| 压缩类型 | 特点 | 适用场景 |
|---|---|---|
| 无压缩 | 数据不进行压缩。 | 适用于不需要压缩的场景,例如数据已经被压缩或者存储空间不是问题的情况。 |
| LZ4 | 压缩和解压速度非常快。压缩比适中。 | 适用于对解压速度要求高的场景,如实时查询或高并发负载。 |
| LZ4F (LZ4 框架) | LZ4 的扩展版本,支持更灵活的压缩配置。- 速度快,压缩比适中。 | 适用于需要快速压缩并对配置有细粒度控制的场景。 |
| LZ4HC (LZ4 高压缩) | 相比 LZ4 有更高的压缩比,但压缩速度较慢。- 解压速度与 LZ4 相当。 | 适用于需要更高压缩比的场景,同时仍然关注解压速度。 |
| ZSTD (Zstandard) | 高压缩比,支持灵活的压缩级别调整。- 即使在高压缩比下,解压速度仍然很快。 | 适用于对存储效率要求较高且需要平衡查询性能的场景。 |
| Snappy | 设计重点是快速解压。- 压缩比适中。 | 适用于对解压速度要求高且对 CPU 消耗低的场景。 |
| Zlib | 提供良好的压缩比与速度平衡。- 与其他算法相比,压缩和解压速度较慢,但压缩比更高。 | 适用于对存储效率要求较高且对解压速度不敏感的场景,如归档和冷数据存储。 |
选择合适的压缩算法需根据工作负载特性:
- 对于
高性能实时分析场景,推荐使用 LZ4 或 Snappy。 - 对于
存储效率优先的场景,推荐使用 ZSTD 或 Zlib。 - 对于
需要兼顾速度和压缩率的场景,可选择 LZ4F。 - 对于
归档或冷数据存储场景,建议使用 Zlib 或 LZ4HC。
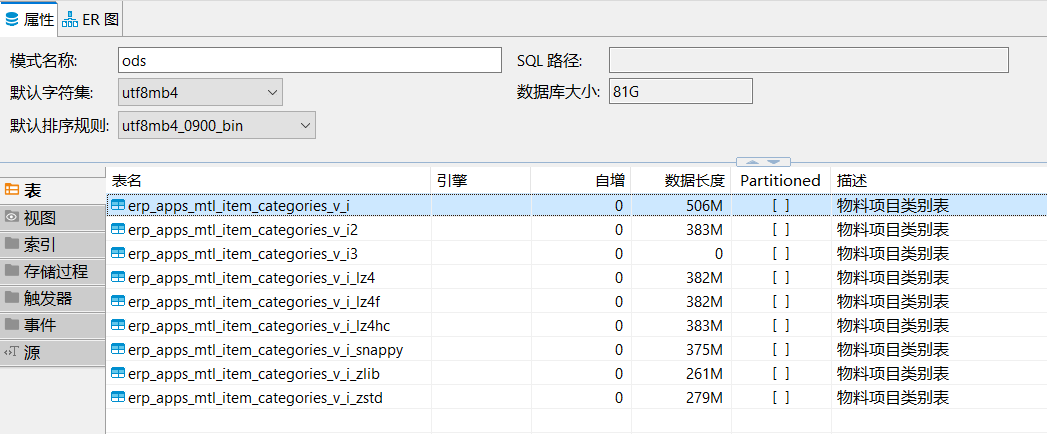
doris 的各个压缩方式,压缩后大概大小:
这里的i表,是原始表,大约700w行
指定压缩方式:"compression" = "lz4" -- 对表单独指定压缩方法`
sql
CREATE TABLE ods.erp_apps_mtl_item_categories_v_i (
inventory_item_id VARCHAR(45) NOT NULL,
organization_id VARCHAR(45) NOT NULL,
category_id VARCHAR(45) NOT NULL,
row_id VARCHAR(20),
category_set_id VARCHAR(45),
last_update_date DATETIME,
last_updated_by VARCHAR(45),
creation_date DATETIME,
created_by VARCHAR(45),
last_update_login VARCHAR(45),
request_id VARCHAR(45),
program_application_id VARCHAR(45),
program_id VARCHAR(45),
program_update_date DATETIME,
category_set_name VARCHAR(30),
structure_id VARCHAR(45),
validate_flag VARCHAR(1),
control_level VARCHAR(45),
control_level_disp VARCHAR(80),
category_concat_segs VARCHAR(163),
mult_item_cat_assign_flag VARCHAR(1),
category_structure_id VARCHAR(45),
category_disable_date DATETIME,
segment1 VARCHAR(40),
segment2 VARCHAR(40),
segment3 VARCHAR(40),
segment4 VARCHAR(40),
segment5 VARCHAR(40),
segment6 VARCHAR(40),
segment7 VARCHAR(40),
segment8 VARCHAR(40),
segment9 VARCHAR(40),
segment10 VARCHAR(40),
segment11 VARCHAR(40),
segment12 VARCHAR(40),
segment13 VARCHAR(40),
segment14 VARCHAR(40),
segment15 VARCHAR(40),
segment16 VARCHAR(40),
segment17 VARCHAR(40),
segment18 VARCHAR(40),
segment19 VARCHAR(40),
segment20 VARCHAR(40),
summary_flag VARCHAR(1),
enabled_flag VARCHAR(1),
hierarchy_enabled VARCHAR(1),
sys_update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
)
UNIQUE KEY(inventory_item_id, organization_id, category_id)
COMMENT '物料项目类别表'
DISTRIBUTED BY HASH(inventory_item_id, organization_id, category_id) BUCKETS AUTO
PROPERTIES (
"replication_num" = "2", -- 副本数,2个副本
"estimate_partition_size" = "3g", -- 自动分桶大小,按照3g大小划分
"enable_unique_key_merge_on_write" = "true", -- unique表,写时合并
"compression" = "lz4" -- 对表单独指定压缩方法
);显示当前doris库的所有表名,和表的创建时间
sql
select concat(table_schema,'.',table_name),CREATE_TIME
FROM information_schema.tables
WHERE table_schema in ('ods','dw','t25')
order by table_schema desc
;显示结果: