摘要 :在企业级 RAG(检索增强生成)落地过程中,我们往往面临一个棘手难题:高价值信息不仅存在于文本中,更大量隐藏在 PDF 的表格 、架构图 和统计图表 里。传统的"纯文本"RAG 对此束手无策。本文将带你从零构建一个多模态 RAG 系统 ,整合
Unstructured解析、CLIP跨模态嵌入、向量数据库及GPT-4o/Llava,实现对复杂文档的深度理解与问答。
一、 引言:为什么我们需要超越文本的 RAG?
在当今的 AI 应用开发中,RAG 已经成为解决大模型幻觉和知识时效性问题的标准范式。然而,在处理真实的商业文档(如金融研报、技术手册、合同)时,我们发现:
-
痛点 1 :约 35% 的关键数据存在于表格中,单纯提取文本会打乱行列关系,导致模型无法理解数据逻辑。
-
痛点 2 :约 15% 的核心信息(如趋势趋势、系统架构)以图片形式存在,传统 RAG 会直接丢弃这些视觉信息。
为了解决这个问题,我们需要构建一个多模态 RAG(Multimodal RAG)系统。它不仅能"读"字,还能"看"图,更能"理"表。
二、 系统架构设计
我们的多模态 RAG 系统包含五个紧密协作的核心模块,形成了一个完整的闭环:
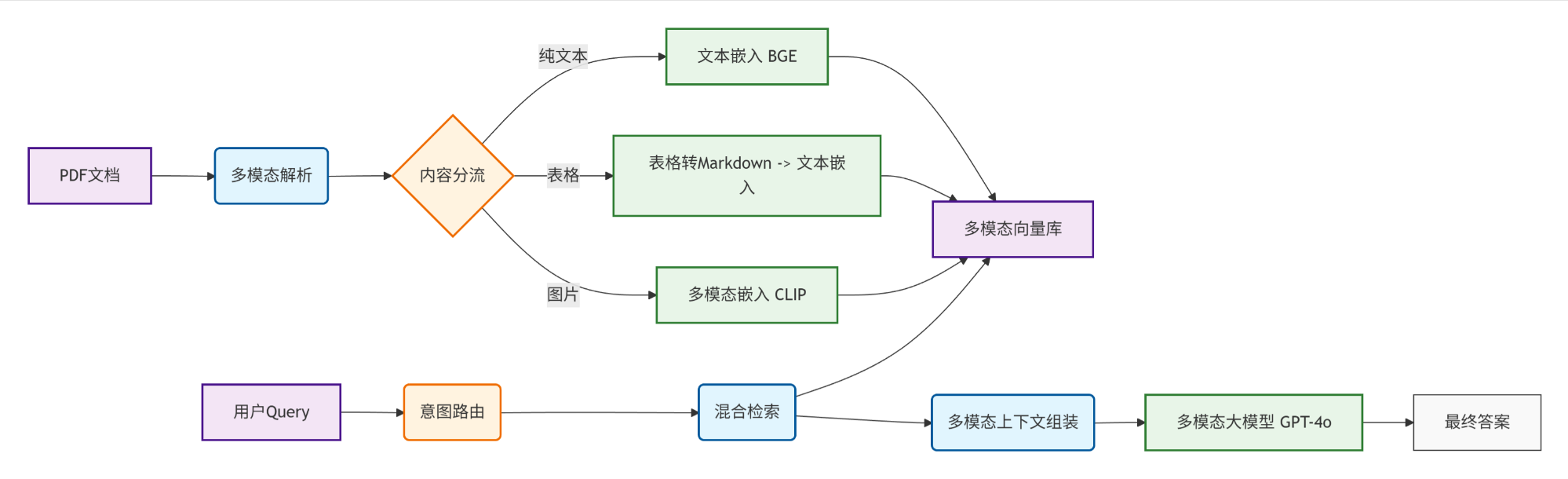
核心差异点
-
传统 RAG:PDF -> 文本提取 -> 文本向量 -> 检索 -> 文本生成
-
多模态 RAG :PDF -> 图/表/文分离 -> 多模态对齐编码 -> 混合检索 -> 多模态生成
三、 核心组件代码实现
3.1 深度文档解析:要把文档"拆碎"
这是最关键的一步。我们使用 unstructured 库,它能够通过计算机视觉模型识别版面,精准分离图片和表格。
环境准备:
python
pip install unstructured[pdf] pandas pillow torch transformers sentence-transformers chromadb openai
sudo apt-get install tesseract-ocr # 需要安装 OCR 引擎解析器实现 (parser.py):
python
import os
import base64
import pandas as pd
from typing import List, Dict, Any
from unstructured.partition.pdf import partition_pdf
class MultiModalPDFParser:
def __init__(self, pdf_path: str, output_dir: str = "./processed_data"):
self.pdf_path = pdf_path
self.output_dir = output_dir
os.makedirs(output_dir, exist_ok=True)
def extract_elements(self):
"""核心解析逻辑"""
print(f"正在解析文档: {self.pdf_path}...")
elements = partition_pdf(
filename=self.pdf_path,
strategy="hi_res", # 使用高分辨率策略(适合复杂布局)
extract_images_in_pdf=True, # 提取图片
extract_image_block_types=["Image", "Table"], # 将表格也作为图片提取一份
infer_table_structure=True, # 推断表格结构
chunking_strategy="by_title", # 按标题切分块
max_characters=2000,
new_after_n_chars=1500,
combine_text_under_n_chars=500,
image_output_dir_path=self.output_dir
)
return elements
def process_table(self, table_element, page_num: int) -> Dict[str, Any]:
"""将表格转换为 LLM 易读的 Markdown 格式"""
html_content = table_element.metadata.text_as_html
if not html_content:
return None
# 转换为 DataFrame 再转 Markdown,保证格式工整
try:
df = pd.read_html(html_content)[0]
table_md = df.to_markdown(index=False)
except:
table_md = table_element.text # 降级处理
return {
"type": "table",
"content": table_md,
"page": page_num,
"bbox": table_element.metadata.coordinates
}
def process_image(self, image_element, page_num: int) -> Dict[str, Any]:
"""处理图片:读取路径并转 Base64"""
image_path = image_element.metadata.image_path
with open(image_path, "rb") as img_file:
image_base64 = base64.b64encode(img_file.read()).decode('utf-8')
return {
"type": "image",
"base64": image_base64,
"path": image_path,
"context": "图片上下文描述", # 实际场景中可抓取图片前后的文本作为 context
"page": page_num
}3.2 多模态嵌入:统一语义空间
为了让图片和文本能相互检索(例如搜"销量趋势",能搜到一张折线图),我们需要使用 CLIP 模型,它将图像和文本映射到同一个向量空间。
嵌入器实现 (embedder.py):
python
from sentence_transformers import SentenceTransformer
from transformers import CLIPModel, CLIPProcessor
from PIL import Image
import torch
class MultiModalEmbedder:
def __init__(self, device: str = None):
self.device = device or ('cuda' if torch.cuda.is_available() else 'cpu')
# 1. 文本/表格嵌入模型 (强力中文模型)
self.text_model = SentenceTransformer('BAAI/bge-large-zh-v1.5', device=self.device)
# 2. 图片/跨模态嵌入模型 (CLIP)
self.clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32").to(self.device)
self.clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def embed_text(self, text: str) -> list:
return self.text_model.encode([text], normalize_embeddings=True)[0].tolist()
def embed_image(self, image_path: str) -> list:
image = Image.open(image_path)
inputs = self.clip_processor(images=image, return_tensors="pt").to(self.device)
with torch.no_grad():
features = self.clip_model.get_image_features(**inputs)
return features[0].cpu().numpy().tolist()
def embed_query_for_image(self, text_query: str) -> list:
"""用文本搜图片:将文本编码为 CLIP 图像空间的向量"""
inputs = self.clip_processor(text=[text_query], return_tensors="pt", padding=True).to(self.device)
with torch.no_grad():
features = self.clip_model.get_text_features(**inputs)
return features[0].cpu().numpy().tolist()3.3 智能路由与混合检索
用户的提问千变万化,我们需要一个**路由器(Router)**来决定去哪里搜数据。
-
问:"2023年营收增长多少?" -> 搜文本/表格
-
问:"展示一下系统架构图。" -> 搜图片
路由与检索实现 (retriever.py):
python
import re
from typing import Literal
class QueryRouter:
@staticmethod
def detect_query_type(query: str) -> Literal['text', 'image', 'mixed']:
query = query.lower()
# 简单的关键词匹配,实际可用 LLM 做分类
image_keywords = ['图片', '图表', '架构图', '趋势图', '展示', 'image', 'chart']
if any(k in query for k in image_keywords):
return 'mixed' # 既搜图也搜文
return 'text'
class MultiModalRetriever:
def __init__(self, vector_store, embedder):
self.vector_store = vector_store
self.embedder = embedder
self.router = QueryRouter()
def retrieve(self, query: str, top_k: int = 3):
query_type = self.router.detect_query_type(query)
results = {'text': [], 'images': []}
print(f"查询意图识别: {query_type}")
# 1. 文本/表格检索
text_emb = self.embedder.embed_text(query)
results['text'] = self.vector_store.search(
embedding=text_emb,
filter_type=["text", "table"],
k=top_k * 2
)
# 2. 图片检索 (如果是相关意图)
if query_type in ['image', 'mixed']:
# 使用 CLIP text encoder 找图片
clip_emb = self.embedder.embed_query_for_image(query)
results['images'] = self.vector_store.search(
embedding=clip_emb,
filter_type=["image"],
k=2 # 图片通常只要最相关的几张
)
return results四、 多模态生成:让 LLM"看图说话"
获取到图片和表格后,我们需要将它们组装成 Prompt 发送给支持视觉的大模型(如 GPT-4o, Claude 3.5 Sonnet 或 Gemini)。
python
import openai
class MultiModalGenerator:
def __init__(self, api_key):
openai.api_key = api_key
def generate_answer(self, query: str, retrieved_data: dict):
messages = [
{"role": "system", "content": "你是一个金融/技术专家,请根据提供的上下文(包含文本、表格Markdown和图片)回答用户问题。"}
]
user_content = [{"type": "text", "text": f"用户问题:{query}\n\n参考资料:"}]
# 1. 注入文本和表格
for item in retrieved_data['text']:
type_label = "【表格】" if item['type'] == 'table' else "【文本】"
user_content.append({
"type": "text",
"text": f"{type_label}\n{item['content']}\n"
})
# 2. 注入图片 (GPT-4V/4o 格式)
for img in retrieved_data['images']:
user_content.append({
"type": "text",
"text": "【相关图片参考】"
})
user_content.append({
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{img['base64']}"
}
})
messages.append({"role": "user", "content": user_content})
# 调用多模态模型
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=messages,
max_tokens=1000
)
return response.choices[0].message.content五、 部署与 API 服务化 (FastAPI)
将上述模块封装为微服务,即可在生产环境使用。
python
from fastapi import FastAPI, UploadFile, File
from pydantic import BaseModel
app = FastAPI()
system = MultiModalRAGSystem(config={...}) # 初始化系统单例
class QueryRequest(BaseModel):
question: str
@app.post("/upload_doc")
async def upload(file: UploadFile = File(...)):
# 1. 保存文件
save_path = f"temp/{file.filename}"
with open(save_path, "wb") as f:
f.write(await file.read())
# 2. 触发解析和入库
success = system.ingest_document(save_path)
return {"status": "success" if success else "failed"}
@app.post("/chat")
async def chat(req: QueryRequest):
# 3. 执行多模态检索与生成
answer = system.query(req.question)
return answer六、 进阶优化与最佳实践
在实际落地金融或工业场景时,还有以下坑需要避开:
-
表格语义增强:
-
单纯把表格转 Markdown 可能会丢失上下文。
-
技巧:使用 LLM 为每个表格生成一段 Text Summary(文本摘要),检索时先检索摘要,命中后再把完整表格 Markdown 塞给模型。
-
-
图片去噪:
-
PDF 页眉页脚通常包含 logo 图片,这些是噪音。
-
技巧:在解析阶段,根据图片尺寸过滤掉过小(图标)或长宽比极端的图片。
-
-
本地私有化替代:
- 如果数据敏感不能用 OpenAI,可以使用 Llava 1.5/1.6 或 Qwen-VL 进行本地部署。虽然推理速度较慢,但数据安全性更高。
-
Token 消耗控制:
-
图片 Base64 非常消耗 Token。
-
技巧 :设置
top_k限制,一次只发最相关的一张图;或者对图片进行下采样压缩后再发送。
-
七、 结语
构建多模态 RAG 系统是文档智能处理的必然趋势。通过本文的架构,我们成功地将非结构化文档中的"暗数据"(Dark Data)------图片和复杂表格,转化为了可检索、可理解的高价值知识。
希望这个框架能帮助你快速搭建起自己的多模态知识库!
附录:项目资源
-
Unstructured Docs : https://unstructured-io.github.io/
-
OpenAI CLIP : https://github.com/openai/CLIP
-
ChromaDB : https://docs.trychroma.com/