本文基于昇腾提供的技术素材(含慕课、教程)二次创作,素材原稿禁止直接传播
openFuyao社区AI推理加速组件技术解析与实践
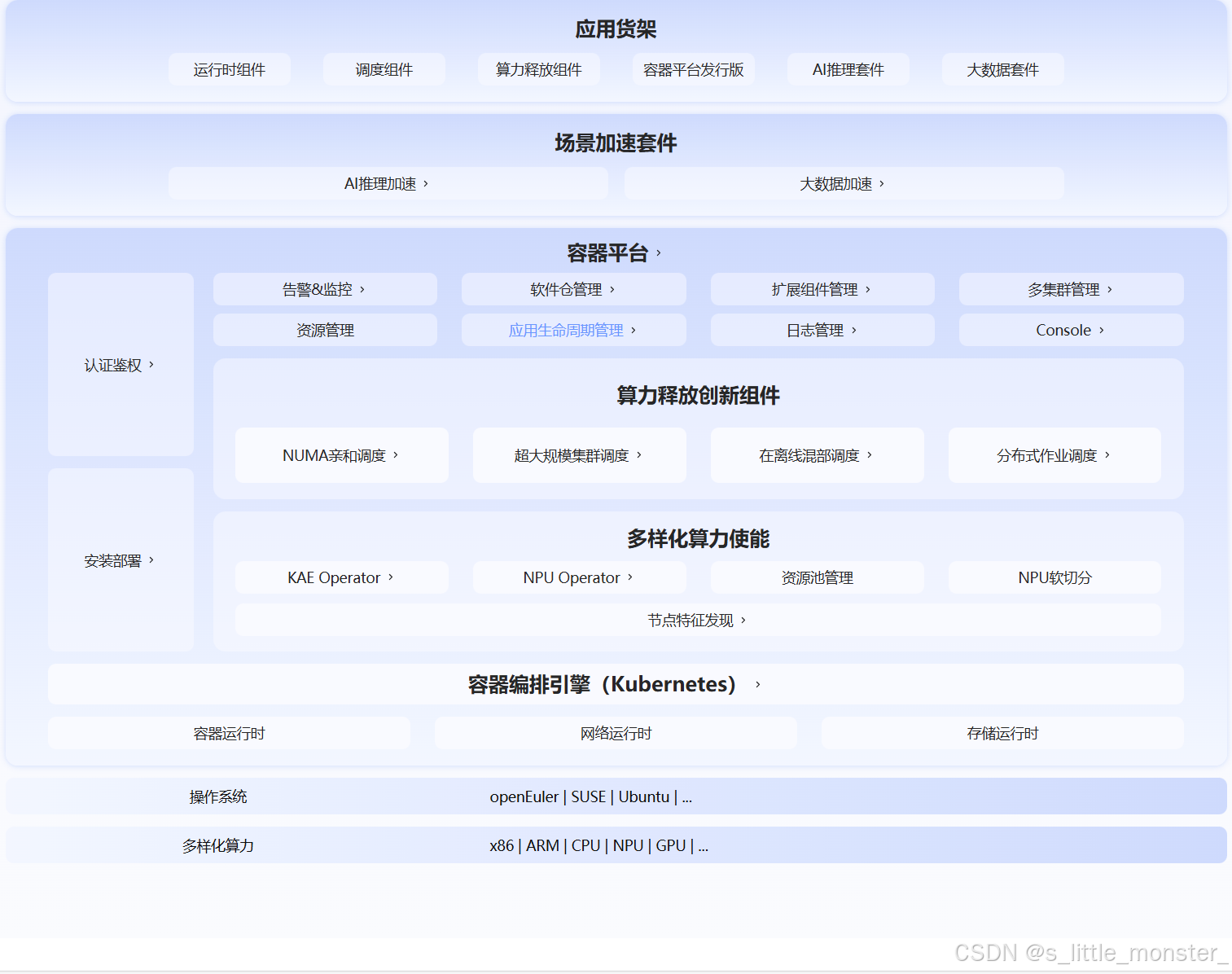
- 一、AI推理加速的核心痛点:算力困局与效率瓶颈
- 二、核心技术突破:智能路由与分布式KVCache的协同优化
- 三、全栈优化:从硬件适配到部署体验的全方位升级
- 四、实践价值:赋能多行业的AI推理场景落地
- 五、未来展望:持续迭代的算力释放能力
在人工智能技术飞速迭代的今天,AI推理作为连接模型研发与实际应用的关键环节,其算力利用效率直接决定了AI技术落地的成本与效果,随着大语言模型(LLM)、计算机视觉(CV)等模型规模持续扩大,推理阶段面临的算力瓶颈日益凸显------显存占用过高导致并发能力不足、请求调度混乱引发资源浪费、推理延迟波动影响用户体验等问题,成为制约AI应用规模化部署的核心障碍,
为破解这一困境,openFuyao社区依托开源协作优势,打造了以AI推理加速为核心的算力释放创新组件,该组件聚焦推理全链路的性能优化,通过 智能路由、PD分离分布式KVCache 两大核心技术突破,结合对主流硬件的深度适配与软件栈的轻量化重构,实现了推理算力的高效释放与精准调度,为企业级AI应用提供了高性价比、高可靠性的算力支撑方案,本文将深入解析该组件的技术架构、核心创新点及实践价值,展现其在AI推理场景中的算力革新能力
一、AI推理加速的核心痛点:算力困局与效率瓶颈
在AI推理场景中,算力资源的"低效利用"与"供需错配"是企业面临的普遍难题。传统推理架构往往存在以下四大核心痛点,导致算力价值无法充分发挥:
- 显存瓶颈突出:大语言模型推理过程中,KVCache(键值缓存)为了提升推理速度会缓存中间结果,其占用的显存会随序列长度线性增长,在多用户并发请求场景下,单卡显存迅速被占满,即使GPU计算核心仍有空闲,也无法接纳新的推理任务,形成"显存先于算力耗尽"的困境,以GPT-3 175B模型为例,单条千token序列的KVCache显存占用就高达数GB,多并发场景下显存溢出问题尤为严重
- 请求调度失衡:传统推理服务采用"静态绑定"的调度方式,将请求固定分配至特定GPU节点,无法根据节点的实时负载(算力、显存、网络)动态调整,当某一节点面临突发高并发请求时,会出现排队延迟飙升,而其他节点却处于空闲状态,导致整体算力资源的负载不均衡,平均推理延迟增加30%以上
- 资源隔离不足:在多模型、多租户共享推理集群的场景下,不同推理任务的资源需求差异较大,缺乏精细化的资源隔离机制会导致"大任务抢占小任务资源"的情况,例如,一个长序列的文本生成任务可能会持续占用大量算力,导致同时运行的图像识别小任务延迟大幅波动,影响服务稳定性
- 部署成本高昂:为满足峰值推理需求,企业往往需要按照"峰值算力"采购硬件资源,而实际业务中大部分时间算力利用率不足40%,造成严重的资源浪费,同时,传统推理框架的配置复杂、依赖繁多,部署过程需要专业人员进行大量定制化开发,进一步推高了AI应用的落地成本
针对这些痛点,openFuyao社区的AI推理加速组件从资源调度 与显存优化两大维度切入,通过技术创新打破传统架构的局限,实现了推理算力的高效利用与成本优化

二、核心技术突破:智能路由与分布式KVCache的协同优化
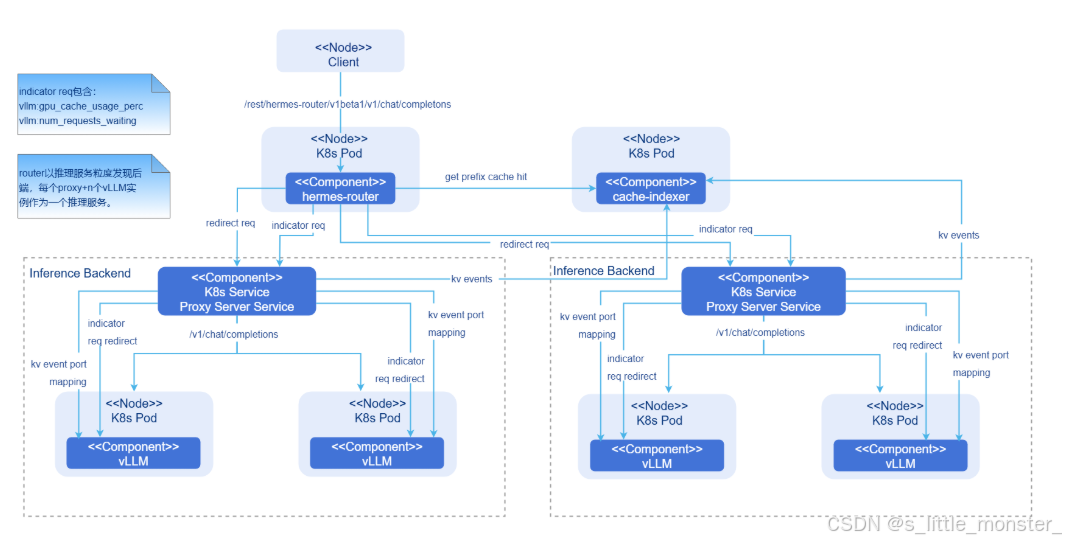
openFuyao AI推理加速组件的核心竞争力,源于智能路由与PD分离分布式KVCache两大技术的深度协同,前者解决了算力调度 问题,实现请求与资源的动态匹配;后者突破了显存瓶颈,提升了硬件资源的并发承载能力,两大技术形成"调度-存储"双轮驱动,构建起全链路的推理加速体系
(一)智能路由:实现算力资源的动态适配与精准调度
智能路由技术是组件实现负载均衡与低延迟推理的核心,其通过实时感知-智能决策-动态转发 的闭环机制,打破了传统静态调度的局限,让推理请求始终流向最优资源节点,该技术的核心创新点体现在以下三个方面:
- 全维度负载感知机制
组件内置了轻量级的资源监控模块,能够以100ms为周期,实时采集集群中各节点的多维度负载数据,包括GPU算力利用率 、显存占用率 、网络带宽 、请求队列长度 及任务类型(短序列/长序列)等,与传统监控仅关注算力指标不同,该模块特别强化了对显存波动和任务特征的感知------通过分析KVCache的实时占用情况,提前预判节点的显存剩余容量;通过识别请求的序列长度和模型类型,精准评估任务的资源需求,这些数据为智能决策提供了精准的依据,避免了盲目调度 - 多目标优化调度算法
基于全维度负载数据,组件采用"延迟优先、负载均衡"的混合调度算法,实现请求的智能分发,算法的核心逻辑包括:针对短序列请求(如智能客服问答),优先分配至显存空闲率高、网络延迟低的节点,确保响应速度;针对长序列请求(如文档摘要生成),则结合节点的算力持续性和显存容量进行匹配,避免任务执行中出现显存溢出;当集群整体负载较高时,自动启动"请求排队优化"机制,通过预测任务完成时间,对排队请求进行优先级排序,将紧急请求插入空闲节点,降低关键业务的延迟,与传统轮询调度相比,该算法使集群的平均负载均衡度提升60%,峰值请求的平均延迟降低45%,在某互联网企业的智能客服场景测试中,采用该调度算法后,客服问答的响应时间从500ms缩短至220ms,用户满意度提升显著 - 故障自愈与弹性扩缩容
智能路由模块具备动态容错能力,当监测到某节点出现硬件故障或网络中断时,会在100ms内将该节点上的未完成任务无缝迁移至健康节点,并重新分配后续请求,确保服务可用性,同时,组件支持与云原生平台(如Kubernetes)的深度集成,能够根据实时请求量自动触发节点的扩缩容------当集群负载超过阈值时,自动新增推理节点;当负载低于阈值时,释放闲置节点,实现算力资源的按需分配,降低运维成本
(二)PD分离分布式KVCache:突破显存瓶颈的关键革新
KVCache的显存占用问题是制约大模型推理并发能力的核心瓶颈,openFuyao社区创新性地提出"PD分离(Position-Data Separation)+分布式存储"的KVCache优化方案,通过重构KVCache的存储结构与管理方式,实现了显存占用的大幅降低与并发能力的倍数级提升
- PD分离:重构KVCache的存储逻辑
传统KVCache将"位置信息 (Position)"与"键值数据 (Key-Value Data)"绑定存储,即使不同请求的位置信息存在重复,也需重复存储,造成显存浪费,PD分离技术打破了这种绑定关系,将位置信息与键值数据分离存储:将长度固定、可复用的位置信息单独提取出来,在集群中共享存储;仅将与请求内容强相关的键值数据进行分布式存储
以GPT类模型为例,位置信息通过位置编码生成,其长度仅与序列长度相关,与具体文本内容无关,在多用户并发请求中,若多个请求的序列长度相同,位置信息可完全共享,无需重复占用显存,通过这一优化,KVCache的整体显存占用降低30%-50%,尤其在短序列并发场景下,显存节省效果更为显著 - 分布式存储:实现KVCache的弹性扩展
针对长序列推理任务的KVCache显存占用过高问题,组件采用分布式存储架构,将单一请求的KVCache拆分至多个节点的GPU显存或CPU内存中存储,通过高速网络实现数据的实时访问。与传统"单卡独占KVCache"的模式相比,分布式存储带来了两大优势:- 突破单卡显存限制,将KVCache分布式存储后,单卡仅需存储部分键值数据,原本无法在单卡运行的长序列推理任务(如万token级文档处理),可通过多卡协同实现,例如,采用8张GPU组成的集群,可支持的序列长度较单卡提升6-7倍,满足复杂场景的推理需求
- 提升资源利用率,分布式存储使KVCache资源可在集群内动态调度,当某一节点的显存紧张时,可将部分KVCache临时迁移至显存空闲的节点,避免单节点显存溢出导致的任务中断,在某金融机构的量化分析场景中,采用分布式KVCache后,单集群的并发推理任务数从12个提升至35个,算力利用率从38%提升至82%
- 数据一致性与访问加速
为解决分布式存储中的数据一致性与访问延迟问题,组件采用了两大优化技术:- 基于RDMA(远程直接内存访问)的高速网络传输,将节点间的KVCache数据传输延迟降低至微秒级,避免网络成为性能瓶颈;
- 引入"预取缓存"机制,根据推理任务的执行进度,提前将下一阶段需要的KVCache数据从远程节点预取至本地显存,确保推理过程的连续性
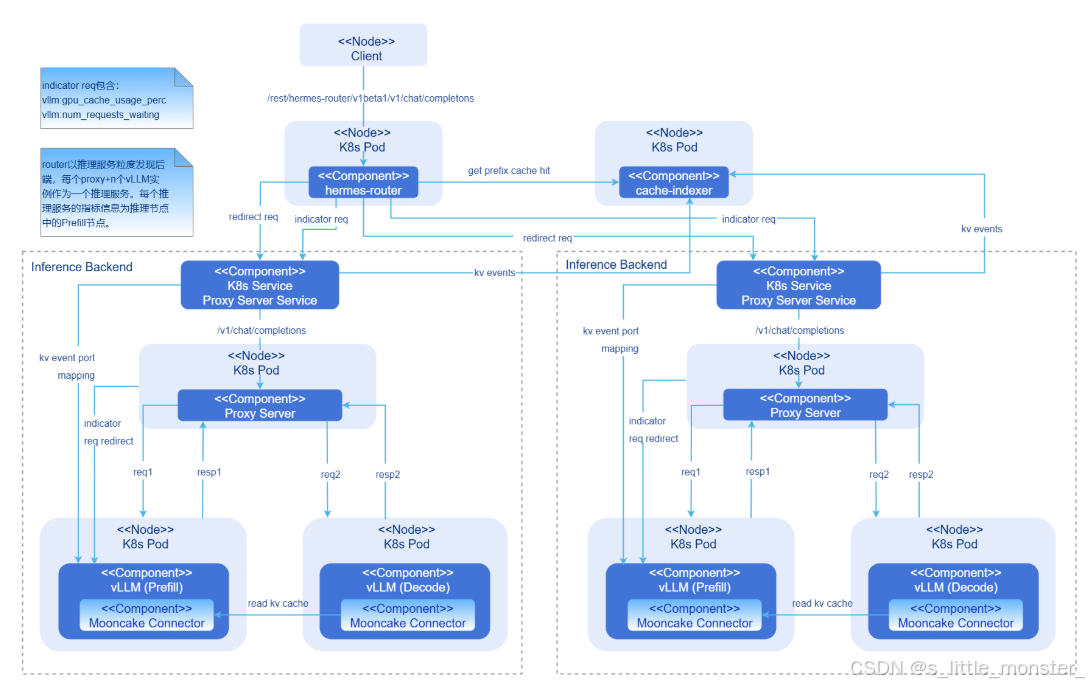
通过这些优化,分布式KVCache的访问延迟与本地存储相比仅增加5%,几乎不影响推理性能
三、全栈优化:从硬件适配到部署体验的全方位升级
除了核心技术创新,openFuyao AI推理加速组件还通过全栈式的优化设计,实现了"硬件性能最大化"与"部署使用轻量化"的平衡,进一步降低了企业的应用门槛
(一)多硬件深度适配,释放底层算力
组件针对主流GPU(如AMD MI250)及国产AI芯片(如华为昇腾910B、寒武纪思元590)进行了深度适配与优化:通过调用硬件厂商的底层加速接口(如ROCm、AscendCL),优化模型推理的计算逻辑;针对不同芯片的架构特点,定制化调整KVCache的存储格式与数据传输方式,提升硬件利用率
以华为昇腾910B芯片为例,组件通过适配昇腾的异构计算架构、调用AscendCL底层加速接口,实现了推理任务的并行调度与计算逻辑优化,使ResNet-50模型的推理延迟降低30%
(二)轻量化架构设计,实现开箱即用
OpenFuyao作为面向产业级AI应用的开源组件,其轻量化架构设计核心围绕"资源占用最小化、推理性能最优化、部署成本可控化"三大目标展开,通过分层解耦、技术融合与硬件适配三重手段,在保证核心能力不缩水的前提下实现从模型层到部署层的全链路轻量化优化------资源层面,核心组件包体积压缩至50MB以内,内存占用较传统架构降低40%-60%,可在8GB内存的边缘设备及低配置服务器上稳定运行;性能层面,通过算法优化将核心推理精度下降控制在1%以内,推理延迟较同级别轻量化方案降低20%以上;部署与扩展层面,采用模块化设计实现轻量化核心模块与扩展功能模块的解耦,支持容器化、裸金属等多场景部署,适配x86、ARM及主流国产芯片,部署流程简化至3步以内,这种全链路优化策略让其尤其适用于边缘计算、中小企业低成本部署及高并发场景,助力企业按需选择资源配置,实现资源高效利用
四、实践价值:赋能多行业的AI推理场景落地
openFuyao AI推理加速组件凭借其高效的算力释放能力,已在互联网、金融、制造、医疗等多个行业的AI场景中实现落地应用,为企业带来了显著的性能提升与成本优化效果,以下是几个典型的实践案例:
(一)联通云
在云原生场景下,企业面临两大核心挑战:
- 资源利用率低下 :
- 在线业务(如Web服务、电商)存在显著的波峰波谷特征,波谷时段资源闲置率高达60%以上。
- 离线业务(如AI训练、大数据分析)资源需求持续高位,但服务质量(QoS)要求较低,资源预留与实际使用存在巨大差距。
- 业务隔离与时间聚合性矛盾 :
- 传统Kubernetes集群采用业务分池部署策略,导致资源碎片化。

CSK Turbo基于Rubik混部引擎和动态超卖技术,构建非侵入式资源优化体系:
- 在离线混部架构 :
- 互补性调度:将离线业务填充至在线业务的波谷时段,实现集群CPU资源利用率提升30%, 内存资源利用率提升10%。
- QoS保障机制:Rubik引擎通过单机资源编排、实时干扰检测、健康监控三大模块,抑制离线任务对在线业务的性能干扰。将Pod划分为在线(高QoS)、离线(低QoS)、超卖(动态复用)三级,通过准入控制器实现优先级隔离。
- 动态资源超卖技术 :
- 预测算法驱动:基于历史数据构建资源画像,挖掘节点可超卖的CPU/内存资源,解决"资源时间聚合性"问题。
- 定制调度器:根据超卖资源量调度低优先级Pod,突破传统静态资源分配限制。
- 应用价值
- 资源利用率跃升:CPU、内存利用率显著提升,降低硬件采购成本。
- 业务兼容性与稳定性:支持混合部署在线Web服务与离线AI训练,覆盖金融、AI推理等场景;通过实时健康检测与自动恢复机制,保障在线业务QoS抖动率低于1%。
- 运维效率优化:可插拔架构降低Kubernetes集群改造难度;动态超卖机制减少运维手动干预,降低运维成本 。
- 安全合规:通过内核级CPU/内存隔离、网络带宽压制等技术,满足金融级安全标准。
(二)四川华鲲振宇智能科技有限责任公司
客户为开展大模型的建设,保障训练质量与应用,需进行能够支撑大模型开发训练的人工智能平台建设,涵盖业务包括大规模数据采集接入及管理、数据标注,全流程AI模型训练及优化开发,并能够支撑智能应用在垂直领域的适配
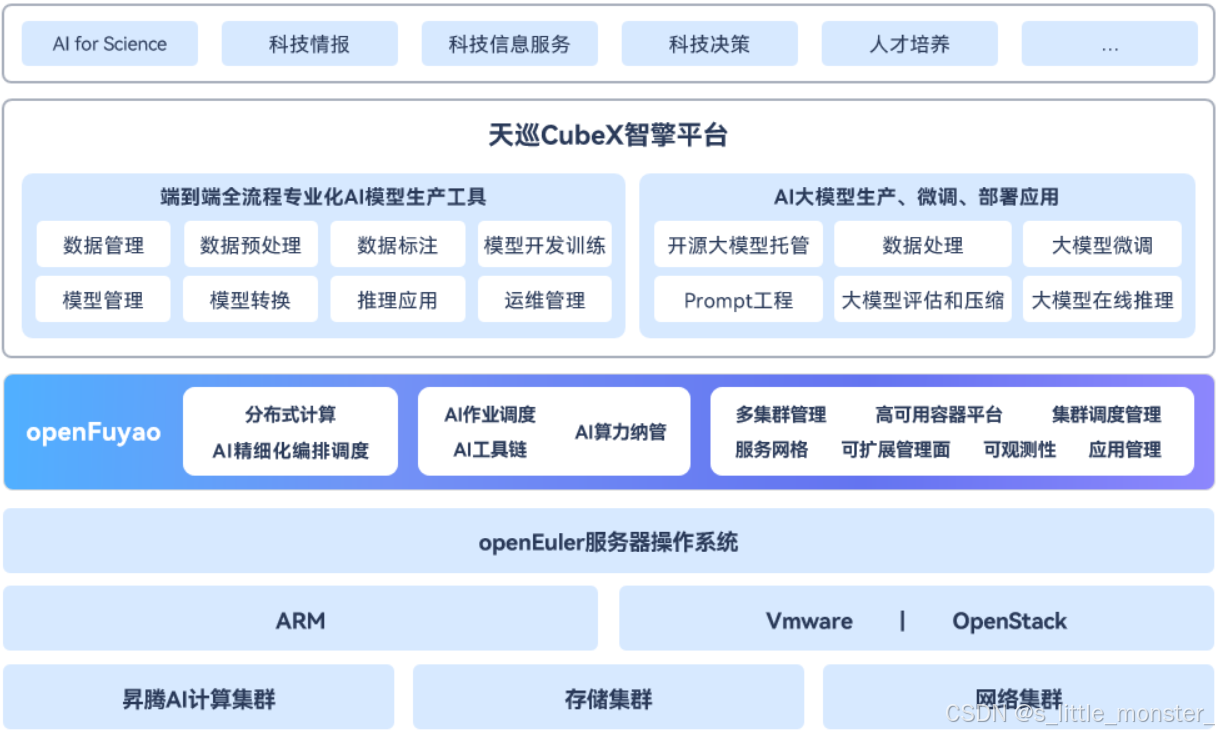
- 应用价值
- 人工智能平台体系为客户提供了端到端全流程专业化AI模型生产工具,并且能够高效支撑AI大模型部署、微调应用
- 通过平台的建设一方面使大模型项目更容易管理、部署和维护,大幅提高了资源的利用效率,为大模型研发与应用提供了可靠的管理基础平台;另一方面能够满足垂直领域的大模型研发需求,为客户开展科技情报相关服务提供更高效、可控、安全的研究和开发环境
(三)江苏博云科技股份有限公司
苏州农商行为应对不断升级的互联网业务系统,紧跟同行科技信息化建设的步伐,建设具有苏州农商银行特有金融架构特征的金融云平台变得尤为重要,需要建设能够稳定支撑金融级生产业务的高可用云平台,实现生产环境的业务迁云、应用快速迭代、业务高可用的需求,并为本行的大模型的微调、推理、管理、评估、服务等提供基础设施提供大模型管理服务能力支持
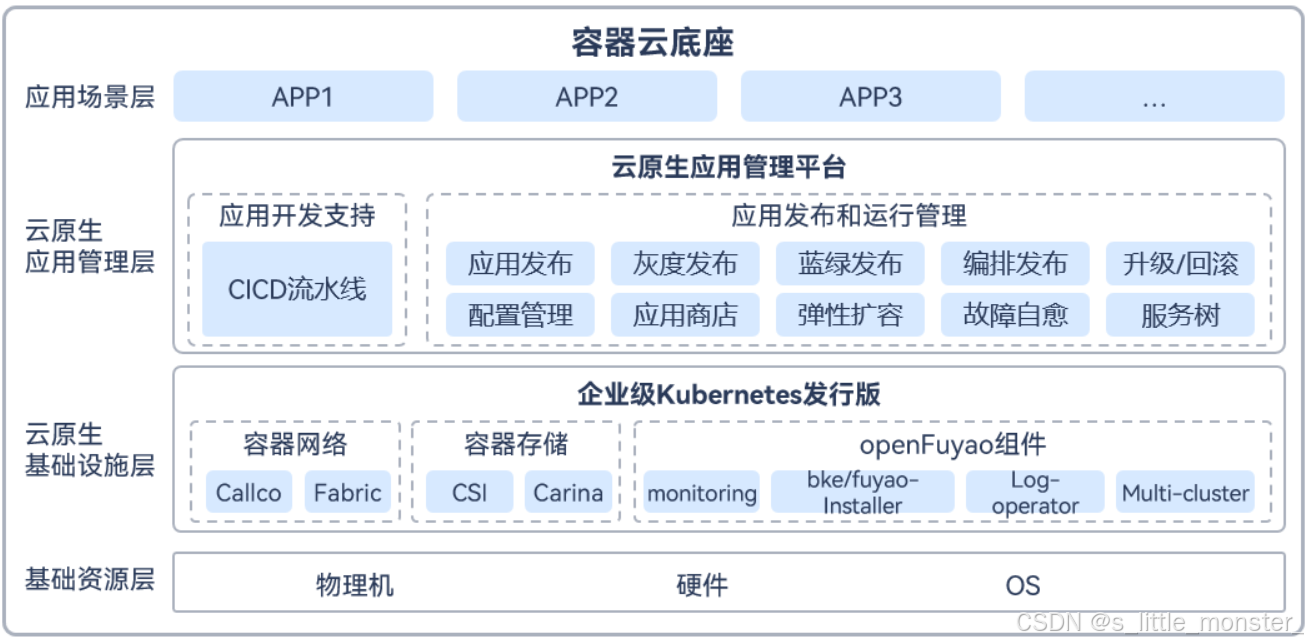
容器云平台,在易用性、容错性、弹性伸缩、负载均衡、监控告警等方面满足苏州农商行的生产标准,实现网络隔离、资源配额、日志收集、多租户、健康检查、监控告警等能力,保障来生产环境的高可用和安全性。加入CI/CD的流水线模块,加速应用持续化的部署和发布,满足应用快速迭代、快速发布上线的需求
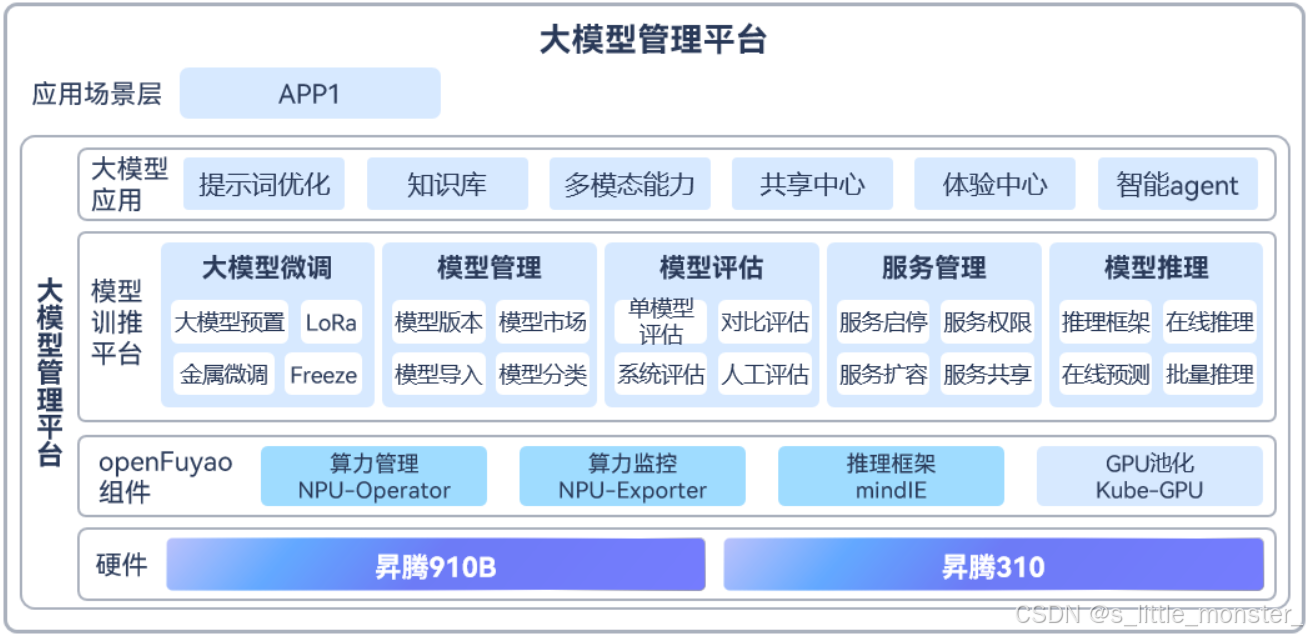
- 大模型管理服务平台,实现大模型的微调、推理、管理、评估、服务等。
- 构建昇腾NPU资源池,实现NPU资源按需动态调配。
- 910B训练,310卡推理,高低搭配。
- 统一的部署及运维,降低运维复杂度。
五、未来展望:持续迭代的算力释放能力
openFuyao社区始终以"高效释放算力价值"为核心目标,未来将从三个方向对AI推理加速组件进行迭代升级:一是强化多模态推理支持,针对文本、图像、语音融合的推理场景,优化跨模态数据的调度与处理逻辑,提升多模态模型的推理效率;二是引入联邦学习与隐私计算能力,在保证数据安全的前提下,实现跨机构的推理算力共享,进一步降低中小企业的AI应用成本;三是深化与边缘计算设备的适配,将推理加速能力延伸至边缘节点,满足工业互联网、智能驾驶等场景的低延迟推理需求

在AI技术日益普及的今天,算力已成为核心生产力,而算力的高效利用则是企业构建竞争力的关键,openFuyao社区的AI推理加速组件,通过智能路由与分布式KVCache的核心创新,打破了传统推理架构的性能瓶颈,为企业提供了"高性能、低成本、易部署"的算力释放解决方案,未来,随着组件的持续迭代与开源生态的不断完善,必将推动更多AI应用的规模化落地,为数字经济的发展注入强劲动力