文章目录
-
- 虚拟内存揭秘:地址空间的魔法
- 一、程序地址空间回顾
-
- [1.1 经典的内存布局图](#1.1 经典的内存布局图)
- [1.2 验证各个区域](#1.2 验证各个区域)
- 二、虚拟地址的发现
-
- [2.1 同地址不同内容的实验](#2.1 同地址不同内容的实验)
- [2.2 奇怪的现象](#2.2 奇怪的现象)
- [2.3 唯一的解释](#2.3 唯一的解释)
- 三、虚拟地址空间的本质
-
- [3.1 什么是虚拟地址空间](#3.1 什么是虚拟地址空间)
- [3.2 用生活例子理解](#3.2 用生活例子理解)
- [3.3 进程看到的vs实际的](#3.3 进程看到的vs实际的)
- [3.4 页表:虚拟到物理的桥梁](#3.4 页表:虚拟到物理的桥梁)
- 四、进程地址空间的管理
-
- [4.1 mm_struct:内存描述符](#4.1 mm_struct:内存描述符)
- [4.2 vm_area_struct:虚拟内存区域](#4.2 vm_area_struct:虚拟内存区域)
- [4.3 VMA的组织方式](#4.3 VMA的组织方式)
- [4.4 完整的数据结构关系图](#4.4 完整的数据结构关系图)
- 五、为什么需要虚拟地址空间
-
- [5.1 问题1:安全风险](#5.1 问题1:安全风险)
- [5.2 问题2:地址不确定](#5.2 问题2:地址不确定)
- [5.3 问题3:内存碎片和效率](#5.3 问题3:内存碎片和效率)
- [5.4 问题4:内存超额使用](#5.4 问题4:内存超额使用)
- 六、写时拷贝(Copy-On-Write)
-
- [6.1 fork的代价](#6.1 fork的代价)
- [6.2 写时拷贝机制](#6.2 写时拷贝机制)
- [6.3 写时拷贝的优势](#6.3 写时拷贝的优势)
- 七、深入理解虚拟地址空间
-
- [7.1 为什么每个进程的地址空间看起来一样](#7.1 为什么每个进程的地址空间看起来一样)
- [7.2 用户空间与内核空间](#7.2 用户空间与内核空间)
- [7.3 为什么需要内核空间](#7.3 为什么需要内核空间)
- 八、虚拟内存管理的完整图景
-
- [8.1 从虚拟地址到物理地址的完整流程](#8.1 从虚拟地址到物理地址的完整流程)
- [8.2 多级页表](#8.2 多级页表)
- [8.3 TLB:页表缓存](#8.3 TLB:页表缓存)
- 九、实际应用:查看进程地址空间
-
- [9.1 通过/proc查看](#9.1 通过/proc查看)
- [9.2 内存使用统计](#9.2 内存使用统计)
- 十、总结与思考
虚拟内存揭秘:地址空间的魔法
💬 欢迎讨论:这是Linux系统编程系列的第四篇,也是最烧脑的一篇!我们将揭开虚拟地址空间的神秘面纱,理解为什么进程之间可以完全隔离。如果你在阅读过程中有任何疑问,欢迎在评论区留言!
👍 点赞、收藏与分享:这篇文章包含了操作系统最核心的设计思想,如果对你有帮助,请务必点赞、收藏并分享!
🚀 前置知识:建议先学习前三篇文章,理解进程的基本概念。本篇会回答第一篇中留下的悬念:为什么父子进程的变量地址相同但内容不同?
一、程序地址空间回顾
在正式讲解虚拟内存之前,我们先回顾一下C语言中学过的内存布局。
1.1 经典的内存布局图
在学C语言时,老师可能给你画过这样的图:
bash
高地址
┌─────────────┐
│ 命令行参数 │ argv[], env[]
│ 和环境变量 │
├─────────────┤
│ │ ↓栈的增长方向
│ 栈(stack) │
│ │
├─────────────┤
│ ↕ │ (未使用的空间)
├─────────────┤
│ │ ↑堆的增长方向
│ 堆(heap) │
│ │
├─────────────┤
│ 未初始化数据│ .bss段
│ (BSS) │ 未初始化的全局变量
├─────────────┤
│ 已初始化数据│ .data段
│ (Data) │ 已初始化的全局变量、静态变量
├─────────────┤
│ 只读数据 │ .rodata段
│ │ 字符串常量等
├─────────────┤
│ 代码段 │ .text段
│ (Text) │ 程序的机器指令
└─────────────┘
低地址但是,这个图只是一个概念模型。当时我们并不理解这些地址是什么,它们是物理内存吗?
1.2 验证各个区域
让我们写代码来验证这个内存布局:
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int g_unval; // 未初始化全局变量
int g_val = 100; // 已初始化全局变量
const char *str = "hello"; // 字符串常量
void func() {} // 函数(代码段)
int main(int argc, char *argv[], char *env[])
{
static int s_val = 10; // 静态变量
int local = 0; // 局部变量(栈)
// 动态分配(堆)
char *heap1 = (char*)malloc(10);
char *heap2 = (char*)malloc(10);
char *heap3 = (char*)malloc(10);
printf("========== 代码段 ==========\n");
printf("函数地址: %p\n", func);
printf("main地址: %p\n", main);
printf("\n========== 只读数据段 ==========\n");
printf("字符串常量: %p\n", str);
printf("\n========== 已初始化数据段 ==========\n");
printf("全局变量g_val: %p\n", &g_val);
printf("静态变量s_val: %p\n", &s_val);
printf("\n========== 未初始化数据段(BSS) ==========\n");
printf("全局变量g_unval: %p\n", &g_unval);
printf("\n========== 堆 ==========\n");
printf("heap1: %p\n", heap1);
printf("heap2: %p\n", heap2);
printf("heap3: %p\n", heap3);
printf("\n========== 栈 ==========\n");
printf("局部变量local: %p\n", &local);
printf("heap1的地址(在栈上): %p\n", &heap1);
printf("heap2的地址(在栈上): %p\n", &heap2);
printf("\n========== 命令行参数和环境变量 ==========\n");
printf("argv[0]: %p\n", argv[0]);
for(int i = 0; i < 3 && env[i]; i++) {
printf("env[%d]: %p\n", i, env[i]);
}
free(heap1);
free(heap2);
free(heap3);
return 0;
}编译运行:
bash
gcc test.c -o test
./test输出示例(地址会因系统而异):
bash
========== 代码段 ==========
函数地址: 0x400566
main地址: 0x40057d
========== 只读数据段 ==========
字符串常量: 0x400808
========== 已初始化数据段 ==========
全局变量g_val: 0x601040
静态变量s_val: 0x601044
========== 未初始化数据段(BSS) ==========
全局变量g_unval: 0x601050
========== 堆 ==========
heap1: 0x1a51010
heap2: 0x1a51030
heap3: 0x1a51050
========== 栈 ==========
局部变量local: 0x7ffd2b8c4a3c
heap1的地址(在栈上): 0x7ffd2b8c4a40
heap2的地址(在栈上): 0x7ffd2b8c4a48
========== 命令行参数和环境变量 ==========
argv[0]: 0x7ffd2b8c5c89
env[0]: 0x7ffd2b8c5c93
env[1]: 0x7ffd2b8c5ca8
env[2]: 0x7ffd2b8c5cbf观察地址的分布规律:
- 代码段地址最低(0x400000附近)
- 数据段在中间(0x601000附近)
- 堆地址较高(0x1a51000附近)
- 栈地址最高(0x7ffd...)
这验证了我们的内存布局图!
二、虚拟地址的发现
现在我们来做一个更有趣的实验,这个实验将揭示虚拟地址的秘密。
2.1 同地址不同内容的实验
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 100; // 全局变量
int main()
{
pid_t id = fork();
if(id < 0) {
perror("fork");
return 1;
}
else if(id == 0) {
// 子进程:修改变量
int count = 0;
while(count < 5) {
printf("子进程[%d]: g_val=%d, 地址=%p\n",
getpid(), g_val, &g_val);
g_val++;
sleep(1);
count++;
}
}
else {
// 父进程:读取变量
int count = 0;
while(count < 5) {
printf("父进程[%d]: g_val=%d, 地址=%p\n",
getpid(), g_val, &g_val);
sleep(1);
count++;
}
}
return 0;
}运行结果:
bash
子进程[12680]: g_val=100, 地址=0x601040
父进程[12679]: g_val=100, 地址=0x601040
子进程[12680]: g_val=101, 地址=0x601040
父进程[12679]: g_val=100, 地址=0x601040
子进程[12680]: g_val=102, 地址=0x601040
父进程[12679]: g_val=100, 地址=0x601040
子进程[12680]: g_val=103, 地址=0x601040
父进程[12679]: g_val=100, 地址=0x601040
子进程[12680]: g_val=104, 地址=0x601040
父进程[12679]: g_val=100, 地址=0x6010402.2 奇怪的现象
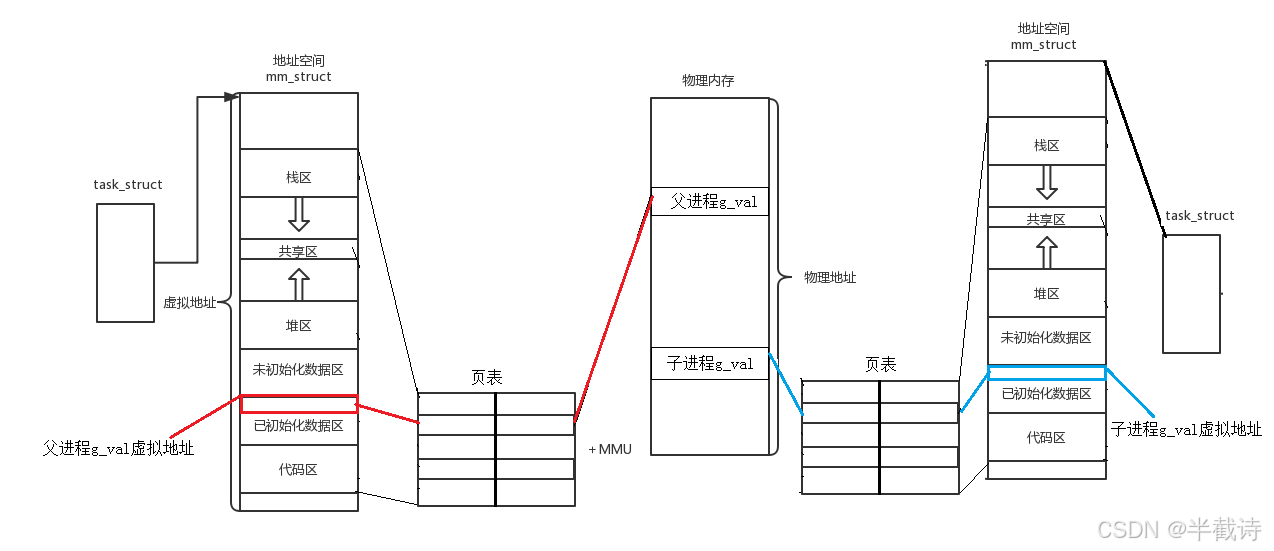
从输出中我们发现了两个矛盾的事实:
事实1:地址相同
- 父进程:
0x601040 - 子进程:
0x601040
事实2:内容不同
- 父进程:
g_val始终是100 - 子进程:
g_val从100递增到104
这怎么可能?如果它们是同一个物理地址,怎么会有不同的值?
2.3 唯一的解释
这说明:我们看到的地址不是物理地址!
在Linux系统中,程序(包括我们写的C/C++代码)看到的所有地址都是虚拟地址(Virtual Address)。
物理地址由操作系统管理,用户程序根本看不到。
三、虚拟地址空间的本质
3.1 什么是虚拟地址空间
虚拟地址空间是操作系统为每个进程提供的一个抽象,它:
- 是一段连续的地址范围
- 在32位系统上是0x00000000到0xFFFFFFFF(4GB)
- 在64位系统上理论上是0到2^64-1(实际使用48位,256TB)
- 每个进程都有自己独立的虚拟地址空间
重点:虚拟地址空间不是物理内存!它是一个抽象的概念!
3.2 用生活例子理解
想象你在玩《大富翁》游戏:
- 游戏地图(虚拟地址空间):每个玩家都有一个相同布局的地图
- 游戏棋子(虚拟地址):标记你在地图上的位置
- 真实房间(物理内存):游戏在真实世界中占用的空间
每个玩家的地图看起来一样,比如都有一个"北京"、一个"上海"。但这只是游戏中的抽象,实际上所有玩家都在同一个房间里,占用不同的物理空间。
3.3 进程看到的vs实际的
画个图说明:
bash
进程A看到的(虚拟地址空间) 进程B看到的(虚拟地址空间)
┌──────────────┐ ┌──────────────┐
│ 0xFFFFFFFF │ │ 0xFFFFFFFF │
│ │ │ │
│ 栈 │ │ 栈 │
│ │ │ │
│ ↓ │ │ ↓ │
│ │ │ │
│ ↑ │ │ ↑ │
│ 堆 │ │ 堆 │
│ │ │ │
│ 数据段 │ │ 数据段 │
│ 代码段 │ │ 代码段 │
│ 0x00000000 │ │ 0x00000000 │
└──────────────┘ └──────────────┘
│ │
│ 页表映射 │
▼ ▼
┌────────────────────────────────────────────┐
│ 物理内存(RAM) │
│ ┌──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┬──┐ │
│ │A │B │ │A │B │空│B │A │ │空│A │ │ │
│ └──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┴──┘ │
│ 进程A和B的数据实际存储在物理内存的不同位置 │
└────────────────────────────────────────────┘3.4 页表:虚拟到物理的桥梁
虚拟地址如何转换成物理地址?答案是:页表(Page Table)。
分页机制:
- 虚拟地址空间和物理内存都被分成固定大小的块,叫做页(Page)
- 在x86架构中,一页通常是4KB(4096字节)
- 每个进程都有一个页表,记录虚拟页到物理页的映射关系
bash
虚拟地址 = 虚拟页号 + 页内偏移
例如:虚拟地址 0x12345678
- 页大小 = 4KB = 0x1000
- 虚拟页号 = 0x12345678 / 0x1000 = 0x12345
- 页内偏移 = 0x12345678 % 0x1000 = 0x678
查页表找到虚拟页号对应的物理页号 = 0xABCDE
物理地址 = 0xABCDE * 0x1000 + 0x678 = 0xABCDE678四、进程地址空间的管理
现在我们来看操作系统如何管理进程的虚拟地址空间。
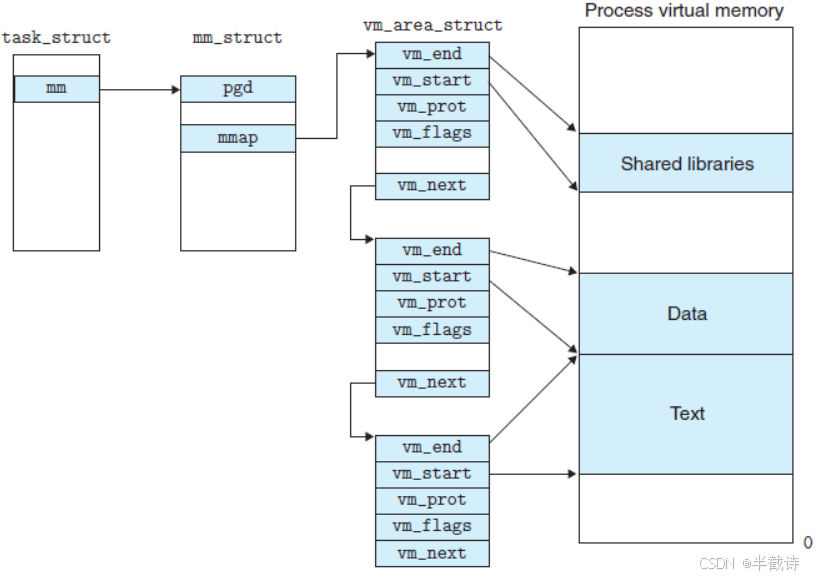
4.1 mm_struct:内存描述符
每个进程的虚拟地址空间信息存储在mm_struct结构体中:
cpp
struct mm_struct {
struct vm_area_struct *mmap; // VMA链表头
struct rb_root mm_rb; // VMA红黑树
unsigned long task_size; // 用户空间大小
// 各个段的起始和结束地址
unsigned long start_code; // 代码段开始
unsigned long end_code; // 代码段结束
unsigned long start_data; // 数据段开始
unsigned long end_data; // 数据段结束
unsigned long start_brk; // 堆开始
unsigned long brk; // 堆当前结束位置
unsigned long start_stack; // 栈开始
unsigned long arg_start; // 命令行参数开始
unsigned long arg_end; // 命令行参数结束
unsigned long env_start; // 环境变量开始
unsigned long env_end; // 环境变量结束
pgd_t *pgd; // 页表指针
// ... 其他字段
};每个进程的task_struct中有一个指向mm_struct的指针:
cpp
struct task_struct {
// ...
struct mm_struct *mm; // 指向内存描述符
// ...
};4.2 vm_area_struct:虚拟内存区域
mm_struct中最重要的是vm_area_struct(VMA),它描述一段连续的虚拟地址区域。
cpp
struct vm_area_struct {
unsigned long vm_start; // 区域开始地址
unsigned long vm_end; // 区域结束地址
struct vm_area_struct *vm_next; // 链表指针
struct rb_node vm_rb; // 红黑树节点
struct mm_struct *vm_mm; // 所属的mm_struct
unsigned long vm_flags; // 标志位(可读/可写/可执行)
struct file *vm_file; // 映射的文件(如果有)
unsigned long vm_pgoff; // 文件映射的偏移
// ... 其他字段
};4.3 VMA的组织方式
一个进程的地址空间通常包含多个VMA,例如:
- 代码段:一个VMA,只读+可执行
- 数据段:一个VMA,可读+可写
- BSS段:一个VMA,可读+可写
- 堆:一个VMA,可读+可写,动态增长
- 栈:一个VMA,可读+可写,动态增长
- 共享库:每个库有多个VMA
这些VMA通过两种方式组织:
1. 链表(VMA较少时)
bash
mm_struct.mmap → VMA1 → VMA2 → VMA3 → NULL2. 红黑树(VMA较多时,查找更快)
bash
mm_struct.mm_rb
│
VMA5
/ \
VMA3 VMA8
/ \ / \
VMA1 VMA4 VMA7 VMA94.4 完整的数据结构关系图
bash
task_struct (进程控制块)
│
├─ mm ───→ mm_struct (内存描述符)
│ │
│ ├─ mmap ───→ VMA链表
│ │ │
│ │ ├─ VMA1 [代码段]
│ │ ├─ VMA2 [数据段]
│ │ ├─ VMA3 [堆]
│ │ └─ VMA4 [栈]
│ │
│ ├─ mm_rb ───→ VMA红黑树
│ │
│ └─ pgd ───→ 页表
│ │
│ └─ 虚拟地址→物理地址映射
│
└─ ...
五、为什么需要虚拟地址空间
理解了虚拟地址空间的结构后,我们来思考:为什么要设计这么复杂的机制?直接使用物理地址不行吗?
5.1 问题1:安全风险
如果程序直接访问物理内存:
cpp
int *p = (int*)0x1000; // 直接访问物理地址0x1000
*p = 666; // 可能破坏其他进程或内核的数据!任何进程都能访问任意物理地址,这会导致:
- 进程可以读写其他进程的数据
- 恶意程序可以修改内核内存
- 一个进程崩溃可能导致整个系统崩溃
虚拟地址的解决方案:
每个进程只能访问自己的虚拟地址空间。即使进程试图访问其他地址,页表也不会映射到其他进程的物理内存,操作系统会触发段错误(Segmentation Fault)。
5.2 问题2:地址不确定
如果使用物理地址,程序加载到内存的位置是不确定的:
第一次运行:
bash
内存空着,程序加载到0x0000地址第二次运行:
bash
内存中已有其他程序,程序只能加载到0x5000地址这会导致:
- 编译时无法确定变量的地址
- 程序每次运行的地址都不同
- 指针失效
虚拟地址的解决方案:
每个进程都有独立的虚拟地址空间,程序总是从固定的虚拟地址开始(如0x400000)。操作系统通过页表将虚拟地址映射到任意的物理地址,程序无需关心实际加载到物理内存的哪里。
5.3 问题3:内存碎片和效率
如果使用物理地址,进程必须作为一个整体加载到连续的物理内存中:
bash
物理内存:
[进程A占用0-100MB] [进程B占用100-200MB] [进程C占用200-300MB]如果进程B退出,留下100MB空闲空间。这时来了一个需要150MB的进程D:
- 100MB的空间不够用
- 需要移动进程C,腾出连续的150MB空间
- 移动大量数据,效率极低
虚拟地址的解决方案:
通过分页机制,进程可以使用不连续的物理内存:
bash
进程D的虚拟地址空间(连续的):
[Page 0] [Page 1] [Page 2] ... [Page 37]...(150MB = 38400页)
映射到物理内存(不连续的):
Page 0 → 物理页 500
Page 1 → 物理页 100
Page 2 → 物理页 305
...
Page 37 → 物理页 888
...进程看到的是连续的虚拟地址,但实际使用的是分散的物理页面。
5.4 问题4:内存超额使用
物理内存有限(比如8GB),但如果:
- 进程A需要3GB
- 进程B需要3GB
- 进程C需要3GB
- 总共需要9GB > 8GB
没有虚拟内存时,只能运行其中两个进程。
虚拟地址的解决方案:
通过交换(Swap)机制:
- 将不常用的页面写入磁盘(交换区)
- 需要时再从磁盘读回内存
- 进程看到的虚拟地址空间没有变化
这样可以运行总内存需求超过物理内存的多个进程。
六、写时拷贝(Copy-On-Write)
现在我们可以解答第一篇文章留下的问题了:fork后父子进程的数据关系。
6.1 fork的代价
如果fork时立即拷贝父进程的所有数据:
cpp
父进程占用 500MB 内存
fork() → 立即拷贝 500MB → 子进程也占用 500MB
总共需要 1000MB这样做的问题:
- 拷贝大量数据很慢
- 浪费内存(子进程可能立即exec()执行新程序)
- 如果子进程只读数据,拷贝是不必要的
6.2 写时拷贝机制
Linux使用了一个聪明的技术:写时拷贝(Copy-On-Write, COW)。
fork时:
- 子进程获得父进程的页表副本
- 父子进程的虚拟地址都映射到相同的物理页面
- 将这些物理页面标记为只读
bash
fork前:
父进程虚拟地址 0x601040 → 物理页 1000
fork后:
父进程虚拟地址 0x601040 ──┐
├→ 物理页 1000 (只读)
子进程虚拟地址 0x601040 ──┘写入时:
当任何一方试图修改数据时:
- 触发缺页异常(Page Fault)
- 操作系统分配一个新的物理页
- 拷贝数据到新页面
- 更新页表,指向新页面
- 设置为可写
- 继续执行写操作
bash
子进程执行 g_val = 200:
1. 试图写入 0x601040
2. 触发缺页异常(页面是只读的)
3. 操作系统处理:
- 分配新物理页 2000
- 拷贝物理页 1000 的内容到 2000
- 更新子进程页表:0x601040 → 物理页 2000
- 设置为可写
4. 继续写入操作
结果:
父进程虚拟地址 0x601040 → 物理页 1000 (值=100)
子进程虚拟地址 0x601040 → 物理页 2000 (值=200)6.3 写时拷贝的优势
写时拷贝机制带来了巨大的性能优势:
1. fork速度快
- 不需要立即拷贝数据,只需拷贝页表
- 页表远小于实际数据
- fork几乎是瞬间完成的
2. 节省内存
- 如果父子进程只读取数据,共享同一份物理内存
- 只有真正修改时才分配新内存
- 如果子进程立即exec(),完全不需要拷贝
3. 延迟分配
- 按需分配,用到才拷贝
- 很多情况下子进程只访问部分数据
让我们用代码验证写时拷贝:
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int g_val = 100;
int main()
{
printf("fork前,父进程查看:\n");
printf(" 地址: %p, 值: %d\n", &g_val, g_val);
pid_t id = fork();
if(id == 0) {
// 子进程:先读后写
printf("\n子进程[%d]:\n", getpid());
printf(" 修改前 - 地址: %p, 值: %d\n", &g_val, g_val);
sleep(2); // 让父进程先输出
g_val = 200; // 触发写时拷贝
printf(" 修改后 - 地址: %p, 值: %d\n", &g_val, g_val);
}
else {
// 父进程:只读
printf("\n父进程[%d]:\n", getpid());
sleep(1);
printf(" 地址: %p, 值: %d\n", &g_val, g_val);
sleep(2); // 等子进程修改完
printf(" 子进程修改后,父进程的值: %d\n", g_val);
}
sleep(1);
return 0;
}运行结果示例:
bash
fork前,父进程查看:
地址: 0x601040, 值: 100
父进程[12700]:
地址: 0x601040, 值: 100
子进程[12701]:
修改前 - 地址: 0x601040, 值: 100
修改后 - 地址: 0x601040, 值: 200
子进程修改后,父进程的值: 100完美!虚拟地址相同(0x601040),但父子进程各有各的值。
七、深入理解虚拟地址空间
7.1 为什么每个进程的地址空间看起来一样
如果你观察多个进程,会发现它们的地址布局几乎相同:
- 代码段都在低地址(如0x400000)
- 栈都在高地址(如0x7fff...)
这不是巧合,而是编译器和操作系统协同的结果:
编译阶段:
- 编译器按照固定的规则分配虚拟地址
- 这些地址是"约定俗成"的布局
运行阶段:
- 操作系统负责将虚拟地址映射到实际的物理地址
- 不同进程的虚拟地址映射到不同的物理地址
这一阶段的内容在之后我们还会详细讲解
7.2 用户空间与内核空间
在32位Linux系统中,4GB虚拟地址空间被划分为:
bash
0xFFFFFFFF ┌─────────────┐
│ 内核空间 │ 1GB
│ (Kernel) │ 所有进程共享
0xC0000000 ├─────────────┤
│ │
│ 用户空间 │ 3GB
│ (User) │ 每个进程独立
│ │
0x00000000 └─────────────┘用户空间(0x00000000 - 0xBFFFFFFF):
- 每个进程独立
- 存放进程自己的代码、数据、堆、栈
内核空间(0xC0000000 - 0xFFFFFFFF):
- 所有进程共享
- 存放内核代码和数据
- 普通程序不能直接访问(需要系统调用)
7.3 为什么需要内核空间
当进程进行系统调用时:
cpp
int fd = open("test.txt", O_RDONLY);这个过程需要:
- 从用户态切换到内核态
- 执行内核代码
- 访问内核数据结构
- 返回用户态
如果内核没有映射到进程的地址空间,切换会很麻烦。通过共享内核空间,切换只需改变权限标志位,不需要切换页表。
八、虚拟内存管理的完整图景
让我们把所有概念串联起来,画一个完整的图景。
8.1 从虚拟地址到物理地址的完整流程
bash
1. 程序访问变量
int x = g_val; // 虚拟地址 0x601040
2. CPU的MMU(内存管理单元)介入
- 分解虚拟地址:页号 + 页内偏移
- 虚拟页号 = 0x601040 / 4096 = 0x601
- 页内偏移 = 0x601040 % 4096 = 0x040
3. 查询页表
- 根据虚拟页号0x601查页表
- 得到物理页号,如0xABC
4. 计算物理地址
- 物理地址 = 0xABC * 4096 + 0x040
- 物理地址 = 0xABC040
5. 访问物理内存
- CPU访问物理地址0xABC040
- 读取数据8.2 多级页表
对于32位系统,如果使用单级页表:
- 虚拟地址空间:4GB
- 页大小:4KB
- 页表项数量:4GB / 4KB = 1M(100万多)
- 每个页表项:4字节
- 页表大小:4MB
每个进程都需要4MB的页表,太浪费了!
解决方案:多级页表
Linux使用四级页表(在x86-64上):
bash
虚拟地址64位
┌────────────┬────────┬────────┬────────┬──────────┐
│ 未使用 │ PGD索引│ PUD索引│ PMD索引│ PTE索引 │ 页内偏移
│ 16位 │ 9位 │ 9位 │ 9位 │ 9位 │ 12位
└────────────┴────────┴────────┴────────┴──────────┘
│ │ │ │
▼ ▼ ▼ ▼
PGD表 → PUD表 → PMD表 → PTE表 → 物理页这样,只有实际使用的部分才需要分配页表,大大节省了内存。
8.3 TLB:页表缓存
每次访问内存都要查4次页表,太慢了!
CPU使用TLB(Translation Lookaside Buffer)缓存最近使用的页表项:
bash
1. CPU访问虚拟地址
↓
2. 先查TLB
- 命中 → 直接得到物理地址(快!)
- 未命中 → 查页表(慢)
↓
3. 访问物理内存TLB命中率通常在95%以上,所以实际性能很好。
这部分内容在之后还会详细讲解。
九、实际应用:查看进程地址空间
9.1 通过/proc查看
Linux提供了/proc/[pid]/maps文件,可以查看进程的虚拟地址空间布局:
cpp
#include <stdio.h>
#include <unistd.h>
int g_val = 100;
int main()
{
printf("我的PID: %d\n", getpid());
printf("请执行: cat /proc/%d/maps\n", getpid());
sleep(30); // 等待30秒,方便查看
return 0;
}运行后,在另一个终端执行:
bash
cat /proc/实际进程PID/maps输出:
bash
00400000-00401000 r-xp 00000000 08:01 123456 /home/user/a.out # 代码段
00600000-00601000 r--p 00000000 08:01 123456 /home/user/a.out # 只读数据
00601000-00602000 rw-p 00001000 08:01 123456 /home/user/a.out # 读写数据
01a51000-01a72000 rw-p 00000000 00:00 0 [heap] # 堆
7f8e4c000000-7f8e4c021000 rw-p 00000000 00:00 0 # 共享库
...
7ffd0f985000-7ffd0f9a6000 rw-p 00000000 00:00 0 [stack] # 栈每一行格式:
bash
地址范围 权限 偏移 设备 inode 路径/说明权限:
r: 可读w: 可写x: 可执行p: 私有(写时拷贝)s: 共享
9.2 内存使用统计
查看进程的内存使用:
bash
cat /proc/12800/status | grep -i vm输出:
bash
VmSize: 4212 kB # 虚拟内存大小
VmRSS: 352 kB # 实际物理内存使用(常驻集)
VmData: 140 kB # 数据段
VmStk: 132 kB # 栈
VmExe: 4 kB # 代码段注意:VmSize可能很大,但VmRSS才是真正占用的物理内存。
十、总结与思考
通过本篇文章,我们深入学习了虚拟内存的核心概念:
- 虚拟地址空间的本质:是操作系统提供的抽象,每个进程都有独立的虚拟地址空间
- 页表机制:通过多级页表实现虚拟地址到物理地址的映射
- 进程隔离:不同进程的虚拟地址映射到不同的物理地址,互不干扰
- 写时拷贝:fork时不立即拷贝数据,只有写入时才拷贝,提高效率
- 内存管理结构:mm_struct和vm_area_struct描述和管理进程地址空间
虚拟内存是操作系统最伟大的设计之一,它:
- 让每个进程拥有独立的地址空间,互不干扰
- 提供了内存保护机制,增强安全性
- 支持内存超额使用,提高资源利用率
- 简化了程序开发,程序不需要关心物理内存布局
至此,我们完成了Linux进程概念的系统学习。从冯诺依曼体系到进程创建,从进程状态到调度算法,从环境变量到虚拟内存,你已经掌握了操作系统最核心的知识!
💡 思考题:
- 如果两个进程都访问虚拟地址0x601040,它们访问的是同一个物理地址吗?
- 为什么fork后立即exec()不会浪费内存?
- 如果物理内存只有4GB,能否运行10个各占用2GB虚拟内存的进程?
- 写时拷贝机制下,如果父子进程都不写数据,它们会共享物理内存吗?
- 为什么栈要从高地址向低地址增长?
💪 后续学习:
- 进程控制(wait/waitpid详解)
- 进程间通信(管道、共享内存、消息队列)
- 信号机制
- 线程与多线程编程
- 网络编程
恭喜你完成了Linux进程概念的学习!这些知识将是你深入系统编程和网络编程的坚实基础!