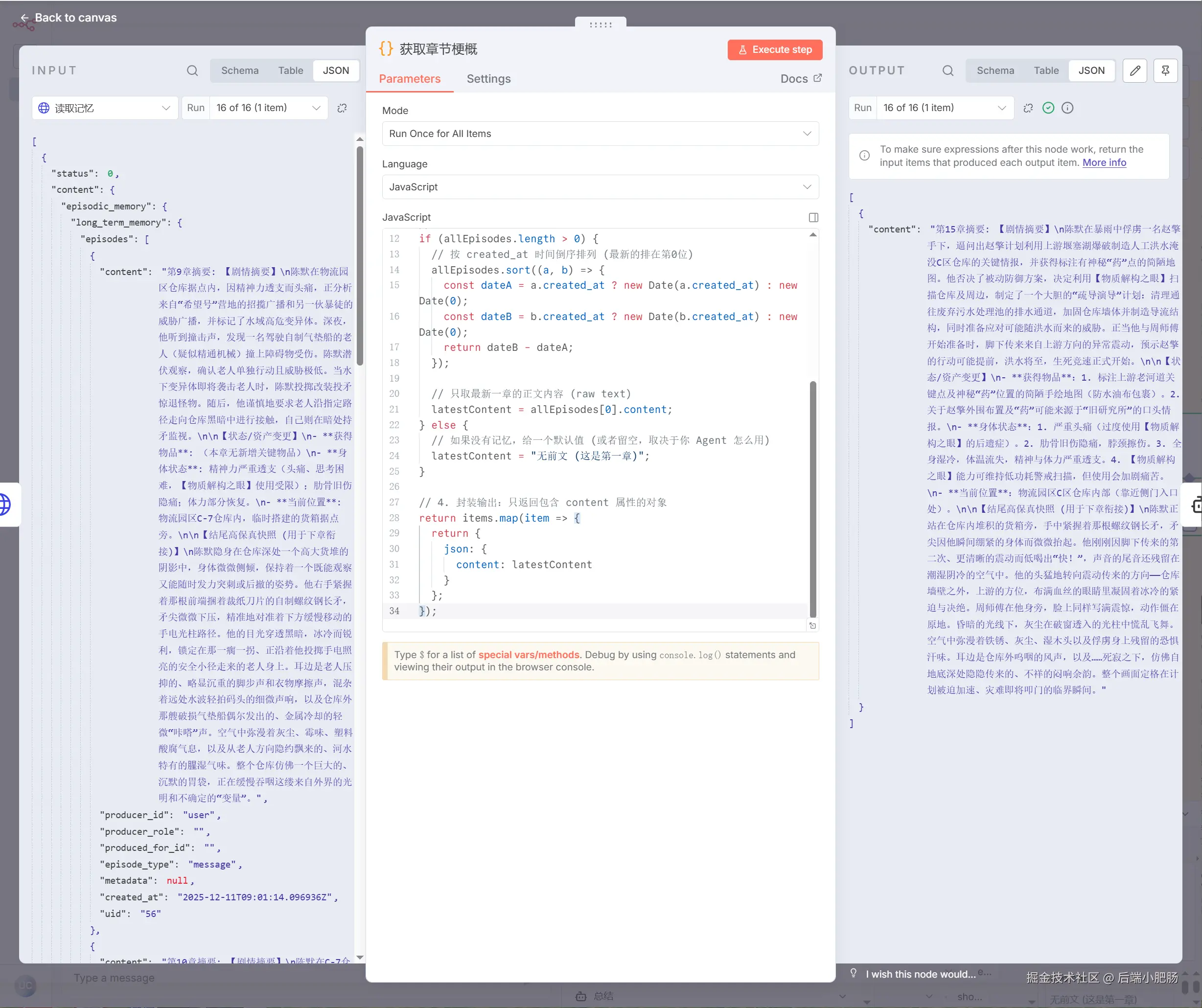
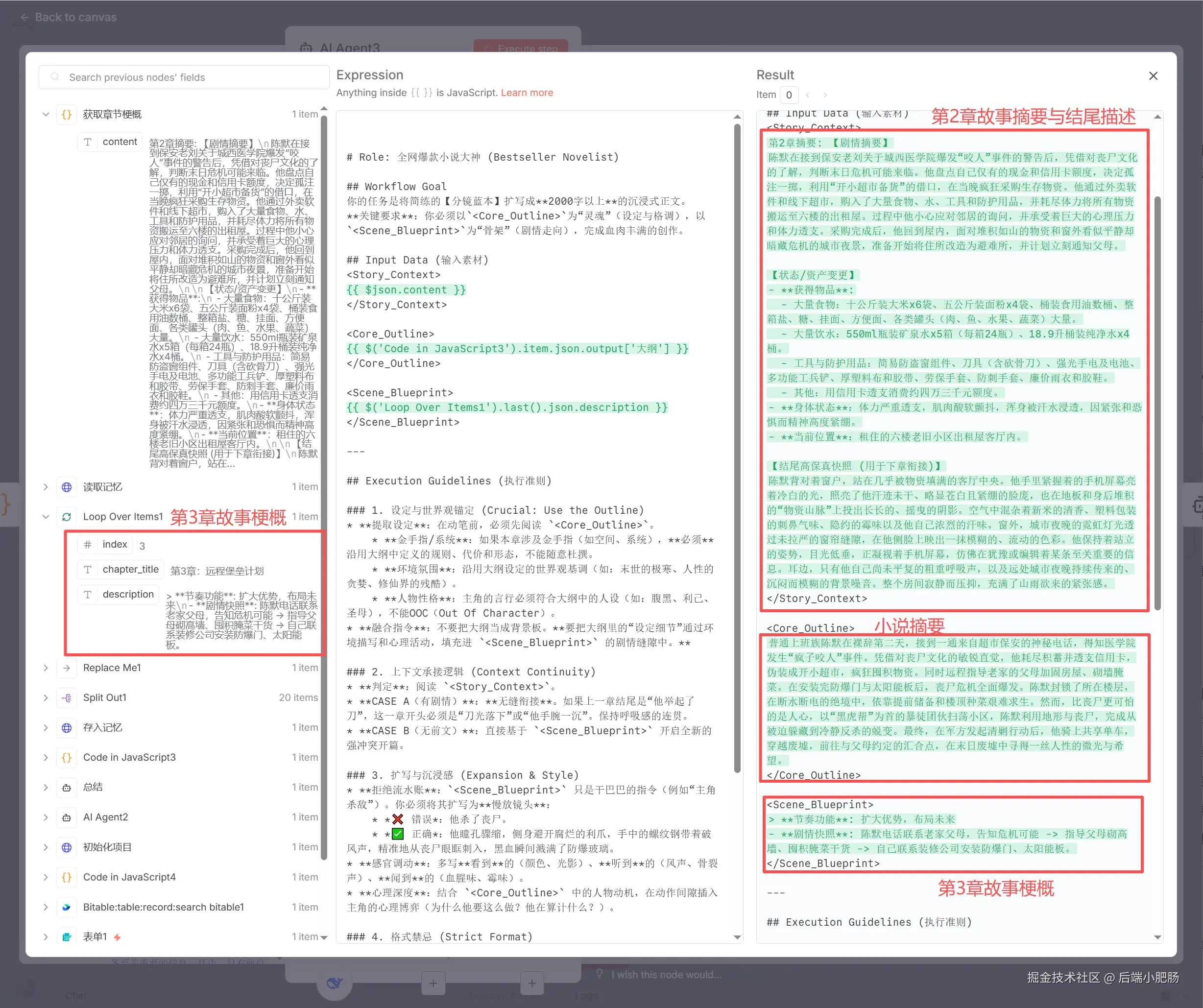
章节编写(AI Agent):获取章节梗概(Code inJavaScript)节点出来后点击【+】新增AI Agent节点。 这个节点的作用是根据小说摘要,第2章故事梗概与结尾,和第三章故事梗概编写第三章内容,这样就能完美解决大模型无法编写长篇小说以及内容过长导致的内容不连贯或人物OOC。
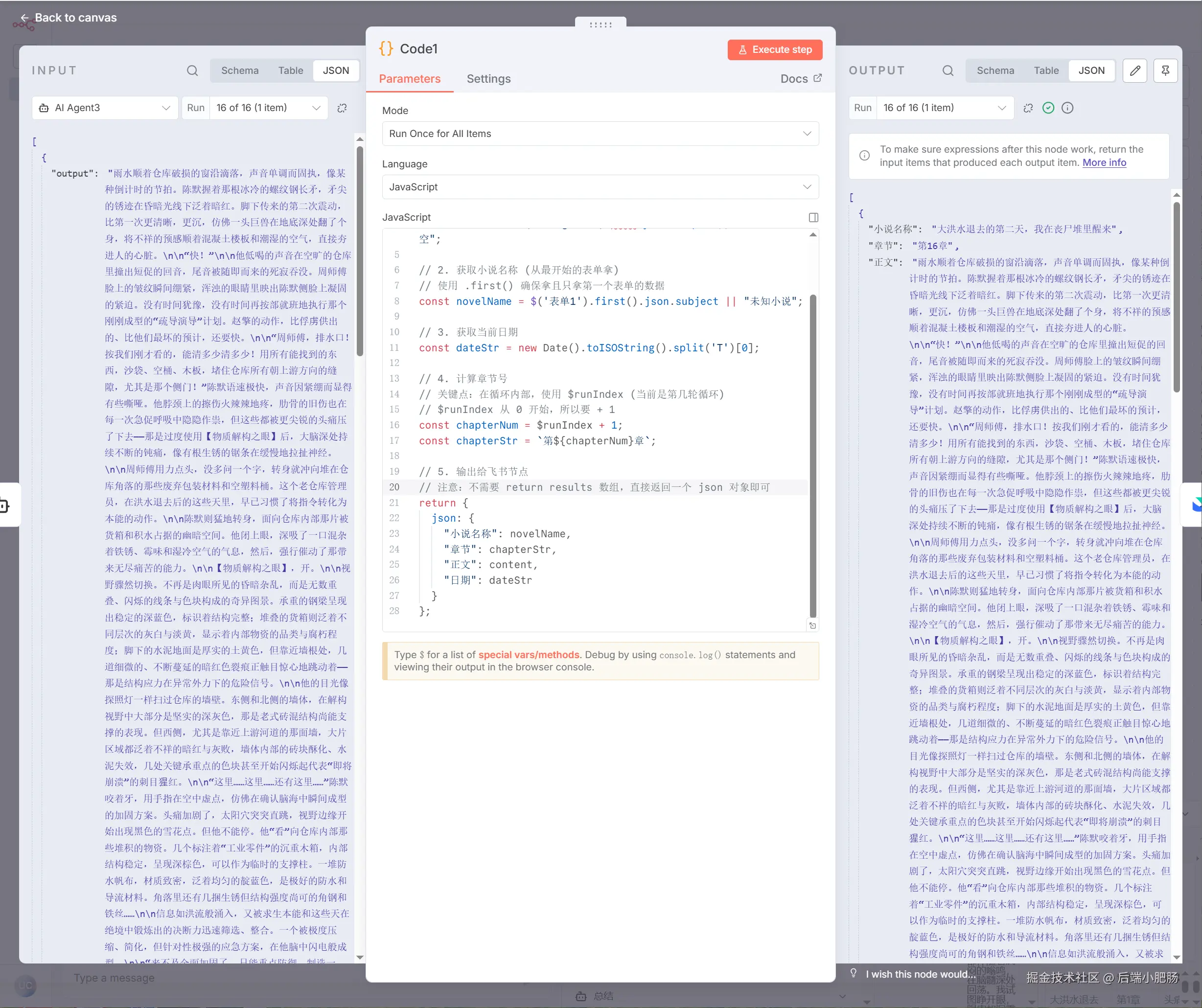
Code1(将数据改为 飞书 表格适配形式):章节编写(AI Agent)节点出来后点击【+】新增Code inJavaScript节点。 这是一个代码节点,它的作用是将小说内容适配为飞书表格的形式。
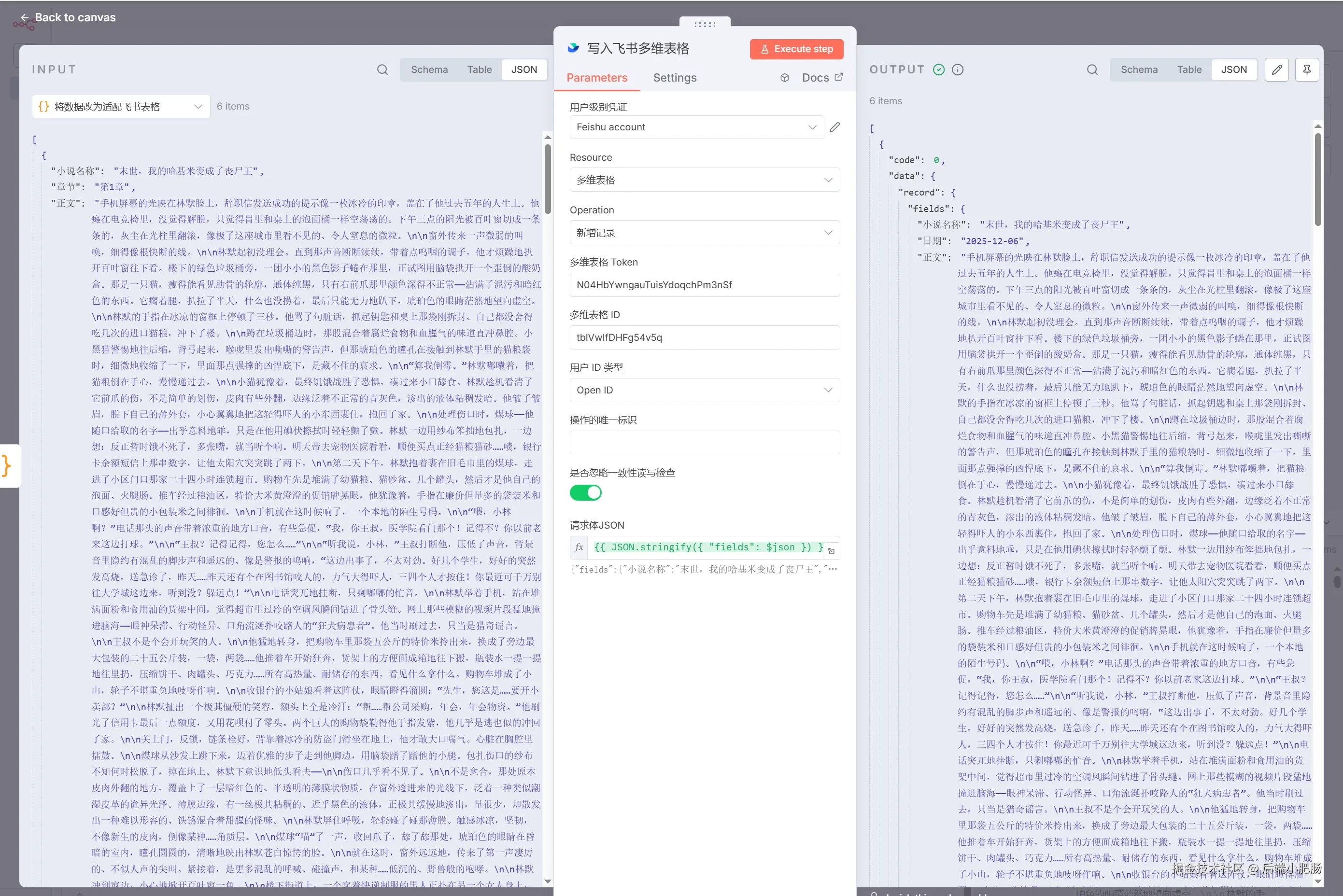
写入 飞书 (Bitable:table:record:add bitable):Code1(将数据改为飞书表格适配形式)出来后点击【+】新增Bitable:table:record:add bitable节点。 这是n8n社区节点,负责写入数据到飞书表格。节点的配置使用可参考n8n+Coze+飞书:公众号对标文章一键录入+深度拆解,打造你的【爆款素材库】
总结(AI Agent):写入 飞书 (Bitable:table:record:add bitable)节点出来后点击【+】新增AI Agent节点。 这个节点的作用是对章节编写(AI Agent)节点输出的小说内容进行总结,总结剧情摘要,保留结尾内容以便下一章的衔接。

存入记忆(HTTP Request):总结(AI Agent)节点出来后点击【+】新增HTTP Request节点。 这个节点的作用是调用MemMachine 接口将章节内容存入project。
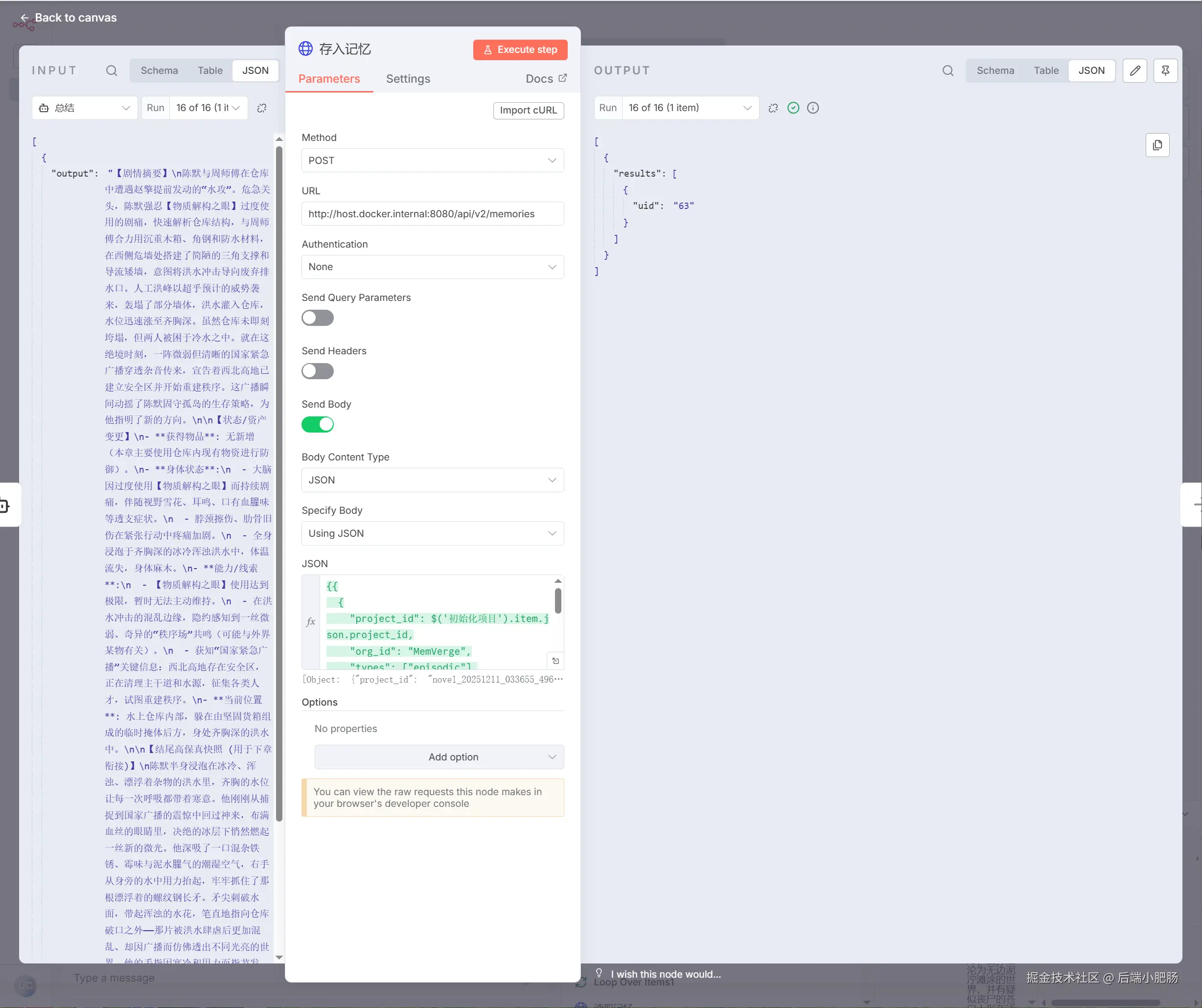
以上就是整个工作流的完整流程拆解,动手能力强的读者可以跟着教程实践一遍。上述工作流已经被收录到了小肥肠行动家社群中,如果想直接获取工作流原件,可以加入社群后我拉你进空间直接学习使用。
4. 结语
至此,一个能够自我迭代、拥有长期记忆的无限长篇小说生成器 就搭建完成了。这套工作流最大的价值,不在于写小说本身,而在于它证明了 MemMachine + n8n 组合的无限可能。当我们把记忆 从大模型中解耦出来,赋予 Agent 真正的长期状态管理能力时,AI就不再是一个聊完即忘的聊天机器人,而是一个能伴随剧情成长的创作者。
如本次分享对你有帮助,麻烦一键三连支持一下小肥肠,我们下期再见~
