数据仓库是什么?
数据仓库概念是由数据仓库之父比尔·恩门(Bill Inmon)在1991年出版的"Building the Data Warehouse"中提出:数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
数据建模是将数据进行有序、有结构地分类组织和存储的方法 。其思路是从企业分析决策等需求出发,建设一个数据易用、产出稳定、质量可信、指标丰富、能够提供标准化数据服务的大数据体系。同时具有高扩展、强复用、低成本的特性,能够避免数据重复建设和指标冗余建设,保障数据的规范性、指标的一致性,能够有效地管理和控制日益增长的存储和计算消耗。
目前工业界流行的建模方法主要是维度建模,维度模型是由数仓领域大师Ralph Kimball所倡导的,大师著作的《The Data Warehouse Toolkit-The Complete Guide to Dimensional Modeling》是数仓工程领域最流行的维度建模经典。
数据仓库中的一些基本概念
维度建模是数据仓库设计中用于结构化数据的逻辑建模方法,由Kimball提出。 其核心将业务数据划分为度量(事实表)和上下文(维度表) ,通过星型或雪花模式优化分析查询效率。 该方法以业务流程为建模单元,单独处理销售、库存等场景,通过预处理维度数据提升性能。
提到的一些名词解释如下:
**度量:**对某一业务过程行为的度量,也称原子指标,不能继续拆分。如支付业务过程中,支付次数、支付金额等
**维度:**维度是实体对象,描述的是度量的环境,是我们观察业务的角度。反应业务的一类属性,这类属性集合构成一个维度,比如,支付过程,度量是支付次数,维度是用户、设备、地理、时间等。一个维度落地就是一张维表。
**维度属性:**一个维度里面的具体属性,如用户维度的用户昵称、年龄、性别等。通俗讲就是维表的列。
1. 星形模式:以事实表为中心,所有的维度表直接连在事实表上,最简单最常用的一种
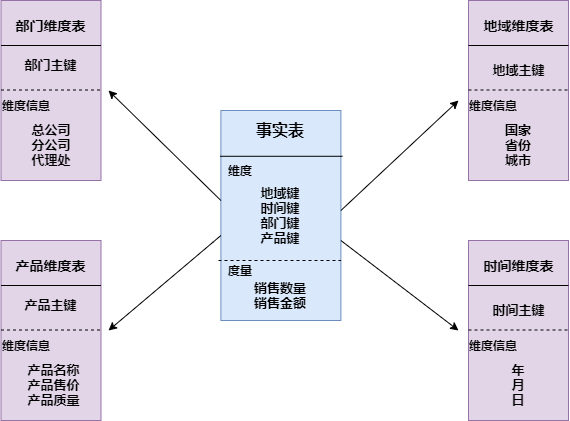
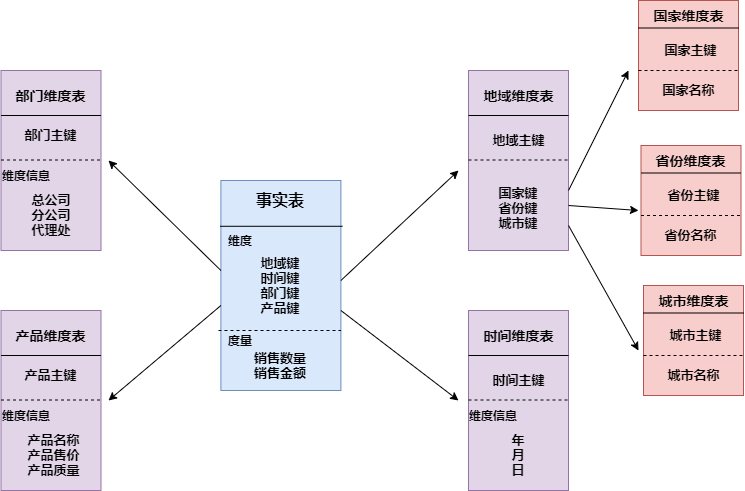
- 雪花模型:雪花模式的维度表可以拥有其他的维度表,这种表不易维护,一般不推荐使用
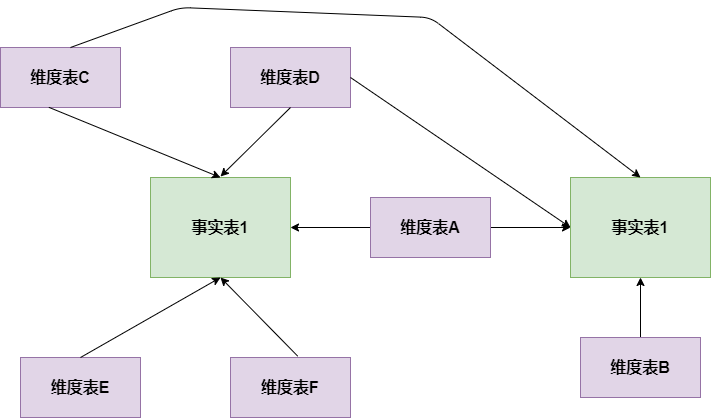
3. 星座模型:基于多张事实表,而且共享维度信息,即事实表之间可以共享某些维度表
如何构建数据仓库:
了解业务需求:
和bi同学和业务运营同学沟通,了解他们实际的用数需求。
定义好数仓分层模型:
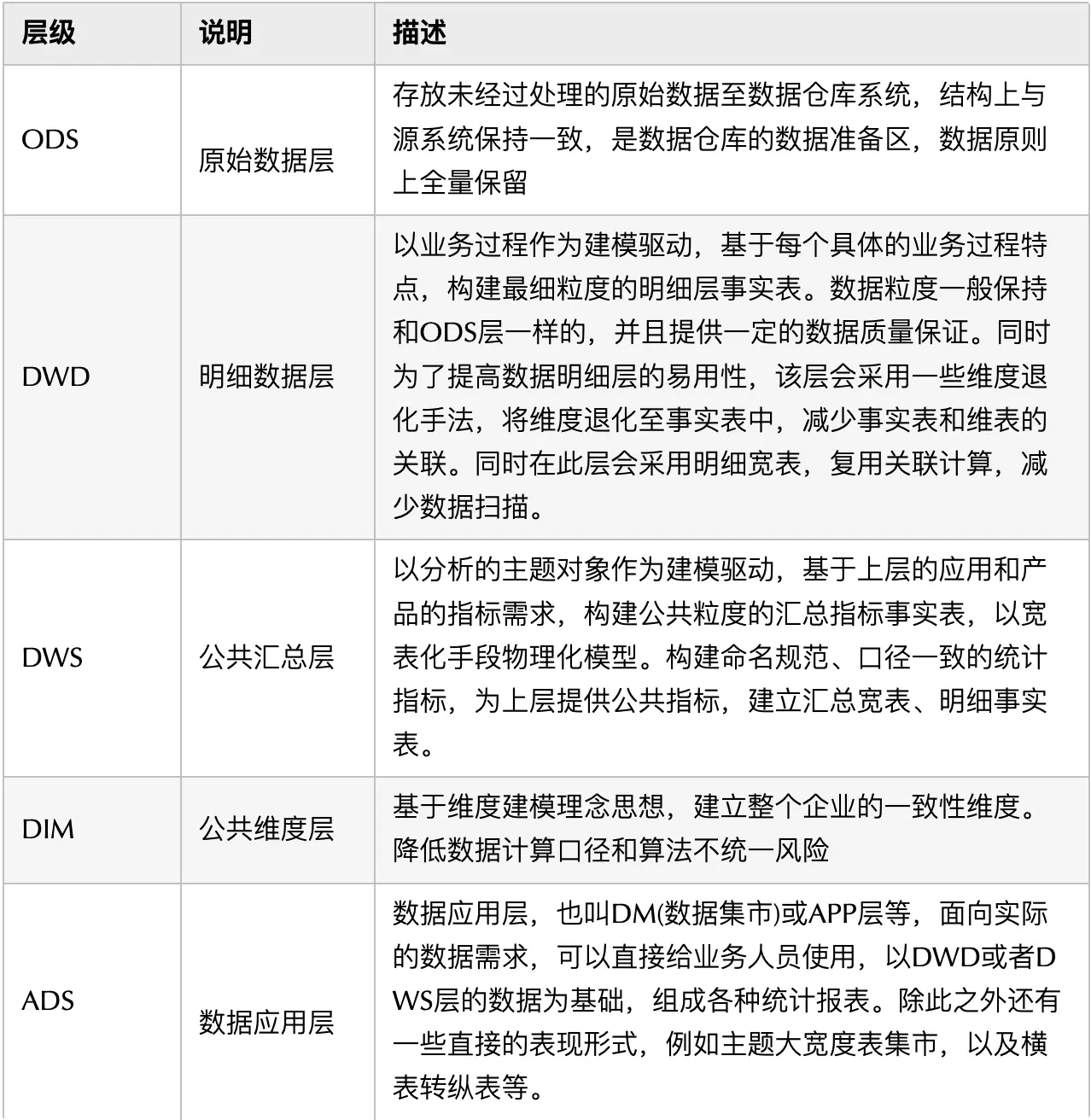
常见的都是把数仓分成四层:
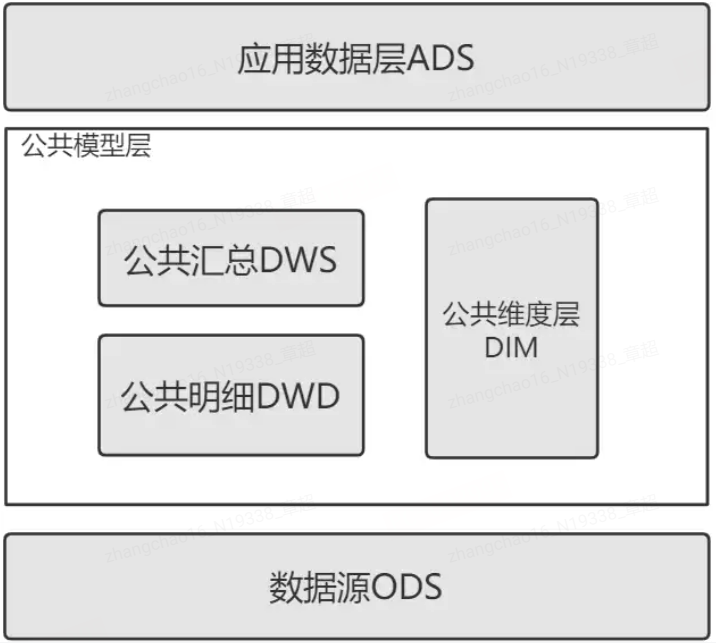
分析业务过程:
先来理解下业务过程、度量、维度、维度属性的含义:
业务过程: 指企业活动中的具体的、不可拆分的行为事件,如播放、下载、分享等都是业务过程。业务过程一般体现在dwd层模型中。
**度量:**对某一业务过程行为的度量,也称原子指标,不能继续拆分。如播放业务过程中,播放次数、播放人数等
**维度:**维度是实体对象,描述的是度量的环境,是我们观察业务的角度。反应业务的一类属性,这类属性集合构成一个维度,比如,播放过程,度量是播放次数,维度是用户、歌曲、设备、地理、时间等。一个维度落地就是一张维表。
**维度属性:**一个维度里面的具体属性,如用户维度的用户昵称、年龄、性别等。通俗讲就是维表的列。
指标:指标分为原子指标和派生指标。原子指标是基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,是具有明确业务含义的名词 ,体现明确的业务统计口径和计算逻辑,例如支付金额。
- 原子指标=业务过程+度量。
- 派生指标=时间周期+修饰词+原子指标,派生指标可以理解为对原子指标业务统计范围的圈定。
划分数据域并构建总线矩阵:
数仓建设是遵循纵向分层开发,横向划分数据域(也可以叫主题域)设计。数据域 是指面向业务分析 的,是联系较为紧密的数据主题的集合,是对业务对象高度概括的抽象归类。数据域一旦定下来之后不要轻易变动,同时也要考虑到覆盖之后可能的业务场景。
数据域划分一般有如下几种方法:
-
按照业务过程来划分,一个业务过程抽象出一个主题域,比如业务系统中的商品、交易、物流 等
-
按照业务部门来划分,一个业务部门抽象出一个主题域,比如中台部门、业务运营部门、供应链部门
-
按照业务系统来划分,一个业务系统抽象出一个主题域,比如搬家系统、erp系统 等
个人觉得不需要这么死板,按企业实际业务场景来设计即可,可以三者结合在一起使用,降一系列相近的业务过程合在一个数据域中,例如用户相关的所有信息可以整合成一个用户域,用户的曝光点击等行为可以整合成一个流量域。
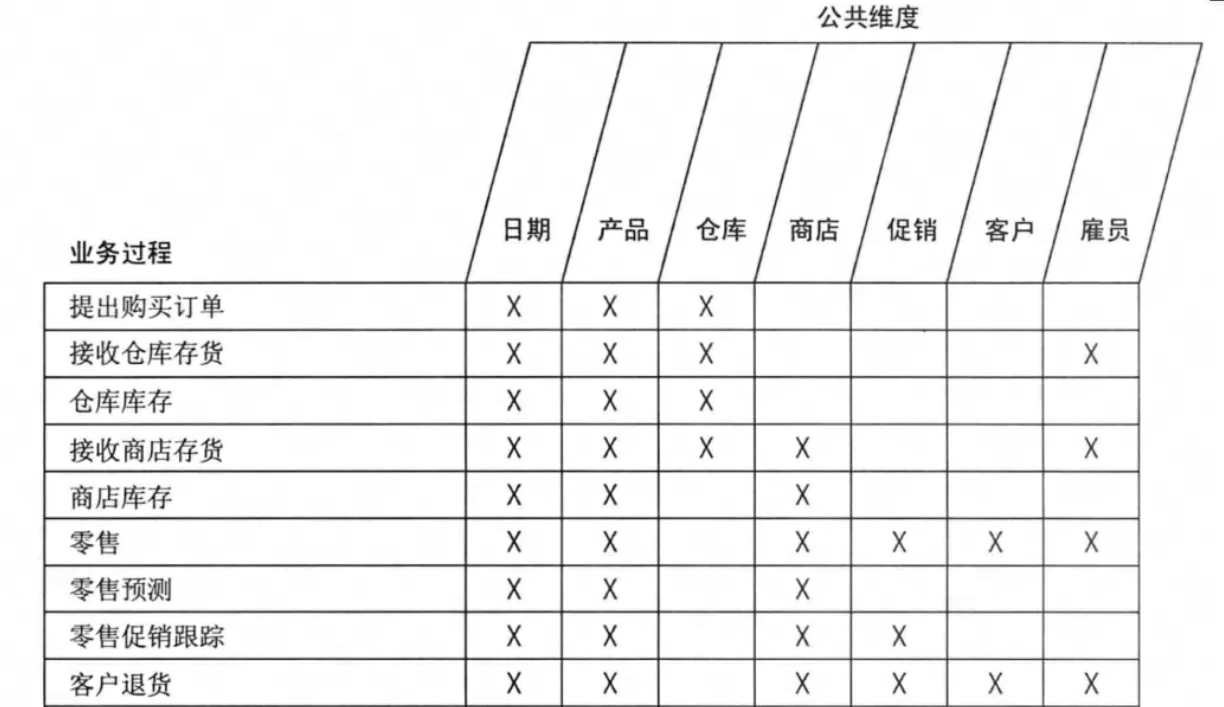
划分好数据域后,每个业务过程都有唯一的数据域。那么,业务过程×维度矩阵可以进一步扩展,构建面向业务过程的数据域×业务过程×维度的总线矩阵。 至此**,数据仓库中所有的业务形态就一目了然了:**
定义数据规范:
建立统一标准的数据规范和开发规范,确保整个数仓团队里面的人看到表名和字段名就能大概知道个七七八八。这里的规范包括但不限于:数据域命名规范、表名命名规范、指标命名规范、数据存储格式规范 等等
参考:
https://www.woshipm.com/pd/5656447.html(数据仓库/数据平台/数据中台/数据湖的区别)
https://www.cnblogs.com/itlz/p/14262577.html(维度建模概念)
https://blog.csdn.net/qiy_icbc/article/details/145607458(维度建模概念)
https://blog.csdn.net/u012100548/article/details/123627403(总线矩阵是数仓建设的纲领性文件.总线矩阵包含业务过程、公共一致性维度。每行代表一个业务过程,每列表示一个公共维度,还包括业务过程与维度间的联系,能看清整个数据仓库的数据)