目录
[1. 项目背景](#1. 项目背景)
[2. 环境准备](#2. 环境准备)
[1. 数据预处理](#1. 数据预处理)
[1. 训练参数设置](#1. 训练参数设置)
[2. 训练与评估流程](#2. 训练与评估流程)
在计算机视觉领域,猫狗分类是经典的入门任务之一。本文将带大家从零开始,使用 PyTorch 框架搭建卷积神经网络(CNN),完成猫狗图像的二分类任务,并对训练过程中的损失和准确率进行可视化分析。
一、项目背景与环境准备
1. 项目背景
猫狗分类任务属于图像二分类问题,目标是让模型能够准确区分输入的图像是猫还是狗。该任务能够很好地帮助我们理解卷积神经网络的工作原理以及 PyTorch 的基本使用流程。
2. 环境准备
本次实战需要用到以下 Python 库:
-
torch:PyTorch 核心库,用于构建和训练神经网络
-
torchvision:提供图像预处理、数据集加载等功能
-
matplotlib:用于数据可视化
-
numpy:数值计算辅助库
可以通过以下命令安装所需库:
python
pip install torch torchvision matplotlib numpy二、数据预处理与加载
1. 数据预处理
为了让图像数据能够适配神经网络的输入,我们需要对图像进行预处理:
-
调整图像尺寸为 224×224(统一输入尺寸)
-
转换为张量(PyTorch 的基本数据类型)
-
归一化(使用 ImageNet 的均值和标准差,提升模型收敛速度)
python
from torchvision import transforms
# 定义数据预处理流程
data_transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像尺寸
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])2、数据加载
使用 PyTorch 的ImageFolder和DataLoader加载数据集,实现批量读取和打乱数据:
python
from torch.utils.data import DataLoader
from torchvision import datasets
# 加载训练集和测试集
train_dataset = datasets.ImageFolder(root=r'E:\数据分析\数据集\cat_and_dog\train', transform=data_transform)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True, drop_last=True)
test_dataset = datasets.ImageFolder(root=r'E:\数据分析\数据集\cat_and_dog\test', transform=data_transform)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=True, drop_last=True)三、搭建卷积神经网络模型
本次搭建的 CNN 模型包含多个卷积层、池化层、全连接层,具体结构如下:
-
卷积层:使用 3×3 的卷积核,逐步提升通道数(16→32→64→128→128→256)
-
激活函数:ReLU,引入非线性特征
-
池化层:最大池化,降低特征维度
-
全连接层:将展平后的特征映射到分类结果(2 类:猫和狗)
-
Dropout 层:防止过拟合
python
import torch
from torch import nn
class Network(nn.Module):
def __init__(self, input_dim):
super(Network, self).__init__()
self.model = nn.Sequential(
# 卷积层1 + 池化层1
nn.Conv2d(in_channels=input_dim, out_channels=16, kernel_size=(3, 3), stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=2),
# 卷积层2 + 池化层2
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=(3, 3), stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=2),
# 卷积层3 + 池化层3
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(3, 3), stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=2),
# 卷积层4 + 池化层4
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3, 3), stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=2),
# 卷积层5 + 池化层5
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3, 3), stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=2),
# 卷积层6 + 池化层6
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3, 3), stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(1, 1), stride=1),
# 展平 + 全连接层
nn.Flatten(),
nn.Linear(in_features=2304, out_features=1024),
nn.ReLU(),
nn.Dropout(p=0.5), # Dropout防止过拟合
nn.Linear(in_features=1024, out_features=2) # 二分类输出
)
def forward(self, x):
return self.model(x)四、模型训练与评估
1. 训练参数设置
python
from torch import optim, device, cuda
# 设备选择:优先使用GPU
device = device('cuda' if cuda.is_available() else 'cpu')
# 初始化模型
network = Network(input_dim=3).to(device) # input_dim=3表示RGB三通道图像
# 损失函数:交叉熵损失(适用于分类任务)
loss_fun = nn.CrossEntropyLoss()
# 优化器:Adam优化器
optimizer = optim.Adam(params=network.parameters(), lr=1e-3)
# 训练轮数
epochs = 202. 训练与评估流程
训练过程中,我们会交替进行训练和测试,记录每一轮的损失和准确率:
python
# 初始化列表,用于存储训练过程中的指标
train_loss_list = []
train_acc_list = []
test_loss_list = []
test_acc_list = []
for epoch in range(epochs):
# 训练模式
network.train()
total_train_loss = 0.0
train_correct = 0
train_total = 0
for train_x, train_y in train_dataloader:
train_x, train_y = train_x.to(device), train_y.to(device)
# 前向传播
pred_y = network(train_x)
loss = loss_fun(pred_y, train_y)
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录损失
total_train_loss += loss.item()
# 计算准确率
_, pred_label = torch.max(pred_y, dim=1)
train_correct += (pred_label == train_y).sum().item()
train_total += train_y.size(0)
# 测试模式(关闭梯度计算,提升速度)
network.eval()
total_test_loss = 0.0
test_correct = 0
test_total = 0
with torch.no_grad():
for test_x, test_y in test_dataloader:
test_x, test_y = test_x.to(device), test_y.to(device)
pred_y = network(test_x)
loss = loss_fun(pred_y, test_y)
total_test_loss += loss.item()
# 计算准确率
_, pred_label = torch.max(pred_y, dim=1)
test_correct += (pred_label == test_y).sum().item()
test_total += test_y.size(0)
# 计算平均损失和准确率
avg_train_loss = total_train_loss / len(train_dataloader)
train_acc = train_correct / train_total
avg_test_loss = total_test_loss / len(test_dataloader)
test_acc = test_correct / test_total
# 存储指标
train_loss_list.append(avg_train_loss)
train_acc_list.append(train_acc)
test_loss_list.append(avg_test_loss)
test_acc_list.append(test_acc)
# 打印训练信息
print(
f'第{epoch + 1}轮训练:训练损失:{avg_train_loss:.4f} 训练准确率:{train_acc:.2%} 测试损失:{avg_test_loss:.4f} 测试准确率:{test_acc:.2%}')五、训练结果可视化
使用 matplotlib 将训练过程中的损失和准确率变化趋势可视化:
python
import matplotlib.pyplot as plt
import numpy as np
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制可视化图表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 损失变化趋势
ax1.plot(range(1, epochs + 1), train_loss_list, label='训练损失', marker='o', markersize=4, linewidth=2)
ax1.plot(range(1, epochs + 1), test_loss_list, label='测试损失', marker='s', markersize=4, linewidth=2)
ax1.set_title('训练/测试损失变化趋势')
ax1.set_xlabel('训练轮数')
ax1.set_ylabel('损失值')
ax1.legend()
ax1.grid(True, alpha=0.3)
ax1.set_xlim(1, epochs)
# 准确率变化趋势
ax2.plot(range(1, epochs + 1), [acc * 100 for acc in train_acc_list], label='训练准确率', marker='o', markersize=4,
linewidth=2)
ax2.plot(range(1, epochs + 1), [acc * 100 for acc in test_acc_list], label='测试准确率', marker='s', markersize=4,
linewidth=2)
ax2.set_title('训练/测试准确率变化趋势')
ax2.set_xlabel('训练轮数')
ax2.set_ylabel('准确率(%)')
ax2.legend()
ax2.grid(True, alpha=0.3)
ax2.set_xlim(1, epochs)
ax2.set_ylim(0, 100)
# 保存并显示图像
plt.tight_layout()
plt.savefig('cat_dog_training_metrics.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印最终结果
print(f'\n最终训练准确率:{train_acc_list[-1]:.2%}')
print(f'最终测试准确率:{test_acc_list[-1]:.2%}')
print(f'最终训练损失:{train_loss_list[-1]:.4f}')
print(f'最终测试损失:{test_loss_list[-1]:.4f}')六、结果分析与优化方向
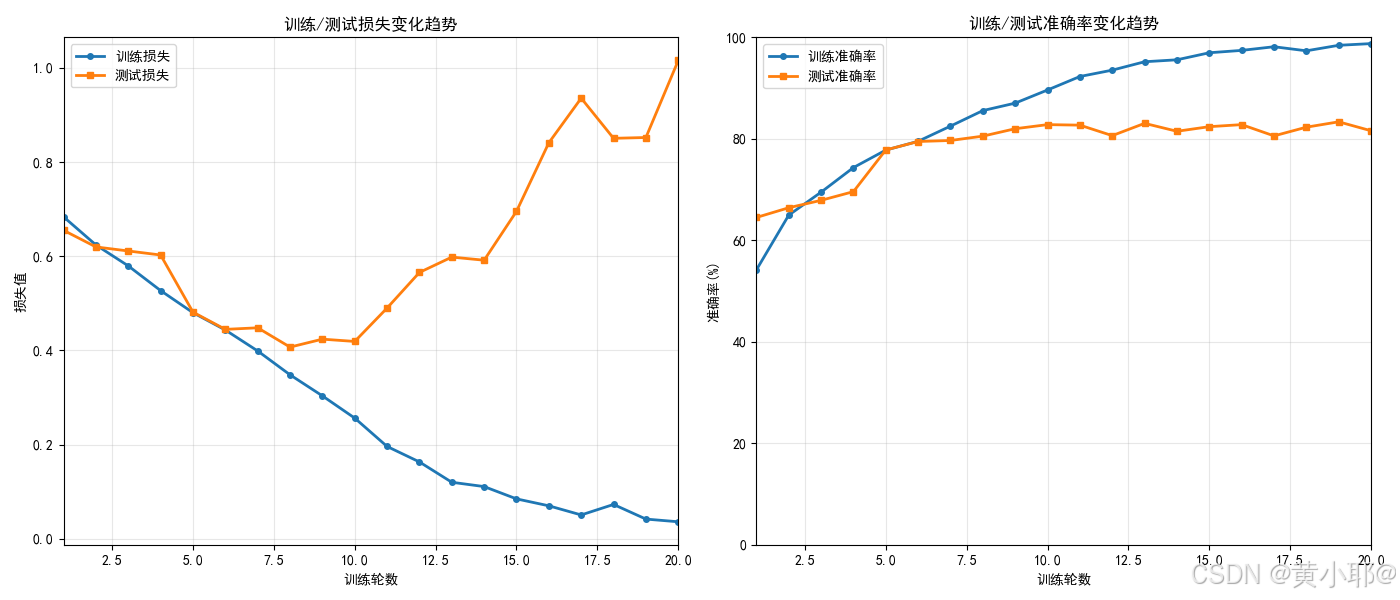
核心指标总结
-
最终训练准确率:98.78%(模型在训练集上几乎完美拟合)
-
最终测试准确率:81.60%(模型泛化能力不足)
-
训练损失趋势:从 0.6834 持续下降至 0.0360,下降趋势明显
-
测试损失趋势:前 10 轮小幅下降(0.6548→0.4189),10 轮后持续上升(0.4189→1.0155)
- 过拟合的典型特征
-
训练集表现:损失持续降低,准确率接近 100%,说明模型完全记住了训练集的特征。
-
测试集表现:前 10 轮测试损失下降、准确率上升(模型正常学习);10 轮后测试损失骤升、准确率波动下降(模型开始学习训练集的噪声和冗余特征,对新数据的适配能力下降)。
- 过拟合产生的原因
结合模型结构和训练流程,过拟合的主要原因有以下几点:
-
模型复杂度较高:搭建的 CNN 包含 6 层卷积层和 2 层全连接层,参数数量较多,容易对训练集过度拟合。
-
缺乏数据增强:仅对图像进行了尺寸调整和归一化,没有增加数据的多样性,模型容易记住有限的训练样本。
-
正则化手段单一:仅使用了 Dropout(p=0.5),正则化强度不足,无法有效抑制过拟合。
-
学习率固定:全程使用 1e-3 的学习率,后期学习率过高,导致模型在训练集上震荡拟合,加剧过拟合。
七、完整代码
python
from torch import nn, optim, device, cuda
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import torch
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_dataset = datasets.ImageFolder(root=r'E:\数据分析\数据集\cat_and_dog\train', transform=data_transform)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True, drop_last=True)
test_dataset = datasets.ImageFolder(root=r'E:\数据分析\数据集\cat_and_dog\test', transform=data_transform)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=True, drop_last=True)
class Network(nn.Module):
def __init__(self, input_dim):
super(Network, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=input_dim, out_channels=16, kernel_size=(3, 3), stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=2),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=(3, 3), stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(3, 3), stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3, 3), stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=2),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3, 3), stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=2),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3, 3), stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(1, 1), stride=1),
nn.Flatten(),
nn.Linear(in_features=2304, out_features=1024),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=1024, out_features=2)
)
def forward(self, x):
return self.model(x)
epochs = 20
device = device('cuda' if cuda.is_available() else 'cpu')
network = Network(input_dim=3).to(device)
loss_fun = nn.CrossEntropyLoss()
optimzer = optim.Adam(params=network.parameters(), lr=1e-3)
# 初始化列表,用于存储训练过程中的指标
train_loss_list = []
train_acc_list = []
test_loss_list = []
test_acc_list = []
for epoch in range(epochs):
network.train()
total_train_loss = 0.0
train_correct = 0
train_total = 0
for train_x, train_y in train_dataloader:
train_x, train_y = train_x.to(device), train_y.to(device)
pred_y = network(train_x)
loss = loss_fun(pred_y, train_y)
optimzer.zero_grad()
loss.backward()
optimzer.step()
total_train_loss += loss.item()
_, pred_label = torch.max(pred_y, dim=1)
train_correct += (pred_label == train_y).sum().item()
train_total += train_y.size(0)
network.eval()
total_test_loss = 0.0
test_correct = 0
test_total = 0
with torch.no_grad():
for test_x, test_y in test_dataloader:
test_x, test_y = test_x.to(device), test_y.to(device)
pred_y = network(test_x)
loss = loss_fun(pred_y, test_y)
total_test_loss += loss.item()
_, pred_label = torch.max(pred_y, dim=1)
test_correct += (pred_label == test_y).sum().item()
test_total += test_y.size(0)
avg_train_loss = total_train_loss / len(train_dataloader)
train_acc = train_correct / train_total
avg_test_loss = total_test_loss / len(test_dataloader)
test_acc = test_correct / test_total
train_loss_list.append(avg_train_loss)
train_acc_list.append(train_acc)
test_loss_list.append(avg_test_loss)
test_acc_list.append(test_acc)
print(
f'第{epoch + 1}轮训练:训练损失:{avg_train_loss:.4f} 训练准确率:{train_acc:.2%} 测试损失:{avg_test_loss:.4f} 测试准确率:{test_acc:.2%}')
# 绘制可视化图表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
ax1.plot(range(1, epochs + 1), train_loss_list, label='训练损失', marker='o', markersize=4, linewidth=2)
ax1.plot(range(1, epochs + 1), test_loss_list, label='测试损失', marker='s', markersize=4, linewidth=2)
ax1.set_title('训练/测试损失变化趋势')
ax1.set_xlabel('训练轮数')
ax1.set_ylabel('损失值')
ax1.legend()
ax1.grid(True, alpha=0.3)
ax1.set_xlim(1, epochs)
ax2.plot(range(1, epochs + 1), [acc * 100 for acc in train_acc_list], label='训练准确率', marker='o', markersize=4,
linewidth=2)
ax2.plot(range(1, epochs + 1), [acc * 100 for acc in test_acc_list], label='测试准确率', marker='s', markersize=4,
linewidth=2)
ax2.set_title('训练/测试准确率变化趋势')
ax2.set_xlabel('训练轮数')
ax2.set_ylabel('准确率(%)')
ax2.legend()
ax2.grid(True, alpha=0.3)
ax2.set_xlim(1, epochs)
ax2.set_ylim(0, 100)
plt.tight_layout()
plt.savefig('cat_dog_training_metrics.png', dpi=300, bbox_inches='tight')
plt.show()
print(f'\n最终训练准确率:{train_acc_list[-1]:.2%}')
print(f'最终测试准确率:{test_acc_list[-1]:.2%}')
print(f'最终训练损失:{train_loss_list[-1]:.4f}')
print(f'最终测试损失:{test_loss_list[-1]:.4f}')