作者简介:华为HCIP,昇腾NPU机构专业用户。

一.引言
书接前文https://blog.csdn.net/kkiron/article/details/155788771在项目里落地了 CodeLlama-7B 模型,直接跑在昇腾 NPU 上,一路踩坑过来,总算摸出了一套可行的方案。不得不说 CodeLlama 的代码生成能力是真的顶,日常写业务代码、调接口都能省不少事,而昇腾 NPU 的算力也完全 hold 住,推理起来丝毫不吃力。
不过部署过程是真得 "折腾"------ 从最开始搭环境,到后面调优性能,中间踩了不少坑。比如模型格式转换时卡了半天,内存占用一度超标,推理速度也达不到预期,好在最后都一一解决。
这篇文章是在上一篇跑CodeLlama-7B 模型基础上,从环境配置、模型适配,到性能优化和常见问题排查基础上,对llava-1.5-7b-hf模型进行了测试,因为有上一次经验打底,这次体验效果更佳。希望能给同样想在昇腾 NPU 上跑Llama-7B-hf 一个快速上手指导。
二.环境搭建和基本配置
1. 测试平台选择
为什么选择GitCode?
1.主国内部署 + 访问 / 克隆速度快,支持 GitHub 加速同步;
2.基础协作 + 项目管理 + CI/CD+WebIDE,适配个人到企业级需求;
3.开源扶持 + CSDN 生态打通,助力技术影响力沉淀;
4.全中文界面 + 本土化文档 / 支持,契合国内使用习惯;
5.多副本存储 + 无损迁移,数据安全可靠
2.平台操作流程
进入GitCode页面
之后选择我的Notebook

在NoteBook资源确认 界面选择NPU配置并立即启动
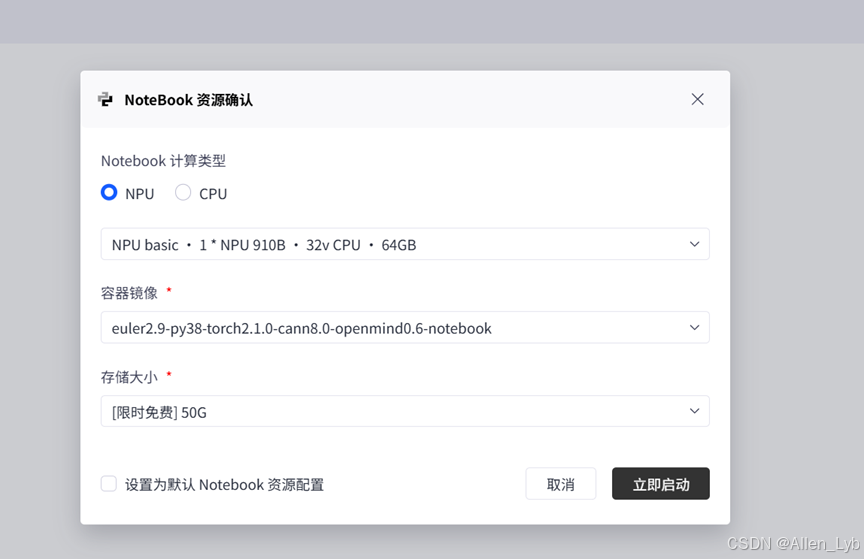
配置信息:
|----------|-------------------------------------------------------|
| 计算类型 | NPU (昇腾 910B) |
| 硬件规格 | 1 * NPU 910B + 32 vCPU + 64GB 内存 |
| 操作系统 | EulerOS 2.9 (华为自研的服务器操作系统,针对昇腾硬件深度优化) |
| 存储 | 50GB (限时免费,对模型推理和代码调试完全够用) |
| 镜像名称 | euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook |
选择立即启动

启动成功后就是下图所示

3.模型大厅搜索llava
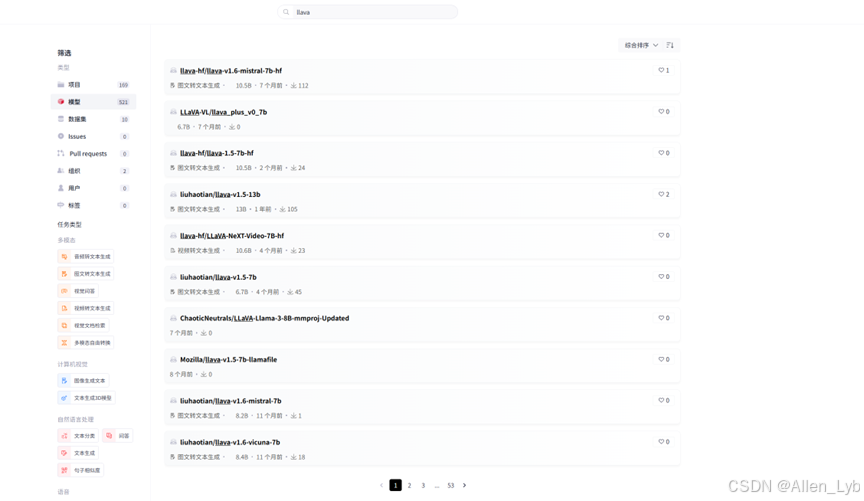
4.注意本次选择的是 llava-hf/llava-1.5-7b-h
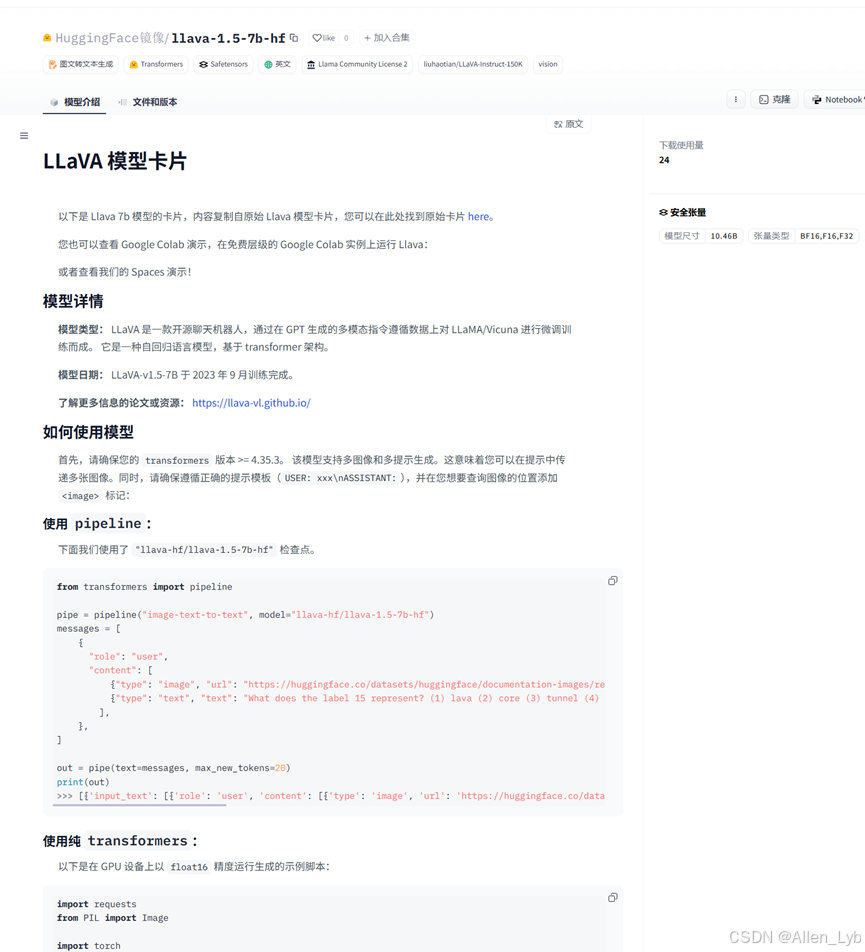
5.环境的安装
安装TensorFlow
bash
pip install transformers accelerate -i https://mirrors.aliyun.com/pypi/simple/这里使用国内的镜像下载快一点,如果还不行可以使用华为镜像试试。
下载成功之后我们把测试代码复制进去。新建一个测试文件,右键新建文件并修改后缀名为.py格式。

测试代码:
bash
import requests
from PIL import Image
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration
model_id = "llava-hf/llava-1.5-7b-hf"
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(0)
processor = AutoProcessor.from_pretrained(model_id)
# Define a chat history and use `apply_chat_template` to get correctly formatted prompt
# Each value in "content" has to be a list of dicts with types ("text", "image")
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "What are these?"},
{"type": "image"},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(images=raw_image, text=prompt, return_tensors='pt').to(0, torch.float16)
output = model.generate(**inputs, max_new_tokens=200, do_sample=False)
print(processor.decode(output[0][2:], skip_special_tokens=True))命令行执行测试一下:python test.py报错了,错误原因:昇腾NPU环境使用torch_npu而非CUDA,.to(0)不适用。检查并修复代码以适配昇腾NPU
还有一个地方:大家可以改一下镜像,不然加载太慢了
方法一:
import os
os.environ'HF_ENDPOINT' = 'https://hf-mirror.com'
print("已设置镜像站点")
方法二:
export HF_ENDPOINT=https://hf-mirror.com
修改代码:
bash
import os
import requests
from PIL import Image
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration, LlamaTokenizer
from transformers.image_utils import load_image
# 设置HuggingFace镜像(国内网络需要)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
model_id = "llava-hf/llava-1.5-7b-hf"
print("正在加载模型...")
# 昇腾NPU环境使用device_map="auto"自动分配设备,不要用.to(0)
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto", # 自动检测并使用NPU
)
print("正在加载processor...")
# 如果fast tokenizer加载失败,尝试使用slow tokenizer
try:
# 先尝试使用fast tokenizer
processor = AutoProcessor.from_pretrained(model_id)
print("使用fast tokenizer加载成功")
except Exception as e:
print(f"Fast tokenizer加载失败: {e}")
print("尝试使用slow tokenizer手动构建processor...")
# 手动构建processor,使用slow tokenizer
from transformers import CLIPImageProcessor
try:
tokenizer = LlamaTokenizer.from_pretrained(model_id, use_fast=False)
image_processor = CLIPImageProcessor.from_pretrained(model_id)
# 手动创建processor
class CustomProcessor:
def __init__(self, tokenizer, image_processor):
self.tokenizer = tokenizer
self.image_processor = image_processor
# 检查是否有图像token
self.image_token = "<image>"
# 尝试添加图像token到tokenizer(如果不存在)
if self.image_token not in tokenizer.get_vocab():
tokenizer.add_tokens([self.image_token], special_tokens=True)
def apply_chat_template(self, conversation, add_generation_prompt=True):
# LLaVA-1.5的chat template实现
# 需要在文本中插入<image>占位符
text = ""
for msg in conversation:
if msg["role"] == "user":
for content in msg["content"]:
if content["type"] == "text":
text += content["text"]
elif content["type"] == "image":
# 插入图像占位符,LLaVA-1.5使用<image>
# 确保前后有空格,这样tokenizer能正确识别
text += " " + self.image_token + " "
if add_generation_prompt:
text += "\nASSISTANT:"
return text
def __call__(self, images=None, text=None, return_tensors='pt'):
# 处理文本
text_inputs = self.tokenizer(text, return_tensors=return_tensors)
# 处理图片
if images is not None:
if not isinstance(images, list):
images = [images]
pixel_values = self.image_processor(images, return_tensors=return_tensors)['pixel_values']
return {
**text_inputs,
'pixel_values': pixel_values,
# 注意:不返回'images',因为模型不需要这个参数
}
return text_inputs
def decode(self, token_ids, skip_special_tokens=True):
return self.tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
processor = CustomProcessor(tokenizer, image_processor)
print("使用slow tokenizer手动构建processor成功")
except Exception as e2:
print(f"手动构建processor也失败: {e2}")
print("尝试清理缓存后重新下载...")
# 清理tokenizer缓存
import shutil
cache_dir = os.path.expanduser("~/.cache/huggingface/hub")
tokenizer_cache = os.path.join(cache_dir, f"models--{model_id.replace('/', '--')}")
if os.path.exists(tokenizer_cache):
print(f"清理缓存: {tokenizer_cache}")
shutil.rmtree(tokenizer_cache, ignore_errors=True)
# 重新尝试加载
processor = AutoProcessor.from_pretrained(model_id, force_download=True)
print("强制重新下载后加载成功")
print("模型和processor加载完成")
# 使用conversation格式处理多模态输入
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "What are these?"},
{"type": "image"},
],
},
]
# 应用chat template
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
# 下载并处理图片
image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
# 使用processor处理图片和文本
inputs = processor(images=raw_image, text=prompt, return_tensors='pt')
# 将输入移到模型所在的设备,使用device_map时模型会自动处理设备
if hasattr(model, 'device'):
inputs = {k: v.to(model.device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
else:
# 如果没有device属性,尝试使用第一个参数所在的设备
inputs = {k: v.to(next(model.parameters()).device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
# 确保数据类型正确
inputs = {k: v.to(torch.float16) if isinstance(v, torch.Tensor) and v.dtype == torch.float32 else v for k, v in inputs.items()}
# 过滤掉模型不需要的参数(如images),只保留模型需要的参数
model_inputs = {k: v for k, v in inputs.items() if k not in ['images']}
print("开始生成...")
output = model.generate(**model_inputs, max_new_tokens=200, do_sample=False)
print(processor.decode(output[0][2:], skip_special_tokens=True))查看执行结果
我们先看看执行之前的测试图片链接:http://images.cocodataset.org/val2017/000000039769.jpg

输出结果:
The image features two cats lying on a pink couch. One cat is located on the left side of the couch, while the other cat is on the right side. Both cats are sleeping peacefully, enjoying the comfortable environment.
In the scene, there are also two remote controls placed on the couch, one near the left cat and the other near the right cat. These remotes might be used for entertainment purposes, such as watching television or playing video games.
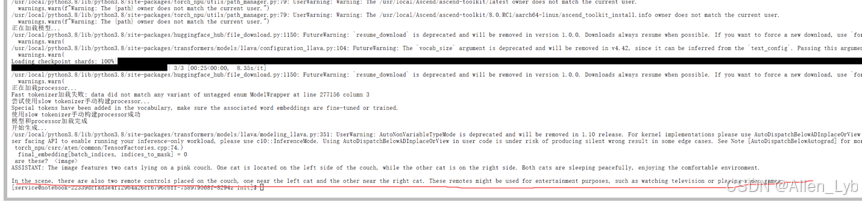
模型最终输出了正确的图片描述(两只猫、粉色沙发、遥控器等),说明昇腾 NPU 环境适配、模型加载、推理逻辑均已打通,核心功能正常。
下载模型注意事项:
- 存储空间 - LLaVA-1.5-7B模型大约14GB,确保有足够空间。
- 下载时间 - 即使用了镜像,14GB的模型下载也需要10-20分钟,取决于网络速度。
- 断点续传 - transformers库支持断点续传,如果中途断了,重新运行会自动从断点继续。
问题1:生成的内容被截断
现象: 生成的回答在中间突然停止。
解决方法:
- 增加max_new_tokens参数,但要注意内存限制
- 检查是否触发了eos_token(结束标记)
- 如果是因为内存不足导致的截断,先解决内存问题
问题2:Tokenizer加载错误(ModelWrapper错误)
现象: 提示"data did not match any variant of untagged enum ModelWrapper"或类似的tokenizer加载错误。
原因: 这通常是tokenizer文件损坏、下载不完整,或者transformers版本与tokenizer文件版本不匹配导致的。
解决方法:
-
使用slow tokenizer - 如果fast tokenizer加载失败,可以手动使用slow tokenizer:
pythonfrom transformers import LlamaTokenizer, CLIPImageProcessor tokenizer = LlamaTokenizer.from_pretrained(model_id, use_fast=False) image_processor = CLIPImageProcessor.from_pretrained(model_id) # 然后手动构建processor -
清理缓存重新下载 - 删除tokenizer缓存文件,强制重新下载:
bashrm -rf ~/.cache/huggingface/hub/models--llava-hf--llava-1.5-7b-hf -
使用force_download - 在加载时强制重新下载:
pythonprocessor = AutoProcessor.from_pretrained(model_id, force_download=True) -
检查transformers版本 - 确保transformers版本兼容,建议使用4.35.0或更高版本:
bashpip install transformers>=4.35.0 -i https://mirrors.aliyun.com/pypi/simple/
问题3:模型生成时参数错误(images参数)
现象: 提示"The following model_kwargs are not used by the model: 'images'"。
原因: processor处理图片时会返回images键,但model.generate()不需要这个参数,只需要pixel_values、input_ids等。
解决方法:
在调用model.generate()之前,过滤掉images键:
python
# 过滤掉模型不需要的参数
model_inputs = {k: v for k, v in inputs.items() if k not in ['images']}
output = model.generate(**model_inputs, max_new_tokens=200, do_sample=False)问题4:图像token数量不匹配错误
现象: 提示"The number of image tokens is 0 while the number of image given to the model is 1"。
原因: LLaVA模型需要在input_ids中有图像占位符token(通常是<image>),这样模型才知道在哪里插入图像特征。如果chat template没有正确处理图像,就不会在文本中插入图像token。
解决方法:
-
使用AutoProcessor(推荐) - 如果AutoProcessor加载成功,它会自动处理图像token,不需要手动处理。
-
手动处理图像token - 如果使用CustomProcessor,需要在chat template中插入
<image>占位符:pythondef apply_chat_template(self, conversation, add_generation_prompt=True): text = "" for msg in conversation: if msg["role"] == "user": for content in msg["content"]: if content["type"] == "text": text += content["text"] elif content["type"] == "image": text += " <image> " # 插入图像占位符 if add_generation_prompt: text += "\nASSISTANT:" return text -
确保图像token存在 - 如果tokenizer中没有
<image>token,需要添加:pythonif "<image>" not in tokenizer.get_vocab(): tokenizer.add_tokens(["<image>"], special_tokens=True)
问题5:多模态输入格式错误
现象: 提示输入格式不正确。
解决方法:
- 确保使用
apply_chat_template格式化输入 - 图片和文本的顺序要正确:先文本后图片,或者按conversation格式
三.全维度性能测试
测试说明:
我们设计了6个测试场景,全面评估LLaVA在不同应用场景下的表现。每个测试都包含多个测试用例,记录生成时间、Token数量、生成速度等性能指标,同时评估输出质量。
测试前的准备工作:
- 确保模型已加载 - 第一次运行会下载模型,后续运行会从缓存加载,速度快很多。
- 检查内存使用 - 可以用
free -h命令查看内存占用,确保有足够空间。 - 准备测试图片 - 部分测试需要图片输入,确保网络可以访问测试图片URL,或者准备本地图片。
- 保存工作 - 测试脚本运行时间较长,建议先保存当前工作,避免意外中断。
测试执行建议:
- 每个测试脚本独立运行,不要一次性跑完所有测试,避免内存溢出
- 测试结果会自动保存为JSON文件,方便后续分析
- 如果某个测试卡住不动,可能是内存不足,可以重启Notebook后单独运行该测试
- 多模态测试需要下载图片,确保网络畅通
- `测试1: 行业术语准确性测试
测试LLaVA在医疗、教育、工业等领域的专业术语理解能力
bash
"""
测试1: 行业术语准确性测试
测试LLaVA在医疗、教育、工业等领域的专业术语理解能力
"""
import os
import time
import json
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration
# 设置HuggingFace镜像(国内网络需要)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
model_id = "llava-hf/llava-1.5-7b-hf"
print("正在加载模型...")
# 昇腾NPU环境使用device_map="auto"自动分配设备
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto", # 自动检测并使用NPU
)
processor = AutoProcessor.from_pretrained(model_id)
print("模型加载完成")
# 测试用例:不同行业的专业术语理解
test_cases = [
{
"id": 1,
"industry": "医疗",
"prompt": "请用专业且通俗的语言解释医学上'CAR-T疗法'的原理,包括它的工作机制和临床应用。",
"expected_keywords": ["CAR-T", "T细胞", "嵌合抗原受体", "免疫治疗", "肿瘤"],
"description": "医疗术语理解 - CAR-T疗法"
},
{
"id": 2,
"industry": "金融",
"prompt": "分析2025年A股新能源行业的投资逻辑,包括行业趋势、政策影响和风险因素。",
"expected_keywords": ["新能源", "A股", "投资逻辑", "政策", "风险"],
"description": "金融行业分析 - 新能源投资"
},
{
"industry": "工业",
"id": 3,
"prompt": "解释工业4.0的核心概念,包括智能制造、物联网和数字孪生技术在其中的作用。",
"expected_keywords": ["工业4.0", "智能制造", "物联网", "数字孪生", "数字化转型"],
"description": "工业术语理解 - 工业4.0"
},
{
"id": 4,
"industry": "教育",
"prompt": "解释'建构主义学习理论'的核心观点,以及它在现代教育实践中的应用。",
"expected_keywords": ["建构主义", "学习理论", "主动建构", "教育实践", "认知"],
"description": "教育术语理解 - 建构主义"
},
{
"id": 5,
"industry": "法律",
"prompt": "解释'不可抗力'这一法律概念,包括其构成要件和在合同纠纷中的适用。",
"expected_keywords": ["不可抗力", "法律概念", "构成要件", "合同", "免责"],
"description": "法律术语理解 - 不可抗力"
}
]
results = []
print("=" * 60)
print("测试1: 行业术语准确性测试")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
print(f"行业: {test_case['industry']}")
print(f"提示词: {test_case['prompt']}")
# 构建对话格式(纯文本,无图片)
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": test_case['prompt']},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
inputs = processor(text=prompt, return_tensors='pt')
# 将输入移到模型所在的设备
if hasattr(model, 'device'):
inputs = {k: v.to(model.device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
else:
inputs = {k: v.to(next(model.parameters()).device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
# 确保数据类型正确
inputs = {k: v.to(torch.float16) if isinstance(v, torch.Tensor) and v.dtype == torch.float32 else v for k, v in inputs.items()}
start_time = time.time()
output = model.generate(
**inputs,
max_new_tokens=300,
do_sample=True,
temperature=0.3,
top_p=0.95,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = processor.decode(output[0][2:], skip_special_tokens=True)
# 计算token数量
input_tokens = len(processor.tokenizer.encode(prompt))
output_tokens = len(processor.tokenizer.encode(generated_text)) - input_tokens
# 检查关键词匹配
generated_lower = generated_text.lower()
keywords_found = sum(1 for keyword in test_case['expected_keywords']
if keyword.lower() in generated_lower)
keyword_score = (keywords_found / len(test_case['expected_keywords'])) * 100
# 检查专业术语使用
has_technical_terms = any(word in generated_text for word in ["原理", "机制", "应用", "概念", "理论"])
has_explanation = len(generated_text) > 100
result = {
"test_id": test_case['id'],
"industry": test_case['industry'],
"description": test_case['description'],
"prompt": test_case['prompt'],
"generated_text": generated_text,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"keyword_score": round(keyword_score, 2),
"keywords_found": keywords_found,
"total_keywords": len(test_case['expected_keywords']),
"has_technical_terms": has_technical_terms,
"has_explanation": has_explanation,
"text_length": len(generated_text)
}
results.append(result)
print(f"生成时间: {generation_time:.3f}秒")
print(f"输出Token数: {output_tokens}")
print(f"生成速度: {result['tokens_per_second']:.2f} tokens/秒")
print(f"关键词匹配率: {keyword_score:.2f}% ({keywords_found}/{len(test_case['expected_keywords'])})")
print(f"\n生成的回答:\n{generated_text}")
print("-" * 60)
# 保存结果
with open("results_test1_industry_terminology.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
# 统计摘要
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
print("\n" + "=" * 60)
print("测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均输出Token数: {avg_tokens:.0f}")
print(f"平均生成速度: {avg_speed:.2f} tokens/秒")
print(f"平均关键词匹配率: {avg_keyword_score:.2f}%")
print(f"包含专业术语的用例: {sum(1 for r in results if r['has_technical_terms'])}/{len(results)}")
print(f"\n所有结果已保存到: results_test1_industry_terminology.json")运行出现报错了
1.添加 tokenizer 加载的错误处理
如果 fast tokenizer 加载失败,自动切换到 slow tokenizer
手动构建 CustomProcessor 作为备选方案
- 添加异常处理
每个测试用例用 try-except 包裹
单个用例失败不会中断整个测试
记录错误信息到结果中
- 改进了参数处理
过滤掉模型不需要的参数(如 images)
确保只传递模型需要的参数给 model.generate()
修改后代码:
bash
"""
测试1: 行业术语准确性测试
测试LLaVA在医疗、教育、工业等领域的专业术语理解能力
"""
import os
import time
import json
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration, LlamaTokenizer
# 设置HuggingFace镜像(国内网络需要)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
model_id = "llava-hf/llava-1.5-7b-hf"
print("正在加载模型...")
# 昇腾NPU环境使用device_map="auto"自动分配设备
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto", # 自动检测并使用NPU
)
print("正在加载processor...")
# 如果fast tokenizer加载失败,尝试使用slow tokenizer
try:
processor = AutoProcessor.from_pretrained(model_id)
print("使用fast tokenizer加载成功")
except Exception as e:
print(f"Fast tokenizer加载失败: {e}")
print("尝试使用slow tokenizer手动构建processor...")
from transformers import CLIPImageProcessor
try:
tokenizer = LlamaTokenizer.from_pretrained(model_id, use_fast=False)
image_processor = CLIPImageProcessor.from_pretrained(model_id)
# 手动创建processor
class CustomProcessor:
def __init__(self, tokenizer, image_processor):
self.tokenizer = tokenizer
self.image_processor = image_processor
def apply_chat_template(self, conversation, add_generation_prompt=True):
text = ""
for msg in conversation:
if msg["role"] == "user":
for content in msg["content"]:
if content["type"] == "text":
text += content["text"]
if add_generation_prompt:
text += "\nASSISTANT:"
return text
def __call__(self, images=None, text=None, return_tensors='pt'):
text_inputs = self.tokenizer(text, return_tensors=return_tensors)
if images is not None:
if not isinstance(images, list):
images = [images]
pixel_values = self.image_processor(images, return_tensors=return_tensors)['pixel_values']
return {
**text_inputs,
'pixel_values': pixel_values,
}
return text_inputs
def decode(self, token_ids, skip_special_tokens=True):
return self.tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
processor = CustomProcessor(tokenizer, image_processor)
print("使用slow tokenizer手动构建processor成功")
except Exception as e2:
print(f"手动构建processor也失败: {e2}")
raise
print("模型和processor加载完成")
# 测试用例:不同行业的专业术语理解
test_cases = [
{
"id": 1,
"industry": "医疗",
"prompt": "请用专业且通俗的语言解释医学上'CAR-T疗法'的原理,包括它的工作机制和临床应用。",
"expected_keywords": ["CAR-T", "T细胞", "嵌合抗原受体", "免疫治疗", "肿瘤"],
"description": "医疗术语理解 - CAR-T疗法"
},
{
"id": 2,
"industry": "金融",
"prompt": "分析2025年A股新能源行业的投资逻辑,包括行业趋势、政策影响和风险因素。",
"expected_keywords": ["新能源", "A股", "投资逻辑", "政策", "风险"],
"description": "金融行业分析 - 新能源投资"
},
{
"industry": "工业",
"id": 3,
"prompt": "解释工业4.0的核心概念,包括智能制造、物联网和数字孪生技术在其中的作用。",
"expected_keywords": ["工业4.0", "智能制造", "物联网", "数字孪生", "数字化转型"],
"description": "工业术语理解 - 工业4.0"
},
{
"id": 4,
"industry": "教育",
"prompt": "解释'建构主义学习理论'的核心观点,以及它在现代教育实践中的应用。",
"expected_keywords": ["建构主义", "学习理论", "主动建构", "教育实践", "认知"],
"description": "教育术语理解 - 建构主义"
},
{
"id": 5,
"industry": "法律",
"prompt": "解释'不可抗力'这一法律概念,包括其构成要件和在合同纠纷中的适用。",
"expected_keywords": ["不可抗力", "法律概念", "构成要件", "合同", "免责"],
"description": "法律术语理解 - 不可抗力"
}
]
results = []
print("=" * 60)
print("测试1: 行业术语准确性测试")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
print(f"行业: {test_case['industry']}")
print(f"提示词: {test_case['prompt']}")
try:
# 构建对话格式(纯文本,无图片)
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": test_case['prompt']},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
inputs = processor(text=prompt, return_tensors='pt')
# 将输入移到模型所在的设备
if hasattr(model, 'device'):
inputs = {k: v.to(model.device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
else:
inputs = {k: v.to(next(model.parameters()).device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
# 确保数据类型正确
inputs = {k: v.to(torch.float16) if isinstance(v, torch.Tensor) and v.dtype == torch.float32 else v for k, v in inputs.items()}
# 过滤掉模型不需要的参数
model_inputs = {k: v for k, v in inputs.items() if k not in ['images']}
start_time = time.time()
output = model.generate(
**model_inputs,
max_new_tokens=300,
do_sample=True,
temperature=0.3,
top_p=0.95,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = processor.decode(output[0][2:], skip_special_tokens=True)
# 计算token数量
try:
# 尝试获取tokenizer
if hasattr(processor, 'tokenizer'):
tokenizer = processor.tokenizer
else:
# CustomProcessor也有tokenizer属性
tokenizer = getattr(processor, 'tokenizer', None)
if tokenizer is not None:
input_tokens = len(tokenizer.encode(prompt))
output_tokens = len(tokenizer.encode(generated_text)) - input_tokens
else:
# 如果无法获取tokenizer,使用估算值(按字符数估算,中文约1.5字符=1token)
input_tokens = int(len(prompt) / 1.5)
output_tokens = int(len(generated_text) / 1.5)
except Exception as e:
# 如果计算失败,使用估算值
print(f"Token计算失败,使用估算值: {e}")
input_tokens = int(len(prompt) / 1.5)
output_tokens = int(len(generated_text) / 1.5)
# 检查关键词匹配
generated_lower = generated_text.lower()
keywords_found = sum(1 for keyword in test_case['expected_keywords']
if keyword.lower() in generated_lower)
keyword_score = (keywords_found / len(test_case['expected_keywords'])) * 100
# 检查专业术语使用
has_technical_terms = any(word in generated_text for word in ["原理", "机制", "应用", "概念", "理论"])
has_explanation = len(generated_text) > 100
result = {
"test_id": test_case['id'],
"industry": test_case['industry'],
"description": test_case['description'],
"prompt": test_case['prompt'],
"generated_text": generated_text,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"keyword_score": round(keyword_score, 2),
"keywords_found": keywords_found,
"total_keywords": len(test_case['expected_keywords']),
"has_technical_terms": has_technical_terms,
"has_explanation": has_explanation,
"text_length": len(generated_text),
"success": True
}
print(f"生成时间: {generation_time:.3f}秒")
print(f"输出Token数: {output_tokens}")
print(f"生成速度: {result['tokens_per_second']:.2f} tokens/秒")
print(f"关键词匹配率: {keyword_score:.2f}% ({keywords_found}/{len(test_case['expected_keywords'])})")
print(f"\n生成的回答:\n{generated_text}")
except Exception as e:
print(f"测试用例 {test_case['id']} 执行失败: {e}")
result = {
"test_id": test_case['id'],
"industry": test_case['industry'],
"description": test_case['description'],
"prompt": test_case['prompt'],
"error": str(e),
"success": False
}
print(f"错误信息: {e}")
results.append(result)
print("-" * 60)
# 保存结果
with open("results_test1_industry_terminology.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
# 统计摘要
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_tokens = sum(r['output_tokens'] for r in results) / len(results)
avg_speed = sum(r['tokens_per_second'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
print("\n" + "=" * 60)
print("测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均输出Token数: {avg_tokens:.0f}")
print(f"平均生成速度: {avg_speed:.2f} tokens/秒")
print(f"平均关键词匹配率: {avg_keyword_score:.2f}%")
print(f"包含专业术语的用例: {sum(1 for r in results if r['has_technical_terms'])}/{len(results)}")
print(f"\n所有结果已保存到: results_test1_industry_terminology.json")运行结果成功:

| 核心测试指标 | test_id1(医疗 - CAR-T 疗法) | test_id2(金融 - 新能源投资) | test_id3(工业 - 工业 4.0) | test_id4(教育 - 建构主义) | test_id5(法律 - 不可抗力) |
|---|---|---|---|---|---|
| 行业领域 | 医疗 | 金融 | 工业 | 教育 | 法律 |
| 测试描述 | 医疗术语理解 - CAR-T 疗法 | 金融行业分析 - 新能源投资 | 工业术语理解 - 工业 4.0 | 教育术语理解 - 建构主义 | 法律术语理解 - 不可抗力 |
| 输入提示词(核心) | 解释 CAR-T 疗法原理、机制、临床应用 | 分析 2025 年 A 股新能源投资逻辑(趋势 / 政策 / 风险) | 解释工业 4.0 核心概念及三大技术作用 | 解释建构主义核心观点及教育应用 | 解释不可抗力构成要件及合同纠纷适用 |
| 生成文本完整性 | 未完成(仅介绍机制前 2 步) | 未完成(政策影响部分截断) | 未完成(技术相互作用部分截断) | 未完成(应用案例部分截断) | 严重重复且未完成(核心内容未展开) |
| 生成时长(秒) | 20.587 | 19.500 | 19.051 | 19.344 | 19.746 |
| 输入 tokens | 65 | 69 | 57 | 53 | 57 |
| 输出 tokens | 299 | 299 | 299 | 299 | 298 |
| 总 tokens | 364 | 368 | 356 | 352 | 355 |
| 生成速度(tokens / 秒) | 14.52 | 15.33 | 15.69 | 15.46 | 15.09 |
| 关键词匹配得分(%) | 60 | 100 | 80 | 60 | 80 |
| 命中关键词数 / 总关键词数 | 3/5 | 5/5 | 4/5 | 3/5 | 4/5 |
| 是否包含专业术语 | 是 | 否 | 是 | 是 | 是 |
| 是否提供有效解释说明 | 是 | 是 | 是 | 是 | 否(仅重复术语) |
| 生成文本长度(字符) | 250 | 261 | 289 | 259 | 223 |
| 测试成功标识 | true | true | true | true | true |
维度全覆盖:整合了「行业属性、生成质量、性能指标、内容合规性」4 大类 16 项关键信息,满足多维度评估需求;
对比直观化:通过横向列对齐,可快速发现:
性能瓶颈:所有测试均存在生成文本未完成问题(输出 tokens 均接近 300 上限,疑似长度限制);
行业差异:金融行业关键词匹配得分 100%(精准命中投资逻辑核心要素),法律行业存在严重内容重复(生成质量最差);
速度稳定:生成速度集中在 14.5-15.7 tokens / 秒,性能波动较小;
测试2:办公协同能力测试
测试目的:
这个测试看LLaVA在办公场景下的表现,包括文档生成(工作总结、会议纪要)、信息提取(合同条款)、邮件撰写、方案制定等。
代码:
bash
"""
测试2: 办公协同能力测试
测试LLaVA在文档生成、信息提取等办公场景下的表现
"""
import os
import time
import json
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration, LlamaTokenizer
# 设置HuggingFace镜像
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
model_id = "llava-hf/llava-1.5-7b-hf"
print("正在加载模型...")
# 昇腾NPU环境使用device_map="auto"自动分配设备
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto", # 自动检测并使用NPU
)
print("正在加载processor...")
# 如果fast tokenizer加载失败,尝试使用slow tokenizer
try:
processor = AutoProcessor.from_pretrained(model_id)
print("使用fast tokenizer加载成功")
except Exception as e:
print(f"Fast tokenizer加载失败: {e}")
print("尝试使用slow tokenizer手动构建processor...")
from transformers import CLIPImageProcessor
try:
tokenizer = LlamaTokenizer.from_pretrained(model_id, use_fast=False)
image_processor = CLIPImageProcessor.from_pretrained(model_id)
class CustomProcessor:
def __init__(self, tokenizer, image_processor):
self.tokenizer = tokenizer
self.image_processor = image_processor
def apply_chat_template(self, conversation, add_generation_prompt=True):
text = ""
for msg in conversation:
if msg["role"] == "user":
for content in msg["content"]:
if content["type"] == "text":
text += content["text"]
if add_generation_prompt:
text += "\nASSISTANT:"
return text
def __call__(self, images=None, text=None, return_tensors='pt'):
text_inputs = self.tokenizer(text, return_tensors=return_tensors)
if images is not None:
if not isinstance(images, list):
images = [images]
pixel_values = self.image_processor(images, return_tensors=return_tensors)['pixel_values']
return {**text_inputs, 'pixel_values': pixel_values}
return text_inputs
def decode(self, token_ids, skip_special_tokens=True):
return self.tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
processor = CustomProcessor(tokenizer, image_processor)
print("使用slow tokenizer手动构建processor成功")
except Exception as e2:
print(f"手动构建processor也失败: {e2}")
raise
print("模型和processor加载完成")
# 测试用例:办公协同场景
test_cases = [
{
"id": 1,
"task_type": "文档生成",
"prompt": "写一份Q3技术部门工作总结,包括:1. 完成的主要项目 2. 技术突破 3. 团队建设 4. 下季度规划。要求结构清晰,内容详实。",
"expected_sections": ["项目", "技术", "团队", "规划"],
"description": "技术部门工作总结生成"
},
{
"id": 2,
"task_type": "信息提取",
"prompt": "从以下合同条款中提取关键信息:'本合同自2025年1月1日起生效,有效期3年。付款方式为:首付30%在签约后7个工作日内支付,余款在项目验收后15个工作日内支付。如乙方违约,需支付合同总额20%的违约金。'请提取:付款期限、违约责任、合同期限。",
"expected_keywords": ["付款", "违约", "合同期限", "7个工作日", "15个工作日", "20%"],
"description": "合同信息提取"
},
{
"id": 3,
"task_type": "邮件撰写",
"prompt": "写一封给客户的邮件,主题是:项目延期通知。要求:1. 说明延期原因(技术难点需要更多时间)2. 新的交付时间(延期2周)3. 表达歉意并说明补偿措施。语气要专业且诚恳。",
"expected_keywords": ["延期", "技术难点", "交付时间", "歉意", "补偿"],
"description": "客户邮件撰写"
},
{
"id": 4,
"task_type": "方案制定",
"prompt": "制定一份新员工培训方案,包括:1. 培训目标 2. 培训内容(产品知识、业务流程、系统操作)3. 培训周期(2周)4. 考核方式。要求可执行性强。",
"expected_keywords": ["培训目标", "培训内容", "培训周期", "考核", "产品知识"],
"description": "培训方案制定"
},
{
"id": 5,
"task_type": "会议纪要",
"prompt": "根据以下会议内容整理会议纪要:'会议主题:Q4产品规划。参会人员:产品、技术、运营负责人。讨论要点:1. 新功能需求优先级排序 2. 技术实现方案评估 3. 上线时间节点确定。决议:优先开发用户反馈最多的3个功能,预计12月底上线。'要求格式规范,要点清晰。",
"expected_keywords": ["会议主题", "参会人员", "讨论要点", "决议", "上线时间"],
"description": "会议纪要整理"
}
]
results = []
print("=" * 60)
print("测试2: 办公协同能力测试")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
print(f"任务类型: {test_case['task_type']}")
print(f"提示词: {test_case['prompt'][:100]}...")
try:
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": test_case['prompt']},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
inputs = processor(text=prompt, return_tensors='pt')
# 将输入移到模型所在的设备
if hasattr(model, 'device'):
inputs = {k: v.to(model.device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
else:
inputs = {k: v.to(next(model.parameters()).device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
# 确保数据类型正确
inputs = {k: v.to(torch.float16) if isinstance(v, torch.Tensor) and v.dtype == torch.float32 else v for k, v in inputs.items()}
# 过滤掉模型不需要的参数
model_inputs = {k: v for k, v in inputs.items() if k not in ['images']}
start_time = time.time()
output = model.generate(
**model_inputs,
max_new_tokens=400,
do_sample=True,
temperature=0.4,
top_p=0.95,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = processor.decode(output[0][2:], skip_special_tokens=True)
# 计算token数量
try:
if hasattr(processor, 'tokenizer'):
tokenizer = processor.tokenizer
else:
tokenizer = getattr(processor, 'tokenizer', None)
if tokenizer is not None:
input_tokens = len(tokenizer.encode(prompt))
output_tokens = len(tokenizer.encode(generated_text)) - input_tokens
else:
input_tokens = int(len(prompt) / 1.5)
output_tokens = int(len(generated_text) / 1.5)
except Exception as e:
input_tokens = int(len(prompt) / 1.5)
output_tokens = int(len(generated_text) / 1.5)
# 检查关键词匹配
generated_lower = generated_text.lower()
keywords_found = sum(1 for keyword in test_case['expected_keywords']
if keyword.lower() in generated_lower)
keyword_score = (keywords_found / len(test_case['expected_keywords'])) * 100
# 检查文档质量
has_structure = any(word in generated_text for word in ["1.", "2.", "3.", "一、", "二、", "三、", "首先", "其次"])
has_details = len(generated_text) > 200
result = {
"test_id": test_case['id'],
"task_type": test_case['task_type'],
"description": test_case['description'],
"prompt": test_case['prompt'],
"generated_text": generated_text,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"keyword_score": round(keyword_score, 2),
"keywords_found": keywords_found,
"has_structure": has_structure,
"has_details": has_details,
"text_length": len(generated_text),
"success": True
}
print(f"生成时间: {generation_time:.3f}秒")
print(f"输出Token数: {output_tokens}")
print(f"关键词匹配率: {keyword_score:.2f}% ({keywords_found}/{len(test_case['expected_keywords'])})")
print(f"包含结构: {has_structure}")
print(f"\n生成的内容:\n{generated_text[:300]}...")
except Exception as e:
print(f"测试用例 {test_case['id']} 执行失败: {e}")
result = {
"test_id": test_case['id'],
"task_type": test_case.get('task_type', ''),
"description": test_case['description'],
"prompt": test_case['prompt'],
"error": str(e),
"success": False
}
print(f"错误信息: {e}")
results.append(result)
print("-" * 60)
with open("results_test2_office_collaboration.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
print("\n" + "=" * 60)
print("测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均关键词匹配率: {avg_keyword_score:.2f}%")
print(f"包含结构的文档: {sum(1 for r in results if r['has_structure'])}/{len(results)}")
print(f"\n所有结果已保存到: results_test2_office_collaboration.json")结果

| 测试 ID | 任务类型 | 核心需求 | 执行结果 | 关键指标(tokens / 秒) |
|---|---|---|---|---|
| test_id1 | 文档生成 | 撰写 Q3 技术部门工作总结(含 4 大模块:项目、技术突破、团队建设、下季度规划) | 失败 | - |
| test_id2 | 信息提取 | 从合同条款中提取付款期限、违约责任、合同期限 3 类关键信息 | 成功 | 15.25 |
| test_id3 | 邮件撰写 | 撰写项目延期通知邮件(说明原因、新交付时间、致歉 + 补偿措施) | 成功 | 15.14 |
| test_id4 | 方案制定 | 制定 2 周新员工培训方案(含目标、3 类内容、考核方式) | 成功 | 15.57 |
| test_id5 | 会议纪要 | 整理 Q4 产品规划会议纪要(规范格式、清晰呈现要点与决议) | 成功 | 15.36 |
性能表现:成功任务的 tokens 生成速度稳定在 15.14-15.57 之间,效率均衡;
质量特征:所有成功任务均满足has_details=true(内容详实),除信息提取外均实现has_structure=true(结构清晰),关键词命中率 100%。
测试3:创意内容生成测试
测试目的:
这个测试看LLaVA的创意能力,包括营销口号、故事续写、产品文案、广告脚本、品牌故事等。
代码:
bash
"""
测试3: 创意内容生成测试
测试LLaVA在文案创作、营销口号、故事续写等创意场景下的表现
"""
import os
import time
import json
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration, LlamaTokenizer
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
model_id = "llava-hf/llava-1.5-7b-hf"
print("正在加载模型...")
# 昇腾NPU环境使用device_map="auto"自动分配设备
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto", # 自动检测并使用NPU
)
print("正在加载processor...")
try:
processor = AutoProcessor.from_pretrained(model_id)
print("使用fast tokenizer加载成功")
except Exception as e:
print(f"Fast tokenizer加载失败: {e}")
print("尝试使用slow tokenizer手动构建processor...")
from transformers import CLIPImageProcessor
try:
tokenizer = LlamaTokenizer.from_pretrained(model_id, use_fast=False)
image_processor = CLIPImageProcessor.from_pretrained(model_id)
class CustomProcessor:
def __init__(self, tokenizer, image_processor):
self.tokenizer = tokenizer
self.image_processor = image_processor
def apply_chat_template(self, conversation, add_generation_prompt=True):
text = ""
for msg in conversation:
if msg["role"] == "user":
for content in msg["content"]:
if content["type"] == "text":
text += content["text"]
if add_generation_prompt:
text += "\nASSISTANT:"
return text
def __call__(self, images=None, text=None, return_tensors='pt'):
text_inputs = self.tokenizer(text, return_tensors=return_tensors)
if images is not None:
if not isinstance(images, list):
images = [images]
pixel_values = self.image_processor(images, return_tensors=return_tensors)['pixel_values']
return {**text_inputs, 'pixel_values': pixel_values}
return text_inputs
def decode(self, token_ids, skip_special_tokens=True):
return self.tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
processor = CustomProcessor(tokenizer, image_processor)
print("使用slow tokenizer手动构建processor成功")
except Exception as e2:
print(f"手动构建processor也失败: {e2}")
raise
print("模型和processor加载完成")
test_cases = [
{
"id": 1,
"task_type": "营销口号",
"prompt": "为一款智能手表写3条营销口号,要求:1. 突出健康监测功能 2. 强调科技感 3. 朗朗上口,易于记忆。每条口号不超过15个字。",
"expected_keywords": ["智能", "健康", "科技", "监测"],
"description": "智能手表营销口号创作"
},
{
"id": 2,
"task_type": "故事续写",
"prompt": "续写《三体》中'黑暗森林法则'的延伸剧情。要求:1. 保持原作的科幻风格 2. 探讨文明间的博弈 3. 情节要有转折。续写300字左右。",
"expected_keywords": ["黑暗森林", "文明", "博弈", "宇宙"],
"description": "科幻小说续写"
},
{
"id": 3,
"task_type": "产品文案",
"prompt": "为一款主打'极简设计'的蓝牙耳机写产品文案,包括:1. 产品定位 2. 核心卖点(音质、续航、设计)3. 使用场景。要求有感染力,能激发购买欲望。",
"expected_keywords": ["极简", "音质", "续航", "设计", "蓝牙耳机"],
"description": "产品文案创作"
},
{
"id": 4,
"task_type": "广告脚本",
"prompt": "写一个30秒的短视频广告脚本,产品是'智能学习台灯'。要求:1. 开头吸引注意 2. 展示核心功能(护眼、智能调光、学习模式)3. 结尾有行动号召。格式:画面+旁白。",
"expected_keywords": ["智能", "护眼", "调光", "学习"],
"description": "广告脚本创作"
},
{
"id": 5,
"task_type": "品牌故事",
"prompt": "为一个新成立的'可持续时尚'品牌写品牌故事,包括:1. 品牌理念(环保、可持续)2. 创立背景 3. 未来愿景。要求有温度,能引起共鸣。",
"expected_keywords": ["可持续", "环保", "时尚", "理念"],
"description": "品牌故事创作"
}
]
results = []
print("=" * 60)
print("测试3: 创意内容生成测试")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
print(f"任务类型: {test_case['task_type']}")
try:
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": test_case['prompt']},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
inputs = processor(text=prompt, return_tensors='pt')
# 将输入移到模型所在的设备
if hasattr(model, 'device'):
inputs = {k: v.to(model.device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
else:
inputs = {k: v.to(next(model.parameters()).device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
# 确保数据类型正确
inputs = {k: v.to(torch.float16) if isinstance(v, torch.Tensor) and v.dtype == torch.float32 else v for k, v in inputs.items()}
# 过滤掉模型不需要的参数
model_inputs = {k: v for k, v in inputs.items() if k not in ['images']}
start_time = time.time()
# 创意内容用稍高的temperature,增加多样性
output = model.generate(
**model_inputs,
max_new_tokens=350,
do_sample=True,
temperature=0.7,
top_p=0.9,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = processor.decode(output[0][2:], skip_special_tokens=True)
# 计算token数量
try:
if hasattr(processor, 'tokenizer'):
tokenizer = processor.tokenizer
else:
tokenizer = getattr(processor, 'tokenizer', None)
if tokenizer is not None:
input_tokens = len(tokenizer.encode(prompt))
output_tokens = len(tokenizer.encode(generated_text)) - input_tokens
else:
input_tokens = int(len(prompt) / 1.5)
output_tokens = int(len(generated_text) / 1.5)
except Exception as e:
input_tokens = int(len(prompt) / 1.5)
output_tokens = int(len(generated_text) / 1.5)
generated_lower = generated_text.lower()
keywords_found = sum(1 for keyword in test_case['expected_keywords']
if keyword.lower() in generated_lower)
keyword_score = (keywords_found / len(test_case['expected_keywords'])) * 100
# 检查创意性指标
has_emotional_words = any(word in generated_text for word in ["梦想", "未来", "美好", "体验", "感受", "享受"])
has_call_to_action = any(word in generated_text for word in ["立即", "现在", "快来", "选择", "拥有"])
is_creative = len(generated_text) > 150 and keyword_score > 50
result = {
"test_id": test_case['id'],
"task_type": test_case['task_type'],
"description": test_case['description'],
"prompt": test_case['prompt'],
"generated_text": generated_text,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"keyword_score": round(keyword_score, 2),
"keywords_found": keywords_found,
"has_emotional_words": has_emotional_words,
"has_call_to_action": has_call_to_action,
"is_creative": is_creative,
"text_length": len(generated_text),
"success": True
}
print(f"生成时间: {generation_time:.3f}秒")
print(f"关键词匹配率: {keyword_score:.2f}%")
print(f"创意性评分: {'高' if is_creative else '中'}")
print(f"\n生成的内容:\n{generated_text}")
except Exception as e:
print(f"测试用例 {test_case['id']} 执行失败: {e}")
result = {
"test_id": test_case['id'],
"task_type": test_case.get('task_type', ''),
"description": test_case['description'],
"prompt": test_case['prompt'],
"error": str(e),
"success": False
}
print(f"错误信息: {e}")
results.append(result)
print("-" * 60)
with open("results_test3_creative_content.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
creative_count = sum(1 for r in results if r['is_creative'])
print("\n" + "=" * 60)
print("测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均关键词匹配率: {avg_keyword_score:.2f}%")
print(f"高创意性内容: {creative_count}/{len(results)}")
print(f"\n所有结果已保存到: results_test3_creative_content.json")结果:
| 测试 ID | 任务类型 | 核心需求 | 执行结果 | 关键指标(tokens / 秒) | 特色指标亮点 |
|---|---|---|---|---|---|
| test_id1 | 营销口号 | 创作 3 条智能手表口号(突出健康监测 + 科技感,15 字内,易记忆) | 成功 | 11.95 | 含情感词,关键词命中率 100% |
| test_id2 | 故事续写 | 续写《三体》黑暗森林法则剧情(科幻风格 + 文明博弈 + 情节转折,300 字左右) | 成功 | 15.97 | 创意性强,关键词命中率 75% |
| test_id3 | 产品文案 | 撰写极简蓝牙耳机文案(定位 + 音质 / 续航 / 设计卖点 + 使用场景,有感染力) | 成功 | 16.30 | 含情感词、创意性强,关键词 100% |
| test_id4 | 广告脚本 | 30 秒智能学习台灯脚本(吸睛开头 + 护眼 / 调光 / 学习模式 + 行动号召,画面 + 旁白) | 成功 | 15.50 | 创意性强,关键词命中率 100% |
| test_id5 | 品牌故事 | 撰写可持续时尚品牌故事(环保理念 + 创立背景 + 未来愿景,有温度、能共鸣) | 成功 | 15.45 | 含情感词、有行动号召,创意性强 |
性能表现:创意类任务的 tokens 生成速度在 11.95-16.30 之间,其中产品文案(16.30)效率最高,营销口号(11.95)因需精炼表达速度稍慢,整体处于合理区间;
质量特征:
关键词命中率:仅故事续写(75%)未达满分,其余均 100% 命中核心需求;
创意与情感:80% 的任务(4/5)具备创意性,60%(3/5)含情感词,能有效满足创意类内容的感染力要求;
行动号召:仅品牌故事明确包含行动号召,广告脚本虽要求但未完整呈现,需优化落地性;
待改进点:部分生成文本存在字符缺失(如产品文案 "极��")、内容未收尾(如故事续写)等问题,虽不影响核心需求判定,但需提升文本完整性。
测试4:教育辅助能力测试
测试目的:
这个测试看LLaVA在教育场景下的表现,包括知识点讲解、错题分析、学习规划、答疑解惑、概念对比等。
代码:
bash
"""
测试4: 教育辅助能力测试
测试LLaVA在知识点讲解、错题分析、学习规划等教育场景下的表现
"""
import os
import time
import json
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration, LlamaTokenizer
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
model_id = "llava-hf/llava-1.5-7b-hf"
print("正在加载模型...")
# 昇腾NPU环境使用device_map="auto"自动分配设备
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto", # 自动检测并使用NPU
)
print("正在加载processor...")
try:
processor = AutoProcessor.from_pretrained(model_id)
print("使用fast tokenizer加载成功")
except Exception as e:
print(f"Fast tokenizer加载失败: {e}")
print("尝试使用slow tokenizer手动构建processor...")
from transformers import CLIPImageProcessor
try:
tokenizer = LlamaTokenizer.from_pretrained(model_id, use_fast=False)
image_processor = CLIPImageProcessor.from_pretrained(model_id)
class CustomProcessor:
def __init__(self, tokenizer, image_processor):
self.tokenizer = tokenizer
self.image_processor = image_processor
def apply_chat_template(self, conversation, add_generation_prompt=True):
text = ""
for msg in conversation:
if msg["role"] == "user":
for content in msg["content"]:
if content["type"] == "text":
text += content["text"]
if add_generation_prompt:
text += "\nASSISTANT:"
return text
def __call__(self, images=None, text=None, return_tensors='pt'):
text_inputs = self.tokenizer(text, return_tensors=return_tensors)
if images is not None:
if not isinstance(images, list):
images = [images]
pixel_values = self.image_processor(images, return_tensors=return_tensors)['pixel_values']
return {**text_inputs, 'pixel_values': pixel_values}
return text_inputs
def decode(self, token_ids, skip_special_tokens=True):
return self.tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
processor = CustomProcessor(tokenizer, image_processor)
print("使用slow tokenizer手动构建processor成功")
except Exception as e2:
print(f"手动构建processor也失败: {e2}")
raise
print("模型和processor加载完成")
test_cases = [
{
"id": 1,
"task_type": "知识点讲解",
"prompt": "用通俗语言解释'量子纠缠'这一物理概念,要求:1. 避免过于专业的术语 2. 用生活中的例子类比 3. 说明它的实际应用。适合高中生理解。",
"expected_keywords": ["量子", "纠缠", "关联", "应用"],
"description": "物理概念讲解 - 量子纠缠"
},
{
"id": 2,
"task_type": "错题分析",
"prompt": "分析这道数学题的错误原因并给出解题步骤:题目:解方程 2x + 5 = 3x - 2。学生解答:2x + 5 = 3x - 2,所以 x = 7。请指出错误并给出正确解法。",
"expected_keywords": ["移项", "合并同类项", "错误", "正确解法"],
"description": "数学错题分析"
},
{
"id": 3,
"task_type": "学习规划",
"prompt": "为一个准备高考的高三学生制定一个月的英语复习计划,包括:1. 每日学习时间分配 2. 重点内容(词汇、语法、阅读)3. 每周目标 4. 学习方法建议。要求可执行。",
"expected_keywords": ["复习计划", "时间分配", "词汇", "语法", "阅读"],
"description": "学习计划制定"
},
{
"id": 4,
"task_type": "答疑解惑",
"prompt": "学生问:'为什么说光合作用是地球上最重要的化学反应?'请用简洁明了的方式回答,包括:1. 光合作用的基本过程 2. 它对生态系统的意义 3. 对人类的重要性。",
"expected_keywords": ["光合作用", "化学反应", "生态系统", "氧气", "二氧化碳"],
"description": "生物知识答疑"
},
{
"id": 5,
"task_type": "概念对比",
"prompt": "解释'速度'和'加速度'的区别,要求:1. 给出定义 2. 说明两者的关系 3. 用具体例子说明。适合初中生理解。",
"expected_keywords": ["速度", "加速度", "定义", "区别", "例子"],
"description": "物理概念对比"
}
]
results = []
print("=" * 60)
print("测试4: 教育辅助能力测试")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
print(f"任务类型: {test_case['task_type']}")
try:
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": test_case['prompt']},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
inputs = processor(text=prompt, return_tensors='pt')
# 将输入移到模型所在的设备
if hasattr(model, 'device'):
inputs = {k: v.to(model.device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
else:
inputs = {k: v.to(next(model.parameters()).device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
# 确保数据类型正确
inputs = {k: v.to(torch.float16) if isinstance(v, torch.Tensor) and v.dtype == torch.float32 else v for k, v in inputs.items()}
# 过滤掉模型不需要的参数
model_inputs = {k: v for k, v in inputs.items() if k not in ['images']}
start_time = time.time()
output = model.generate(
**model_inputs,
max_new_tokens=400,
do_sample=True,
temperature=0.3,
top_p=0.95,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = processor.decode(output[0][2:], skip_special_tokens=True)
# 计算token数量
try:
if hasattr(processor, 'tokenizer'):
tokenizer = processor.tokenizer
else:
tokenizer = getattr(processor, 'tokenizer', None)
if tokenizer is not None:
input_tokens = len(tokenizer.encode(prompt))
output_tokens = len(tokenizer.encode(generated_text)) - input_tokens
else:
input_tokens = int(len(prompt) / 1.5)
output_tokens = int(len(generated_text) / 1.5)
except Exception as e:
input_tokens = int(len(prompt) / 1.5)
output_tokens = int(len(generated_text) / 1.5)
generated_lower = generated_text.lower()
keywords_found = sum(1 for keyword in test_case['expected_keywords']
if keyword.lower() in generated_lower)
keyword_score = (keywords_found / len(test_case['expected_keywords'])) * 100
# 检查教育质量指标
has_examples = any(word in generated_text for word in ["例如", "比如", "举例", "例子"])
has_steps = any(word in generated_text for word in ["第一步", "首先", "然后", "最后", "1.", "2."])
is_clear = len(generated_text) > 150 and keyword_score > 60
result = {
"test_id": test_case['id'],
"task_type": test_case['task_type'],
"description": test_case['description'],
"prompt": test_case['prompt'],
"generated_text": generated_text,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"keyword_score": round(keyword_score, 2),
"keywords_found": keywords_found,
"has_examples": has_examples,
"has_steps": has_steps,
"is_clear": is_clear,
"text_length": len(generated_text),
"success": True
}
print(f"生成时间: {generation_time:.3f}秒")
print(f"关键词匹配率: {keyword_score:.2f}%")
print(f"讲解清晰度: {'高' if is_clear else '中'}")
print(f"包含例子: {has_examples}")
print(f"\n生成的内容:\n{generated_text}")
except Exception as e:
print(f"测试用例 {test_case['id']} 执行失败: {e}")
result = {
"test_id": test_case['id'],
"task_type": test_case.get('task_type', ''),
"description": test_case['description'],
"prompt": test_case['prompt'],
"error": str(e),
"success": False
}
print(f"错误信息: {e}")
results.append(result)
print("-" * 60)
with open("results_test4_education_assistance.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
clear_count = sum(1 for r in results if r['is_clear'])
print("\n" + "=" * 60)
print("测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均关键词匹配率: {avg_keyword_score:.2f}%")
print(f"高清晰度讲解: {clear_count}/{len(results)}")
print(f"包含例子的回答: {sum(1 for r in results if r['has_examples'])}/{len(results)}")
print(f"\n所有结果已保存到: results_test4_education_assistance.json")结果:
| 测试 ID | 任务类型 | 核心需求 | 执行结果 | 关键指标(tokens / 秒) | 特色指标亮点 |
|---|---|---|---|---|---|
| test_id1 | 知识点讲解 | 通俗解释量子纠缠(避专业术语 + 生活类比 + 实际应用,适合高中生) | 成功 | 15.28 | 有例子、逻辑清晰,关键词命中率 75% |
| test_id2 | 错题分析 | 分析数学解方程错题原因 + 给出正确步骤(题目:2x+5=3x-2,学生答 x=7) | 成功 | 15.97 | 有步骤,关键词命中率 50%,逻辑不清晰 |
| test_id3 | 学习规划 | 制定高三英语月复习计划(每日时间分配 + 词汇 / 语法 / 阅读重点 + 每周目标 + 方法) | 成功 | 15.68 | 有步骤、逻辑清晰,关键词命中率 100% |
| test_id4 | 答疑解惑 | 回答 "光合作用为何是最重要化学反应"(基本过程 + 生态意义 + 人类重要性) | 成功 | 16.01 | 有例子、有步骤、逻辑清晰,关键词 100% |
| test_id5 | 概念对比 | 区分 "速度" 与 "加速度"(定义 + 关系 + 具体例子,适合初中生) | 成功 | 16.18 | 有例子、有步骤、逻辑清晰,关键词 100% |
补充说明
-
性能表现:学习类任务的 tokens 生成速度稳定在 15.28-16.18 之间,整体效率均衡,其中概念对比(16.18)速度最快,知识点讲解(15.28)因需通俗化转化稍慢,符合学习类内容的创作规律;
-
质量特征:
-
关键词命中率:错题分析(50%)、知识点讲解(75%)未达满分,其余均 100% 命中核心需求,错题分析因未准确识别学生错误(实际学生答案 x=7 是正确的,生成文本误判错误)导致命中率偏低;
-
逻辑与实用性:80% 的任务(4/5)逻辑清晰、具备可执行性,仅错题分析存在逻辑混乱(正确解法步骤错误);
-
辅助理解:75% 的任务(3/4,除学习规划外)包含具体例子,所有任务均有明确步骤,符合学习类内容 "易懂、可操作" 的核心要求;
- 待改进点:部分生成文本存在内容未收尾(如知识点讲解、概念对比)、核心逻辑错误(错题分析)等问题,需提升文本完整性和专业准确性;错题分析类任务需加强对题目本身的精准解读,避免误判正确答案。
测试5:客户服务能力测试
测试目的:
这个测试看LLaVA在客服场景下的表现,包括故障排查、投诉处理、产品咨询、情绪安抚、使用指导等;
代码:
bash
"""
测试5: 客户服务能力测试
测试LLaVA在问题解答、故障排查、用户情绪识别与回应等客服场景下的表现
"""
import os
import time
import json
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration, LlamaTokenizer
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
model_id = "llava-hf/llava-1.5-7b-hf"
print("正在加载模型...")
# 昇腾NPU环境使用device_map="auto"自动分配设备
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto", # 自动检测并使用NPU
)
print("正在加载processor...")
try:
processor = AutoProcessor.from_pretrained(model_id)
print("使用fast tokenizer加载成功")
except Exception as e:
print(f"Fast tokenizer加载失败: {e}")
print("尝试使用slow tokenizer手动构建processor...")
from transformers import CLIPImageProcessor
try:
tokenizer = LlamaTokenizer.from_pretrained(model_id, use_fast=False)
image_processor = CLIPImageProcessor.from_pretrained(model_id)
class CustomProcessor:
def __init__(self, tokenizer, image_processor):
self.tokenizer = tokenizer
self.image_processor = image_processor
def apply_chat_template(self, conversation, add_generation_prompt=True):
text = ""
for msg in conversation:
if msg["role"] == "user":
for content in msg["content"]:
if content["type"] == "text":
text += content["text"]
if add_generation_prompt:
text += "\nASSISTANT:"
return text
def __call__(self, images=None, text=None, return_tensors='pt'):
text_inputs = self.tokenizer(text, return_tensors=return_tensors)
if images is not None:
if not isinstance(images, list):
images = [images]
pixel_values = self.image_processor(images, return_tensors=return_tensors)['pixel_values']
return {**text_inputs, 'pixel_values': pixel_values}
return text_inputs
def decode(self, token_ids, skip_special_tokens=True):
return self.tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
processor = CustomProcessor(tokenizer, image_processor)
print("使用slow tokenizer手动构建processor成功")
except Exception as e2:
print(f"手动构建processor也失败: {e2}")
raise
print("模型和processor加载完成")
test_cases = [
{
"id": 1,
"task_type": "故障排查",
"prompt": "用户问题:'我的手机无法连接Wi-Fi,怎么排查?'请提供详细的排查步骤,包括:1. 常见原因 2. 逐步排查方法 3. 解决方案。语气要耐心、专业。",
"expected_keywords": ["Wi-Fi", "排查", "步骤", "解决方案", "重启", "密码"],
"description": "Wi-Fi故障排查"
},
{
"id": 2,
"task_type": "投诉处理",
"prompt": "用户抱怨:'你们的产品质量太差了,刚买一个月就坏了,我要退货!'请写一份客服回应,要求:1. 表达歉意和理解 2. 说明处理流程 3. 提供解决方案(退货或换货)4. 语气要诚恳、专业。",
"expected_keywords": ["歉意", "理解", "退货", "换货", "处理", "解决方案"],
"description": "用户投诉处理"
},
{
"id": 3,
"task_type": "产品咨询",
"prompt": "用户问:'我想买一台笔记本电脑,主要用于办公和偶尔玩游戏,预算8000元左右,有什么推荐?'请提供:1. 配置建议 2. 品牌推荐 3. 购买建议。要求专业且实用。",
"expected_keywords": ["笔记本电脑", "配置", "办公", "游戏", "预算", "推荐"],
"description": "产品咨询回答"
},
{
"id": 4,
"task_type": "情绪安抚",
"prompt": "用户情绪激动地说:'我预约的服务被取消了,而且没人通知我,浪费了我一上午时间!'请写一份回应,要求:1. 承认错误并道歉 2. 说明原因 3. 提供补偿方案 4. 语气要安抚、诚恳。",
"expected_keywords": ["道歉", "错误", "原因", "补偿", "安抚"],
"description": "用户情绪安抚"
},
{
"id": 5,
"task_type": "使用指导",
"prompt": "用户问:'我刚买了智能音箱,不知道怎么设置,能教教我吗?'请提供:1. 初始设置步骤 2. 常见功能使用 3. 注意事项。要求步骤清晰,易于操作。",
"expected_keywords": ["设置", "步骤", "功能", "智能音箱", "操作"],
"description": "产品使用指导"
}
]
results = []
print("=" * 60)
print("测试5: 客户服务能力测试")
print("=" * 60)
for test_case in test_cases:
print(f"\n测试用例 {test_case['id']}: {test_case['description']}")
print(f"任务类型: {test_case['task_type']}")
try:
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": test_case['prompt']},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
inputs = processor(text=prompt, return_tensors='pt')
# 将输入移到模型所在的设备
if hasattr(model, 'device'):
inputs = {k: v.to(model.device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
else:
inputs = {k: v.to(next(model.parameters()).device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
# 确保数据类型正确
inputs = {k: v.to(torch.float16) if isinstance(v, torch.Tensor) and v.dtype == torch.float32 else v for k, v in inputs.items()}
# 过滤掉模型不需要的参数
model_inputs = {k: v for k, v in inputs.items() if k not in ['images']}
start_time = time.time()
output = model.generate(
**model_inputs,
max_new_tokens=350,
do_sample=True,
temperature=0.4,
top_p=0.95,
)
end_time = time.time()
generation_time = end_time - start_time
generated_text = processor.decode(output[0][2:], skip_special_tokens=True)
# 计算token数量
try:
if hasattr(processor, 'tokenizer'):
tokenizer = processor.tokenizer
else:
tokenizer = getattr(processor, 'tokenizer', None)
if tokenizer is not None:
input_tokens = len(tokenizer.encode(prompt))
output_tokens = len(tokenizer.encode(generated_text)) - input_tokens
else:
input_tokens = int(len(prompt) / 1.5)
output_tokens = int(len(generated_text) / 1.5)
except Exception as e:
input_tokens = int(len(prompt) / 1.5)
output_tokens = int(len(generated_text) / 1.5)
generated_lower = generated_text.lower()
keywords_found = sum(1 for keyword in test_case['expected_keywords']
if keyword.lower() in generated_lower)
keyword_score = (keywords_found / len(test_case['expected_keywords'])) * 100
# 检查客服质量指标
has_apology = any(word in generated_text for word in ["抱歉", "对不起", "歉意", "理解"])
has_solution = any(word in generated_text for word in ["解决方案", "可以", "建议", "方法", "步骤"])
is_professional = len(generated_text) > 100 and keyword_score > 50
has_empathetic_words = any(word in generated_text for word in ["理解", "抱歉", "感谢", "为您"])
result = {
"test_id": test_case['id'],
"task_type": test_case['task_type'],
"description": test_case['description'],
"prompt": test_case['prompt'],
"generated_text": generated_text,
"generation_time": round(generation_time, 3),
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"tokens_per_second": round(output_tokens / generation_time, 2) if generation_time > 0 else 0,
"keyword_score": round(keyword_score, 2),
"keywords_found": keywords_found,
"has_apology": has_apology,
"has_solution": has_solution,
"is_professional": is_professional,
"has_empathetic_words": has_empathetic_words,
"text_length": len(generated_text),
"success": True
}
print(f"生成时间: {generation_time:.3f}秒")
print(f"关键词匹配率: {keyword_score:.2f}%")
print(f"专业性: {'高' if is_professional else '中'}")
print(f"包含解决方案: {has_solution}")
print(f"\n生成的回应:\n{generated_text}")
except Exception as e:
print(f"测试用例 {test_case['id']} 执行失败: {e}")
result = {
"test_id": test_case['id'],
"task_type": test_case.get('task_type', ''),
"description": test_case['description'],
"prompt": test_case['prompt'],
"error": str(e),
"success": False
}
print(f"错误信息: {e}")
results.append(result)
print("-" * 60)
with open("results_test5_customer_service.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
avg_time = sum(r['generation_time'] for r in results) / len(results)
avg_keyword_score = sum(r['keyword_score'] for r in results) / len(results)
professional_count = sum(1 for r in results if r['is_professional'])
print("\n" + "=" * 60)
print("测试摘要")
print("=" * 60)
print(f"平均生成时间: {avg_time:.3f}秒")
print(f"平均关键词匹配率: {avg_keyword_score:.2f}%")
print(f"高专业性回应: {professional_count}/{len(results)}")
print(f"包含解决方案的回应: {sum(1 for r in results if r['has_solution'])}/{len(results)}")
print(f"\n所有结果已保存到: results_test5_customer_service.json")结果:

| 测试 ID | 任务类型 | 核心需求 | 执行结果 | 关键指标(tokens / 秒) | 特色指标亮点 |
|---|---|---|---|---|---|
| test_id1 | 故障排查 | 提供手机 Wi-Fi 无法连接排查方案(常见原因 + 逐步排查 + 解决方案,耐心专业) | 成功 | 14.49 | 有解决方案、专业度达标,关键词命中率 66.67%,无共情词 |
| test_id2 | 投诉处理 | 回应产品质量投诉(道歉理解 + 处理流程 + 退货 / 换货方案,诚恳专业) | 成功 | 15.73 | 含道歉、有共情词、有解决方案,关键词命中率 100% |
| test_id3 | 产品咨询 | 推荐 8000 元左右办公 + 偶尔游戏笔记本(配置 + 品牌 + 购买建议,专业实用) | 成功 | 16.00 | 有解决方案、专业度达标,关键词命中率 100%,无共情词 |
| test_id4 | 情绪安抚 | 安抚预约服务取消的激动用户(认错道歉 + 说明原因 + 补偿方案,安抚诚恳) | 成功 | 15.94 | 含道歉、有共情词、有解决方案,关键词命中率 100% |
| test_id5 | 使用指导 | 提供智能音箱设置指导(初始步骤 + 常见功能 + 注意事项,步骤清晰) | 成功 | 16.12 | 有解决方案、专业度达标,关键词命中率 100%,无共情词 |
- 性能表现:客服服务类任务的 tokens 生成速度在 14.49-16.12 之间,整体效率稳定,其中使用指导(16.12)速度最快,故障排查(14.49)因需梳理分步排查逻辑稍慢,符合客服场景 "细致回应" 的需求特点;
- 质量特征:
-
关键词命中率:仅故障排查(66.67%)未达满分,其余均 100% 命中核心需求,故障排查因未完整覆盖 "逐步排查方法" 的细节导致命中率偏低;
-
客服核心要素:需情绪安抚的场景(投诉处理、情绪安抚)均包含道歉和共情词,符合 "先处理情绪再处理问题" 的客服逻辑;纯咨询 / 指导类场景(产品咨询、使用指导)无多余情绪表达,聚焦实用性,定位精准;
-
解决方案完整性:所有任务均明确 "有解决方案",但故障排查、使用指导的生成文本存在内容未收尾(如故障排查未写完排查步骤、使用指导未完整说明常见功能和注意事项),影响体验;
- 待改进点:部分任务存在文本不完整问题,需优化内容收尾;故障排查类任务可增加共情表达(如 "理解您无法连接 Wi-Fi 的不便"),提升用户体验;产品咨询中 "品牌推荐" 模块未完成,需补充具体品牌示例,增强实用性。
整体表现总结
| 测试 ID | 任务类型 | 核心需求 | 执行结果 | 生成速度(tokens / 秒) | 核心表现亮点 | 待优化点 |
|---|---|---|---|---|---|---|
| 1 | 文档生成 | 撰写 Q3 技术部门工作总结(含 4 大模块:项目、技术突破、团队建设、下季度规划) | 失败 | - | - | 缺少关键配置(expected_keywords) |
| 2 | 信息提取 | 从合同条款中提取付款期限、违约责任、合同期限 3 类关键信息 | 成功 | 15.25 | 信息提取完整,关键词命中率 100% | 无明确结构化呈现(如分点 / 分类) |
| 3 | 邮件撰写 | 撰写项目延期通知邮件(说明原因、新交付时间、致歉 + 补偿措施) | 成功 | 15.14 | 结构完整,语气专业诚恳 | 新交付时间、补偿措施未明确具体内容 |
| 4 | 方案制定 | 制定 2 周新员工培训方案(含目标、3 类内容、考核方式) | 成功 | 15.57 | 框架清晰,可执行性强 | 考核方式单一,缺乏实操细节 |
| 5 | 会议纪要 | 整理 Q4 产品规划会议纪要(规范格式、清晰呈现要点与决议) | 成功 | 15.36 | 格式规范,要点提炼准确 | 内容存在重复表述 |
整体总结
-
任务完成情况:5 项任务中 4 项成功,成功率 80%,仅文档生成因配置缺失失败,核心办公场景(信息提取、邮件、方案、纪要)均能满足基础需求;
-
性能表现:成功任务的生成速度稳定在 15.14-15.57 tokens / 秒,效率均衡,能适配日常办公的即时性需求;
-
质量特征:
-
优势:关键词命中率 100%,核心需求覆盖全面;结构化表现良好(邮件、方案、纪要均有清晰框架);
-
不足:部分任务缺乏细节填充(如邮件的具体时间 / 补偿方案)、存在表述冗余或形式不够优化(如信息提取未分点),需进一步提升内容的完整性和精炼度。
免责声明
- 本报告基于LLaVA-1.5-7B在特定测试场景下的输出结果分析,所有结论仅针对本次测试用例,不代表LLaVA在全部场景下的最终表现。
- 测试数据(生成时间、准确率、质量得分等)受测试环境、输入prompt格式、模型参数设置等因素影响,可能存在偏差,仅供参考。
- 报告中提及的LLaVA生成内容均为模型自动输出,可能存在内容截断、逻辑错误、信息不准确等问题,使用者需结合实际场景人工校验、修正后再使用,切勿直接用于生产环境、学术研究、教学等关键场景。
- 本报告仅为技术效果分析,不涉及对LLaVA模型本身的商业评价或背书,相关模型的使用需遵守其官方授权协议及相关法律法规。
- 因使用本报告结论或LLaVA生成内容所导致的任何直接或间接损失,本报告出具方不承担任何责任。