初识RabbitMQ
首先介绍MQ(Message Queue,消息队列),用于解决不同进程或线程的异步通信问题,该模块主要起三个作用:异步通信增加了并发性 ;同时缓存消息,可以实现流量的削峰填谷 ;作为消息中间件隔离进程干扰,降低耦合性 ,所以由于该设计理念,MQ天然适合在微服务架构中使用。
但要注意的是一些需要立即获取结果 才能继续执行的场景不适用MQ,比如支付场景,必须要获得支付结果才能继续进行,
RabbitMQ是消息队列的具体实现之一,此外还有ActiveMQ、RocketMQ和Kafka,其中RocketMQ是阿里的开源项目,使用也较多,Kafka吞吐量最高,而RabbitMQ凭借其较低延迟(微秒级,其余都是毫秒级),和可接受的吞吐量得到最为广泛的应用。
有关RabbitMQ的详细文档可见官网:https://www.rabbitmq.com

快速入门
安装
RabbitMQ支持Windows和Linux系统,安装方法多样,Linux可以部署较为方便的容器,Windows则提供Chocolatey管理器安装和安装程序两种方法。
简要介绍下这几种方法:
- Chocolatey自动安装。Chocolatey是Windows的包管理工具,类似Linux中的apt,python中的pip,软件先发布到仓库,用户直接通过该仓库拉取;
- 安装程序。RabbitMQ基于并发语言Erlang,先安装该语言环境,配置系统变量,再下载rabbitmq执行;
- docker容器。只需一行命令
docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:4-management,即可拉取容器并指定端口,用户名等信息。
docker安装
生产环境下RabbitMQ多部署在Linux系统上,docker拉取运行也比较方便,但因为docker最近镜像源被封的很多,以前用的中科大现在不提供docker服务,阿里云等只对其服务器开放,所以只介绍下大致过程:
-
首先是安装docker:
更新源
sudo apt update
安装docker
sudo apt install docker.io docker-compose
将当前用户加入 docker 组(无需 sudo 操作 Docker)
sudo usermod -aG docker $USER
刷新组权限(无需重启生效)
newgrp docker
-
切换镜像源
创建并打开配置文件
sudo mkdir -p /etc/docker
sudo vim /etc/docker/daemon.json镜像源添加到配置及文件
{
"registry-mirrors": [
"https://docker.xuanyuan.me",
"https://docker.mirrors.ustc.edu.cn"
]
}重启守护进程与服务
sudo systemctl daemon-reload
sudo systemctl restart docker -
拉取RabbitMQ
拉取带管理界面的3版本
docker pull rabbitmq:3-management
Windows安装
流程参考官网:https://www.rabbitmq.com/docs/install-windows
RabbitMQ基于Erlang语言,所以首先要安装语言环境,可以到官网https://www.rabbitmq.com/docs/which-erlang查找对应支持的Erlang版本,目前最新的RabbitMQ是4.2版本,对应最大匹配Erlang是27。

Erlang下载官网:https://www.erlang.org/downloads
RabbitMQ下载连接:rabbitmq-server-4.2
下载后的安装过程可以参考:Erlang与RabbitMQ的下载与安装
配置Erlang环境变量,系统变量中添加名为ERLANG_HOME值为安装路径的变量,path中添加%ERLANG_HOME%\bin,此时系统任意位置打开cmd,输入erl -version见到如下界面,说明Erlang环境配置成功。
rabbitmq正常安装后,在其sbin目录下打开cmd控制台,输入rabbitmq-plugins enable rabbitmq_management安装管理界面 ,访问http://localhost:15672,初始用户名和密码都是guest,可进入如下页面:
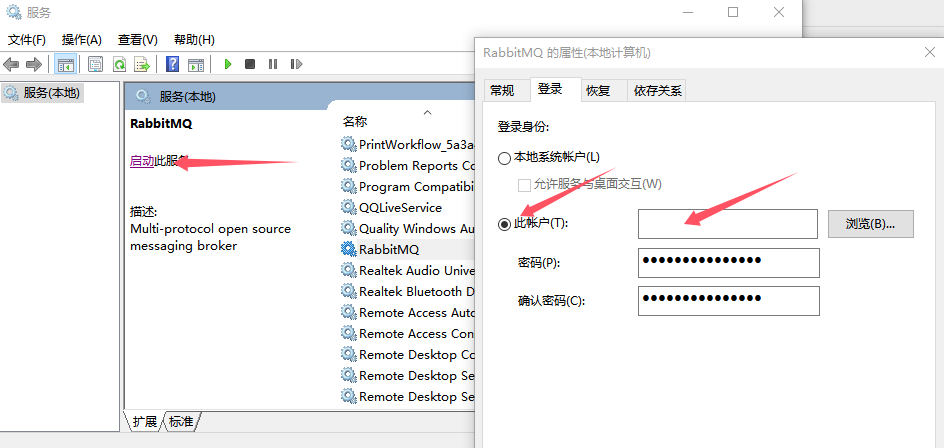
注意! 管理页面可能出现无法访问的情况。
参照这篇文章:15762无法访问解决
本质是用户管理授权问题,win+R并输入services.msc打开服务管理页面,找到rabbitmq,将登陆身份改为当前账户即可。
消息原理
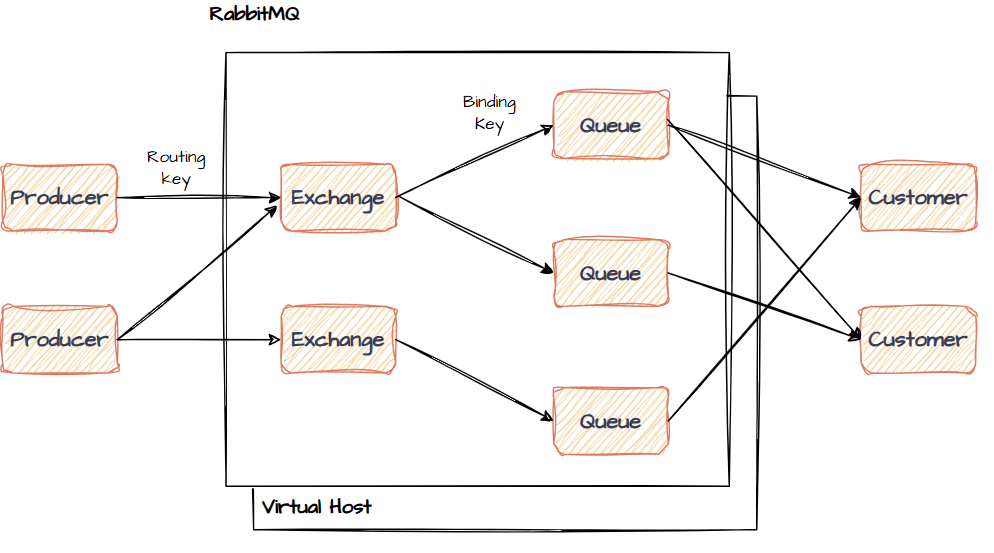
MQ结构的主体是生产者Producer和消费者Consumer,分别负责通过发送和接收消息,有关RabbitMQ的大致工作原理如下:
- 用户将信息发送到交换机
Exchange,交换机结合自身类型,根据路由标签Routing key与队列匹配规则Binding key决定要将消息转发到哪些队列; - 队列
Queue是消息暂存的容器(先进先出),默认状况下多消费者轮询读取消,费者确认读取后消息消失; - 虚拟主机
Virtual Host类似网络中码分复用技术,将消息队列隔离划分成多个区域,可充分利用其吞吐量,多个业务可共用MQ,数据通过虚拟主机分隔保证安全。
控制台使用
新增队列
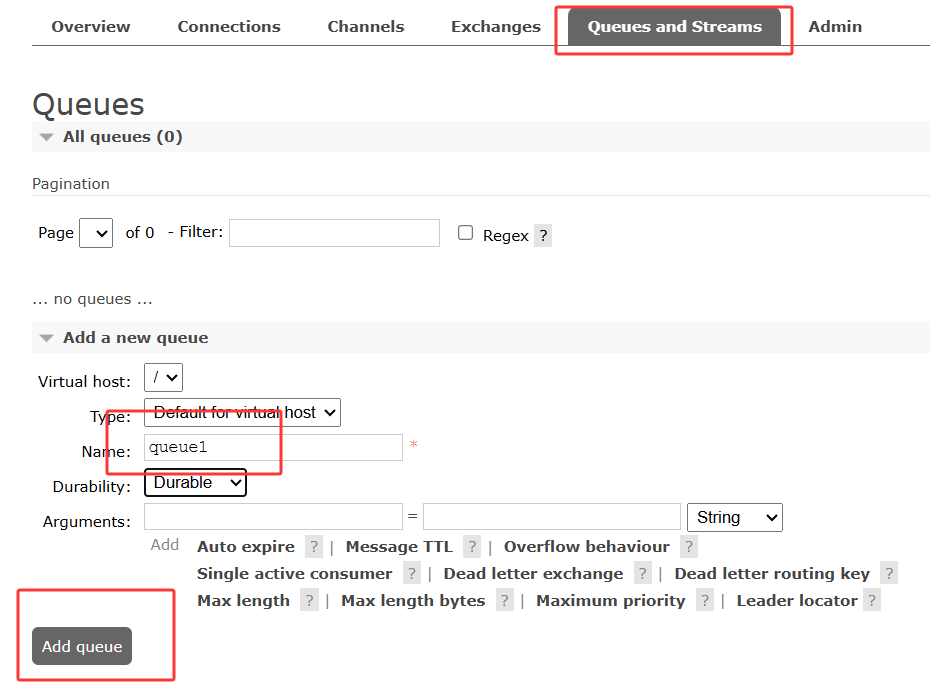
新增交换机
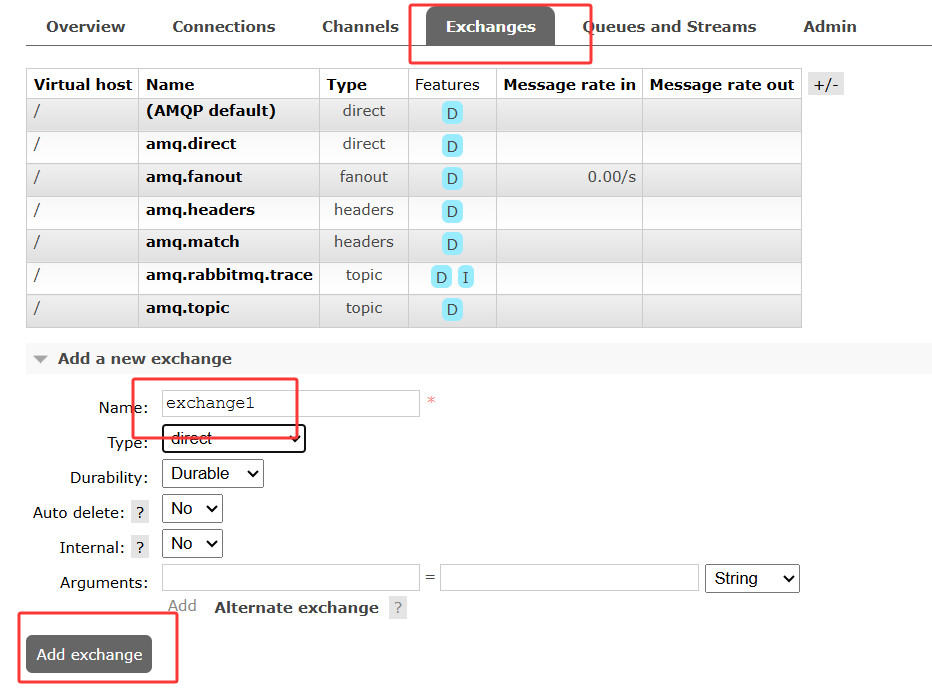
绑定队列并发送消息
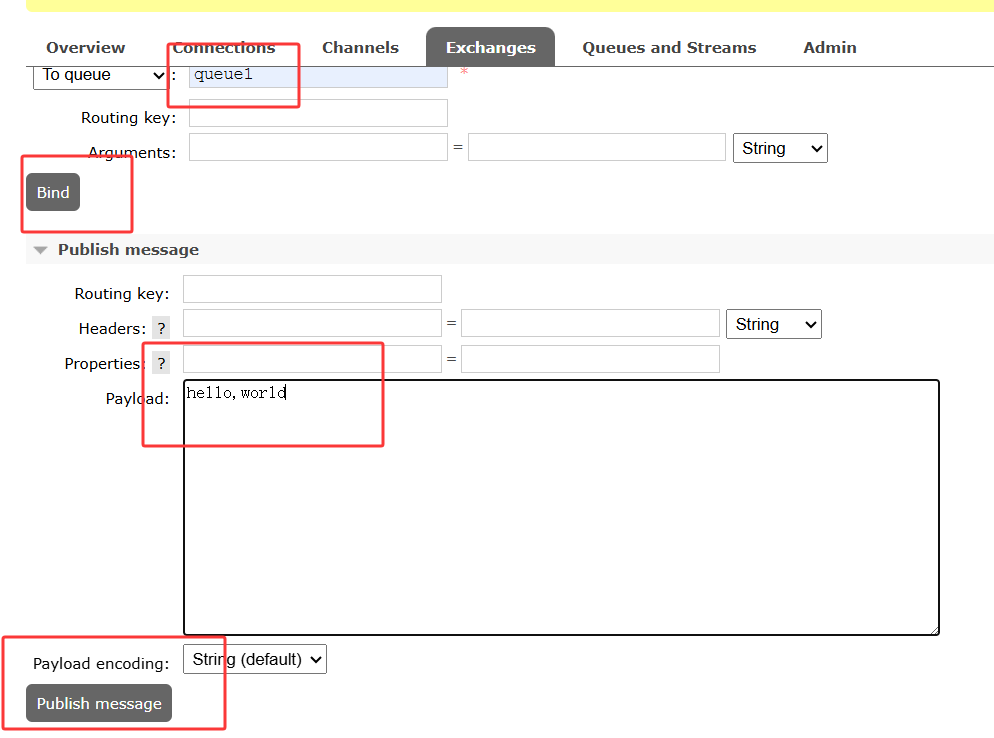
随后在队列中可获取信息
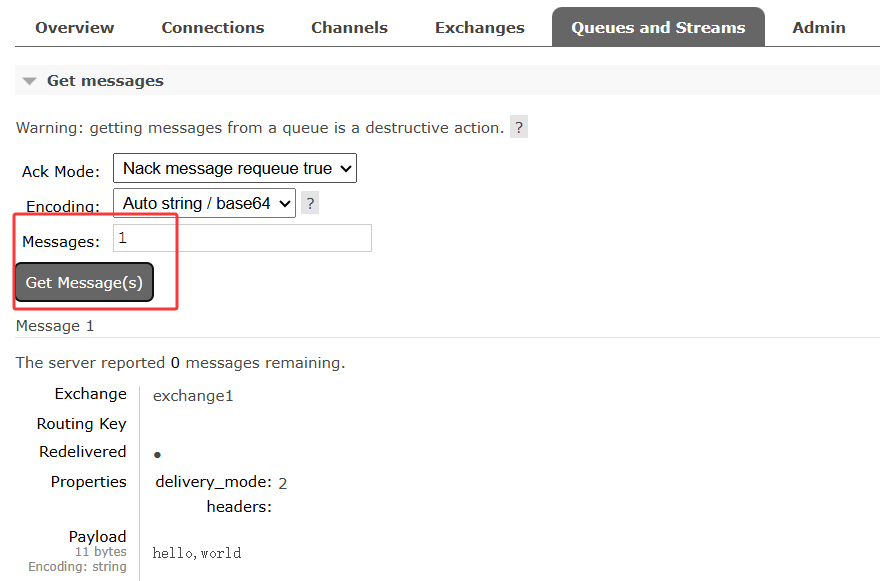
此外还可以在管理员界面新增用户与虚拟主机
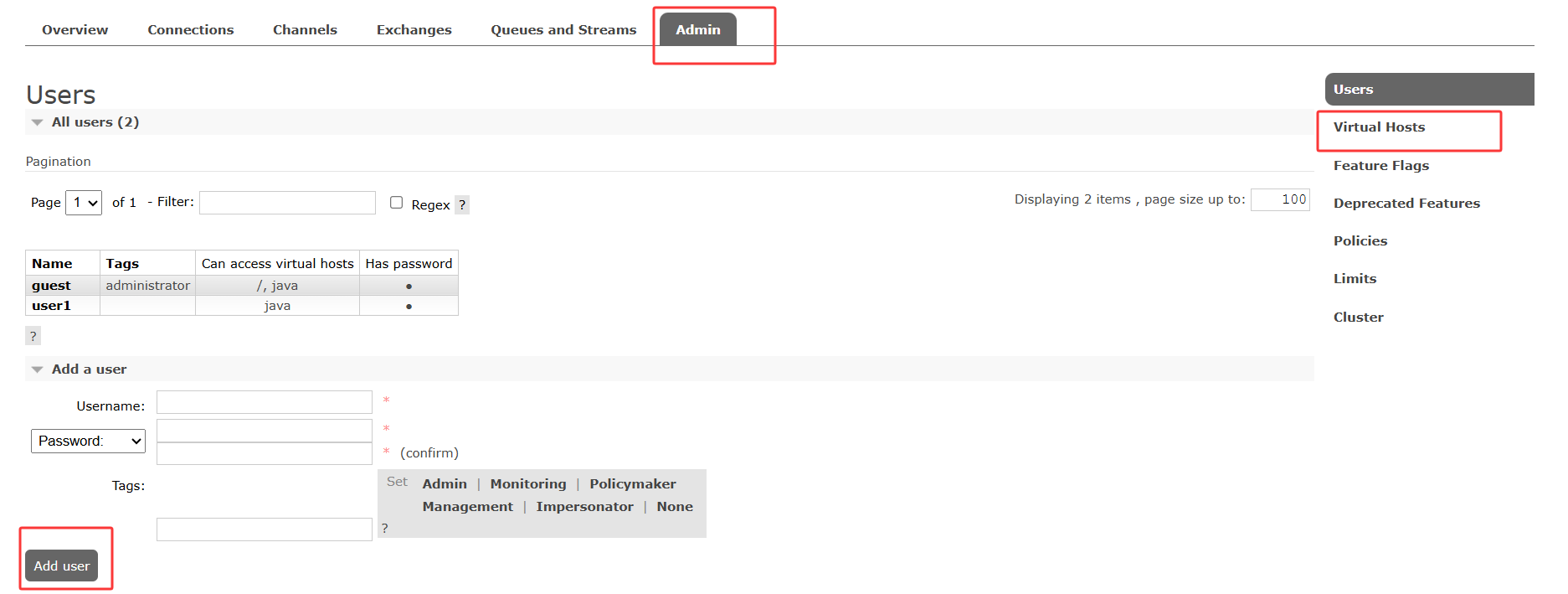
rabbitmq默认管理端口15672 ,默认消息监听端口5672 ,docker可通过运行指定修改端口等配置信息,Windows中可到C:\Users\用户名\AppData\Roaming\RabbitMQ下新建rabbitmq.conf,使用listeners.tcp.default = 15763 management.tcp.port = 15672修改端口等信息,重启服务生效。
Java客户端------Spring AMQP
AMQP是Advanced Message Queuing Protocol(高级消息队列协议),是一套跨语言、跨平台的通信协议标准;RabbitMQ是AMQP的具体实现,Spring AMQP对AMQP协议进行了抽象封装,并对RabbitMQ进行了适配,提供了更简单的调用方法。
官网给出的RabbitMQ的Java发送方法:
使用Spring AMQP 只需要
rabbitTemplate.convertAndSend(队列名,信息)
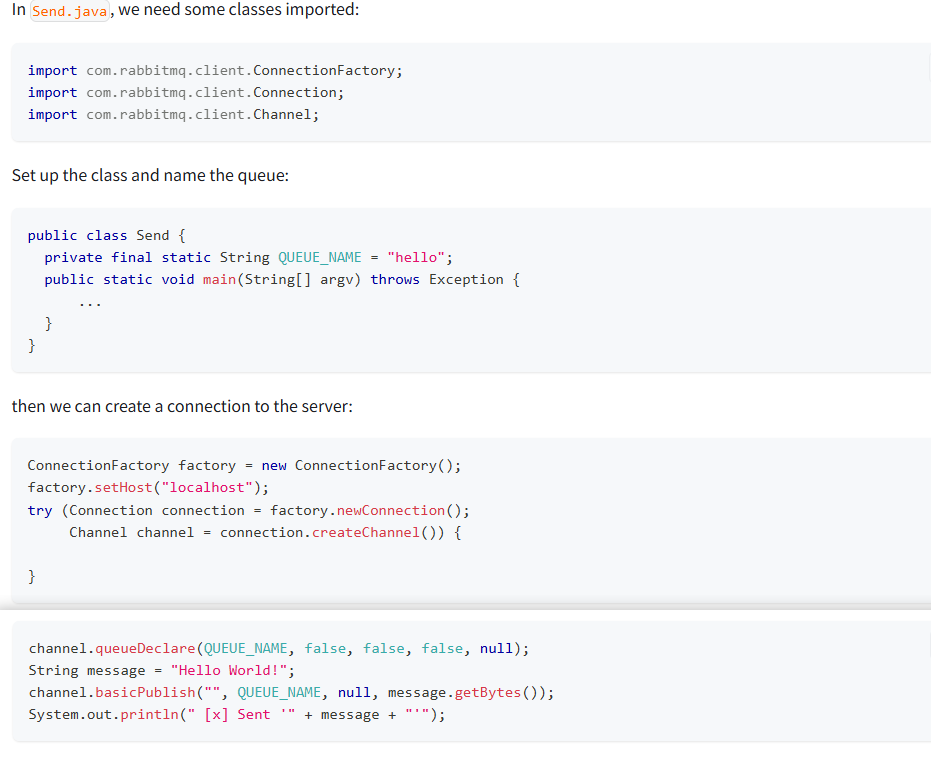
补充:AMQP就像python生成的diffusers库,整合各类生成模型,统一标准,为不同模型进行了简化适配。
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>配置连接参数
yml
spring:
rabbitmq:
host: localhost
port: 5672
virtual-host: java
username: user1
password: 123RabbitTemplate核心类
RabbitTemplate是 Spring AMQP 提供的一个核心工具类,用于简化RabbitMQ的操作,如发送、接收消息等。
简单使用实例如下:
java
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void rabbitTemplateTest() {
String message = "Hello World!";
String queueName = "queue1";
String exchangeName = "exchange1";
// 向队列发送消息
rabbitTemplate.convertAndSend(queueName,message);
// 向交换机发送消息
// rabbitTemplate.convertAndSend(exchangeName,message);
// 主动拉取消息
System.out.println("收到消息:"+rabbitTemplate.receiveAndConvert(queueName));
}
// 被动消费,后台监听,消息自动传到message参数中,message可以是任意类型
@RabbitListener(queues = "queue1")
String getMessage(String message) {
System.out.println("消费者收到消息"+message);
return message;
}消费模型------工作队列模型
工作队列模型是实际生产环境中最常用的一种消费模型,即多个消费者共享同一个队列,竞争消费信息,形成如下图的结构:
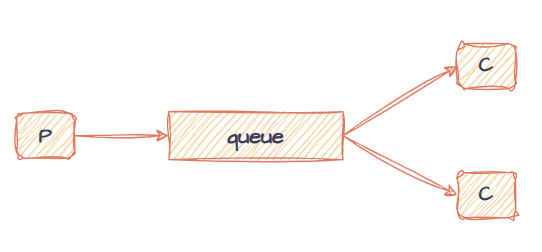
这种方式允许多个消费者并行处理消息,避免消息拥堵,提高并发性,但在消息原理中我们提到,队列的默认消息分发逻辑是轮询,也就是说消息会平均分配,当消费者处理能力不同时会导致资源浪费。
为了充分利用资源,可以采用预分配或应答策略,让消费者处理完数据后再从队列中获取消息。
预分配prefetch
Spring AMQP根据prefetch(预取数)限制一个信道下的单个消费者手中已推送但未确认(ACK)的消息最大数量(默认 prefetch=250),将该值设置为1后,消费者必须处理完当前消息并完成 ACK 确认,才能获取新消息,实现按执行效率分发,而非轮询分配。
yml
spring:
rabbitmq:
host: localhost
port: 5672
virtual-host: java
username: user1
password: 123
listener:
simple:
prefetch: 1路由模型
消费模型决定消息消费的策略,路由模型则决定生产交换机分发到队列的方法,二者任意组合成不同维度规则,共同构成 RabbitMQ 消息流转的完整逻辑。
根据分发策略不同,路由模型主要分为以下三种:
Fanout广播模型
Fanout采用广播策略,即消息会转发到每一个与之绑定的队列,适用于多个需要处理同样数据的微服务。
Spring AMQP提供声明交换机、队列及绑定关系的代码,不同模式只需创建不同的交换机实例即可,使用示例如下:
java
// 生产者
// 消息转发到交换机,路由键设为空
rabbitTemplate.convertAndSend(exchangeName, "", message);
// 消费者
// 声明 Fanout Exchange
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange("demo.fanout");
}
// 创建队列
@Bean
public Queue queue1() {
return new Queue("queue1");
}
// 创建交换机
@Bean
public FanoutExchange exchange1() {
return new FanoutExchange("exchange1");
}
@Bean
public Binding binding1(Queue queue1, FanoutExchange exchange1) {
return BindingBuilder.bind(queue1).to(exchange1);
}
@RabbitListener(queues = "queue1")
void getMessage(String message) {
System.out.println("消费者收到消息:"+message);
}Direct定向模型
定向模型可以将消息映射到指定的队列中,通过消息的Routing Key与队列的Binding Key匹配实现。
即消息发送时绑定routing key,交换机将其与队列映射规则的binding key进行比较,向符合规则的队列转发,可以实现消息的定向发布,示例图如下:
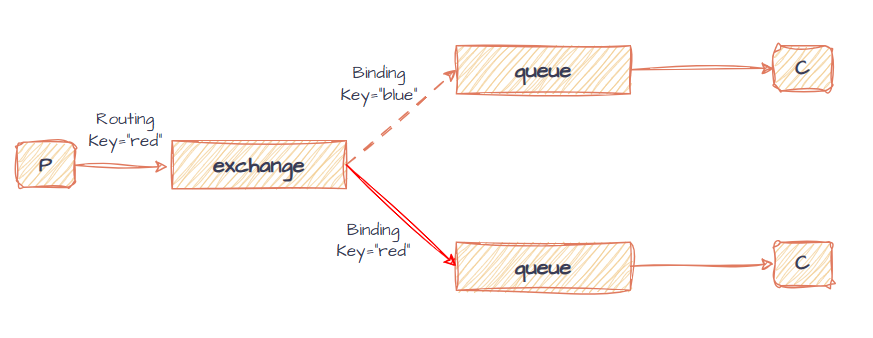
代码实现示例如下:
java
// 生产者只需绑定routing key,交换机自动完成后续转发
rabbitTemplate.convertAndSend(exchangeName, "red", message);
// 消费者可使用DirectExchange类型绑定队列,并确定匹配规则
@Bean
public DirectExchange exchange1() {
return new DirectExchange("exchange1");
}
@Bean
public Binding binding1(Queue queue1, DirectExchange exchange1) {
return BindingBuilder.bind(queue1).to(exchange1).with("blue");
}
// 也可以使用注解一次性配置完成
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "queue1"),
exchange=@Exchange(name = "exchange1",type = ExchangeTypes.DIRECT),
key={"blue"}
))
String getMessage(String message) {
System.out.println("消费者收到消息"+message);
return message;
} 注解一次性配置中,@QueueBinding用于声明绑定关系,value声明队列,exchange声明交换机,并设置映射规则Binding Key。
Topic话题模型
话题模型可以认为是更灵活的定向模型,Topic支持多个单词列表的Routing Key,单词通过.分割,匹配规则可以包括通配符,以实现特定话题的转发。
该模型下的消息发布示意图如下:
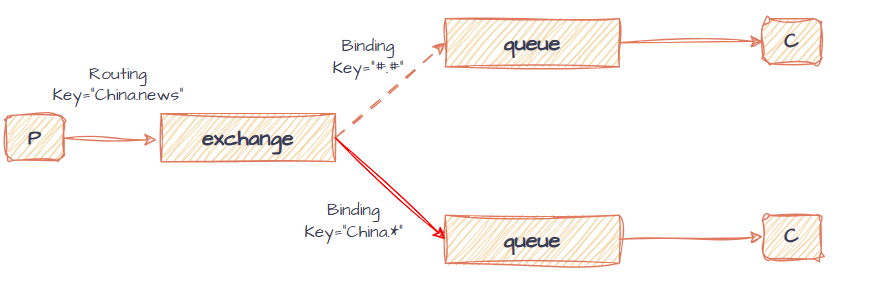
通配符中#表示0或多个单词,*表示一个单词,所以#.#可以表示接收任意类型的消息。
生产者只需在Routing Key中设置以.相连的多个单词,消费者更换路由模式,及Binding Key即可接收信息,使用示例如下:
java
// 生产者示例
rabbitTemplate.convertAndSend(exchangeName, "China.news", message);
// 消费者示例
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "queue1"),
exchange=@Exchange(name = "exchange1",type = ExchangeTypes.TOPIC),
key={"China.#"}
))
String getMessage(String message) {
System.out.println("消费者收到消息"+message);
return message;
}消息转换器
消息队列中的消息可以是任意类型,包括对象引用,但Spring AMQP底层默认使用JDK序列化,会导致引用类型可读性差,需要将序列化对象更换为更适合的Jackson。
引入jackson-databind依赖后,通过将消息转换器添加到容器中,覆盖原有方案,实现消息转换器的更换。
java
@Bean
public MessageConverter messageConverter(){
return new Jackson2JsonMessageConverter();
}有关该部分的详细介绍及代码,可见:基于 Spring AMQP 实现简单、工作队列模型,发布订阅模型
消息可靠性
RabbitMQ作为一个中间件,实现消息解耦的同时也带来了额外的运维开销,最主要的就是消息传递可靠性的保证问题。
从错误形式来说,可能有两种场景:
- 消息未送达。因为网络波动或服务宕机,导致消息在发送的一个环节出错,而最终未被接收。这种错误可以参考网络中的确认重传机制解决。
- 消息重复。确认重传带来的问题就是消息重复,单纯网络拥堵也可能导致时间窗口内未收到确认消息,这导致队列中有两条重复消息。
中间件连接生产者和消费者,从错误产生位置来说,可能出现在三个阶段:
- 生产者可靠性。生产者的消息是否正确到达MQ,比如网络丢包,MQ宕机等情况。
- MQ可靠性 。MQ接收到的消息是否被正确转发,如路由键
Routing Key错误配置。 - 消费者可靠性。消费者是否取到合规的消息,如消息格式不符,消费者自身程序问题等。
RabbitMQ主要针对这三个环节分别设计了可靠性方案。
生产者可靠性
生产者只负责向交换机发送数据,所以只需解决消息未送达问题,导致该问题的原因可能有两个:
- RabbitMQ连接失败。
- 网络问题。
RabbitMQ分别用重试机制 和确认机制解决该问题。
重试 是当RabbitMQ连接失败时自动重连的策略,可通过配置文件application.yml实现,文件中指定超时时间、失败后的初始等待时间、失败后的等待时间倍数和最大重连次数,示例如下:
yml
spring:
rabbitmq:
connection-timeout: 1s # 超时连接时间
template:
retry:
enabled: true # 开启重试
initial-interval: 1000ms # 初始等待时间
multiplier: 1 # 失败后下次等待时间的倍数
max-attempts: 3 # 最大重试次数要注意的是尝试时间是超时时间+初始等待时间*(n*等待时间倍数),如第一次尝试时间为1s+1000ms=2s。
另外该方案只能解决网络原因导致的连接失败,同时采用阻塞式重试,高性能要求的场景下可以关闭该机制。
确认 机制是MQ收到消息后返回处理状态给生产者的方法,告知其消息状态,返回类型分为Return和Confirm两种,具体场景如下:
- 消息到达MQ,但路由失败,Return异常原因,
Confirm返回ack(通常是路由与队列的映射关系出错) - 消息到达MQ并成功入队,返回
ack - 持久化消息入队,并持久化后,返回
ack - 其他情景都返回
nack
其中ack与nack属于Confirm,Return和nack都表示消息错误,只有ack单独出现才表示消息成功。
开启配置如下:
yml
spring:
rabbitmq:
publisher-confirm-type: correlated # 开启confirm机制,simple同步等待,correlated异步回调
publisher-returns: true # 开启return机制,返回路由失败信息代码层面每个rabbitTemplate只能配置一个ReturnsCallback用于处理Return信息,示例如下:
java
void testConnection() {
// 开启mandatory模式,将路由信息返回给生产者
rabbitTemplate.setMandatory(true);
// ReturnsCallback,用Lambda简化
rabbitTemplate.setReturnsCallback(returnedMessage -> {
// 匿名内部类获取关键信息,省略类型配置,可只写方法体
String exchange = returnedMessage.getExchange();
String routingKey = returnedMessage.getRoutingKey();
Message message = returnedMessage.getMessage();
int replyCode = returnedMessage.getReplyCode();
String replyText = returnedMessage.getReplyText(); // 补充获取错误描述
// 打印日志 + 记录失败消息
System.err.printf("消息路由失败!交换机:%s,路由键:%s,响应码:%d,错误信息:%s,消息体:%s%n",
exchange, routingKey, replyCode, replyText, new String(message.getBody()));
});
}而ConfirmCallBack回调因为消息逻辑不同,需要单独指定。具体流程为:在发送信息的convertAndSend方法中额外指定一个CorrelationData示例,用于处理回调信息。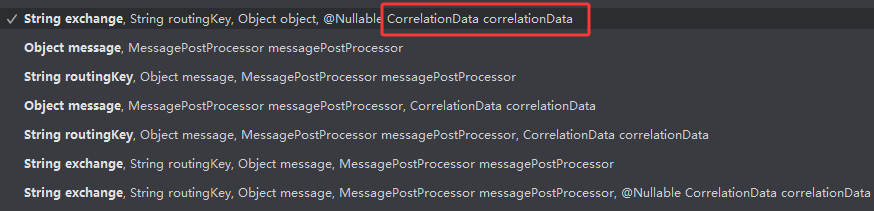
具体实例如下:
java
void Confirm(){
// 消息关联元数据对象,绑定消息与确认结果
// UUID.randomUUID().toString(),128位数字随机,工程上几乎保证唯一
CorrelationData correlationData=new CorrelationData(UUID.randomUUID().toString());
// 获取异步结果容器,增加回调方法
correlationData.getFuture().addCallback(new ListenableFutureCallback<CorrelationData.Confirm>() {
// 回调接口,监听执行结果
@Override
public void onFailure(Throwable ex) {
// onFailure代表获取信息失败,而不代表获取到失败信息
System.out.println("处理结果异常:"+ex.getMessage());
}
@Override
public void onSuccess(CorrelationData.Confirm result) {
if (result.isAck()){
System.out.println("消息处理成功");
}
else {
System.out.println("消息处理失败");
}
}
});
rabbitTemplate.convertAndSend("exchange1","red","message",correlationData);
}复杂的回调结构让我想起动态代理
实现一个增强方法类,通过被代理类、其接口以及增强类的字节码构建代理类
实现增强被代理类的方法,现在看起来好像也不涉及回调,只是几个反射的组合,不知道为什么这里想起动态代理,可能就是我当时觉得最复杂的结构了吧
生产者可靠性小总结
确认和重试都会影响性能,网络能正常连通的情况下内部路由不会出问题(除非配置错误),而如果是网络有问题则通常不是重试几次能解决的,特殊场景下开启,也推荐针对nack作有限重试即可。
MQ可靠性
MQ作为消息的暂存容器,其最大的不可靠因素就是存储层故障。如部署消息队列的服务器关机重启,解决这一问题的首要方案就是持久化。
MQ内部核心组件有两个:交换机和队列,Spring默认开启持久化,控制台内可通过Durable开启。
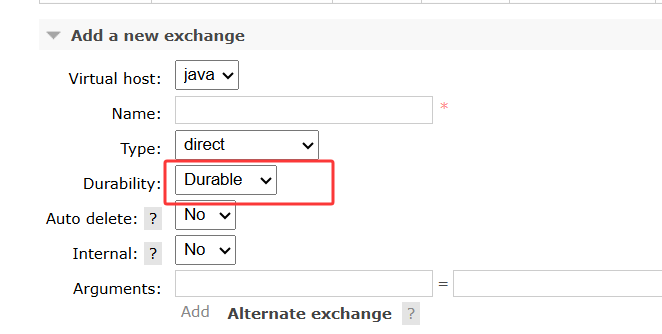
另一个增强队列可靠性的方案就是惰性队列Lazy Queue,原有方案当内存到水位线时会触发page out操作,即将先入队的消息换出到磁盘中。目的是压缩内存使用,让后续消息能正常入队,但该过程极大影响性能(会导致消息发送时出现剧烈波动,新RabbitMQ默认惰性队列,无法复现),基于该问题提出了惰性队列。
page out是将先入队且未被消费的消息换出到磁盘中(我还是觉得应该换出后入队的,没找到相关文档介绍),队列中只保留其索引,读到该消息再从磁盘中取出来。
惰性队列是将消息先持久化到磁盘,读取时再从磁盘恢复到内存中,这种方式的好处是:
- 持久化,先写入磁盘,保证消息可靠性,同时优化了写入操作,效率高于传统持久化。
- 避免阻塞,按需加载消息,减少内存占用,避免内存满触发的阻塞。
- 动态缓存解决读写瓶颈。当消费者处理速度较慢时完全按需加载,处理速度较快时会默认预加载2048条消息到内存,避免磁盘读取的瓶颈影响消费者的处理速度。
开启惰性队列的方法如下:
java
@Bean
public Queue getQueue() {
// 创建持久化的惰性队列
return QueueBuilder.durable("queue1").lazy().build();
}
// 注解一次性配置
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name="queue1",arguments = @Argument(name="x-queue-mode",value = "lazy")),
exchange = @Exchange(name = "exchange1",type = ExchangeTypes.TOPIC),
key = {"blue"}
))
String getMessage(String message) {
System.out.println("消费者收到消息"+message);
return message;
}持久化和惰性队列都是Spring和RabbitMQ新版本的默认配置,所以MQ可靠性这一块也不用我们操心。
消费者可靠性
消费者端也使用确认机制向MQ发送回执,以告知消息的处理状态,便于MQ删除或重传消息,回执有以下三种:
- ack,成功处理消息,MQ可删除队列中的消息
- nack,处理消息失败,MQ应再次投递消息
- reject,消息处理失败并拒绝,MQ应删除队列中的消息(通常是消息格式问题)
由于消息回执的场景比较固定,Spring AMQP为我们实现了自动确认,有以下三种配置模式:
- none,不处理回执,消费者收到消息自动发送
ack,MQ从队列中删除消息 - manual,开发者手动发送ack,更灵活
- auto,自动确认,Spring AOP环绕增强,业务正常时返回
ack,异常返回nack,消息转换异常时返回reject
消费者端配置方法如下:
yml
spring:
listener:
simple:
acknowledge-mode: auto回执为nack时MQ会重新投递,可当消费者自身问题无法正确处理时,MQ默认无限重入队会增加系统压力,所以失败重试机制也应作配置。
retry本地重试 :避免无限重新投递。当消费者执行错误时先不返回nack,而是使用本地重试(再次调用消费方法),重试次数大于配置值时直接返回reject拒绝,配置方式如下:
yml
spring:
listener:
direct:
retry:
enabled: true # 开启本地重试
initial-interval: 1000ms # 初始等待时长
multiplier: 1 # 失败的等待时长倍数
max-attempts: 3 # 最大重试次数
stateless: true # 无状态,有事务要求设置为有状态重试耗尽的消息处理策略(MessageRecover接口):本地重试方法默认将到达重试上限的消息直接丢弃,对于可靠性要求较高的场景不适用,应该单独设置策略处理这类消息。
处理策略通过MessageRecover接口实现,具体有三种不同的实现策略:
RejectAndDontRequeueRecoverer:默认策略,重试次数耗尽直接丢弃消息ImmediateRequeueMessageRecoverer:重试次数耗尽返回nack,消息重新入队,只是拖延了消息重试,并未解决问题RepublishMessageRecoverer:重试耗尽,将失败的消息发送到指定交换机(死信交换机),这种方式最优雅,真正的问题应该人工介入解决
创建消息处理策略的示例如下:
java
@Bean
public MessageRecoverer messageRecoverer(RabbitTemplate rabbitTemplate) {
// 绑定交换机和routing key
return new RepublishMessageRecoverer(rabbitTemplate,"error.exchange","error");
}这是RabbitMQ本地重试机制的兜底,将所有死信发送到指定交换机,与rabbitmq死信交换机不同。
rabbitmq死信交换机配置于队列,通过指定参数Dead letter exchange=exchange的方式实现死信转发。
业务幂等性
幂等性原本是数学定义,f(x)=f(f(x)),指重复运算仍等于其自身的方法,如|x|绝对值函数,在计算机中指同一个业务执行一次或多次对业务的影响一致,有些业务天然具有幂等性,如查询、删除,重复操作不会造成状态影响;而有些业务则影响极大,如下单、退款。
虽然我们从三个层面尽可能保证了消息的可靠性,业务幂等性 则是该保障体系下最后的兜底手段。
幂等性主要解决同一消息被多次处理导致业务出错的问题,第一个思路是把消息绑定唯一ID,处理消息时查库对比,已有记录直接丢弃。
可使用AMQP消息转换器的MessageID功能,以Jackson转换器为例,示例代码如下:
java
@Bean
public MessageConverter messageConverter(){
// 定义消息转换器
Jackson2JsonMessageConverter jjmc = new Jackson2JsonMessageConverter();
// 配置自动创建消息id
jjmc.setCreateMessageIds(true);
return jjmc;
}幂等性的其他保证方法可见:业务幂等性设计的六种方案
延迟队列
现有队列是生产后消费者立即取出,取出时间取决于消费者的处理能力,有些场景下我们可能希望消费者在指定间隔后再处理,如:
- 订单创建30分钟后未支付自动删除;
- 收货三天自动确认;
- 发车半小时前提醒乘客
数据量较大的场景下定时任务轮询会给数据库带来极大压力,此时就需要用到延迟队列。
死信交换机
消费者可靠性中我们提到,异常的消息通常设置转发到特定交换机,来让人工介入处理,这个特定交换机我们称为死信交换机。
死信,也就是需要人工处理的消息有以下三类:
- 消费者返回reject或nack声明消费失败的消息,并且参数requeue设置为false;
- 超时无人消费的过期消息
- 队列已满时,早期消息可能成为死信
我们同样可以利用该机制实现延迟队列,给消息设置过期时间,发送到无消费者监听的队列,绑定死信交换机后,超时自动转发到死信交换机。
死信交换机实现延迟队列结构如下:
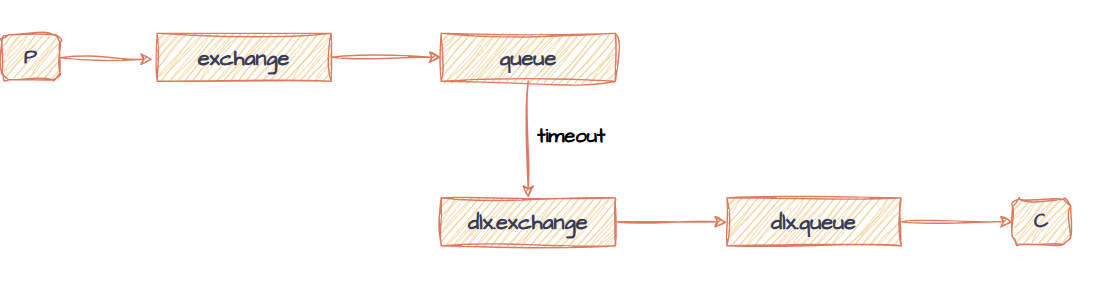
这种方式能实现需求,复用性也强,但从开发者角度来说,除了死信交换机和队列以外,还要额外部署一个暂存消息的队列,配置复杂,所以生产中通常使用延迟插件。
延迟插件
插件发布地址:https://www.rabbitmq.com/community-plugins
搜索要下载的插件delay后点击release可见如下页面:
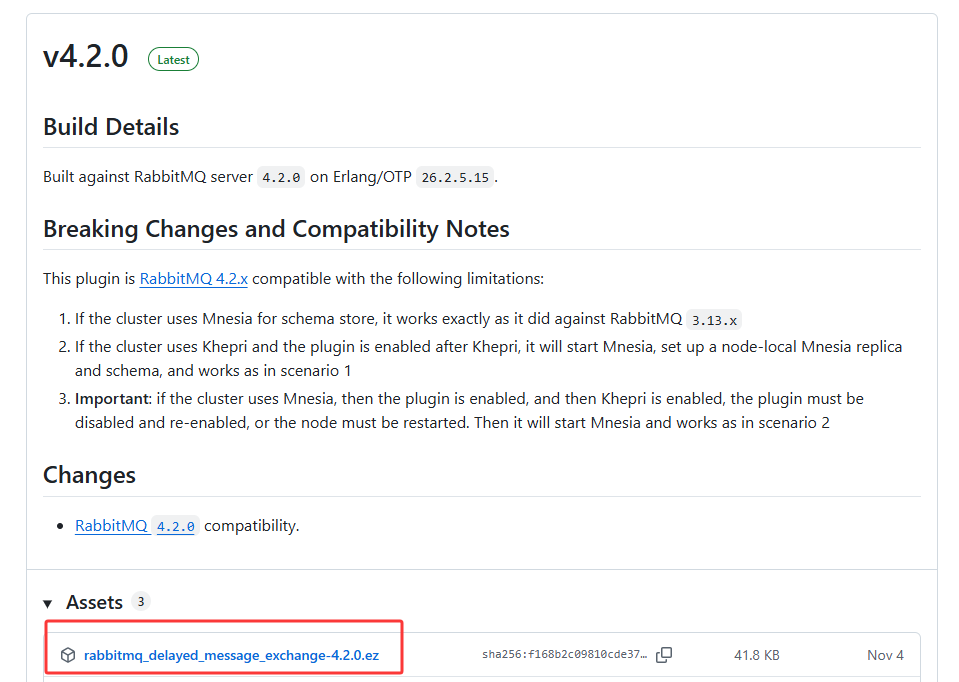
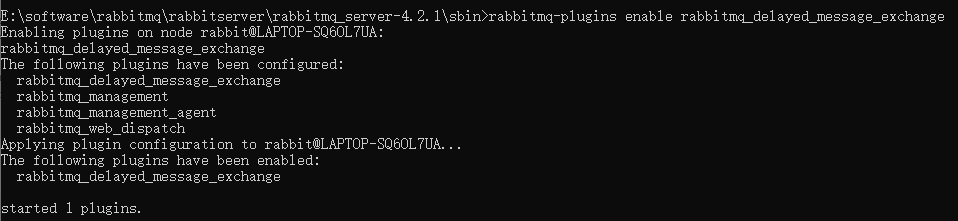
文件复制到安装目录的\plugins下,Windows切换到sbin目录打开cmd,Linux直接执行rabbitmq-plugins enable rabbitmq_delayed_message_exchange启用插件,出现如下界面说明启用成功。
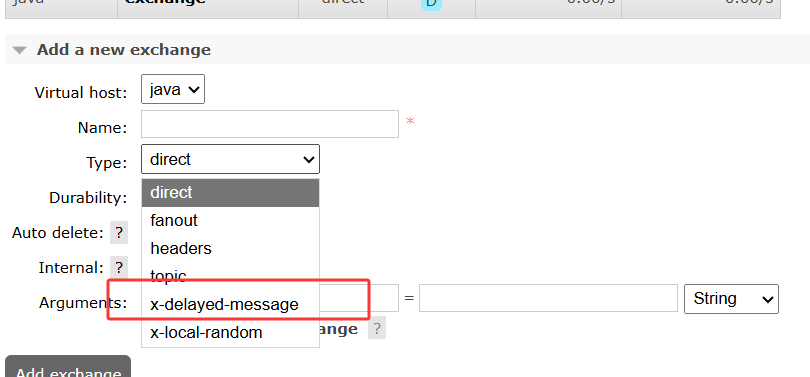
创建延迟交换机的方法如下:
java
@Bean
public DirectExchange exchange1() {
return ExchangeBuilder.directExchange("delay.direct").delayed() // 设置延迟属性
.build();
}
@RabbitListener(bindings=@QueueBinding(
value = @Queue(name="delay.queue"),
exchange = @Exchange(name="delay.direct",delayed = "true"),
key = "delay"
))
void getDelayMessage(String message) {
System.out.println("获取到延迟消息"+message);
}发送消息需要配置延迟时间,通过MessagePostProcessor类实现,实际项目中可将该类独立出来,发送延迟消息示例代码如下:
java
String message="delay message";
// 向队列发送消息
String exchange="delay.direct";
rabbitTemplate.convertAndSend(exchange, "delay", message, new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
// 设置超时时间
message.getMessageProperties().setDelay(10000);
return message;
}
});总结
花了四天时间补了个后端技术栈,用下面一张图就能概括了。
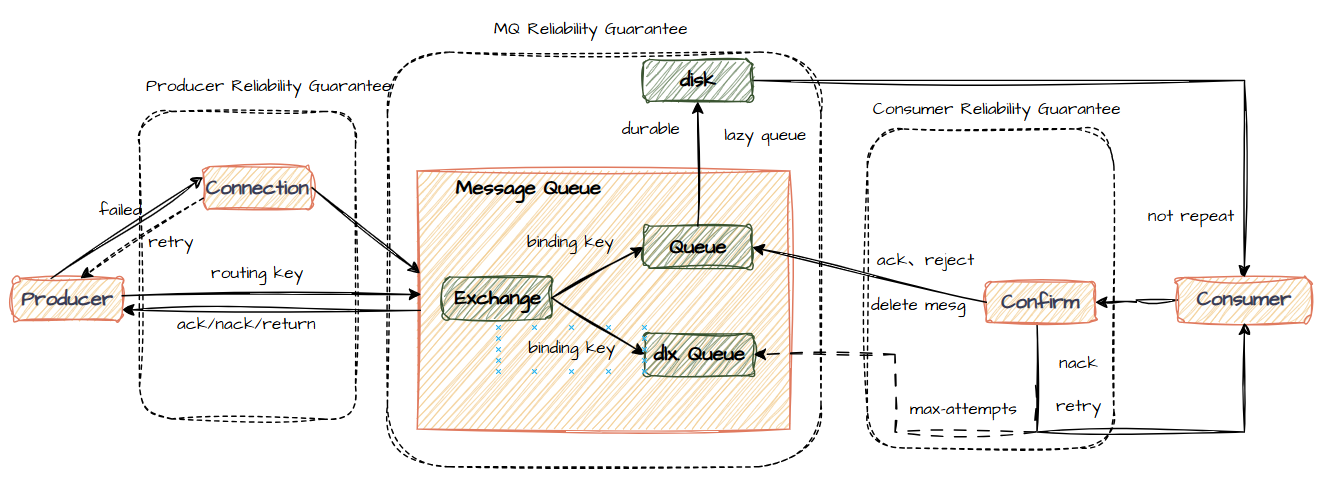
相比远程调用,消息队列的意义可以简要概括为解耦与缓存
而由于引入了中间件,该中间件的可用性又需要分三个层次保证:
生产者端 几乎不会出现问题,重试重连解决不了基本就没办法了,通常不用管;
MQ 通过持久化来保证数据可用,现有持久化及队列方案都是默认的,也不用配置;
消费者端 Spring也提供了自动应答机制,唯一要处理的就是指定重试上限消息转发的死信交换机,让人工介入。