目录
[1. 语言结构的差异:从分词到词形变化](#1. 语言结构的差异:从分词到词形变化)
[2. 低资源语言的生存困境](#2. 低资源语言的生存困境)
[3. 字符编码的兼容性问题](#3. 字符编码的兼容性问题)
[1. 从语音到文本:语音识别(ASR)](#1. 从语音到文本:语音识别(ASR))
[2. 理解的核心:自然语言理解(NLU)](#2. 理解的核心:自然语言理解(NLU))
[3. 对话的决策者:对话管理](#3. 对话的决策者:对话管理)
[4. 从结构化到自然语言:自然语言生成(NLG)](#4. 从结构化到自然语言:自然语言生成(NLG))
[5. 从文本到语音:文本到语音转换(TTS)](#5. 从文本到语音:文本到语音转换(TTS))
[1. 通用语音助手:生活中的 "全能助手"](#1. 通用语音助手:生活中的 “全能助手”)
[2. 企业助手:垂直领域的专业服务](#2. 企业助手:垂直领域的专业服务)
[3. 翻译:打破语言壁垒的桥梁](#3. 翻译:打破语言壁垒的桥梁)
[4. 教育:个性化的学习伙伴](#4. 教育:个性化的学习伙伴)
[1. 分类:文本的 "标签化" 处理](#1. 分类:文本的 “标签化” 处理)
[2. 安全类应用:抵御文本欺诈](#2. 安全类应用:抵御文本欺诈)
[3. 信息检索与抽取:从文本中 "找信息"](#3. 信息检索与抽取:从文本中 “找信息”)
[4. 机器翻译:跨越语言的文本沟通](#4. 机器翻译:跨越语言的文本沟通)
[5. 其他应用:文本价值的多元释放](#5. 其他应用:文本价值的多元释放)
[六、Python:NLU 开发的 "利器"](#六、Python:NLU 开发的 “利器”)
[示例 1:包含【人名 + 地点 + 组织 + 日期 + 产品】](#示例 1:包含【人名 + 地点 + 组织 + 日期 + 产品】)
[示例 2:包含【机构 + 地点 + 事件 + 日期】](#示例 2:包含【机构 + 地点 + 事件 + 日期】)
[示例 3:包含【电影名 + 演员 + 上映时间 + 城市】](#示例 3:包含【电影名 + 演员 + 上映时间 + 城市】)
[示例 4:贴近原文场景(体育赛事)](#示例 4:贴近原文场景(体育赛事))
[七、NLU 的未来:从 "理解" 到 "共情"](#七、NLU 的未来:从 “理解” 到 “共情”)
一、引言
在人工智能深度渗透日常生活的今天,当我们对着手机说出 "明天的天气预报",当电商平台自动识别用户评论中的 "差评",当跨国会议的实时翻译流畅衔接不同语言 ------ 这些场景的背后,都离不开 ** 自然语言理解(Natural Language Understanding, NLU)** 技术的支撑。尽管目前尚无技术能复刻人类对语言的复杂感知与深度解读,但 NLU 已成为连接人类与机器、解锁文本价值的核心工具。从口语对话到文档分析,从通用助手到企业服务,NLU 的应用早已渗透到信息社会的每一个角落。
二、自然语言理解的基础:语言的复杂性与技术挑战
自然语言是人类沟通的核心载体,分为口语 与书面语两类:口语存在于日常对话、广播、播客中,具有即时性、随意性的特点;书面语则涵盖网络文本、书籍、邮件,甚至数据库的文本字段(这类文本常因格式限制无法被搜索引擎抓取)。这些语言形式共同构成了 NLU 技术的处理对象,但语言本身的 "多样性",却给技术落地带来了诸多挑战。
1. 语言结构的差异:从分词到词形变化
不同语言的结构特性,是 NLU 工具首先要跨越的门槛。
- 中文的 "分词困境":与英语等西方语言用空格分隔单词不同,中文书面语中词与词之间没有天然边界 ------"下雨天留客天留我不留" 既可以解读为 "下雨天,留客天,留我不?留!",也可以是 "下雨天留客,天留我不留"。这种歧义性意味着中文 NLU 必须先完成 "分词" 预处理(如借助 Jieba、spaCy 等工具),才能让机器识别基本语义单元。
- 屈折语的词形变形:英语的动词变形相对简单(如 "walk" 的过去式仅为 "walked"),但西班牙语、法语等屈折语的词形变化极为复杂 ------ 以西班牙语动词 "caminar(行走)" 为例,仅现在时就有 "Yo camino(我走)""Tú caminas(你走)""Él camina(他走)" 等 6 种变形,过去时、完成时又有不同形态。这些变形包含了人称、时态等语法信息,NLU 需通过 "词形还原" 预处理,才能将不同形式的单词映射到同一词根,准确计算词频或理解语义。
2. 低资源语言的生存困境
世界上存在成千上万种语言,但 NLU 工具的支持度高度集中于 "高资源语言"(如英语、中文、西班牙语)------ 这些语言有充足的语料库、商业开发动力,工具链成熟。而使用人数不足 1000 万的 "低资源语言"(如非洲的豪萨语、南太平洋的毛利语),往往既无现成的处理工具,也缺乏训练模型的语料数据。部分低资源语言甚至濒临灭绝,仅靠少数人群传承,为其开发 NLU 技术不仅成本高昂,更需要结合语言学研究与迁移学习(从高资源语言模型迁移知识),才能实现基础的文本处理。
3. 字符编码的兼容性问题
汉语、俄语、阿拉伯语等语言不使用罗马字符,对应的字符编码(如中文的 UTF-8、俄语的 KOI8-R)是机器识别这些语言的前提。若文本处理工具不支持目标编码,就会出现 "乱码"------ 比如将 "你好" 显示为 "????"。因此,NLU 工具必须具备多编码兼容能力,开发者也需在处理非罗马字符语言时,明确指定编码格式。
三、对话式人工智能:人机交互的核心模块
当我们与 Siri 聊天、向智能音箱下达指令时,背后是对话式人工智能系统的协同工作。这个系统由 5 个核心模块构成,NLU 是其中的 "理解中枢"。
1. 从语音到文本:语音识别(ASR)
对话的起点是 "语音识别(Automatic Speech Recognition, ASR)"------ 它将用户的语音音频转换为文本。比如用户说 "打开客厅的灯",ASR 会先捕捉音频信号,通过声学模型与语言模型,将其转换为对应的文字。ASR 的准确率直接影响后续流程:若将 "灯" 识别为 "登",后续的 NLU 就会无法理解用户意图。
2. 理解的核心:自然语言理解(NLU)
ASR 输出的文本,需经过 NLU 转换为机器可处理的结构化表示------ 核心是 "意图识别" 与 "实体提取"。
- 意图识别:判断用户的核心目标,比如 "我想订一张从北京到上海的机票" 的意图是 "预订机票"。
- 实体提取:提取实现意图所需的关键信息(称为 "槽位"),比如上述句子中的 "出发地(北京)""目的地(上海)"。若实体缺失(如用户没说 "出行日期"),NLU 会触发 "槽填充",让系统询问 "请问你要订哪一天的机票?"。
3. 对话的决策者:对话管理
NLU 输出的意图与实体,由 "对话管理" 模块决定系统的反应:是直接执行操作(如 "打开灯"),还是询问补充信息(如槽填充),或是提供信息(如 "北京明天的天气是晴天")。在多轮对话中,对话管理还需 "记忆" 用户的历史输入 ------ 比如用户先问 "附近的咖啡店",再问 "哪家有优惠",系统需理解 "哪家" 指代的是之前提到的咖啡店。
4. 从结构化到自然语言:自然语言生成(NLG)
对话管理的决策,需要通过 "自然语言生成(Natural Language Generation, NLG)" 转换为人类易懂的文本。比如系统需要回复 "北京明天的天气是晴天,气温 15-22℃",NLG 会将 "天气:晴天;气温:15-22℃" 的结构化数据,组织成流畅的自然语句。
5. 从文本到语音:文本到语音转换(TTS)
若用户需要语音回复,NLG 生成的文本会通过 "文本到语音转换(Text-to-Speech, TTS)" 模块,转换为自然的语音音频 ------ 比如 Siri 用女声播报天气,就是 TTS 的输出结果。
这 5 个模块形成了完整的人机对话流程:用户语音→ASR→文本→NLU→意图 / 实体→对话管理→决策→NLG→文本→TTS→系统语音→用户。
四、交互式应用:实时人机对话的落地场景
交互式应用是 NLU 最贴近用户的场景 ------ 用户与系统实时交流,要求响应快速、输入简洁。这类应用主要包括通用语音助手、企业助手、翻译工具与教育应用。
1. 通用语音助手:生活中的 "全能助手"
亚马逊 Alexa、苹果 Siri、谷歌 Assistant 是通用语音助手的代表。它们的核心特点是 "知识广博但缺乏深度":
- 能快速响应 "播放周杰伦的歌""设置早上 7 点的闹钟" 等简单指令,识别 "获取 < 北京 > 的天气预报" 这类意图 + 实体的组合;
- 但无法处理复杂对话 ------ 比如用户问 "量子力学的哥本哈根诠释是什么",助手只能给出简短概述,无法展开学术讨论;
- 多数通用助手是 "封闭私有系统",开发者难以扩展功能(如添加方言支持),开源替代方案 Mycroft 则允许用户自定义底层功能。
2. 企业助手:垂直领域的专业服务
与通用助手不同,企业助手聚焦特定组织的需求,连接企业数据库提供专业服务:
- 银行助手:用户询问 "我的银行卡余额是多少",助手通过 NLU 识别意图后,调用银行的用户数据接口,返回余额信息;
- 电商客服助手:自动处理 "我的订单什么时候发货""商品质量有问题怎么办" 等常见问题,减轻人工客服压力;
- 开发工具:RASA(开源)、Microsoft LUIS 等工具允许企业上传意图 / 实体样本,快速搭建自定义助手 ------ 比如零售企业可以训练助手识别 "查询商品库存" 的意图,提取 "商品名称" 实体。
基于文本的聊天机器人是企业助手的常见形式,比如电商网站的 "在线客服" 弹窗:用户输入文本问题,机器人通过 NLU 理解后,返回预设的回复或引导人工客服。
3. 翻译:打破语言壁垒的桥梁
交互式翻译是 NLU 的经典应用之一,它让不同语言的用户实时交流:
- 口语翻译:用户说出 "我想去火车站",ASR 转换为文本后,NLU 理解意图,再通过机器翻译转换为目标语言(如英语 "I want to go to the train station"),最后 TTS 播报给对方;
- 挑战:口语输入的 "口音" 会降低 ASR 准确率(比如将 "火车站" 识别为 "火电站"),复杂话题(如商务谈判的专业术语)则容易出现翻译偏差 ------ 这也是当前翻译工具在正式场合仍需人工校对的原因。
4. 教育:个性化的学习伙伴
NLU 为教育带来了 "个性化交互" 的可能:
- 语言学习:学生用目标语言(如法语)与应用对话,"我明天要去巴黎旅游",NLU 会判断语法是否正确、意图是否清晰,并给出纠正建议;
- 优势:机器不会让学生感到 "尴尬",学生可以反复练习口语,助手也能根据学习进度调整难度;
- 其他场景:自动批改作文(通过 NLU 分析语法错误、内容连贯性)、单词听写(识别学生的口语回答是否正确)等。
五、非交互式应用:文本价值的深度挖掘
非交互式应用无需实时用户交互,聚焦单个 / 一组文档的处理,可分析任意长度的文本,是企业与机构挖掘文本价值的核心工具。
1. 分类:文本的 "标签化" 处理
分类是是非交互式应用的核心 ------ 将文本按内容分配到预设类别:
- FAQ 分类:将用户的问题(如 "怎么修改密码")分类到对应的问题类型,再匹配预设的回答,常见于企业官网的 "常见问题" 板块;
- 情感分析:判断文本的情感倾向(正面 / 负面 / 中性),比如电商平台分析用户评论 "这个手机拍照很好,但续航有点差"------ 尽管包含负面词汇,整体倾向仍是 "正面",这种 "矛盾文本" 是情感分析的难点,需要 NLU 理解上下文的权重。
2. 安全类应用:抵御文本欺诈
文本是欺诈的常见载体,NLU 为安全防护提供了技术支持:
- 垃圾邮件检测:识别 "免费领取礼品""快速赚大钱" 等垃圾邮件,垃圾邮件发送者常通过 "故意拼错单词"(如 "fr33" 替代 "free")规避关键词过滤,NLU 则通过语义分析判断内容是否为垃圾信息;
- 网络钓鱼检测:识别伪装成合法机构(如银行、电商)的邮件,这类邮件通常包含 "点击链接修改密码" 的诱导内容,NLU 会分析邮件的发件人可信度、链接合法性,及时预警风险;
- 虚假新闻检测:识别 "看似真实但信息不实" 的文本(如 "某明星突发心脏病去世"),NLU 会交叉验证信息来源、分析内容的逻辑一致性,帮助平台过滤谣言。
3. 信息检索与抽取:从文本中 "找信息"
- 文档检索:根据用户查询找到匹配的文档,传统关键词检索易受歧义影响(如 "glasses" 既指 "眼镜" 也指 "酒杯"),NLU 则通过理解上下文("我需要买一副 glasses"→眼镜),提高检索准确性;
- 信息抽取:从文本中提取结构化信息,核心技术是 "命名实体识别(NER)"------ 比如从新闻 "2025 年 12 月 15 日,中国队在卡塔尔世界杯预选赛中以 2-1 战胜韩国队" 中,抽取 "时间(2025-12-15)""组织(中国队、韩国队)""赛事(世界杯预选赛)""结果(2-1 胜)",并填充到数据库中。
4. 机器翻译:跨越语言的文本沟通
非交互式翻译聚焦书面文本(如文档、书籍),是全球化时代的必备工具:
- 发展:谷歌翻译、必应翻译等工具已能支持约 109 种语言,但小语种(如冰岛语)的翻译质量仍较差 ------ 这类语言缺乏足够的 "平行语料库"(两种语言的对照文本),目前的解决方案是 "迁移学习":从高资源语言(如英语)的模型中迁移知识,提升小语种翻译的准确性;
- 挑战:专业领域的文本(如医学论文、法律合同)包含大量术语,机器翻译容易出现偏差,通常需要 "领域适配"(用专业语料微调模型)。
5. 其他应用:文本价值的多元释放
NLU 还支撑着更多细分场景:
- 文本摘要:自动生成长文本的摘要(如新闻摘要、论文摘要),帮助用户快速了解核心内容;
- 作者身份识别:通过 NLU 分析文本的用词习惯、语法特点,判断作者的身份(常用于学术查重、文学作品考证);
- 社交媒体分析:从微博、推特的帖子中提取热门话题、分析用户情感,帮助企业了解市场舆情。
六、Python:NLU 开发的 "利器"
传统 NLP 开发依赖 Lisp、Prolog 等专业语言,而Python已成为当前 NLU 领域的主流工具 ------ 原因在于其 "开发效率高""库生态丰富":
- NLTK:自然语言处理工具包,提供分词、词性标注、词形还原等基础功能,适合入门学习;
- spaCy:工业级 NLU 库,速度比 NLTK 更快,支持高效分词、命名实体识别、依存句法分析;
- scikit-learn:机器学习库,可用于搭建情感分类、文本分类等模型;
- Keras/TensorFlow:深度学习框架,用于构建神经网络模型(如 LSTM、Transformer),实现机器翻译、文本生成等复杂任务。
下面将展示spaCy中文命名实体识别(NER)对不同类型实体(人名、地名、组织、日期、作品名等)的识别效果,同时标注各实体标签的含义(zh_core_web_sm的核心实体标签:DATE= 日期、PERSON= 人名、GPE= 地理实体 / 地点、ORG= 组织、WORK_OF_ART= 作品名、EVENT= 事件、PRODUCT= 产品)。
首先安装中文模型"zh_core_web_sm",方法如下:
- 打开「Anaconda Prompt」(或 PyCharm 的终端、系统 cmd);
- 输入以下命令并回车,自动下载安装中文小模型:
bash
python -m spacy download zh_core_web_sm安装时间可能比较长,出现如图所示,代表安装成功。
示例 1:包含【人名 + 地点 + 组织 + 日期 + 产品】
python
import spacy
# 加载中文小模型
nlp = spacy.load("zh_core_web_sm")
# 替换后的文本:包含马云(人名)、杭州(地点)、阿里巴巴(组织)、日期、阿里云服务器(产品)
text = "2024年6月18日,马云在杭州阿里巴巴总部发布了新款阿里云服务器"
doc = nlp(text)
# 遍历识别到的实体并打印
for ent in doc.ents:
print(f"实体内容:{ent.text} | 实体类型:{ent.label_}")程序运行截图展示:

示例 2:包含【机构 + 地点 + 事件 + 日期】
python
import spacy
nlp = spacy.load("zh_core_web_sm")
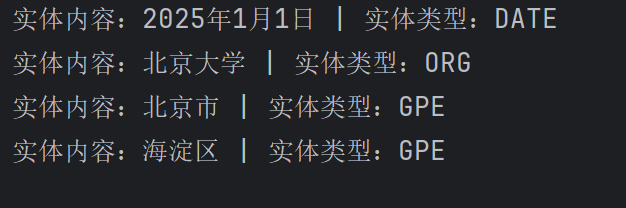
# 替换后的文本:北京大学(组织)、北京市海淀区(地点)、人工智能学术研讨会(事件)、日期
text = "2025年1月1日,北京大学在北京市海淀区举办了人工智能学术研讨会"
doc = nlp(text)
for ent in doc.ents:
print(f"实体内容:{ent.text} | 实体类型:{ent.label_}")程序运行截图展示:
示例 3:包含【电影名 + 演员 + 上映时间 + 城市】
python
import spacy
nlp = spacy.load("zh_core_web_sm")
# 替换后的文本:吴京(人名)、《流浪地球2》(作品名)、上海(地点)、日期
text = "2023年7月20日,吴京主演的电影《流浪地球2》在上海首映"
doc = nlp(text)
for ent in doc.ents:
print(f"实体内容:{ent.text} | 实体类型:{ent.label_}")程序运行截图展示:

示例 4:贴近原文场景(体育赛事)
python
import spacy
nlp = spacy.load("zh_core_web_sm")
# 替换后的文本:世界杯决赛(事件)、阿根廷队/法国队(组织)、卡塔尔卢塞尔体育场(地点)、日期
text = "2022年12月18日,阿根廷队在卡塔尔卢塞尔体育场击败法国队夺得世界杯决赛冠军"
doc = nlp(text)
for ent in doc.ents:
print(f"实体内容:{ent.text} | 实体类型:{ent.label_}")程序运行截图展示:

七、NLU 的未来:从 "理解" 到 "共情"
当前的 NLU 技术已能完成 "识别意图""提取信息" 等基础任务,但距离人类的 "深度理解" 仍有差距 ------ 比如无法完全感知文本中的 "隐喻""讽刺",难以处理复杂的逻辑推理。未来的 NLU 将向两个方向发展:
- 低资源语言的突破:通过迁移学习、多语言模型,让更多小语种获得 NLU 支持,保护语言多样性;
- 情感与逻辑的深化:让机器不仅 "理解字面意思",更能感知文本的情感倾向、理解复杂的逻辑关系,实现更自然的人机对话、更精准的文本分析。
从口语对话到文档挖掘,从通用服务到垂直领域,NLU 已成为信息时代的 "基础设施"。它不仅改变了人机交互的方式,更让海量文本的价值得到释放 ------ 而这,仅仅是自然语言理解的开始。
八、总结
自然语言理解(NLU)技术已成为连接人类与机器的核心工具,广泛应用于语音助手、企业服务、翻译工具和教育应用等领域。文章分析了NLU面临的语言多样性挑战,包括中文分词困境、屈折语词形变化、低资源语言支持等问题。同时详细介绍了对话式人工智能的五大模块(ASR、NLU、对话管理、NLG、TTS)及其协同工作流程。文章还探讨了Python在NLU开发中的优势,并展示了spaCy库的中文实体识别示例。未来NLU将向低资源语言支持和情感逻辑深化方向发展,推动人机交互迈向更高水平。