目录
[2.1 ChatModel(与其他大模型交互接口)](#2.1 ChatModel(与其他大模型交互接口))
[2.2 ChatClient(与大模型交互 + 维护上下文)](#2.2 ChatClient(与大模型交互 + 维护上下文))
[2.3 Prompt Templates(提示词模板)](#2.3 Prompt Templates(提示词模板))
[2.4 ChatOptions接口](#2.4 ChatOptions接口)
[2.5 Message](#2.5 Message)
[2.6 流式对话](#2.6 流式对话)
[2.7 文生图](#2.7 文生图)
[2.8 文本转语音、语音转文本](#2.8 文本转语音、语音转文本)
[2.9 多模态](#2.9 多模态)
[2.10 提示词填充](#2.10 提示词填充)
[2.11 嵌入模式](#2.11 嵌入模式)
[2.12 向量数据库](#2.12 向量数据库)
[2.13 函数调用](#2.13 函数调用)
[2.14 增强器](#2.14 增强器)
[2.15 对话记忆](#2.15 对话记忆)
[2.16 内容审查](#2.16 内容审查)
一、SpringAI特点
- 模型统一调用:通过 ChatClient 和 ChatModel 等接口,提供一致的编程模型来调用不同提供商的大语言模型(如 OpenAI、Azure OpenAI、本地部署的 Llama 等),支持文本生成、多模态处理(图像理解、语音转文字),并内置了提示词模板、请求重试、超时控制等企业级功能
- 向量存储与检索:通过 VectorStore 接口抽象主流向量数据库(如 Milvus、Chroma、Elasticsearch),并结合 EmbeddingModel 实现文本向量化,简化检索增强生成(RAG)流程,便于构建私有知识库问答系统
- 工具与 Agent 支持:内置 Function Calling 机制,允许将 Java 方法或外部 API 注册为工具,使 Agent 能够自动选择工具执行复杂任务(如数据分析、查询调度),并管理对话记忆以维持上下文连贯性
- 分层架构:采用清晰的分层设计,包括功能增强层(如提示模板、结构化输出)、模型抽象层(统一模型接口)和数据支撑层(向量库、文档解析)
- Spring 生态无缝集成(由于SpringAI基于Spring Boot3.x 开发,所以JDK 版本要求为 17 及以上)
二、SpringAI核心技术
2.1 ChatModel(与其他大模型交互接口)
ChatModel是Spring AI与大模型交互的核心接口。该接口定义了与大模型交互的标准方法,包括发送请求、接收响应、支持流式响应和多轮对话等高级功能。
ChatModel专注于与模型的直接通信,通常不涉及复杂的业务逻辑。通过ChatModel,开发者可以轻松集成不同的大模型,并实现文本生成、问答、对话等功能。
2.2 ChatClient(与大模型交互 + 维护上下文)
ChatClient是对ChatModel的更高层次的抽象和封装,支持同步和流式编程模型。除了负责与大模型的通信,ChatClient还可以维护对话上下文、支持多轮对话、实现流式响应,以及执行错误重试。这简化了业务逻辑的实现过程,帮助开发者高效地构建智能对话系统。类似地,可以使用ChatClient接入OpenAI大模型
2.3 Prompt Templates(提示词模板)
Spring AI使用提示词模板创建和管理提示词。Prompt Templates基于文本模板引擎,开发者通过预定义模板和占位符动态生成提示内容
定义模板字符串"请你给我讲一个关于{topic}的故事,故事是{adjective}的
2.4 ChatOptions接口
ChatOptions接口用于设置模型配置,例如模型名称、温度、最大词元数等。ChatOptions接口的常用实现类是OpenAiChatOptions
2.5 Message
Message接口表示对话中的消息,它封装了消息的内容、角色以及元数据。
SpringAI定义了四种消息角色:
- 系统角色常用于在开始对话之前向模型提供指令或上下文信息。
- 用户角色表示用户的输入,包括用户的问题、命令或陈述。
- 助理角色表示模型对用户输入的响应,通常在生成响应时使用。
- 工具/功能角色用于返回与工具调用相关的信息,通常在模型调用外部工具或函数时使用。
比如,在chat方法中,首先创建++系统消息并将模型的角色设置为"中学老师"++ 。接着,++创建用户消息内容为"请你谈谈本学期的教学安排"++。然后,将系统消息和用户消息添加到消息列表中,并使用该消息列表创建Prompt对象。最后,通过ChatClient生成响应并返回结果。
2.6 流式对话
流式对话以实时、逐步的方式接收大模型的响应。
这种方式特别适用于需要实时、持续数据交互的场景,如在线聊天、实时翻译等。通过流式对话,用户可以更快地看到部分结果,减少等待时间。
2.7 文生图
Spring AI集成了多种图像生成模型,能够根据用户输入的文本生成图像。
2.8 文本转语音、语音转文本
- Spring AI集成了多种语音合成模型,开发者只需通过简单的API调用即可将文本转换为自然语音
- 语音转文本类似地,可以借助OpenAiAudioTranscriptionModel将语音转换成文本
2.9 多模态
Spring AI的多模态支持同时处理多种类型的数据输入和输出,例如文本、图像和语音。通过多模态功能,开发者可以将不同类型的数据结合,生成更丰富的交互体验
2.10 提示词填充
通过将外部数据注入提示词模板来提高模型对上下文的理解能力。提示词填充适用于需要结合外部知识或动态数据的场景,例如问答系统和知识检索等
2.11 嵌入模式
Spring AI使用嵌入模型(EmbeddingModel)生成文本嵌入向量,将文本转换为高维向量表示。这些向量捕捉了文本的语义信息,适用于文本相似度计算、分类和聚类等任务.
2.12 向量数据库
- 向量数据库用于存储高维向量数据。不同于传统关系数据库的匹配检索方式,向量数据库采用相似性搜索
- Spring AI支持多种向量数据库。 系统从向量数据库中检索一组相似文档,并将其作为上下文与查询一起发送至模型
注
1) 向量数据库
- 专为处理高维向量数据(如图像、文本的数学表示)设计,支持相似性搜索;
- 存储非结构化数据的向量化结果(如文本嵌入、图像特征),数据以高维数值数组形式组织,维度可达数千
2)传统数据库
- 传统数据库则针对结构化数据(如表格),依赖精确匹配查询
3)性能差异
- 向量数据库:采用近似最近邻(ANN)算法进行相似性搜索(如余弦相似度),返回最相似的Top K结果,适用于模糊语义匹配,但计算密集型。
- 传统数据库:基于精确查询(如SQL条件匹配),结果确定性强,适用于事务处理(CRUD操作),但难以处理语义模糊需求。
向量数据库常见举例:
Milvus:开源向量数据库,专注于大规模相似性搜索,支持数十亿向量的高效检索,适用于图像识别、推荐系统等场景。
Chroma:开源嵌入数据库,专为大型语言模型(LLM)应用设计,简化知识管理与检索,减少模型幻觉
其他如MongoDB Atlas(集成向量搜索的文档数据库)、Deep Lake(专为深度学习设计的AI数据库)和Faiss(Facebook AI相似性搜索库)也常见于特定用例。
注: ClickHouse 是一个开源的列式数据库管理系统。ClickHouse 可被视为"支持向量搜索的数据库",但不属于严格意义上的向量数据库。
注: Elasticsearch 一个基于Lucene的分布式搜索引擎,Elasticsearch通常被归类为"支持向量搜索的搜索引擎",而非专用向量数据库。
2.13 函数调用
Spring AI的函数调用(Function Calling)功能允许大模型在生成响应的过程中调用外部函数或服务。
首先,自定义执行特定任务的函数,该函数通常封装了外部工具或API。然后,将自定义函数注册到Spring容器中。最后,将自定义函数添加到ChatClient中。
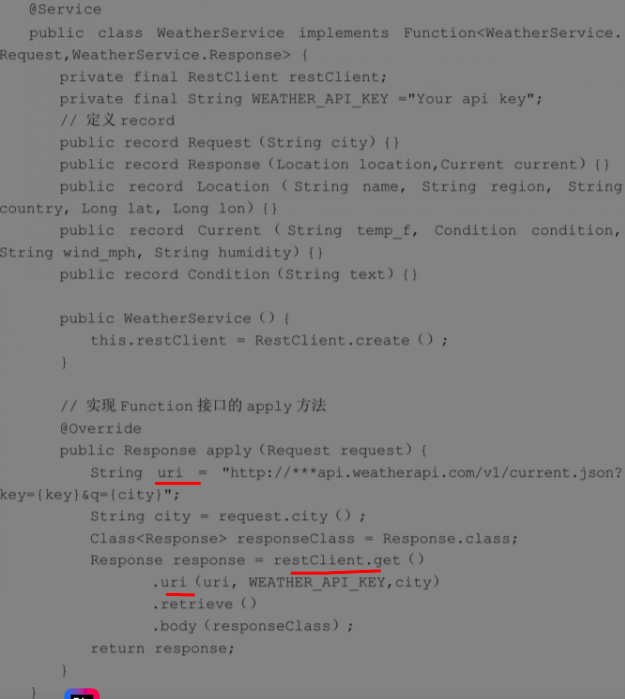
2.14 增强器
增强器, 通过在模型调用的请求发送之前和响应返回之后插入自定义逻辑;
例如实现输入验证、结果过滤、日志记录、性能监控等功能;
注: 这里的结果过滤, 可以间接实现大模型结果的自动化校验;
2.15 对话记忆
对话记忆用于管理对话上下文和历史记录,适用于多轮对话或需要上下文感知的场景。对话记忆支持内存存储和持久化存储等实现方式
2.16 内容审查
- Spring AI集成了内容审核模型,用于检测用户输入中可能存在的不当内容,例如暴力、仇恨言论、性暗示、自残和恐怖主义等。
- 开发者可以在模型调用之前对用户输入进行审核,确保其符合道德伦理和业务要求。若检测发现不当内容,那么系统将拦截请求并返回相应的提示信息,避免模型生成不当的响应。
- 内容审查机制适用于聊天机器人、内容生成平台等多种场景。
注: uri是外部的接口;