欢迎关注『跟我学 YOLO』系列
【跟我学YOLO】YOLO5 环境配置与检测
【跟我学YOLO】YOLO8 环境配置与推理检测
【跟我学YOLO】YOLO11 环境配置与基本应用
【跟我学YOLO】Mamba YOLO:基于状态空间模型的目标检测基线模型
-
- [0. 论文简介](#0. 论文简介)
-
- [0.1 基本信息](#0.1 基本信息)
- [0.2 论文概览](#0.2 论文概览)
- [0.3 摘要](#0.3 摘要)
- [1. 引言](#1. 引言)
- [2. 方法](#2. 方法)
-
- [2.1 Mamba理论基础](#2.1 Mamba理论基础)
- [2.2 MambaFusion-PAN](#2.2 MambaFusion-PAN)
- [3. 实验](#3. 实验)
-
- [3.1 实施细节](#3.1 实施细节)
- [3.2 零样本结果](#3.2 零样本结果)
- [3.3 微调结果](#3.3 微调结果)
- [3.4 消融实验](#3.4 消融实验)
- [4. 结论](#4. 结论)
- [5. Github 项目介绍](#5. Github 项目介绍)
-
- [5.1 快速开始](#5.1 快速开始)
- [5.3 可视化结果](#5.3 可视化结果)
- [6. 参考文献](#6. 参考文献)
0. 论文简介
0.1 基本信息
2025年,复旦大学 Haoxuan Wang 等在 ICASSP 2025 发布论文 【Mamba-YOLO-World:YOLO-World与Mamba 融合的开放词汇目标检测】(Mamba-YOLO-World: Marrying YOLO-World with Mamba for Open-Vocabulary Detection)。
论文下载: arxiv
项目地址: github, huggingface
引用格式: Wang Haoxuan, He Qingdong, Peng Jinlong, Yang Hao, Chi Mingmin, Wang Yabiao. Mamba-YOLO-World: Marrying YOLO-World with Mamba for Open-Vocabulary Detection©//ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025:1-5.
0.2 论文概览
设计理念
用 线性复杂度的 SSM 替代 Transformer 自注意力 降低计算负担,同时通过多模块协同优化特征提取与融合,无需大规模预训练即可高效训练。
核心架构
0.3 摘要
受深度学习技术快速发展的推动,YOLO系列为实时目标检测器树立了新标杆。与此同时,基于Transformer的结构已成为该领域最强大的解决方案,极大地扩展了模型的感受野并实现了显著的性能提升。然而,这种改进是以牺牲计算效率为代价的------自注意力机制的二次复杂度增加了模型的计算负担。
为解决这一问题,我们提出了一种简单而有效的基线方法Mamba YOLO,其主要贡献如下:
- 在ODMamba骨干网络中引入具有线性复杂度的状态空间模型,以替代自注意力的二次复杂度。与其他基于Transformer或SSM的方法不同,ODMamba无需预训练即可直接训练;
- 为满足实时性需求,设计了ODMamba的宏观结构,确定了最优阶段比例与缩放尺寸;
- 提出RG模块,采用多分支结构对通道维度建模,以解决SSM在序列建模中可能存在的感受野受限和图像定位能力不足问题,从而更精准地捕捉局部图像依赖关系。
在公开COCO基准数据集上的大量实验表明,Mamba YOLO相较现有方法取得了最优性能。具体而言,其轻量版在单张4090 GPU上推理耗时仅1.5毫秒时,mAP指标提升达7.5%。
PyTorch代码已开源:https://github.com/HZAI-ZJNU/Mamba-YOLO
1. 引言
目标检测作为计算机视觉的基础任务,在自动驾驶、个人电子设备、医疗保健与安防等诸多领域发挥着关键作用。传统方法1, 2, 3, 4, 5, 6在目标检测方面已取得显著进展。然而,这些模型通常在封闭集数据集上进行训练,其检测能力被限定于预设类别(例如COCO数据集7中的80个类别)。为突破这一局限,开放词汇目标检测8应运而生------该任务要求模型能够检测超出预设类别范围的对象。
先前研究基础
部分开放词汇目标检测研究10-14尝试利用预训练视觉语言模型固有的图文对齐能力。然而,这类模型主要在图像-文本层级进行训练,缺乏区域-文本层级的对齐能力。近期研究如MDETR15、GLIP16、DetClip17、Grounding DINO18、mm-Grounding-DINO19及YOLO-World20将开放词汇检测重新定义为视觉语言预训练任务,采用传统目标检测器直接在大规模数据集上学习区域-文本层级的开放词汇对齐能力。
现有方法分析
根据相关研究,将传统目标检测器转化为开放词汇检测模型的关键在于设计适配模型现有颈部结构的视觉-语言特征融合机制,例如YOLO-World中的VL-PAN20和Grounding DINO中的特征增强模块18。作为将YOLO系列引入开放词汇检测的开创性模型,YOLO-World非常适合部署在注重速度与效率的场景中。尽管如此,其VL-PAN特征融合机制仍存在以下局限性:
具体而言,VL-PAN在文本-图像特征融合流中采用最大Sigmoid视觉通道注意力机制,在图像-文本融合流中使用多头交叉注意力机制,这导致若干缺陷:首先,由于跨模态注意力机制的特性,两个融合流的复杂度均随图像尺寸与文本长度的乘积呈二次方增长;其次,VL-PAN缺乏全局引导感受野。一方面,文本-图像融合流仅生成缺乏像素级空间引导的视觉通道权重向量;另一方面,图像-文本融合流仅允许图像信息单独引导每个词汇,未能利用文本描述中的上下文信息。
创新解决方案
为解决上述问题,我们提出Mamba-YOLO-World------一种基于YOLO的新型开放词汇检测模型,采用创新的MambaFusion路径聚合网络作为颈部架构。近期兴起的状态空间模型Mamba21已展现其避免二次复杂度与捕获全局感受野的能力22-26。然而,直接拼接多模态特征进行Mamba处理27-29会导致复杂度达到O(N+M),且随拼接序列长度线性增长,这对于开放词汇检测中的大规模词汇尤为不利。
受此启发,我们在MambaFusion-PAN中提出基于状态空间模型的特征融合机制:以Mamba隐状态作为不同模态间特征融合的中介,实现O(N+1)复杂度并提供全局引导感受野。如图1所示的可视化结果证明,Mamba-YOLO-World在所有规模变体上均显著超越YOLO-World的精度与泛化能力。
本文贡献
我们的贡献可归纳为以下三点:
- 提出采用MambaFusion-PAN颈部架构的新型YOLO基开放词汇检测模型Mamba-YOLO-World
- 设计包含并行引导选择性扫描与串行引导选择性扫描算法的状态空间模型特征融合机制,实现O(N+1)复杂度与全局引导感受野
- 实验表明,本模型在保持相当参数量和计算量的同时超越原始YOLO-World,并以更少的参数量与计算量超越现有先进开放词汇检测方法。

图1:零样本推理在LVIS9上的可视化结果。我们的Mamba-YOLO-World在准确性和从小型到大型模型的泛化能力上显著优于YOLO-World。
2. 方法
Mamba-YOLO-World主要基于YOLOv830构建,包含作为骨干网络的Darknet主干网络3与CLIP31文本编码器、作为颈部网络的MambaFusion-PAN,以及由文本对比分类头和边界框回归头组成的检测头,整体架构如图2所示。
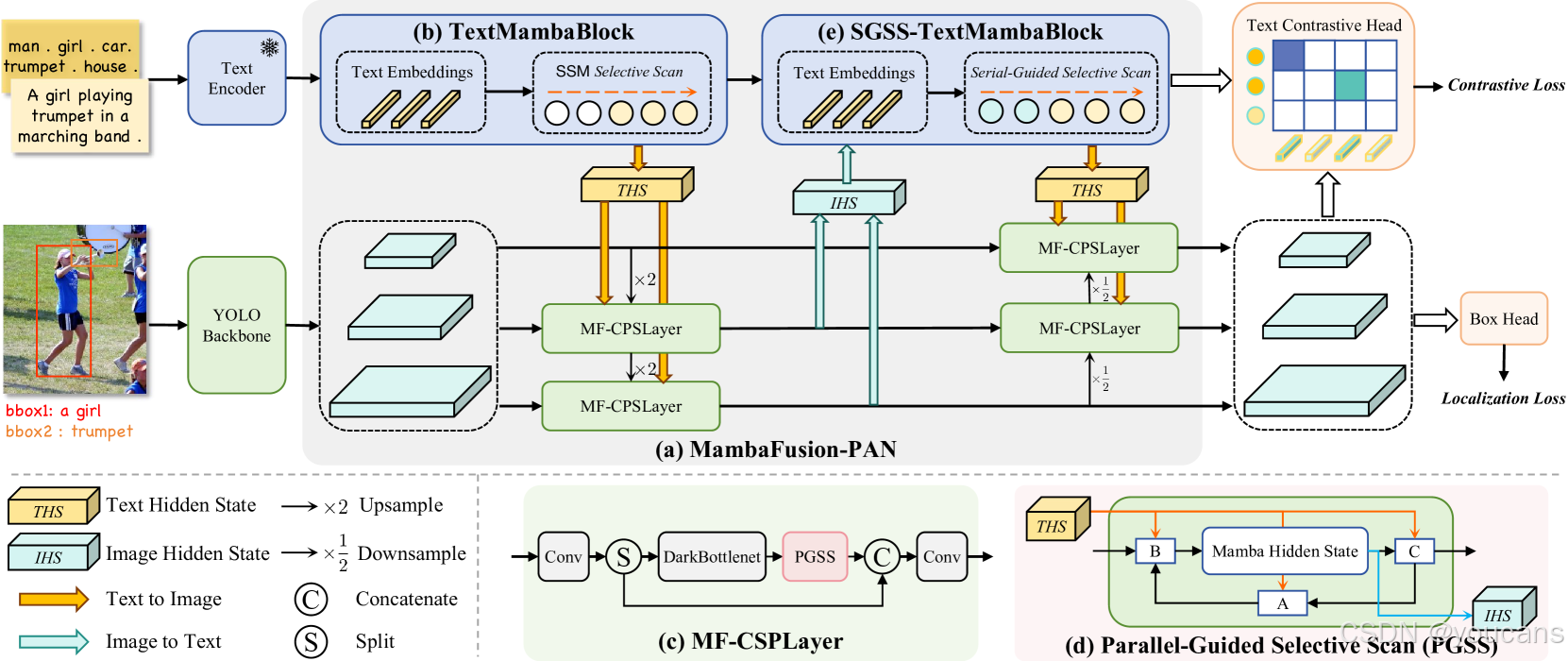
图2:Mamba-YOLO-World的整体架构。它由五个关键组件组成:
(a) MambaFusion-PAN是我们提出的一种特征融合网络,用于替代YOLO中的Path Aggregation Feature Pyramid Network。
(b) TextMambaBlock包含堆叠的Mamba层,扫描输入的文本嵌入以提取输出文本特征和文本隐藏状态(THS)。
(c ) MF-CSPLayer将提出的PGSS算法整合到YOLO CSPLayer风格的网络中。
(d) 在Parallel-Guided Selective Scan (PGSS)算法中,压缩的文本信息THS在视觉选择性扫描的整个过程中并行注入Mamba参数,以提取输出图像特征和图像隐藏状态(IHS)。
(e) SGSS-TextMambaBlock是使用Serial-Guided Selective Scan算法的TextMambaBlock。
在提取文本特征之前,通过扫描压缩的视觉信息IHS来按顺序调整Mamba参数。
2.1 Mamba理论基础
对于连续输入信号 𝑢 ( 𝑡 ) ∈ R 𝑢(𝑡) ∈ ℝ u(t)∈R,状态空间模型32通过隐状态 h ( 𝑡 ) ∈ R E ℎ(𝑡) ∈ ℝᴱ h(t)∈RE 将其映射为连续输出信号 𝑦 ( 𝑡 ) ∈ R 𝑦(𝑡) ∈ ℝ y(t)∈R:
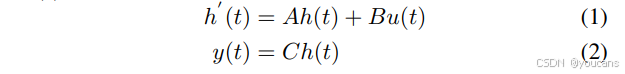
其中 𝐸 为状态空间模型的状态扩展因子, 𝐴 ∈ R E x E 𝐴 ∈ ℝ^{ExE} A∈RExE 为状态转移矩阵,$𝐵 ∈ ℝ^{Ex1} 和 𝐶 ∈ R 1 x E 𝐶 ∈ ℝ^{1xE} C∈R1xE 分别为输入与输出映射矩阵。基于状态空间模型,Mamba21引入选择性扫描算法,使 𝐴、𝐵、𝐶 成为输入序列的函数。
2.2 MambaFusion-PAN
MambaFusion-PAN是我们提出的用于替代YOLO中路径聚合特征金字塔网络的特征融合网络。如图2(a)所示,该网络通过提出的基于状态空间模型的并行与串行特征融合机制,在视觉与语言分支间建立三阶段特征融合流(文本→图像、图像→文本、最终文本→图像),实现多尺度图像特征聚合与文本特征增强。具体组件将在本节后续部分详细说明。
-
Mamba隐状态
当前基于Transformer和Mamba的视觉语言模型通常直接拼接多模态特征18,19,33,34,27-29,导致复杂度随文本序列长度和图像分辨率增长而必然增加。虽然YOLO-World中的VL-PAN采用单向融合避免特征拼接,但仍因文本→图像融合流中的视觉通道注意力机制和图像→文本融合流中的多头交叉注意力机制,产生 𝑂(𝑁²) 复杂度。
为解决此问题,我们提出通过Mamba隐状态 ℎ(𝑡) ∈ ℝᴰ×ᴱ 提取压缩序列信息,作为不同模态间特征融合的中介。其中 𝐷 为输入序列维度,𝐸 为状态空间模型扩展因子21,26。由于 𝐷 和 𝐸 均为常数且不受序列长度影响,我们的特征融合机制复杂度为 𝑂(𝑁+1)------其中 𝑁 来源于单模态输入序列,1 来源于另一模态的Mamba隐状态。
-
文本Mamba模块
文本Mamba模块由堆叠的Mamba层构成。针对CLIP文本编码器输出的文本嵌入 𝑤₀ ∈ ℝᴸᵗ×ᴰᵗ,我们采用图2(b)所示的文本Mamba模块,不仅提取输出文本特征 𝑤₁ ∈ ℝᴸᵗ×ᴰᵗ,同时生成文本隐状态 𝑇𝐻𝑆 ∈ ℝᴰᵗ×ᴱᵗ,该隐状态将用于后续文本→图像特征融合。
-
MF-CSP层
如图2©所示,我们通过MambaFusion CSP层将文本隐状态与多尺度图像特征进行集成。该层将提出的并行引导选择性扫描算法融入YOLO CSP层风格网络。经MF-CSP层处理后,既可获得输出图像特征,还能生成图像隐状态 𝐼𝐻𝑆 ∈ ℝᴰⁱ×ᴱⁱ,用于后续图像→文本特征融合。
-
并行引导选择性扫描
Mamba选择性扫描算法根据输入序列动态调整内部参数。受此启发,我们创新性地提出并行引导选择性扫描算法。如图2(d)和算法1 所示,该算法在扫描过程中同时依据输入图像序列和文本隐状态,动态调整Mamba内部参数(𝐴、𝐵、𝐶)的取值。因此,压缩的文本信息在整个视觉选择性扫描过程中以并行方式注入Mamba,使多尺度图像特征能在像素级别而非通道级别获得引导。由此生成的输出将传递至MF-CSP层的后续层级。下文将这部分流程称为文本→图像特征融合流。

- 串行引导选择性扫描
Mamba选择性扫描算法能基于输入序列将信息持续压缩至隐状态 ℎ(𝑡)。受此启发,我们提出串行引导选择性扫描算法,并将其集成至文本Mamba模块中,如图2(e)所示。该算法旨在将来自先前序列的先验知识压缩至 ℎ(𝑡),并以此为后续序列提供引导。具体而言,SGSS-文本Mamba模块在提取文本特征前,通过扫描压缩的视觉信息(图像隐状态IHS),以串行方式调整Mamba内部参数(𝐴、𝐵、𝐶)的取值。下文将这部分流程称为图像→文本特征融合流。
3. 实验
3.1 实施细节
Mamba-YOLO-World基于MMYOLO35工具箱与MMDetection36工具箱开发。
我们提供了三种规模变体:小型、中型和大型。实验包含预训练阶段与微调阶段。
预训练阶段采用目标检测与定位数据集,包括Objects365 (V1)37、GQA38和Flickr30k39。与其他开放词汇检测方法15-20保持一致,在排除COCO数据集7图像后,将GQA与Flickr30k数据集合并标注为GoldG数据集15。微调阶段使用预训练的Mamba-YOLO-World模型,在下游任务数据集上进行微调。除特殊说明外,所有实验均遵循YOLO-World20的设置进行。
3.2 零样本结果
完成预训练后,我们在LVIS9和COCO7基准上以零样本方式直接评估所提出的Mamba-YOLO-World模型,并与YOLO-World及其他现有先进方法进行全面对比。
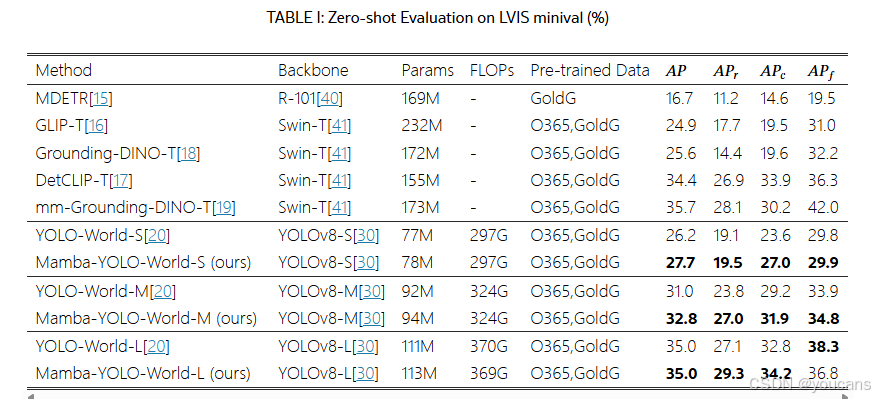
- LVIS零样本评估
LVIS数据集包含1203个长尾目标类别。遵循先前研究15-20的设置,我们采用固定AP42指标,并在LVIS验证集上每张图像报告1000个预测结果以确保公平比较。根据表I所示,在保持相当参数量和计算量的条件下,Mamba-YOLO-World小型变体相较于YOLO-World实现了1.5%的AP提升,中型变体提升了1.8%。此外,在所有规模变体上,其稀有类别AP和常见类别AP分别优于YOLO-World 0.4%3.2%和1.4%3.4%。Mamba-YOLO-World大型变体以更少的参数量和计算量,超越了15-18等先前先进方法,取得了优越性能。
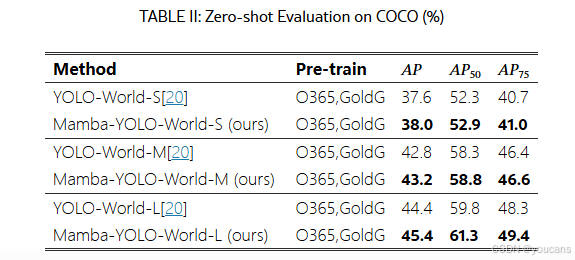
- COCO零样本评估
COCO数据集包含80个类别,是目标检测领域最常用的数据集。如表II所示,我们的Mamba-YOLO-Word展现出全面优势,在所有规模变体上均超越YOLO-World 0.4%~1%的AP指标。
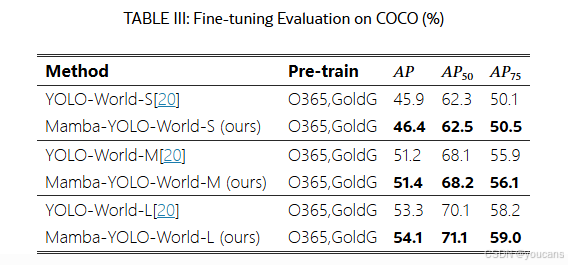
3.3 微调结果
在表III中,我们进一步评估了COCO基准上的微调结果。在COCO train2017数据集上进行微调后,Mamba-YOLO-World获得了更高的检测精度,所有规模变体均稳定超越微调后的YOLO-World模型,AP指标提升幅度达0.2%~0.8%。
3.4 消融实验
我们在表IV中基于Mamba-YOLO-World-S模型开展消融实验,以分析MambaFusion-PAN中文本→图像与图像→文本特征融合流的作用。在COCO基准上的零样本评估结果表明,我们提出的并行(文本→图像)与串行(图像→文本)特征融合方法均能有效提升模型性能,且未增加参数量或计算量。
此外,我们分析了计算成本随输入图像分辨率增加的变化情况。如图3所示,在所有规模变体中,MambaFusion-PAN(Mamba-YOLO-World的颈部网络)相比VL-PAN(YOLO-World的颈部网络)可减少高达15%的浮点运算量,这表明我们的MambaFusion-PAN具有更低的模型复杂度。
4. 结论
本文提出了适用于开放词汇目标检测的 Mamba-YOLO-World 模型。
我们设计了一种创新性的、基于状态空间模型(State Space Model, SSM)的特征融合机制,并将其集成到 MambaFusion-PAN 架构中。
实验结果表明,在参数规模和计算量(FLOPs)相当的前提下,Mamba-YOLO-World 的性能优于原始 YOLO-World 模型。我们期望本研究能为多模态 Mamba 架构的探索提供新的思路,并推动开放词汇视觉任务的进一步发展。
5. Github 项目介绍
项目地址: github, huggingface
本仓库包含Mamba-YOLO-World的PyTorch实现代码、预训练权重以及预训练/微调脚本。
我们提出了Mamba-YOLO-World,这是一种基于YOLO架构的新型开放词汇目标检测模型,其核心创新在于采用了我们设计的MambaFusion-PAN作为颈部网络结构。
我们引入了一种基于状态空间模型的特征融合机制,该机制包含并行引导选择性扫描算法与串行引导选择性扫描算法,在实现O(N+1)线性复杂度的同时具备全局引导感受野。
实验结果表明,我们的模型在保持相当参数量和计算量的前提下,性能显著超越原始YOLO-World。同时,该模型以更少的参数量和计算量,超越了现有的先进开放词汇检测方法。
5.1 快速开始
- 环境安装
Mamba-YOLO-World基于以下环境开发:
bash
torch==2.0.0
mamba-ssm==2.1.0
triton==2.1.0
supervision==0.20.0
mmcv==2.0.1
mmyolo==0.6.0
mmdetection==3.3.0需将third_party目录下的mmyolo库链接至环境。
-
数据准备
预训练数据的具体说明详见docs/data目录。
-
模型评估
bash
./tools/dist_test.sh configs/mamba2_yolo_world_s.py 模型权重路径 单节点GPU数量
./tools/dist_test.sh configs/mamba2_yolo_world_m.py 模型权重路径 单节点GPU数量
./tools/dist_test.sh configs/mamba2_yolo_world_l.py 模型权重路径 单节点GPU数量- 预训练
bash
./tools/dist_train.sh configs/mamba2_yolo_world_s.py 单节点GPU数量 --amp
./tools/dist_train.sh configs/mamba2_yolo_world_m.py 单节点GPU数量 --amp
./tools/dist_train.sh configs/mamba2_yolo_world_l.py 单节点GPU数量 --amp- 微调训练
bash
./tools/dist_train.sh configs/mamba2_yolo_world_s_mask-refine_finetune_coco.py 单节点GPU数量 --amp
./tools/dist_train.sh configs/mamba2_yolo_world_m_mask-refine_finetune_coco.py 单节点GPU数量 --amp
./tools/dist_train.sh configs/mamba2_yolo_world_l_mask-refine_finetune_coco.py 单节点GPU数量 --amp- 演示示例
image_demo.py:支持单张图像或图像目录的推理
video_demo.py:支持视频文件推理
5.3 可视化结果
我们采用预训练的Mamba-YOLO-World-S/M/L模型与YOLO-World-v2-S/M/L模型,在LVIS-val2017数据集(使用COCO-val2017图像配合LVIS词汇库)上进行零样本推理。需要说明的是,LVIS词汇库包含1203个目标类别。
所有可视化结果可通过以下链接获取:
夸克网盘:https://pan.quark.cn/s/450070c03c58
HuggingFace仓库:https://huggingface.co/Xuan-World/Mamba-YOLO-World/tree/main/zeroshot_pictures_COCO_Comparison
欢迎下载这些可视化结果,对比我们提出的Mamba-YOLO-World与原始YOLO-World(包括最新版本YOLO-World-v2)在小型、中型、大型变体上的性能表现。可视化结果充分证明,Mamba-YOLO-World在所有规模变体上均显著超越YOLO-World系列模型,在检测精度与泛化能力方面展现出明显优势。
6. 参考文献
bash
[1] R. Girshick, "Fast r-cnn," in Proceedings of the IEEE internationalconference on computer vision, 2015, pp. 1440--1448.
[2] S. Ren, K. He, R. Girshick, and J. Sun, "Faster r-cnn: Towards real-timeobject detection with region proposal networks," Advances in neuralinformation processing systems, vol. 28, 2015.
[3] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, "You only lookonce: Unified, real-time object detection," in Proceedings of the IEEEconference on computer vision and pattern recognition, 2016, pp. 779--788.
[4] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, andS. Zagoruyko, "End-to-end object detection with transformers," inEuropean conference on computer vision. Springer, 2020, pp. 213--229.
[5] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, "DeformableDETR: Deformable transformers for end-to-end object detection," inInternational Conference on Learning Representations, 2021.
[6] H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. Ni, and H.-Y. Shum,"DINO: DETR with improved denoising anchor boxes for end-to-endobject detection," in The Eleventh International Conference on LearningRepresentations, 2023.
[7] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan,P. Dollar, and C. L. Zitnick, "Microsoft coco: Common objects in ´context," in Computer Vision--ECCV 2014: 13th European Conference,Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13.Springer, 2014, pp. 740--755.
[8] A. Zareian, K. D. Rosa, D. H. Hu, and S.-F. Chang, "Open-vocabularyobject detection using captions," in Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition, 2021, pp.14 393--14 402.
[9] A. Gupta, P. Dollar, and R. Girshick, "Lvis: A dataset for largevocabulary instance segmentation," in Proceedings of the IEEE/CVFconference on computer vision and pattern recognition, 2019, pp. 5356--5364.
[10] X. Gu, T.-Y. Lin, W. Kuo, and Y. Cui, "Open-vocabulary object detec tion via vision and language knowledge distillation," in InternationalConference on Learning Representations, 2022.
[11] S. Wu, W. Zhang, S. Jin, W. Liu, and C. C. Loy, "Aligning bag ofregions for open-vocabulary object detection," in Proceedings of theIEEE/CVF conference on computer vision and pattern recognition, 2023,pp. 15 254--15 264.
[12] W. Kuo, Y. Cui, X. Gu, A. Piergiovanni, and A. Angelova, "Open vocabulary object detection upon frozen vision and language models,"in The Eleventh International Conference on Learning Representations,2023.
[13] S. Xu, X. Li, S. Wu, W. Zhang, Y. Li, G. Cheng, Y. Tong, K. Chen, andC. C. Loy, "Dst-det: Simple dynamic self-training for open-vocabularyobject detection," arXiv preprint arXiv:2310.01393, 2023.
[14] X. Wu, F. Zhu, R. Zhao, and H. Li, "Cora: Adapting clip for open vocabulary detection with region prompting and anchor pre-matching,"in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recog nition (CVPR), 2023, pp. 7031--7040.
[15] A. Kamath, M. Singh, Y. LeCun, G. Synnaeve, I. Misra, and N. Carion,"Mdetr-modulated detection for end-to-end multi-modal understanding,"in Proceedings of the IEEE/CVF international conference on computervision, 2021, pp. 1780--1790.
[16] L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y. Zhong, L. Wang,L. Yuan, L. Zhang, J.-N. Hwang et al., "Grounded language-image pre training," in Proceedings of the IEEE/CVF Conference on ComputerVision and Pattern Recognition, 2022, pp. 10 965--10 975.
[17] L. Yao, J. Han, Y. Wen, X. Liang, D. Xu, W. Zhang, Z. Li, C. Xu,and H. Xu, "Detclip: Dictionary-enriched visual-concept paralleled pre training for open-world detection," Advances in Neural InformationProcessing Systems, vol. 35, pp. 9125--9138, 2022.
[18] S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang,H. Su, J. Zhu et al., "Grounding dino: Marrying dino with grounded pre training for open-set object detection," arXiv preprint arXiv:2303.05499,2023.
[19] X. Zhao, Y. Chen, S. Xu, X. Li, X. Wang, Y. Li, and H. Huang, "An openand comprehensive pipeline for unified object grounding and detection,"arXiv preprint arXiv:2401.02361, 2024.
[20] T. Cheng, L. Song, Y. Ge, W. Liu, X. Wang, and Y. Shan, "Yolo world: Real-time open-vocabulary object detection," in Proceedings ofthe IEEE/CVF Conference on Computer Vision and Pattern Recognition,2024, pp. 16 901--16 911.
[21] A. Gu and T. Dao, "Mamba: Linear-time sequence modeling withselective state spaces," arXiv preprint arXiv:2312.00752, 2023.
[22] Y. Liu, Y. Tian, Y. Zhao, H. Yu, L. Xie, Y. Wang, Q. Ye, and Y. Liu,"Vmamba: Visual state space model," arXiv preprint arXiv:2401.10166,2024.
[23] L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, "Visionmamba: Efficient visual representation learning with bidirectional statespace model," arXiv preprint arXiv:2401.09417, 2024.
[24] A. Hatamizadeh and J. Kautz, "Mambavision: A hybrid mamba transformer vision backbone," arXiv preprint arXiv:2407.08083, 2024.
[25] L. Ren, Y. Liu, Y. Lu, Y. Shen, C. Liang, and W. Chen, "Samba: Simplehybrid state space models for efficient unlimited context languagemodeling," arXiv preprint arXiv:2406.07522, 2024.
[26] T. Dao and A. Gu, "Transformers are ssms: Generalized models and ef ficient algorithms through structured state space duality," arXiv preprintarXiv:2405.21060, 2024.
[27] Y. Qiao, Z. Yu, L. Guo, S. Chen, Z. Zhao, M. Sun, Q. Wu, and J. Liu,"Vl-mamba: Exploring state space models for multimodal learning,"arXiv preprint arXiv:2403.13600, 2024.
[28] B.-K. Lee, C. W. Kim, B. Park, and Y. M. Ro, "Meteor: Mamba based traversal of rationale for large language and vision models," arXivpreprint arXiv:2405.15574, 2024.
[29] H. Zhao, M. Zhang, W. Zhao, P. Ding, S. Huang, and D. Wang, "Cobra:Extending mamba to multi-modal large language model for efficientinference," arXiv preprint arXiv:2403.14520, 2024.
[30] G. Jocher, A. Chaurasia, and J. Qiu, "Ultralytics yolov8," 2023. [Online]. Available: https://github.com/ultralytics/ultralytics
[31] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal,G. Sastry, A. Askell, P. Mishkin, J. Clark et al., "Learning transferablevisual models from natural language supervision," in Internationalconference on machine learning. PMLR, 2021, pp. 8748--8763.
[32] A. Gu, K. Goel, and C. Re, "Efficiently modeling long sequences with ´structured state spaces," in The International Conference on LearningRepresentations (ICLR), 2022.
[33] H. Liu, C. Li, Q. Wu, and Y. J. Lee, "Visual instruction tuning,"Advances in neural information processing systems, vol. 36, 2024.
[34] J. Li, D. Li, C. Xiong, and S. Hoi, "Blip: Bootstrapping language-imagepre-training for unified vision-language understanding and generation,"in International conference on machine learning. PMLR, 2022, pp.12 888--12 900.
[35] M. Contributors, "MMYOLO: OpenMMLab YOLO series toolbox andbenchmark," https://github.com/open-mmlab/mmyolo, 2022.
[36] K. Chen, J. Wang, J. Pang, Y. Cao, Y. Xiong, X. Li, S. Sun, W. Feng,Z. Liu, J. Xu, Z. Zhang, D. Cheng, C. Zhu, T. Cheng, Q. Zhao, B. Li,X. Lu, R. Zhu, Y. Wu, J. Dai, J. Wang, J. Shi, W. Ouyang, C. C. Loy, andD. Lin, "MMDetection: Open mmlab detection toolbox and benchmark,"arXiv preprint arXiv:1906.07155, 2019.
[37] S. Shao, Z. Li, T. Zhang, C. Peng, G. Yu, X. Zhang, J. Li, and J. Sun,"Objects365: A large-scale, high-quality dataset for object detection,"in Proceedings of the IEEE/CVF international conference on computervision, 2019, pp. 8430--8439.
[38] D. A. Hudson and C. D. Manning, "Gqa: A new dataset for real-worldvisual reasoning and compositional question answering," in Proceedingsof the IEEE/CVF conference on computer vision and pattern recognition,2019, pp. 6700--6709.
[39] B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hocken maier, and S. Lazebnik, "Flickr30k entities: Collecting region-to-phrasecorrespondences for richer image-to-sentence models," in Proceedings ofthe IEEE international conference on computer vision, 2015, pp. 2641--2649.
[40] K. He, X. Zhang, S. Ren, and J. Sun, "Deep residual learning for imagerecognition," in 2016 IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2016, pp. 770--778.
[41] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, andB. Guo, "Swin transformer: Hierarchical vision transformer using shiftedwindows," in Proceedings of the IEEE/CVF International Conference onComputer Vision (ICCV), 2021.
[42] A. Dave, P. Dollar, D. Ramanan, A. Kirillov, and R. Girshick, "Evaluat- ´ing large-vocabulary object detectors: The devil is in the details," arXivpreprint arXiv:2102.01066, 2021【本节完】
本文由 youcans@xidian 对论文 Mamba-YOLO-World: Marrying YOLO-World with Mamba for Open-Vocabulary Detection 进行摘编和翻译。该论文版权属于原文期刊和作者,译文只供研究学习使用。
引用格式: Wang Haoxuan, He Qingdong, Peng Jinlong, Yang Hao, Chi Mingmin, Wang Yabiao. Mamba-YOLO-World: Marrying YOLO-World with Mamba for Open-Vocabulary Detection©//ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025:1-5.
版权声明:
youcans@xidian 作品,转载必须标注原文链接:
【跟我学YOLO】Mamba-YOLO-World:YOLO-World与Mamba 融合的开放词汇目标检测(https://youcans.blog.csdn.net/article/details/155461540)
Copyright 2025 by youcans@Xidian
Crated:2025-12