知识点回顾:
- 类的定义
- pass 占位语句
- 类的初始化方法
- 类的普通方法
- 类的继承:属性的继承、方法的继承
零基础学 Python 类相关知识点(超详细拆解)
先跟你说个核心:类是用来描述 "一类事物" 的模板,比如 "小狗" 这个类,能定义所有小狗都有的特征(名字、颜色)和行为(叫、跑);而具体的某只小狗(比如叫旺财的黄狗)就是这个类的 "对象"。就像做包子的模具是 "类",用模具做出的每个包子是 "对象"。
下面一步步拆解,每个知识点都配 "通俗解释 + 代码 + 代码解释",保证你能懂。
知识点 1:类的定义(最基础的框架)
通俗解释
定义类就像 "创建一个模板",需要用 Python 的关键字class,格式是固定的,类名要遵守 "大驼峰规则"(每个单词首字母大写,比如Dog、XiaoGou,别用dog或xiao_gou),最后加冒号,缩进的内容都是类的 "内部内容"。
基本语法
python
class 类名:
# 类的内部内容(暂时可以先空着)代码示例(先定义一个空的小狗类)
python
# 定义一个名为Dog的类(小狗类)
class Dog:
# 暂时先不写任何内容,但是空着会报错,所以需要用pass(下一个知识点讲)
pass代码解释
class Dog::告诉 Python "我要定义一个叫 Dog 的类";- 缩进的
pass:占位置用,避免类里空着报错; - 这一步只是创建了 "小狗模板",还没做出具体的小狗(对象)。
小总结
定义类的核心步骤:
- 写
class+ 类名(大驼峰) + 冒号; - 缩进写类的内容(空内容时加
pass)。
知识点 2:pass 占位语句
通俗解释
pass就像 "临时占座的纸条"------Python 规定 "类、函数、循环" 等结构里不能空着(空着会报错),但你暂时没想好写什么内容时,放一个pass,Python 就知道 "这里暂时没内容,不用报错",它不执行任何操作,只是占位置。
适用场景
- 定义空类(比如上面的 Dog 类);
- 定义空函数;
- 空的 if/for/while 语句里。
代码示例(不同场景的 pass)
python
# 场景1:空类里的pass(最常用)
class Cat:
pass # 占位置,避免报错
# 场景2:空函数里的pass
def say_hello():
pass # 暂时没想好函数要做什么,先占位置
# 场景3:空循环里的pass
for i in range(5):
pass # 暂时不想循环做事,先占位置小总结
pass的唯一作用:占位,让代码不报错,本身不执行任何功能 ,后续可以把pass替换成真正的代码。
知识点 3:类的初始化方法 init (给对象加 "特征 / 属性")
通俗解释
初始化方法(也叫构造方法)是 "创建对象时自动执行的方法"------ 就像你用包子模具做包子时,模具会自动给每个包子压出花纹(特征);用Dog类创建具体小狗时,__init__会自动给这只小狗设置名字、颜色等特征(属性)。
核心要点
- 方法名是固定的:
__init__(前后各两个下划线,别少写!); - 第一个参数必须是
self(代表 "当前创建的那个对象本身",比如创建旺财时,self就是旺财;创建来福时,self就是来福); - 创建对象时,会自动调用这个方法,不用手动调;
- 可以在
__init__里定义对象的 "属性"(特征),格式是self.属性名 = 属性值。
代码示例(给小狗类加初始化方法,设置名字和颜色)
python
# 定义Dog类,加初始化方法
class Dog:
# 初始化方法:self必须是第一个参数,后面可以加自定义参数(name、color)
def __init__(self, name, color):
# 给对象设置属性:self.属性名 = 参数值
self.name = name # 名字属性
self.color = color # 颜色属性
# 用Dog类创建具体的小狗对象(旺财)
# 创建对象时,要传__init__里除了self之外的参数(name和color)
wang_cai = Dog("旺财", "黄色")
# 打印旺财的属性(验证是否设置成功)
print("小狗名字:", wang_cai.name) # 输出:小狗名字: 旺财
print("小狗颜色:", wang_cai.color) # 输出:小狗颜色: 黄色代码解释
def __init__(self, name, color)::定义初始化方法,self是必传的第一个参数(不用手动传,Python 自动传),name和color是我们自定义的参数(用来给小狗设置名字和颜色);self.name = name:把传入的name值绑定到 "当前对象" 的name属性上,比如创建旺财时,self.name就是wang_cai.name;wang_cai = Dog("旺财", "黄色"):创建具体的小狗对象,此时 Python 自动调用__init__方法,把 "旺财" 传给name,"黄色" 传给color;wang_cai.name:访问对象的属性,就是取初始化时设置的值。
小总结
初始化方法的核心:
- 固定写法
__init__(self, ...); - 作用是 "创建对象时自动给对象设置属性";
self代表当前对象,给属性赋值必须加self.。
知识点 4:类的普通方法(给对象加 "行为 / 动作")
通俗解释
普通方法是类里定义的 "函数",用来描述对象的行为(比如小狗叫、跑),必须通过 "对象。方法名 ()" 调用,而且方法的第一个参数必须是self(和__init__一样,self代表当前对象)。
基本语法
python
class 类名:
def __init__(self, 属性1, 属性2):
self.属性1 = 属性1
self.属性2 = 属性2
# 定义普通方法
def 方法名(self, 可选参数):
# 方法的功能代码(可以用self.属性访问对象的特征)
执行的操作代码示例(给小狗类加 "叫" 和 "跑" 的方法)
python
class Dog:
# 初始化方法:设置名字和颜色属性
def __init__(self, name, color):
self.name = name
self.color = color
# 普通方法1:小狗叫(无额外参数)
def bark(self):
# 方法里可以用self.属性访问当前对象的名字
print(f"{self.name}({self.color})汪汪叫!")
# 普通方法2:小狗跑(带额外参数:跑的距离)
def run(self, distance):
print(f"{self.name}跑了{distance}米!")
# 创建具体的小狗对象:旺财
wang_cai = Dog("旺财", "黄色")
# 调用旺财的"叫"方法(对象.方法名())
wang_cai.bark() # 输出:旺财(黄色)汪汪叫!
# 调用旺财的"跑"方法(传额外参数50)
wang_cai.run(50) # 输出:旺财跑了50米!
# 再创建一个对象:来福,验证方法是否独立
lai_fu = Dog("来福", "黑色")
lai_fu.bark() # 输出:来福(黑色)汪汪叫!
lai_fu.run(100) # 输出:来福跑了100米!代码解释
def bark(self)::定义 "叫" 的方法,第一个参数是self,方法里用self.name和self.color访问当前对象的属性;wang_cai.bark():调用方法时,不用传self参数(Python 自动把wang_cai传给self);def run(self, distance)::带额外参数的方法,调用时需要传distance(比如 50);- 每个对象的方法调用是独立的:旺财叫和来福叫,输出的内容不一样,因为
self对应的对象不同。
小总结
类的普通方法核心:
- 定义时第一个参数必须是
self; - 调用时用
对象.方法名(),不用传self; - 方法里可以通过
self.属性访问对象的特征。
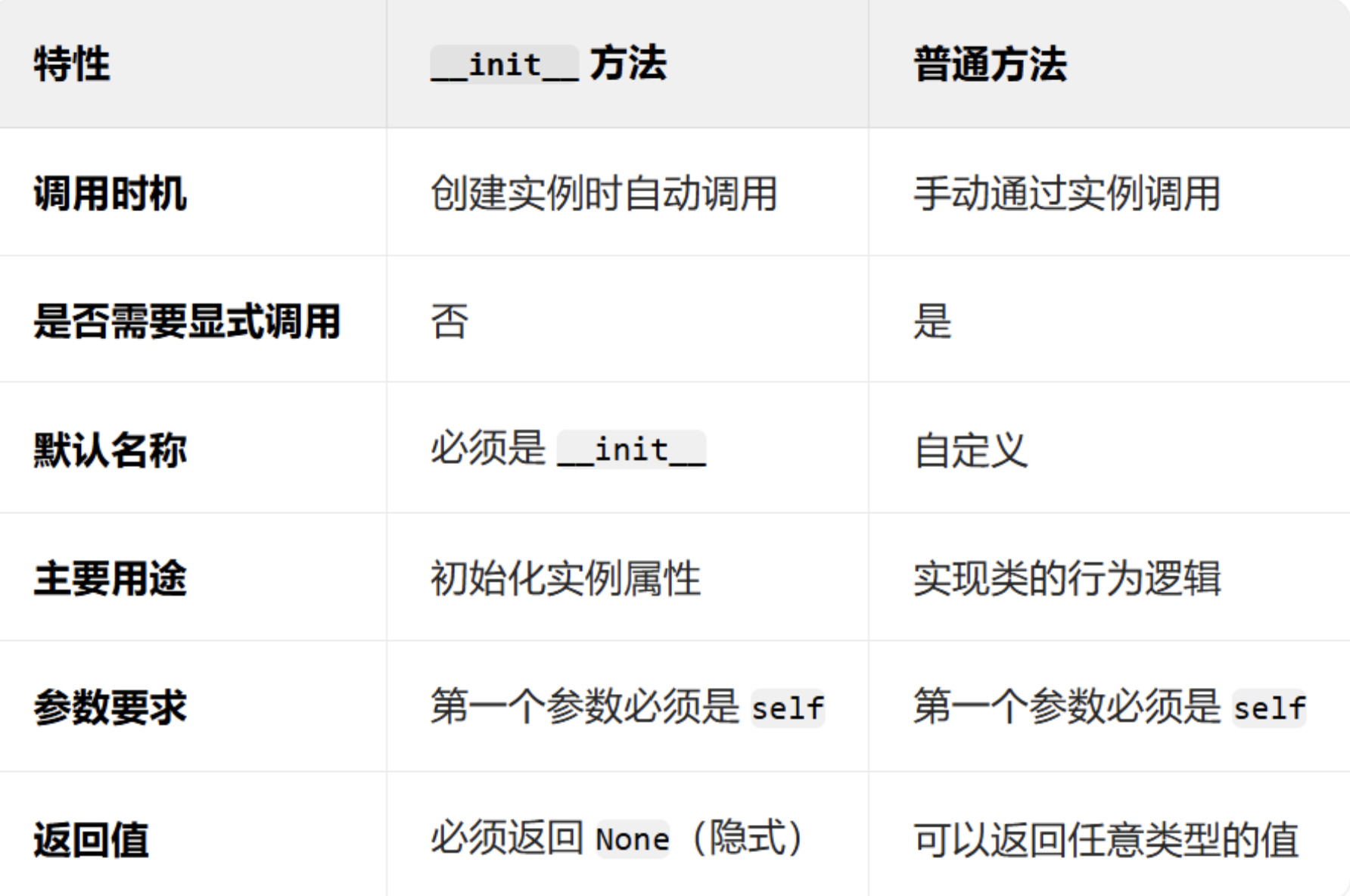
知识点 5:类的继承(属性的继承 + 方法的继承)
通俗解释
继承就像 "儿子继承爸爸的财产和技能"------子类(比如 "哈士奇")可以继承父类(比如 "小狗")的所有属性和方法,不用重复写代码,子类还能在父类的基础上加自己的属性 / 方法。
- 父类:被继承的类(比如 "小狗" 类),也叫 "基类";
- 子类:继承父类的类(比如 "哈士奇" 类),也叫 "派生类"。
基本语法
python
# 定义父类
class 父类名:
# 父类的属性和方法
# 定义子类,继承父类(括号里写父类名)
class 子类名(父类名):
# 子类的内容(可以继承父类的所有属性/方法,也可以加自己的)子知识点 5.1:属性的继承
通俗解释
子类创建的对象,能直接用父类__init__里定义的属性,不用在子类里重复写。如果子类想加自己的属性,需要在子类的__init__里先调用父类的__init__,再加自己的属性。
代码示例(属性继承:哈士奇继承小狗的名字 / 颜色,再加 "拆家等级" 属性)
python
# 第一步:定义父类(Dog:小狗类)
class Dog:
def __init__(self, name, color):
self.name = name # 父类的属性1:名字
self.color = color # 父类的属性2:颜色
# 第二步:定义子类(Husky:哈士奇类),继承Dog类
class Husky(Dog):
def __init__(self, name, color, chai_jia_level):
# 第一步:调用父类的__init__,继承父类的属性(必须先写这行)
super().__init__(name, color) # super()代表父类,调用父类的初始化方法
# 第二步:加子类自己的属性
self.chai_jia_level = chai_jia_level # 子类独有的属性:拆家等级
# 第三步:创建子类对象(哈士奇:二哈)
erha = Husky("二哈", "黑白", 10)
# 第四步:访问继承的属性(父类的name、color)和子类自己的属性
print("名字:", erha.name) # 继承的属性,输出:名字: 二哈
print("颜色:", erha.color) # 继承的属性,输出:颜色: 黑白
print("拆家等级:", erha.chai_jia_level) # 子类自己的属性,输出:拆家等级: 10代码解释
class Husky(Dog)::Husky 是子类,括号里写 Dog,代表继承 Dog 类;super().__init__(name, color):super()是 Python 内置函数,用来 "调用父类的方法",这里调用父类的__init__,把 name 和 color 传进去,这样子类对象就能继承 name 和 color 属性;self.chai_jia_level = chai_jia_level:子类独有的属性,只有哈士奇有,普通小狗没有。
子知识点 5.2:方法的继承
通俗解释
子类能直接调用父类定义的普通方法,不用重复写。如果子类想修改父类的方法(比如哈士奇的 "叫" 和普通小狗不一样),可以重写方法(子类里写和父类同名的方法)。
代码示例(方法继承 + 方法重写)
python
# 父类:Dog(小狗类)
class Dog:
def __init__(self, name, color):
self.name = name
self.color = color
# 父类的普通方法:叫
def bark(self):
print(f"{self.name}普通汪汪叫!")
# 父类的普通方法:跑
def run(self):
print(f"{self.name}慢慢跑!")
# 子类:Husky(哈士奇类),继承Dog
class Husky(Dog):
def __init__(self, name, color, chai_jia_level):
super().__init__(name, color)
self.chai_jia_level = chai_jia_level
# 重写父类的bark方法(子类的方法名和父类一样,就是重写)
def bark(self):
print(f"{self.name}(哈士奇)嗷呜嗷呜叫!")
# 创建子类对象:二哈
erha = Husky("二哈", "黑白", 10)
# 1. 调用继承的方法(父类的run方法,子类没重写,直接用)
erha.run() # 输出:二哈慢慢跑!
# 2. 调用重写的方法(子类自己的bark方法,覆盖父类)
erha.bark() # 输出:二哈(哈士奇)嗷呜嗷呜叫!
# 3. 对比:创建父类对象(普通小狗)
pu_gou = Dog("普通小狗", "黄色")
pu_gou.bark() # 输出:普通小狗普通汪汪叫!代码解释
- 子类继承父类后,不用写
run方法,就能直接调用erha.run(),这就是 "方法的继承"; - 子类写了和父类同名的
bark方法,调用时会优先用子类的方法(覆盖父类),这叫 "方法重写"(也叫方法覆盖); super()也能调用父类被重写的方法(比如想在子类 bark 里加父类的 bark):
python
def bark(self):
super().bark() # 调用父类的bark
print(f"{self.name}(哈士奇)嗷呜嗷呜叫!")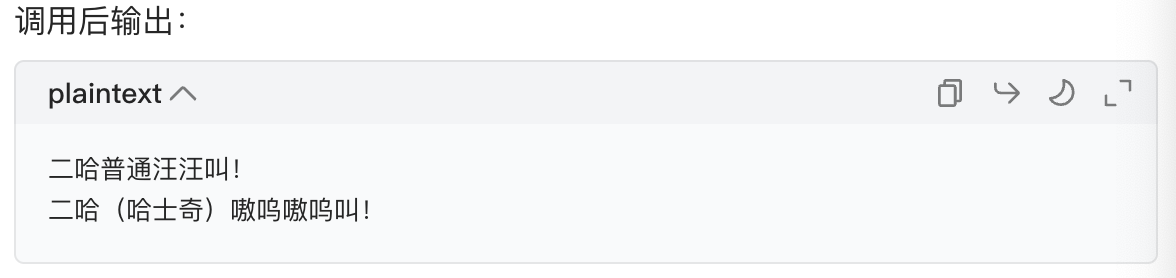
小总结(继承的核心)
- 子类定义格式:
class 子类名(父类名):; - 属性继承:子类
__init__里用super().__init__(父类参数)调用父类初始化,就能继承父类属性; - 方法继承:子类能直接用父类的普通方法,不用重复写;
- 方法重写:子类写和父类同名的方法,会覆盖父类的方法(实现子类特有的行为)。
整体总结(快速回顾)
| 知识点 | 核心要点 |
|---|---|
| 类的定义 | class 类名(大驼峰): + 缩进内容,空内容加pass |
| pass | 占位语句,避免空结构报错,无实际功能 |
| 初始化方法 | __init__(self, 参数),创建对象时自动执行,用self.属性定义对象特征 |
| 普通方法 | def 方法名(self, 参数),用对象.方法名()调用,self代表当前对象 |
| 类的继承 | 子类括号写父类名,用super()继承父类属性 / 方法,同名方法会重写父类方法 |
动手练一练(必做!)
按下面步骤写代码,验证你是否真的懂了:
- 定义一个父类
Animal(动物类),初始化方法有name(名字)、age(年龄),普通方法eat()(打印 "XX 在吃东西"); - 定义子类
Cat(猫类),继承Animal,加自己的属性hobby(爱好,比如抓老鼠),重写eat()方法(打印 "XX 爱吃小鱼干"); - 创建
Cat对象(比如名字 "咪咪",年龄 2,爱好 "抓老鼠"); - 打印对象的所有属性,调用
eat()方法。
参考答案(先自己写,再对照)
python
# 父类:Animal
class Animal:
def __init__(self, name, age):
self.name = name
self.age = age
def eat(self):
print(f"{self.name}在吃东西!")
# 子类:Cat
class Cat(Animal):
def __init__(self, name, age, hobby):
super().__init__(name, age)
self.hobby = hobby
def eat(self):
print(f"{self.name}爱吃小鱼干!")
# 创建Cat对象
mimi = Cat("咪咪", 2, "抓老鼠")
# 打印属性
print("名字:", mimi.name) # 名字: 咪咪
print("年龄:", mimi.age) # 年龄: 2
print("爱好:", mimi.hobby) # 爱好: 抓老鼠
# 调用方法
mimi.eat() # 咪咪爱吃小鱼干!如果能独立写出这段代码,说明你已经掌握了所有知识点!如果哪里卡壳,回头再看对应的知识点拆解,多写几遍就会了。零基础学编程,"多写代码" 比 "多看" 重要 10 倍~
类的属性和方法的访问控制有哪些?
先通俗解释核心:访问控制就是规定 "类的属性 / 方法" 能被谁访问、能不能修改------ 就像你家的东西:
- 客厅的沙发(公开):谁都能坐(外部、子类都能访问);
- 卧室的衣柜(受保护):只有家人能碰(提醒外部别用,子类能访问);
- 保险柜(私有):只有你自己能开(外部、子类都直接访问不到)。
Python 没有像 Java/C++ 那样严格的 "公有 / 私有" 关键字,而是靠命名约定实现访问控制,主要分 3 类,下面逐个拆解(还是用小狗类举例,保持和之前一致,降低理解成本)。
1. 公开属性 / 方法(默认,无下划线)
通俗解释
最常用的类型,没有任何下划线开头,类外部、子类都能自由访问、修改 ,就像客厅的沙发,谁都能用。这是 Python 里默认的访问级别,之前学的name、color、bark()都是公开的。
代码示例(回顾 + 验证公开访问)
python
class Dog:
# 公开属性(初始化方法里定义,无下划线)
def __init__(self, name, age):
self.name = name # 公开属性
self.age = age # 公开属性
# 公开方法(无下划线)
def bark(self):
print(f"{self.name}汪汪叫!")
# ========== 类外部访问/修改公开属性/方法 ==========
# 创建对象
wang_cai = Dog("旺财", 2)
# 1. 访问公开属性
print("名字(外部访问):", wang_cai.name) # 输出:名字(外部访问): 旺财
print("年龄(外部访问):", wang_cai.age) # 输出:年龄(外部访问): 2
# 2. 修改公开属性(直接改)
wang_cai.age = 3
print("修改后的年龄:", wang_cai.age) # 输出:修改后的年龄: 3
# 3. 调用公开方法
wang_cai.bark() # 输出:旺财汪汪叫!
# ========== 子类访问公开属性/方法 ==========
class Husky(Dog):
def show_info(self):
# 子类里访问父类的公开属性
print(f"子类访问:名字={self.name},年龄={self.age}")
erha = Husky("二哈", 1)
erha.show_info() # 输出:子类访问:名字=二哈,年龄=1
erha.bark() # 子类调用父类公开方法,输出:二哈汪汪叫!小总结
- 命名:无任何下划线开头;
- 访问范围:类外部、子类都能自由访问、修改;
- 适用场景:需要对外暴露的属性 / 方法(比如小狗的名字、叫的行为)。
2. 受保护的属性 / 方法(单下划线_开头)
通俗解释
命名时加一个下划线开头 (_属性名/_方法名),这是 Python 里的 "约定俗成"------ 告诉开发者:"这个属性 / 方法是类内部用的,外部最好别直接访问 / 修改",但 Python 不会强制禁止,只是 "提醒"。就像家里的卧室,虽然外人能进,但礼貌上不该进;子类能正常访问(家人能进)。
核心要点
- 命名:单下划线开头(
_xxx); - 访问规则:✅ 类内部、子类能正常访问 / 修改;❗ 类外部 "能访问,但不建议"(PEP8 编码规范不推荐);
- 本质:Python 没有真正限制,只是开发者之间的 "君子协定"。
代码示例(受保护属性 / 方法)
python
class Dog:
def __init__(self, name, age, health):
self.name = name # 公开属性
self._health = health # 受保护属性(单下划线):健康值,内部用
# 受保护方法(单下划线):内部检查健康
def _check_health(self):
print(f"{self.name}的健康值:{self._health}")
return self._health > 80 # 健康值>80返回True
# 公开方法:对外提供的"查看健康"接口(调用内部受保护方法)
def show_health(self):
if self._check_health():
print(f"{self.name}身体健康!")
else:
print(f"{self.name}需要看医生!")
# ========== 类外部访问受保护属性/方法(不推荐,但能访问) ==========
wang_cai = Dog("旺财", 2, 85)
# 1. 外部访问受保护属性(能访问,但IDE会标黄提醒)
print("外部访问健康值:", wang_cai._health) # 输出:外部访问健康值: 85
# 2. 外部调用受保护方法(能调用,但不推荐)
wang_cai._check_health() # 输出:旺财的健康值:85
# 3. 外部修改受保护属性(能修改,但风险高)
wang_cai._health = 50
wang_cai.show_health() # 输出:旺财需要看医生!
# ========== 子类访问受保护属性/方法(正常访问) ==========
class Husky(Dog):
def check_husky_health(self):
# 子类访问父类的受保护属性
print(f"二哈健康值:{self._health}")
# 子类调用父类的受保护方法
self._check_health()
erha = Husky("二哈", 1, 90)
erha.check_husky_health()
# 输出:
# 二哈健康值:90
# 二哈的健康值:90代码解释
self._health = health:定义受保护属性,代表 "健康值" 是类内部管理的,外部不该直接改(比如随便改成负数就不合理);def _check_health(self)::受保护方法,内部用来检查健康,对外不直接暴露,而是通过公开方法show_health()调用;- 子类
Husky里能正常访问_health和_check_health(),因为子类属于 "内部范围"。
小总结
- 命名:单下划线开头(
_xxx); - 访问规则:类内部 / 子类自由访问,外部能访问但不推荐;
- 适用场景:类内部辅助的属性 / 方法(比如健康检查),不想对外暴露,但子类需要用。
3. 私有属性 / 方法(双下划线__开头)
通俗解释
命名时加两个下划线开头 (__属性名/__方法名),Python 会自动做 "名字改写"(也叫 "名称修饰"),把__xxx改成_类名__xxx,导致类外部、子类都无法直接访问,是真正的 "内部专用",就像保险柜,只有自己能开。
核心要点
- 命名:双下划线开头(
__xxx); - 访问规则:✅ 只有类内部能访问 / 修改;❌ 类外部、子类都无法直接访问(会报错);
- 本质:Python 通过 "名字改写" 实现私有,不是真正的 "权限控制",但足够阻止外部随意访问。
代码示例(私有属性 / 方法)
python
class Dog:
def __init__(self, name, age, secret):
self.name = name # 公开属性
self.__secret = secret # 私有属性(双下划线):小狗的秘密
# 私有方法(双下划线):内部处理秘密
def __keep_secret(self):
print(f"{self.name}的秘密:{self.__secret},不能告诉别人!")
# 公开方法:对外提供"间接访问秘密"的接口(类内部能调用私有方法)
def tell_secret_to_master(self):
self.__keep_secret() # 类内部调用私有方法
# ========== 类外部访问私有属性/方法(直接访问会报错) ==========
wang_cai = Dog("旺财", 2, "偷吃过骨头")
# 1. 外部直接访问私有属性(报错!)
# print(wang_cai.__secret) # 运行会报:AttributeError: 'Dog' object has no attribute '__secret'
# 2. 外部直接调用私有方法(报错!)
# wang_cai.__keep_secret() # 运行会报:AttributeError: 'Dog' object has no attribute '__keep_secret'
# 3. 外部通过"改写后的名字"访问(不推荐,破坏封装)
# Python把__secret改成了_Dog__secret,强行访问能拿到,但绝对不推荐!
print("强行访问私有属性:", wang_cai._Dog__secret) # 输出:强行访问私有属性:偷吃过骨头
# 4. 外部通过公开方法间接访问私有内容(推荐方式)
wang_cai.tell_secret_to_master() # 输出:旺财的秘密:偷吃过骨头,不能告诉别人!
# ========== 子类访问父类私有属性/方法(直接访问会报错) ==========
class Husky(Dog):
def get_secret(self):
# 子类直接访问父类私有属性(报错!)
# print(self.__secret) # 运行报:AttributeError: 'Husky' object has no attribute '__secret'
pass
erha = Husky("二哈", 1, "拆家没被发现")
# erha.get_secret() # 调用会报错代码解释
self.__secret = secret:定义私有属性,Python 会自动把它改成_Dog__secret,外部直接写__secret找不到这个属性;def __keep_secret(self)::私有方法,同样会被改名为_Dog__keep_secret,外部无法直接调用;tell_secret_to_master():公开方法,作为 "接口" 对外提供访问私有内容的方式,既保证了私有内容不被随意访问,又能按需暴露(比如只告诉主人)。
小总结
- 命名:双下划线开头(
__xxx); - 访问规则:仅类内部能访问,外部 / 子类直接访问报错;
- 适用场景:类的核心隐私内容(比如密码、核心逻辑),绝对不想被外部 / 子类修改或访问。
关键补充:如何 "安全访问" 私有 / 受保护属性?
既然私有 / 受保护属性不建议外部直接改,那如果需要修改(比如改小狗的健康值),该怎么做?✅ 推荐方式:定义公开的 "getter/setter 方法"(获取 / 设置属性的接口),在方法里加校验逻辑,避免非法修改。
代码示例(安全修改受保护 / 私有属性)
python
class Dog:
def __init__(self, name, age, health):
self.name = name
self._health = health # 受保护属性
self.__password = 123456 # 私有属性(密码)
# getter方法:获取健康值(对外提供读取接口)
def get_health(self):
return self._health
# setter方法:修改健康值(加校验,避免非法值)
def set_health(self, new_health):
if 0 <= new_health <= 100: # 校验:健康值必须在0-100之间
self._health = new_health
print(f"健康值修改成功,新值:{self._health}")
else:
print("健康值必须在0-100之间!修改失败!")
# getter方法:获取密码(仅主人能看)
def get_password(self, master_pwd):
if master_pwd == "admin123": # 校验主人密码
return self.__password
else:
return "密码错误,无权查看!"
# 测试安全访问
wang_cai = Dog("旺财", 2, 85)
# 1. 安全修改受保护属性(通过setter方法)
wang_cai.set_health(95) # 输出:健康值修改成功,新值:95
wang_cai.set_health(150) # 输出:健康值必须在0-100之间!修改失败!
# 2. 安全获取受保护属性(通过getter方法)
print("当前健康值:", wang_cai.get_health()) # 输出:当前健康值:95
# 3. 安全获取私有属性(通过带校验的getter方法)
print(wang_cai.get_password("123")) # 输出:密码错误,无权查看!
print(wang_cai.get_password("admin123")) # 输出:123456代码解释
get_health()/set_health():专门用来读取 / 修改健康值的接口,在set_health里加了校验,避免健康值被改成负数或超过 100;get_password():获取私有密码的接口,加了主人密码校验,只有密码正确才能拿到,保证了隐私安全。
整体总结(对比表)
| 访问级别 | 命名规则 | 类内部访问 | 子类访问 | 类外部访问 | 适用场景 |
|---|---|---|---|---|---|
| 公开 | 无下划线(xxx) | ✅ 能 | ✅ 能 | ✅ 能 | 对外暴露的属性 / 方法(如名字) |
| 受保护 | 单下划线(_xxx) | ✅ 能 | ✅ 能 | ❗ 不推荐 | 类内部辅助,子类需用(如健康值) |
| 私有 | 双下划线(__xxx) | ✅ 能 | ❌ 不能 | ❌ 不能 | 核心隐私内容(如密码) |
动手练一练(必做!)
按下面步骤写代码,验证访问控制:
- 定义父类
Person(人类):- 公开属性:
name(姓名); - 受保护属性:
_salary(工资,内部用); - 私有属性:
__id_card(身份证号); - 公开方法:
show_info()(打印姓名 + 工资,调用内部受保护属性); - 私有方法:
__check_id()(打印身份证号); - 公开方法:
verify_id(master_pwd)(校验密码后调用私有方法)。
- 公开属性:
- 创建
Person对象,测试:- 访问公开属性 / 方法;
- 尝试直接访问受保护 / 私有属性(看是否提醒 / 报错);
- 通过公开方法修改受保护属性(加校验:工资≥0);
- 通过
verify_id访问私有方法(密码正确才显示身份证)。
- 定义子类
Employee(员工类)继承Person,测试子类能否访问父类的受保护属性、私有属性。
参考答案(先自己写,再对照)
python
# 父类:Person
class Person:
def __init__(self, name, salary, id_card):
self.name = name # 公开属性
self._salary = salary # 受保护属性
self.__id_card = id_card # 私有属性
# 公开方法:显示信息
def show_info(self):
print(f"姓名:{self.name},工资:{self._salary}")
# 私有方法:检查身份证
def __check_id(self):
print(f"身份证号:{self.__id_card}")
# 公开方法:验证密码后查看身份证
def verify_id(self, pwd):
if pwd == "123456":
self.__check_id()
else:
print("密码错误,无法查看身份证!")
# setter方法:修改工资(加校验)
def set_salary(self, new_salary):
if new_salary >= 0:
self._salary = new_salary
print(f"工资修改成功:{self._salary}")
else:
print("工资不能为负数!")
# 测试父类
p1 = Person("张三", 8000, "110101199001011234")
# 1. 访问公开属性/方法
print(p1.name) # 输出:张三
p1.show_info() # 输出:姓名:张三,工资:8000
# 2. 访问受保护属性(能访问,不推荐)
print(p1._salary) # 输出:8000
p1.set_salary(9000) # 输出:工资修改成功:9000
p1.set_salary(-500) # 输出:工资不能为负数!
# 3. 访问私有属性(直接访问报错)
# print(p1.__id_card) # 报错
# 4. 验证身份证
p1.verify_id("123") # 输出:密码错误,无法查看身份证!
p1.verify_id("123456") # 输出:身份证号:110101199001011234
# 子类:Employee
class Employee(Person):
def get_salary(self):
# 子类访问父类受保护属性(正常)
print(f"员工工资:{self._salary}")
def get_id(self):
# 子类访问父类私有属性(报错)
# print(self.__id_card) # 报错
pass
# 测试子类
e1 = Employee("李四", 10000, "110101199505056789")
e1.get_salary() # 输出:员工工资:10000
# e1.get_id() # 调用会报错如果能独立完成这段代码,说明你已经掌握了访问控制的核心!记住:Python 的访问控制靠 "约定",私有属性虽然能通过改写后的名字强行访问,但实际开发中绝对不要这么做 ------ 遵守约定才能写出易维护的代码。
类的继承和多态的区别是什么?
先给核心结论:继承是 "子类拿父类的属性和方法"(减少重复代码),多态是 "子类重写父类方法后,同一调用方式有不同表现"(灵活扩展功能) ------ 继承是多态的前提,多态是继承的 "高级用法",两者解决的是不同问题。
下面用 "生活比喻 + 代码示例 + 对比拆解",让你彻底分清两者的区别和联系。
一、先回顾:继承的核心作用(减少重复代码)
通俗比喻
继承就像 "儿子继承爸爸的房子、车子和技能":爸爸会开车、会做饭,儿子不用重新学,直接就能用;儿子还能在爸爸的基础上,学自己的技能(比如编程)。
核心目的
避免代码重复:多个类有相同的属性 / 方法时,不用每个类都写一遍,只需要写一个父类,子类继承即可。
代码示例(继承的核心表现)
python
# 父类:Animal(所有动物的通用模板)
class Animal:
def __init__(self, name):
self.name = name # 所有动物都有"名字"属性(重复代码抽离到父类)
# 所有动物都有"叫"的行为(重复代码抽离到父类)
def bark(self):
print(f"{self.name}发出叫声!")
# 子类:Dog(继承Animal)
class Dog(Animal):
# 不用重写__init__和bark,直接继承父类的
pass
# 子类:Cat(继承Animal)
class Cat(Animal):
# 不用重写__init__和bark,直接继承父类的
pass
# 测试继承
dog = Dog("旺财")
cat = Cat("咪咪")
dog.bark() # 输出:旺财发出叫声!(继承父类的bark)
cat.bark() # 输出:咪咪发出叫声!(继承父类的bark)继承的关键特征
- 子类 → 父类:子类能直接用父类的属性和方法,不用重复写;
- 核心价值:解决 "代码冗余"(比如多个动物类都有 name 和 bark,父类写一次就行)。
二、多态的核心作用(同一行为,不同表现)
通俗比喻
多态就像 "爸爸说'叫一声',儿子汪汪叫,女儿喵喵叫":同一个指令(调用 bark 方法),不同的子类(Dog/Cat)有不同的执行结果 ------ 这就是 "同一行为的不同表现"。
核心目的
灵活扩展功能:在继承的基础上,子类可以重写父类的方法,让同一方法调用适配不同子类,不用修改原有代码就能新增功能(符合 "开闭原则")。
代码示例(多态的核心表现)
基于上面的继承代码,给子类重写bark方法:
python
# 父类:Animal(不变)
class Animal:
def __init__(self, name):
self.name = name
def bark(self):
print(f"{self.name}发出叫声!") # 父类的通用行为
# 子类:Dog(重写父类的bark方法)
class Dog(Animal):
def bark(self):
print(f"{self.name}汪汪叫!") # 子类的特有表现
# 子类:Cat(重写父类的bark方法)
class Cat(Animal):
def bark(self):
print(f"{self.name}喵喵叫!") # 子类的特有表现
# 新增子类:Duck(继承+重写,体现多态的扩展性)
class Duck(Animal):
def bark(self):
print(f"{self.name}嘎嘎叫!") # 新增子类不用改原有代码
# 测试多态:同一调用方式,不同结果
def make_animal_bark(animal):
# 不管传入的是Dog、Cat还是Duck,都调用bark方法(同一接口)
animal.bark()
# 创建不同子类对象
dog = Dog("旺财")
cat = Cat("咪咪")
duck = Duck("小黄")
# 同一函数调用,不同表现(多态的核心)
make_animal_bark(dog) # 输出:旺财汪汪叫!
make_animal_bark(cat) # 输出:咪咪喵喵叫!
make_animal_bark(duck) # 输出:小黄嘎嘎叫!多态的关键特征
- 依赖继承:必须先有继承(子类继承父类),才能重写方法实现多态;
- 方法重写:子类的方法名和父类完全一致(参数、返回值也一致);
- 同一接口,不同实现:调用者(比如
make_animal_bark函数)不用关心对象是哪个子类,只需要调用统一的bark方法,就能得到对应的结果; - 扩展性强:新增子类(比如 Duck)时,不用修改
make_animal_bark等原有代码,直接新增子类并重写方法即可。
三、继承和多态的核心区别(表格对比)
| 对比维度 | 继承(Inheritance) | 多态(Polymorphism) |
|---|---|---|
| 核心定义 | 子类继承父类的属性和方法,复用代码 | 子类重写父类方法,同一调用有不同表现 |
| 核心目的 | 解决 "代码冗余"(避免重复写相同代码) | 解决 "灵活扩展"(新增功能不用改原有代码) |
| 依赖关系 | 独立存在(不需要多态就能用) | 依赖继承(没有继承就没有多态) |
| 代码特征 | 子类直接使用父类的属性 / 方法,不用重写 | 子类重写父类的方法(方法名、参数一致) |
| 使用场景 | 多个类有相同的属性 / 方法(比如所有动物都有名字) | 多个子类有相同行为但实现不同(比如动物叫的方式不同) |
| 形象比喻 | 儿子继承爸爸的房子、车子(直接用) | 爸爸说 "赚钱",儿子上班赚钱,女儿创业赚钱(同一目标不同方式) |
四、关键关联:继承是多态的 "前提"
没有继承,就没有多态 ------ 因为多态的本质是 "子类重写父类的方法",而重写的前提是子类继承了父类的方法。
举个反例:如果没有继承,Dog 和 Cat 是完全独立的类,就算都有bark方法,也不算多态(只是 "碰巧方法名相同"),因为无法用统一的接口调用(比如make_animal_bark函数无法同时接收 Dog 和 Cat 对象)。
只有通过继承,让 Dog、Cat、Duck 都属于 "Animal 家族",才能用统一的Animal类型接口调用bark方法,这才是多态的核心价值。
五、求职场景:继承和多态在数据分析 / 机器学习中的应用
作为准备求职的零基础学习者,你需要知道这两个概念在实际工作中的用途:
继承的应用:
- 比如定义
DataProcessor(数据处理器)父类,包含 "读取数据""清洗数据" 等通用方法; - 子类
CSVProcessor(CSV 数据处理器)、ExcelProcessor(Excel 数据处理器)继承父类,不用重复写 "读取 / 清洗" 的通用逻辑,只需要重写 "解析文件" 的特有逻辑。
多态的应用:
- 比如机器学习中,定义
Model(模型)父类,包含train(训练)、predict(预测)方法; - 子类
LinearRegression(线性回归)、DecisionTree(决策树)继承父类,重写train和predict方法(不同模型的训练 / 预测逻辑不同); - 调用时,不管是线性回归还是决策树,都能用
model.train()训练、model.predict()预测,不用修改调用代码,方便切换模型。
六、动手练一练(巩固区别)
按要求写代码,体会继承和多态的区别:
-
定义父类
Shape(图形),包含calculate_area(计算面积)方法(默认打印 "计算图形面积"); -
定义子类
Rectangle(矩形)、Triangle(三角形),继承Shape:
- 矩形需要属性
width(宽)、height(高),重写calculate_area(面积 = 宽 × 高); - 三角形需要属性
base(底)、height(高),重写calculate_area(面积 = 底 × 高 ÷2);
3.写一个统一的函数print_area(shape),接收任意图形对象,调用其calculate_area方法并打印结果;
4.测试:创建矩形、三角形对象,传入print_area函数,观察多态效果。
参考答案
python
# 父类:Shape
class Shape:
def calculate_area(self):
print("计算图形面积")
# 子类:Rectangle(继承+重写)
class Rectangle(Shape):
def __init__(self, width, height):
self.width = width
self.height = height
def calculate_area(self):
area = self.width * self.height
print(f"矩形面积:{area}")
return area
# 子类:Triangle(继承+重写)
class Triangle(Shape):
def __init__(self, base, height):
self.base = base
self.height = height
def calculate_area(self):
area = self.base * self.height / 2
print(f"三角形面积:{area}")
return area
# 统一函数(多态的体现)
def print_area(shape):
shape.calculate_area()
# 测试
rect = Rectangle(4, 5)
tri = Triangle(6, 4)
print_area(rect) # 输出:矩形面积:20
print_area(tri) # 输出:三角形面积:12.0总结
- 继承:复用代码,子类拿父类的 "基础功能";
- 多态:扩展功能,子类改写父类的 "基础功能",让同一调用适配不同子类;
- 关系:继承是多态的前提,多态是继承的高级应用,两者结合能写出 "简洁、易扩展" 的代码(这也是求职面试中考察的核心点)。
记住:零基础不用死记概念,只要能通过代码实现 "子类继承父类、重写方法、统一调用",就已经掌握了两者的核心!
类的继承和多态在实际应用中如何选择?
先明确核心结论:继承和多态不是 "二选一" 的关系,而是 "先判断是否需要继承,再判断是否需要多态" ------ 继承是 "基础复用",多态是 "继承后的扩展优化"。实际应用中,先看是否有 "代码复用 + is-a(是一种)" 的需求,再看是否有 "子类个性化实现" 的需求,最终决定如何搭配使用。
下面用 "选择思路 + 实际场景 + 求职案例" 的方式,让你彻底明白怎么选,全程贴合零基础认知和求职实际需求。
一、核心选择原则(先记牢,再理解)
| 决策步骤 | 判断标准 | 选择方案 | 核心目的 |
|---|---|---|---|
| 第一步:是否用继承? | 1. 类之间是 "is-a" 关系(比如 "狗是一种动物""矩形是一种图形");2. 多个类有重复的属性 / 方法(比如所有动物都有名字,所有图形都要算面积)。 | ✅ 用继承:抽离重复代码到父类,子类继承;❌ 不用继承:类之间是 "has-a"(有一个)或关联关系(比如 "用户有订单""汽车有轮子"),用 "组合 / 关联" 代替。 | 解决代码冗余,减少重复开发 |
| 第二步:是否用多态? | 继承后,子类需要对父类的某个方法做 "个性化实现"(比如 "狗叫" 和 "猫叫" 逻辑不同,"矩形算面积" 和 "三角形算面积" 逻辑不同)。 | ✅ 用多态:子类重写父类方法,统一接口调用;❌ 不用多态:子类完全复用父类方法,无个性化需求。 | 提升代码灵活性,方便扩展(新增子类不用改原有代码) |
二、第一步:判断是否需要继承(最关键的前置决策)
继承的核心是 "is-a" 关系 + 代码复用,没有 "is-a" 关系的继承都是 "错误使用"(零基础最易踩的坑)。
场景 1:该用继承的情况(满足 is-a + 代码复用)
通俗例子
- "哈士奇是一种狗,狗是一种动物":Animal(父类)→ Dog(子类)→ Husky(孙子类),所有动物都有
name/age,所有狗都有bark(),抽离到父类能减少重复代码。 - "CSV 数据处理器是一种数据处理器,Excel 处理器也是一种数据处理器":DataProcessor(父类)有 "读取数据、清洗数据" 的通用逻辑,子类只需关注 "解析 CSV/Excel" 的特有逻辑。
求职场景案例(数据分析方向)
python
# 父类:DataProcessor(所有数据处理器的通用逻辑)
class DataProcessor:
def __init__(self, file_path):
self.file_path = file_path # 所有处理器都需要文件路径(复用属性)
def clean_data(self, data):
# 所有处理器都需要的通用清洗逻辑(复用方法)
return data.dropna() # 删除空值
# 子类:CSVProcessor(CSV处理器,是一种DataProcessor)
class CSVProcessor(DataProcessor):
# 只需要写CSV特有的解析逻辑,复用父类的__init__和clean_data
def parse_file(self):
import pandas as pd
data = pd.read_csv(self.file_path)
return self.clean_data(data) # 复用父类的清洗方法
# 子类:ExcelProcessor(Excel处理器,是一种DataProcessor)
class ExcelProcessor(DataProcessor):
# 只需要写Excel特有的解析逻辑,复用父类的通用逻辑
def parse_file(self):
import pandas as pd
data = pd.read_excel(self.file_path)
return self.clean_data(data) # 复用父类的清洗方法
# 使用:复用了父类的文件路径和清洗逻辑,子类只写特有代码
csv_processor = CSVProcessor("data.csv")
excel_processor = ExcelProcessor("data.xlsx")
print(csv_processor.parse_file())
print(excel_processor.parse_file())场景 2:不该用继承的情况(无 is-a 关系)
通俗例子
- "用户有订单":User 类和 Order 类是 "has-a" 关系,不是 "is-a",不能让 Order 继承 User(订单不是一种用户),应该在 User 里关联 Order 对象。
- "汽车有轮子":Car 类和 Wheel 类是组合关系,不能让 Wheel 继承 Car(轮子不是一种汽车),应该在 Car 里包含 Wheel 对象。
求职场景案例(避坑)
python
# 错误示例:硬套继承(Order不是一种User,继承无意义)
class User:
def __init__(self, name):
self.name = name
class Order(User): # 错误!订单不是一种用户
def __init__(self, name, order_id):
super().__init__(name)
self.order_id = order_id
# 正确示例:关联关系(User包含Order对象)
class User:
def __init__(self, name):
self.name = name
self.orders = [] # 用户的订单列表(关联Order对象)
def add_order(self, order_id):
self.orders.append(Order(order_id))
class Order: # 独立类,不继承User
def __init__(self, order_id):
self.order_id = order_id
# 使用:正确的关联关系
user = User("张三")
user.add_order("OD001")
print(f"{user.name}的订单:{[o.order_id for o in user.orders]}")三、第二步:在继承基础上,判断是否需要多态
继承后,若子类的核心方法需要 "个性化实现",就用多态;若子类完全复用父类方法,就不用多态。
场景 1:需要继承 + 多态(子类有个性化实现)
这是实际应用中最常见的场景,核心是 "统一接口,不同实现",方便扩展和维护(求职面试高频考点)。
求职场景案例(机器学习方向)
python
# 父类:BaseModel(所有模型的通用框架)
class BaseModel:
def __init__(self, data):
self.data = data # 所有模型都需要数据(复用属性)
def train(self):
# 父类定义通用框架(也可以留空,用pass占位)
raise NotImplementedError("子类必须重写train方法") # 强制子类实现
def predict(self, x):
# 父类定义通用框架
raise NotImplementedError("子类必须重写predict方法")
# 子类:LinearRegression(线性回归,重写train/predict)
class LinearRegression(BaseModel):
def train(self):
print("训练线性回归模型...")
# 线性回归的特有训练逻辑(比如最小二乘法)
self.model = "线性回归模型"
def predict(self, x):
return f"{self.model}预测结果:{x * 0.8 + 0.2}"
# 子类:DecisionTree(决策树,重写train/predict)
class DecisionTree(BaseModel):
def train(self):
print("训练决策树模型...")
# 决策树的特有训练逻辑(比如ID3算法)
self.model = "决策树模型"
def predict(self, x):
return f"{self.model}预测结果:{x * 1.2 + 0.5}"
# 多态核心:统一接口调用,适配不同子类
def run_model(model):
model.train() # 同一调用,不同模型有不同训练逻辑
print(model.predict(5))
# 使用:新增模型时,不用改run_model函数(扩展方便)
lr_model = LinearRegression("房价数据")
dt_model = DecisionTree("房价数据")
run_model(lr_model) # 输出:训练线性回归模型... 线性回归模型预测结果:4.2
run_model(dt_model) # 输出:训练决策树模型... 决策树模型预测结果:6.5
# 新增模型(比如随机森林),只需加子类,不用改原有代码
class RandomForest(BaseModel):
def train(self):
print("训练随机森林模型...")
self.model = "随机森林模型"
def predict(self, x):
return f"{self.model}预测结果:{x * 1.0 + 0.3}"
run_model(RandomForest("房价数据")) # 无缝扩展场景 2:只需要继承(不用多态,子类完全复用父类方法)
子类只是 "复用父类的所有逻辑",没有个性化实现,此时只需继承,不用重写方法(多态无意义)。
求职场景案例(通用工具类)
python
# 父类:FileTool(文件操作通用工具)
class FileTool:
def __init__(self, file_path):
self.file_path = file_path
def read_file(self):
# 通用读取逻辑(所有文本文件都适用)
with open(self.file_path, "r", encoding="utf-8") as f:
return f.read()
def write_file(self, content):
# 通用写入逻辑
with open(self.file_path, "w", encoding="utf-8") as f:
f.write(content)
# 子类:TxtTool(TXT文件工具,完全复用父类方法)
class TxtTool(FileTool):
pass # 不用重写任何方法,直接继承
# 使用:子类完全复用父类逻辑
txt_tool = TxtTool("test.txt")
txt_tool.write_file("Hello World")
print(txt_tool.read_file()) # 输出:Hello World四、实际应用中的避坑指南(零基础必看)
坑 1:为了 "炫技" 滥用继承
❌ 错误:只要两个类有点关联就继承(比如 "订单" 继承 "用户");✅ 正确:只有满足 "is-a"+ 代码复用,才用继承,否则用 "组合 / 关联"。
坑 2:过度设计多态
❌ 错误:不管子类是否需要个性化,都强行重写父类方法;✅ 正确:只有子类需要不同实现时才用多态,简单场景(比如通用工具类)直接继承即可。
坑 3:忽略 "继承的层级"
❌ 错误:继承层级太深(比如 A→B→C→D),代码难维护;✅ 正确:继承层级控制在 2-3 层(比如 BaseModel→LinearRegression),超过 3 层优先用 "组合" 代替。
五、总结:继承 + 多态的选择流程(可直接套用)
判断是否需要继承:
- 是:类之间有 "is-a" 关系 + 有重复代码需要复用 → 定义父类,子类继承;
- 否:类之间是 "has-a"/ 关联关系 → 用组合 / 关联,不用继承。
在继承基础上,判断是否需要多态:
- 是:子类需要个性化实现父类的核心方法 → 子类重写方法,用多态(统一接口调用);
- 否:子类完全复用父类方法 → 直接继承,不用多态。
核心目标:
- 继承:让代码 "少重复";
- 多态:让代码 "易扩展"。
六、动手练一练(求职场景模拟)
按要求写代码,练习继承和多态的选择:
- 需求:实现 "数据分析器",支持 "数值型数据分析" 和 "分类型数据分析";
- 步骤:
- 第一步:判断继承:"数值分析器 / 分类分析器" 都是 "数据分析器"(is-a),定义父类
DataAnalyzer,包含通用属性(数据)和通用方法(数据校验); - 第二步:判断多态:数值分析和分类分析的 "核心分析逻辑" 不同 → 子类重写
analyze方法;
- 第一步:判断继承:"数值分析器 / 分类分析器" 都是 "数据分析器"(is-a),定义父类
- 要求:新增 "文本型数据分析器" 时,不用改原有代码。
参考答案
python
# 父类:DataAnalyzer(通用数据分析器)
class DataAnalyzer:
def __init__(self, data):
self.data = data # 通用属性
def check_data(self):
# 通用方法:数据校验
if len(self.data) == 0:
raise ValueError("数据不能为空")
print("数据校验通过")
def analyze(self):
# 强制子类重写(多态基础)
raise NotImplementedError("子类必须重写analyze方法")
# 子类1:NumericAnalyzer(数值型分析,重写analyze)
class NumericAnalyzer(DataAnalyzer):
def analyze(self):
self.check_data() # 复用父类的校验方法
print("数值型数据分析:")
print(f"均值:{sum(self.data)/len(self.data)},最大值:{max(self.data)}")
# 子类2:CategoricalAnalyzer(分类型分析,重写analyze)
class CategoricalAnalyzer(DataAnalyzer):
def analyze(self):
self.check_data() # 复用父类的校验方法
print("分类型数据分析:")
from collections import Counter
count = Counter(self.data)
print(f"类别计数:{count},最频繁类别:{count.most_common(1)[0][0]}")
# 多态调用:统一接口
def run_analysis(analyzer):
analyzer.analyze()
# 测试
numeric_analyzer = NumericAnalyzer([1,2,3,4,5])
categorical_analyzer = CategoricalAnalyzer(["男","女","男","男","女"])
run_analysis(numeric_analyzer)
run_analysis(categorical_analyzer)
# 新增子类:TextAnalyzer(文本分析,无需改原有代码)
class TextAnalyzer(DataAnalyzer):
def analyze(self):
self.check_data()
print("文本型数据分析:")
word_count = sum(len(text.split()) for text in self.data)
print(f"总词数:{word_count}")
run_analysis(TextAnalyzer(["Hello World", "Python is cool"]))通过这个练习,你能直观感受到:继承解决了 "数据校验" 的代码复用,多态解决了 "不同类型分析" 的灵活扩展 ------ 这就是实际应用中继承和多态的核心选择逻辑。
类的继承和多态的优缺点分别是什么?
先给核心结论:继承的核心价值是 "代码复用",但缺点是 "耦合度高、灵活性差";多态的核心价值是 "灵活扩展",但缺点是 "依赖继承、理解成本高"。两者是面向对象编程(OOP)的核心,实际应用中不是 "只用优点",而是 "权衡优缺点,适配场景"。
下面用 "通俗解释 + 求职场景例子 + 避坑提示",拆解两者的优缺点,全程贴合零基础认知和求职实际需求。
一、继承的优缺点(核心:复用 vs 耦合)
继承是 OOP 中最基础的复用手段,优点集中在 "减少重复代码",缺点集中在 "父子类绑定过紧,维护麻烦"。
(一)继承的优点(实际工作中最常用的 3 个)
| 优点 | 通俗解释 | 求职场景例子(数据分析 / 机器学习) |
|---|---|---|
| 1. 代码复用 | 父类写一遍通用逻辑,所有子类直接用,不用重复敲代码 | 定义DataProcessor父类包含 "数据清洗" 方法,CSVProcessor/ExcelProcessor子类直接复用,不用各自写清洗逻辑 |
| 2. 结构清晰 | 类之间的 "is-a" 关系(比如 "狗是一种动物")符合人类认知,代码层级一目了然 | BaseModel(基础模型)→ LinearRegression(线性回归)→ RidgeRegression(岭回归),模型层级清晰 |
| 3. 易维护 | 通用逻辑只改父类,所有子类自动生效,不用逐个修改子类 | 若要优化 "数据清洗" 逻辑,只需改DataProcessor.clean_data(),所有子类的清洗逻辑都会同步更新 |
代码示例(继承的优点体现)
python
# 父类:通用数据处理器(写一遍通用逻辑)
class DataProcessor:
def clean_data(self, data):
# 通用清洗逻辑:删除空值、去重(只需维护这一处)
return data.dropna().drop_duplicates()
# 子类1:CSV处理器(复用父类清洗逻辑)
class CSVProcessor(DataProcessor):
def read_data(self, path):
import pandas as pd
data = pd.read_csv(path)
return self.clean_data(data) # 复用父类方法
# 子类2:Excel处理器(复用父类清洗逻辑)
class ExcelProcessor(DataProcessor):
def read_data(self, path):
import pandas as pd
data = pd.read_excel(path)
return self.clean_data(data) # 复用父类方法
# 优点1:复用代码(子类不用写清洗逻辑);优点3:易维护(改父类clean_data即可)
csv_processor = CSVProcessor()
print(csv_processor.read_data("data.csv"))(二)继承的缺点(零基础最易踩坑的 4 个)
| 缺点 | 通俗解释 | 求职场景踩坑例子 |
|---|---|---|
| 1. 耦合度高 | 父类和子类强绑定,父类的微小修改可能导致所有子类出错 | 若给DataProcessor.clean_data加一个参数threshold,所有子类调用该方法的地方都要改,否则报错 |
| 2. 层级深难维护 | 继承层级超过 3 层(比如 A→B→C→D),找问题时要一层层溯源,调试效率低 | BaseModel→LinearModel→RidgeRegression→LassoRegression,调试时要查 4 层代码才能定位问题 |
| 3. 灵活性差 | 继承是 "静态的",运行时无法动态改变父类,无法适配临时的逻辑调整 | 若想让CSVProcessor临时用 "特殊清洗逻辑",只能改代码重写方法,无法在运行时切换 |
| 4. 易滥用 | 新手容易为了 "炫技" 给无 "is-a" 关系的类加继承(比如 "订单" 继承 "用户"),导致代码逻辑混乱 | 让Order类继承User类(订单不是一种用户),后续扩展订单功能时,会继承到用户的无关属性(如user_name),代码冗余且易出错 |
代码示例(继承的缺点体现)
python
# 坑1:耦合度高(父类改参数,子类全报错)
class DataProcessor:
# 父类新增参数threshold
def clean_data(self, data, threshold=0.5):
data = data.dropna(thresh=threshold)
return data.drop_duplicates()
class CSVProcessor(DataProcessor):
def read_data(self, path):
import pandas as pd
data = pd.read_csv(path)
# 子类调用时没传threshold,运行报错!
return self.clean_data(data) # TypeError: clean_data() missing 1 required positional argument: 'threshold'
# 坑2:层级深难维护(3层继承,找问题难)
class A:
def func(self):
print("A")
class B(A):
def func(self):
super().func()
class C(B):
def func(self):
super().func()
# 调用C的func,要查A→B→C三层才知道输出是"A"
C().func()二、多态的优缺点(核心:扩展 vs 依赖)
多态是继承的 "高级用法",优点集中在 "灵活扩展",缺点集中在 "依赖继承、理解成本高"。
(一)多态的优点(求职面试高频考点)
| 优点 | 通俗解释 | 求职场景例子 |
|---|---|---|
| 1. 灵活扩展 | 新增子类时,不用修改原有调用代码,直接适配(符合 "开闭原则") | 新增RandomForest模型子类,run_model函数不用改,直接传入即可调用 |
| 2. 统一接口 | 调用者不用关心子类类型,只需调用统一方法,降低调用复杂度 | 不管是LinearRegression还是DecisionTree,都用model.train()训练、model.predict()预测 |
| 3. 代码解耦 | 调用逻辑和具体实现分离(调用者只认父类接口,不认子类) | run_model函数只依赖BaseModel的train/predict接口,不关心具体是哪种模型 |
| 4. 易替换 | 切换子类只需改 "创建对象" 的一行代码,调用逻辑完全不变 | 把model = LinearRegression()改成model = DecisionTree(),后续model.train()/predict()不用改 |
代码示例(多态的优点体现)
python
# 父类:基础模型(统一接口)
class BaseModel:
def train(self):
raise NotImplementedError("子类必须重写")
def predict(self, x):
raise NotImplementedError("子类必须重写")
# 子类1:线性回归
class LinearRegression(BaseModel):
def train(self):
print("训练线性回归")
def predict(self, x):
return x * 0.8 + 0.2
# 子类2:决策树
class DecisionTree(BaseModel):
def train(self):
print("训练决策树")
def predict(self, x):
return x * 1.2 + 0.5
# 多态核心:统一调用逻辑(新增子类不用改这个函数)
def run_model(model):
model.train()
print("预测结果:", model.predict(5))
# 优点1:灵活扩展(新增RandomForest子类,run_model不用改)
class RandomForest(BaseModel):
def train(self):
print("训练随机森林")
def predict(self, x):
return x * 1.0 + 0.3
# 优点4:易替换(改一行代码切换模型)
run_model(LinearRegression()) # 输出:训练线性回归 → 预测结果:4.2
run_model(DecisionTree()) # 输出:训练决策树 → 预测结果:6.5
run_model(RandomForest()) # 输出:训练随机森林 → 预测结果:5.3(二)多态的缺点(零基础易困惑的 4 个)
| 缺点 | 通俗解释 | 求职场景踩坑例子 |
|---|---|---|
| 1. 依赖继承 | 多态必须基于继承(子类重写父类方法),无 "is-a" 关系的类无法用多态 | 若CSVProcessor和User无继承关系,无法用多态统一调用它们的方法 |
| 2. 理解成本高 | 零基础难理解 "同一调用不同结果" 的逻辑,比如为什么model.train()会有不同输出 |
新手会疑惑:明明调用的是train,为什么线性回归和决策树的输出不一样 |
| 3. 调试难度大 | 报错时需要定位到具体子类的方法,而不是父类接口 | model.train()报错,要查是LinearRegression还是DecisionTree的train方法有问题,增加调试步骤 |
| 4. 过度设计 | 简单场景硬用多态,会增加代码复杂度(比如通用工具类没必要重写方法) | 给FileTool父类写read_file方法,TxtTool子类完全复用即可,硬重写read_file实现多态,纯纯增加代码量 |
代码示例(多态的缺点体现)
python
# 坑1:依赖继承(无继承则无多态)
class CSVProcessor: # 无父类
def read_data(self):
print("读取CSV")
class User: # 无父类
def read_data(self):
print("读取用户数据")
# 无法用多态统一调用(因为无共同父类,调用逻辑要写两遍)
def read(proc):
proc.read_data()
# 虽然方法名相同,但不是多态(只是碰巧同名),代码冗余
read(CSVProcessor())
read(User())
# 坑4:过度设计(简单场景硬用多态)
class FileTool:
def read_file(self):
print("通用读取")
class TxtTool(FileTool):
# 完全没必要重写,硬写多态反而增加代码
def read_file(self):
print("读取TXT") # 和父类逻辑一样,纯冗余三、实际应用中的权衡技巧
1. 用继承的场景(优点 > 缺点)
- 类之间是 "is-a" 关系 + 有大量重复代码(比如所有模型都有 "数据" 属性、"训练 / 预测" 接口);
- 通用逻辑需要统一维护(比如所有数据处理器的清洗逻辑)。
2. 不用继承的场景(缺点 > 优点)
- 类之间是 "has-a"/ 关联关系(比如 "用户有订单");
- 继承层级超过 3 层(优先用 "组合" 代替,比如把
LinearRegression的逻辑拆成独立模块,组合到BaseModel中)。
3. 用多态的场景(优点 > 缺点)
- 子类需要个性化实现父类的核心方法(比如不同模型的训练逻辑不同);
- 未来可能新增子类(比如后续要加随机森林、SVM 等模型)。
4. 不用多态的场景(缺点 > 优点)
- 子类完全复用父类方法,无个性化需求(比如
TxtTool复用FileTool的read_file); - 场景简单,新增子类的概率极低(比如固定只处理 CSV 文件)。
四、核心总结(表格对比)
| 特性 | 继承 | 多态 |
|---|---|---|
| 核心价值 | 代码复用、结构清晰 | 灵活扩展、统一接口 |
| 核心缺点 | 耦合度高、层级深难维护 | 依赖继承、理解成本高 |
| 适用场景 | is-a 关系 + 重复代码多 | 子类需个性化实现 + 需扩展 |
| 避坑关键 | 控制继承层级≤3 层 | 不滥用,简单场景不用 |
| 求职高频考点 | 继承的耦合问题、组合替代 | 多态的开闭原则、接口设计 |
最后提醒(零基础学习建议)
- 不用追求 "完美使用":先掌握继承的核心(复用),再理解多态的核心(扩展),实际写代码时 "够用就好";
- 优先写 "简单代码":比如新手写数据分析工具,先不用多态,等需要新增子类时,再重构出父类 + 多态;
- 面试回答技巧:被问优缺点时,先答核心价值,再答缺点,最后补充 "实际会结合场景权衡,比如用继承复用通用逻辑,用多态扩展核心方法"。
作业练习

编写 Circle 类代码(分步拆解,结合知识点)
打开circle.py文件,按以下步骤逐行编写(每一步都标注知识点对应):
步骤 1:导入 math 模块(用于获取 π)
python
# 导入math模块,因为计算面积/周长需要用到π(math.pi)
import math✅ 知识点:Python 内置模块,math.pi是精确的圆周率值(约 3.1415926535)。
步骤 2:定义 Circle 类(类的定义知识点)
python
# 定义Circle类,类名遵守大驼峰规则(首字母大写)
class Circle:
# 步骤3:初始化方法(__init__),传入半径,默认值为1
def __init__(self, radius=1):
# 给对象绑定radius属性,self代表当前对象
self.radius = radius # 半径属性,接收传入的radius值(默认1)
# 步骤4:定义计算面积的方法(普通方法)
def calculate_area(self):
# 面积公式:π * 半径²(radius**2表示半径的平方)
area = math.pi * (self.radius ** 2)
return area # 返回计算出的面积
# 步骤5:定义计算周长的方法(普通方法)
def calculate_circumference(self):
# 周长公式:2 * π * 半径
circumference = 2 * math.pi * self.radius
return circumference # 返回计算出的周长步骤 3:编写测试代码(验证类的功能)
在类定义下方添加测试代码(模拟使用 Circle 类):
python
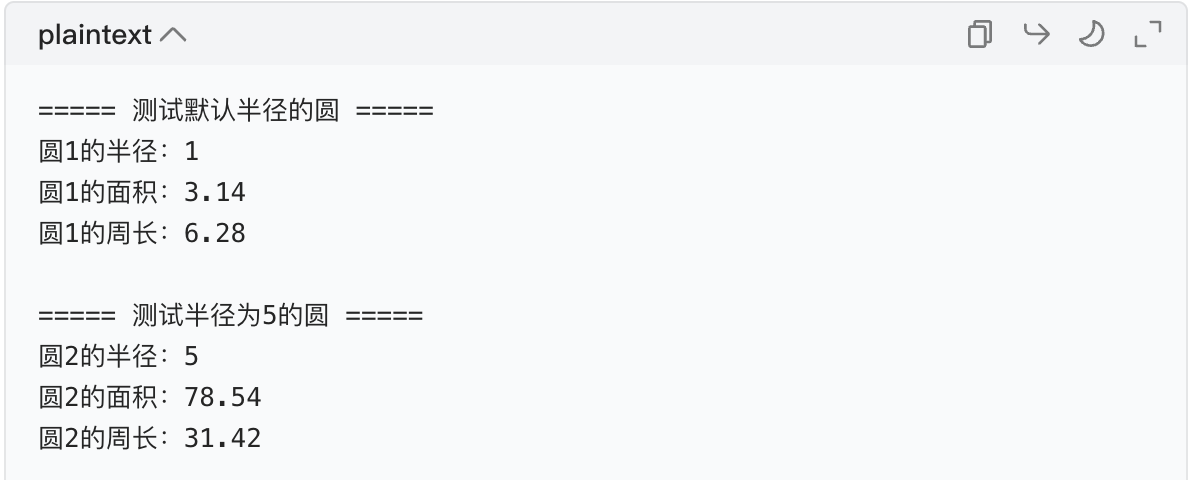
# 测试1:创建默认半径(1)的圆对象
circle1 = Circle()
print("===== 测试默认半径的圆 =====")
print(f"圆1的半径:{circle1.radius}")
print(f"圆1的面积:{circle1.calculate_area():.2f}") # .2f保留2位小数
print(f"圆1的周长:{circle1.calculate_circumference():.2f}")
# 测试2:创建半径为5的圆对象
circle2 = Circle(5)
print("\n===== 测试半径为5的圆 =====")
print(f"圆2的半径:{circle2.radius}")
print(f"圆2的面积:{circle2.calculate_area():.2f}")
print(f"圆2的周长:{circle2.calculate_circumference():.2f}")完整代码汇总
python
# 导入math模块获取π
import math
# 定义Circle类
class Circle:
# 初始化方法:传入半径,默认值为1
def __init__(self, radius=1):
self.radius = radius # 定义半径属性
# 计算面积的方法
def calculate_area(self):
return math.pi * (self.radius ** 2)
# 计算周长的方法
def calculate_circumference(self):
return 2 * math.pi * self.radius
# 测试代码
if __name__ == "__main__":
# 测试默认半径(1)的圆
circle1 = Circle()
print("===== 测试默认半径的圆 =====")
print(f"圆1的半径:{circle1.radius}")
print(f"圆1的面积:{circle1.calculate_area():.2f}")
print(f"圆1的周长:{circle1.calculate_circumference():.2f}")
# 测试半径为5的圆
circle2 = Circle(5)
print("\n===== 测试半径为5的圆 =====")
print(f"圆2的半径:{circle2.radius}")
print(f"圆2的面积:{circle2.calculate_area():.2f}")
print(f"圆2的周长:{circle2.calculate_circumference():.2f}")✅ 补充:if __name__ == "__main__": 是 Python 规范写法,意思是 "只有直接运行这个文件时,才执行里面的代码",避免导入该类时自动运行测试代码。
核心知识点回顾(对应你之前学的内容)
| 代码部分 | 对应知识点 |
|---|---|
class Circle: |
类的定义 |
def __init__(self, radius=1): |
类的初始化方法(默认参数) |
self.radius = radius |
定义对象属性 |
def calculate_area(self): |
类的普通方法 |
math.pi * (self.radius ** 2) |
方法中访问对象属性 + 面积公式 |
这样一步步操作后,你不仅完成了 Circle 类的项目,还能巩固之前学的类的核心知识点。

编写 Rectangle 类代码(分步拆解,结合知识点)
打开rectangle.py文件,按以下步骤逐行编写(每一步标注知识点和逻辑解释):
步骤 1:定义 Rectangle 类(类的定义)
python
# 定义Rectangle类,类名遵守大驼峰规则(首字母大写)
class Rectangle:
# 步骤2:初始化方法(__init__),传入长和宽,默认值均为1
def __init__(self, length=1, width=1):
# 给对象绑定属性:长(length)、宽(width)
# self代表当前对象,把传入的参数赋值给对象属性
self.length = length
self.width = width✅ 知识点:初始化方法__init__是创建对象时自动执行的方法,self是必传的第一个参数,length=1/width=1是参数默认值(不传参时用 1)。
步骤2:定义计算面积的方法(calculate_area)
在__init__方法下方(保持缩进)添加:
python
# 计算面积:公式=长×宽
def calculate_area(self):
# 访问对象的length和width属性,计算面积并返回
area = self.length * self.width
return area✅ 知识点:类的普通方法,第一个参数必须是self,方法内通过self.属性名访问对象的属性。
步骤 3:定义计算周长的方法(calculate_perimeter)
继续添加(保持缩进):
python
# 计算周长:公式=2×(长+宽)
def calculate_perimeter(self):
perimeter = 2 * (self.length + self.width)
return perimeter步骤 4:定义判断正方形的方法(is_square)
继续添加(保持缩进):
python
# 判断是否为正方形:长==宽时返回True,否则返回False
def is_square(self):
# 比较length和width是否相等,返回布尔值(True/False)
return self.length == self.width步骤 5:编写测试代码(验证类的功能)
在类定义下方(取消缩进)添加测试代码(模拟使用 Rectangle 类):
python
# 测试代码:只有直接运行该文件时才执行(规范写法)
if __name__ == "__main__":
# 测试1:使用默认值(长1、宽1)创建矩形
rect1 = Rectangle()
print("===== 测试默认长宽的矩形 =====")
print(f"矩形1的长:{rect1.length},宽:{rect1.width}")
print(f"面积:{rect1.calculate_area()}")
print(f"周长:{rect1.calculate_perimeter()}")
print(f"是否为正方形:{rect1.is_square()}") # 1==1,返回True
# 测试2:自定义长宽(长5、宽3)创建矩形
rect2 = Rectangle(5, 3)
print("\n===== 测试长5宽3的矩形 =====")
print(f"矩形2的长:{rect2.length},宽:{rect2.width}")
print(f"面积:{rect2.calculate_area()}")
print(f"周长:{rect2.calculate_perimeter()}")
print(f"是否为正方形:{rect2.is_square()}") # 5≠3,返回False
# 测试3:自定义长宽(长4、宽4)创建矩形(正方形)
rect3 = Rectangle(4, 4)
print("\n===== 测试长4宽4的矩形(正方形) =====")
print(f"矩形3的长:{rect3.length},宽:{rect3.width}")
print(f"面积:{rect3.calculate_area()}")
print(f"周长:{rect3.calculate_perimeter()}")
print(f"是否为正方形:{rect3.is_square()}") # 4==4,返回True完整代码汇总
python
# 定义Rectangle类
class Rectangle:
# 初始化方法:长和宽默认值均为1
def __init__(self, length=1, width=1):
self.length = length
self.width = width
# 计算面积:长×宽
def calculate_area(self):
return self.length * self.width
# 计算周长:2×(长+宽)
def calculate_perimeter(self):
return 2 * (self.length + self.width)
# 判断是否为正方形:长==宽返回True,否则False
def is_square(self):
return self.length == self.width
# 测试代码
if __name__ == "__main__":
# 测试1:默认长宽(1,1)
rect1 = Rectangle()
print("===== 测试默认长宽的矩形 =====")
print(f"矩形1的长:{rect1.length},宽:{rect1.width}")
print(f"面积:{rect1.calculate_area()}")
print(f"周长:{rect1.calculate_perimeter()}")
print(f"是否为正方形:{rect1.is_square()}")
# 测试2:长5、宽3
rect2 = Rectangle(5, 3)
print("\n===== 测试长5宽3的矩形 =====")
print(f"矩形2的长:{rect2.length},宽:{rect2.width}")
print(f"面积:{rect2.calculate_area()}")
print(f"周长:{rect2.calculate_perimeter()}")
print(f"是否为正方形:{rect2.is_square()}")
# 测试3:长4、宽4(正方形)
rect3 = Rectangle(4, 4)
print("\n===== 测试长4宽4的矩形(正方形) =====")
print(f"矩形3的长:{rect3.length},宽:{rect3.width}")
print(f"面积:{rect3.calculate_area()}")
print(f"周长:{rect3.calculate_perimeter()}")
print(f"是否为正方形:{rect3.is_square()}")
优化扩展(可选,巩固知识点)
如果想让代码更健壮,可在初始化方法中添加「长宽非负校验」(避免传入负数导致计算错误):
python
def __init__(self, length=1, width=1):
# 校验长和宽是否为非负数
if length < 0 or width < 0:
raise ValueError("长和宽不能为负数!") # 抛出异常,提示错误
self.length = length
self.width = width测试负数场景:
python
# 尝试创建长-2、宽3的矩形(会报错)
rect4 = Rectangle(-2, 3)运行后终端会提示:ValueError: 长和宽不能为负数!,避免非法数据输入。
核心知识点回顾(对应你所学内容)
| 代码部分 | 对应知识点 |
|---|---|
class Rectangle: |
类的定义 |
def __init__(self, length=1, width=1): |
类的初始化方法(多参数 + 默认值) |
self.length = length |
定义对象属性 |
def calculate_area(self): |
类的普通方法 |
return self.length == self.width |
方法中判断逻辑 + 返回布尔值 |
常见问题排查(Mac 下易踩坑点)
- 报错 "IndentationError: expected an indented block" :Python 缩进错误!类内的方法(
__init__/calculate_area等)必须缩进(4 个空格或 1 个 Tab),确保代码缩进一致; - 长宽传入字符串(比如 Rectangle ("5",3)) :运行会报
TypeError,因为字符串不能和数字相乘,若想优化,可在__init__中加类型校验(零基础暂不用); - 终端运行提示 "No such file or directory" :
cd命令路径错误!确认项目文件夹在桌面,且文件名拼写正确(比如Rectangle_Project不是rectangle_project)。
编写图形工厂代码(分步拆解)
打开shape_factory.py文件,按以下步骤逐行编写(先复用已有类,再写工厂函数,最后测试):
步骤 1:导入依赖 + 定义基础图形类(复用之前的代码)
首先写入 Circle 和 Rectangle 类(核心逻辑和之前一致,简化注释,保留核心功能):
python
# 导入math模块(Circle类计算面积/周长需要π)
import math
# ====================== 1. 定义圆(Circle)类 ======================
class Circle:
# 初始化:半径默认值1
def __init__(self, radius=1):
# 可选优化:校验半径非负(避免非法数据)
if radius < 0:
raise ValueError("圆的半径不能为负数!")
self.radius = radius
# 计算面积:πr²
def calculate_area(self):
return math.pi * (self.radius ** 2)
# 计算周长:2πr
def calculate_circumference(self):
return 2 * math.pi * self.radius
# ====================== 2. 定义长方形(Rectangle)类 ======================
class Rectangle:
# 初始化:长、宽默认值均为1
def __init__(self, length=1, width=1):
# 可选优化:校验长宽非负
if length < 0 or width < 0:
raise ValueError("长方形的长和宽不能为负数!")
self.length = length
self.width = width
# 计算面积:长×宽
def calculate_area(self):
return self.length * self.width
# 计算周长:2×(长+宽)
def calculate_perimeter(self):
return 2 * (self.length + self.width)
# 判断是否为正方形
def is_square(self):
return self.length == self.width步骤 2:定义工厂函数 create_shape(核心逻辑)
在基础类下方添加工厂函数,功能是 "根据 shape_type 创建对应图形对象":
python
# ====================== 3. 定义图形工厂函数 ======================
def create_shape(shape_type, *args):
"""
图形工厂函数:根据类型创建不同图形对象
:param shape_type: 图形类型,可选"circle"(圆)、"rectangle"(长方形)
:param *args: 可变参数,接收图形的参数:
- circle:传入1个参数(半径)
- rectangle:传入2个参数(长、宽)
:return: 对应图形的对象
"""
# 转换类型为小写,避免大小写错误(比如传入"Circle"也能识别)
shape_type = shape_type.lower()
# 情况1:创建圆对象
if shape_type == "circle":
# 圆需要1个参数(半径),校验参数数量
if len(args) > 1:
raise ValueError("创建圆只需传入1个参数(半径)!")
# 提取半径(args是元组,取第一个元素,无参数则用默认值1)
radius = args[0] if args else 1
return Circle(radius)
# 情况2:创建长方形对象
elif shape_type == "rectangle":
# 长方形需要2个参数(长、宽),校验参数数量
if len(args) > 2:
raise ValueError("创建长方形只需传入2个参数(长、宽)!")
# 提取长和宽(无参数则用默认值1)
length = args[0] if len(args) >= 1 else 1
width = args[1] if len(args) >= 2 else 1
return Rectangle(length, width)
# 情况3:不支持的图形类型
else:
raise ValueError(f"不支持的图形类型:{shape_type}!可选类型:circle、rectangle")✅ 核心知识点解释:
*args:可变长度参数,能接收任意数量的位置参数,打包成元组(比如传入 5,args=(5,);传入 4,5,args=(4,5));shape_type.lower():统一转换为小写,避免用户传入 "Circle""RECTANGLE" 等大小写混合的类型导致识别失败;- 参数校验:避免传入过多参数(比如创建圆时传入 2 个参数)导致错误。
步骤 3:编写测试代码(验证工厂函数)
在工厂函数下方添加测试代码,验证不同场景的创建逻辑:
python
# ====================== 4. 测试工厂函数 ======================
if __name__ == "__main__":
print("===== 测试图形工厂 =====")
# 测试1:创建圆(传入半径5)
circle1 = create_shape("circle", 5)
print("\n【圆1】")
print(f"半径:{circle1.radius}")
print(f"面积:{circle1.calculate_area():.2f}")
print(f"周长:{circle1.calculate_circumference():.2f}")
# 测试2:创建圆(无参数,用默认半径1)
circle2 = create_shape("Circle") # 大小写不敏感
print("\n【圆2】")
print(f"半径:{circle2.radius}")
print(f"面积:{circle2.calculate_area():.2f}")
# 测试3:创建长方形(传入长4、宽3)
rect1 = create_shape("rectangle", 4, 3)
print("\n【长方形1】")
print(f"长:{rect1.length},宽:{rect1.width}")
print(f"面积:{rect1.calculate_area()}")
print(f"周长:{rect1.calculate_perimeter()}")
print(f"是否为正方形:{rect1.is_square()}")
# 测试4:创建长方形(无参数,用默认长宽1)
rect2 = create_shape("RECTANGLE") # 大小写不敏感
print("\n【长方形2】")
print(f"长:{rect2.length},宽:{rect2.width}")
print(f"是否为正方形:{rect2.is_square()}")完整代码汇总
python
import math
# 圆类
class Circle:
def __init__(self, radius=1):
if radius < 0:
raise ValueError("圆的半径不能为负数!")
self.radius = radius
def calculate_area(self):
return math.pi * (self.radius ** 2)
def calculate_circumference(self):
return 2 * math.pi * self.radius
# 长方形类
class Rectangle:
def __init__(self, length=1, width=1):
if length < 0 or width < 0:
raise ValueError("长方形的长和宽不能为负数!")
self.length = length
self.width = width
def calculate_area(self):
return self.length * self.width
def calculate_perimeter(self):
return 2 * (self.length + self.width)
def is_square(self):
return self.length == self.width
# 图形工厂函数
def create_shape(shape_type, *args):
shape_type = shape_type.lower()
if shape_type == "circle":
if len(args) > 1:
raise ValueError("创建圆只需传入1个参数(半径)!")
radius = args[0] if args else 1
return Circle(radius)
elif shape_type == "rectangle":
if len(args) > 2:
raise ValueError("创建长方形只需传入2个参数(长、宽)!")
length = args[0] if len(args) >= 1 else 1
width = args[1] if len(args) >= 2 else 1
return Rectangle(length, width)
else:
raise ValueError(f"不支持的图形类型:{shape_type}!可选类型:circle、rectangle")
# 测试代码
if __name__ == "__main__":
print("===== 测试图形工厂 =====")
# 测试1:创建圆(半径5)
circle1 = create_shape("circle", 5)
print("\n【圆1】")
print(f"半径:{circle1.radius}")
print(f"面积:{circle1.calculate_area():.2f}")
print(f"周长:{circle1.calculate_circumference():.2f}")
# 测试2:创建圆(默认半径1)
circle2 = create_shape("Circle")
print("\n【圆2】")
print(f"半径:{circle2.radius}")
print(f"面积:{circle2.calculate_area():.2f}")
# 测试3:创建长方形(长4、宽3)
rect1 = create_shape("rectangle", 4, 3)
print("\n【长方形1】")
print(f"长:{rect1.length},宽:{rect1.width}")
print(f"面积:{rect1.calculate_area()}")
print(f"周长:{rect1.calculate_perimeter()}")
print(f"是否为正方形:{rect1.is_square()}")
# 测试4:创建长方形(默认长宽1)
rect2 = create_shape("RECTANGLE")
print("\n【长方形2】")
print(f"长:{rect2.length},宽:{rect2.width}")
print(f"是否为正方形:{rect2.is_square()}")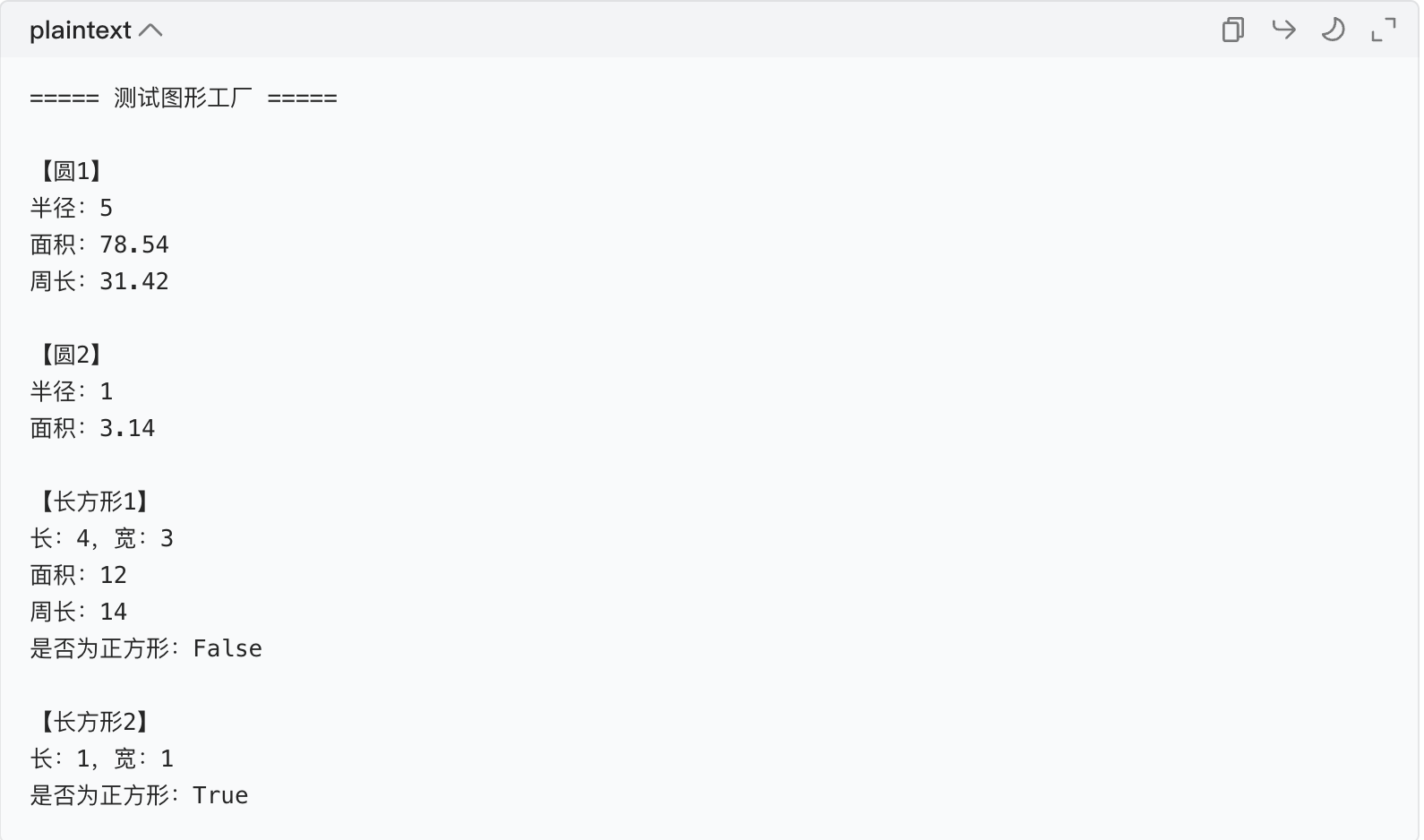
扩展测试(验证异常处理逻辑,可选)
工厂函数添加了参数校验,可测试异常场景(比如创建圆时传入 2 个参数),在测试代码中添加:
python
# 测试5:异常场景(创建圆传入2个参数)
try:
circle3 = create_shape("circle", 5, 6)
except ValueError as e:
print("\n【异常测试1】", e) # 输出:创建圆只需传入1个参数(半径)!
# 测试6:异常场景(不支持的图形类型)
try:
tri = create_shape("triangle", 3, 4, 5)
except ValueError as e:
print("\n【异常测试2】", e) # 输出:不支持的图形类型:triangle!可选类型:circle、rectangle运行后会输出异常提示,说明参数校验生效,代码更健壮。
常见问题排查(Mac 下易踩坑点)
- 报错 "IndentationError":Python 缩进错误!类和函数内的代码必须缩进(4 个空格或 1 个 Tab),确保所有缩进一致;
- 报错 "ValueError: 圆的半径不能为负数!" :传入了负数半径(比如
create_shape("circle", -5)),检查参数是否合法; - 终端提示 "No such file or directory" :
cd命令路径错误!确认项目文件夹在桌面,且文件名拼写正确(比如ShapeFactory_Project不是shapefactory_project); *args参数理解困难 :记住args是元组,比如create_shape("rectangle",4,3),args=(4,3),通过args[0]取长,args[1]取宽即可。
核心知识点回顾(整合你所学内容)
| 代码部分 | 对应知识点 |
|---|---|
class Circle/Rectangle: |
类的定义 |
def __init__(self, ...): |
类的初始化方法(默认参数) |
def create_shape(shape_type, *args): |
函数定义 + 可变参数 * args |
shape_type.lower() |
字符串方法(统一大小写) |
if/elif/else |
条件判断(分支逻辑) |
raise ValueError(...) |
异常抛出(错误处理) |
return Circle(radius) |
函数返回对象 |
这个项目整合了 "类的定义、初始化方法、普通方法、函数、可变参数、异常处理" 等核心知识点,是对之前内容的综合应用。