AI视频技术原理与架构
-
- 一、AI视频生成的核心逻辑与完整流程
-
- [1. 核心定义:什么是AI视频生成模型?](#1. 核心定义:什么是AI视频生成模型?)
- [2. 完整流程:从数据到视频的四步走](#2. 完整流程:从数据到视频的四步走)
- 二、技术范式演进:从早期探索到主流架构
-
- [1. 四大基础技术范式对比](#1. 四大基础技术范式对比)
- [2. 范式演进时间线](#2. 范式演进时间线)
- [3. 主流架构:扩散模型的两大路线](#3. 主流架构:扩散模型的两大路线)
- 三、关键技术组件:解码视频生成的核心机制
-
- [1. 像素空间与潜空间:降维与提效的核心](#1. 像素空间与潜空间:降维与提效的核心)
- [2. 时空压缩:高效处理的基础](#2. 时空压缩:高效处理的基础)
- [3. 时空补丁:统一格式与降低复杂度](#3. 时空补丁:统一格式与降低复杂度)
- [4. CLIP:文本与视觉的"翻译官"](#4. CLIP:文本与视觉的"翻译官")
- [5. 典型模型架构示例(以Sora为例)](#5. 典型模型架构示例(以Sora为例))
- 四、训练数据:AI视频生成的"燃料"
-
- [1. 数据的三大核心影响因素](#1. 数据的三大核心影响因素)
- [2. 主流数据集分类](#2. 主流数据集分类)
- 五、核心要点总结
AI视频技术正以数据驱动、模型赋能的方式重塑视觉内容创作,其背后是复杂的技术范式演进、精密的架构设计与高质量数据支撑。本文将基于北京大学相关研究内容,系统拆解AI视频生成的核心逻辑、技术架构、关键组件及训练数据核心要素,带大家全面理解这项革命性技术。
一、AI视频生成的核心逻辑与完整流程
AI视频生成并非简单的图像拼接,而是一个由数据、模型、算法共同驱动的系统工程,完整生命周期包含四个核心环节,本质是实现从"现实数据"到"视觉内容"的智能转换。
1. 核心定义:什么是AI视频生成模型?
AI视频模型是基于数据和算法构建的计算机程序,通过在海量数据集上"学习"而非人工编程,掌握识别数据模式、生成新内容的能力。与传统程序相比,它具有显著不同的特性:
| 特性 | 传统程序 | AI模型 |
|---|---|---|
| 逻辑来源 | 由人明确编写的固定规则 | 从数据中自动学习到的模式和概率 |
| 处理方式 | 基于确定的指令执行 | 基于学习到的规律动态生成 |
| 面对新情况 | 只能处理预设范围内的情况 | 具备对未知数据的泛化和推断能力 |
| 核心构成 | 硬编码的逻辑和算法 | 算法与数据的结合体,数据是核心原料 |
其核心功能是"输入到输出"的映射:接收提示词、参考图、参考视频等生成条件,输出文本、图像、视频、音频等多样化内容,视频生成模型是其中聚焦动态视觉内容的重要分支,代表性产品包括Gen-3、Sora、Stable Video Diffusion等。
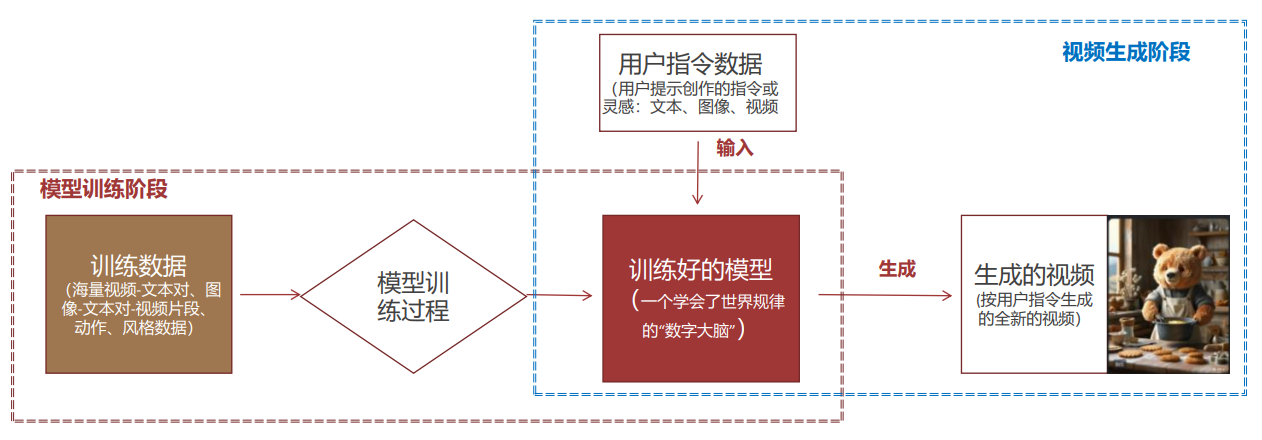
2. 完整流程:从数据到视频的四步走
- 数据收集:获取文本、图像、视频片段等原始数据,构建规模庞大、内容多样、反映真实物理规律的数据集,为模型训练提供"原料"。
- 数据预处理:将原始数据转化为模型可理解的数学语言,包括去重、过滤低质量内容的清洗步骤,统一分辨率和帧率的标准化步骤,以及核心的数据编码过程。
- 模型训练:通过深度学习算法,让模型在预处理后的数据集上学习视觉规律、时空关系和物理逻辑,形成具备生成能力的"数字大脑"。
- 视频生成:根据用户输入的指令,模型通过多次循环去噪,逐步生成清晰、连贯的视频画面,完成从"混沌"噪声到"有序"内容的创造。
二、技术范式演进:从早期探索到主流架构
AI视频生成的技术范式经历了多轮迭代,从简单的图像拼接逐步发展为基于复杂模型的智能生成,每一次范式升级都带来生成质量和能力的飞跃。
1. 四大基础技术范式对比
早期AI视频生成依托多种基础技术范式,各有优劣和适用场景:
| 对比项目 | 变分自编码器 (VAE) | 生成对抗网络 (GAN) | 自回归模型 (Autoregressive) | 扩散模型 (Diffusion) |
|---|---|---|---|---|
| 基本概念 | 通过编码器映射到潜在空间,解码器重构数据,优化重构误差和潜在空间分布 | 生成器与判别器对抗学习,通过博弈训练生成逼真样本 | 按顺序生成数据,每次生成依赖之前内容 | 逐步添加噪声再学习反向去噪,恢复数据分布 |
| 优点 | 有明确潜在表示、训练稳定、可用于特征学习、生成速度快 | 生成质量高、生成速度快、适合图像生成 | 生成过程可控、概率模型清晰、适合序列数据 | 训练稳定、多样性好、可控性强 |
| 缺点 | 生成质量较低、存在模糊问题、重构与KL散度平衡困难 | 训练不稳定、模式崩溃、难以评估 | 生成速度较慢、错误可能累积、长序列困难 | 采样速度慢、计算资源消耗大、理论复杂 |
| 典型模型 | β-VAE、VQ-VAE、NVAE | DCGAN、StyleGAN、CycleGAN | GPT系列、PixelCNN、WaveNet | DDPM、Stable Diffusion、DALL-E 2/3 |
| 应用场景 | 图像生成、特征学习、异常检测、数据压缩 | 图像生成、图像增强、风格转换、艺术创作 | 自然语言生成、代码补全、音乐创作、视频预测 | 图像生成、超分辨率重建、图像编辑、3D模型生成 |
2. 范式演进时间线
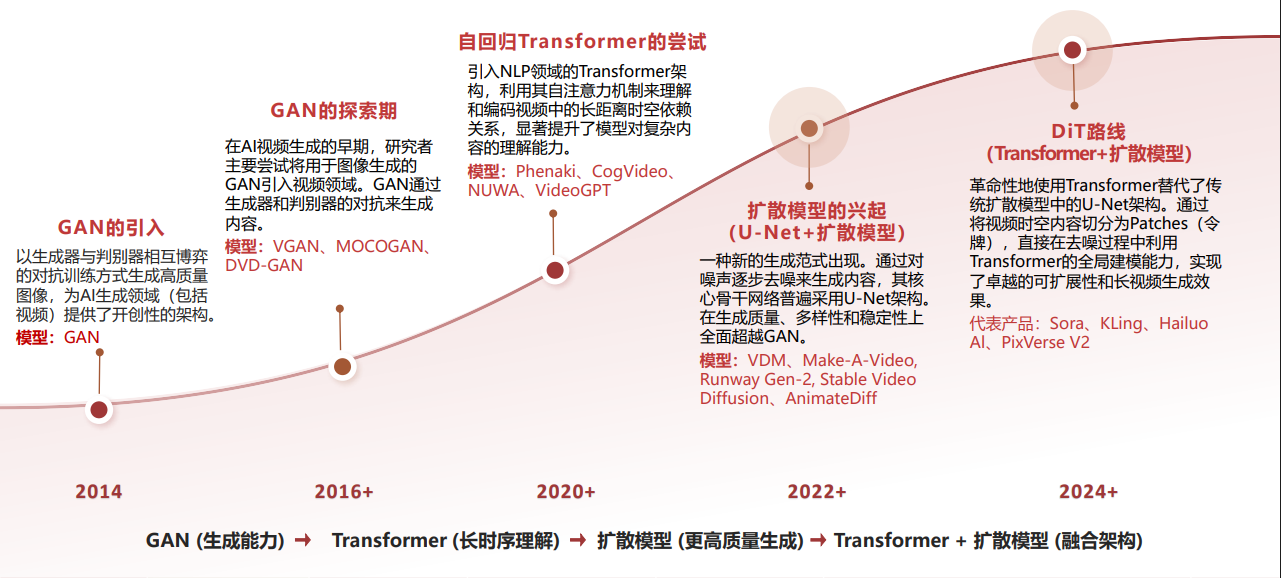
3. 主流架构:扩散模型的两大路线
扩散模型之所以成为当前主流,核心源于三大原理性优势:训练稳定(缓解GAN的收敛难题)、多样性强(超越GAN和自回归模型)、可控性高(通过无分类器引导实现精准文本控制)。其架构主要分为两条路线:
| 架构路线 | 核心特点 | 代表模型 | 优劣势 |
|---|---|---|---|
| U-Net架构 | 基于SD逐帧生成 | Pika、Gen-2、Stable Video Diffusion、MagicVideo-V2 | 模型容易训练,但视频内容一致性较差,长视频生成困难 |
| 混合架构(U-Net+Transformer) | 融合两者优势,基于时空Patches生成 | Sora、清影、Pixverse V2、可灵、Google Lumiere | 训练成本较高,但能更好保证视频长度和一致性 |
其中,Transformer架构堪称生成技术的"游戏改变者",其核心的自注意力机制赋予模型三大关键能力:
- 时间一致性:确保物体在视频中不"画风突变",解决GAN的"闪烁"问题;
- 动态关系理解:能捕捉"A导致B"的逻辑,如"人跑过水坑→水花溅起";
- 高可扩展性:可灵活处理长短视频、宽屏竖屏等不同格式内容。
三、关键技术组件:解码视频生成的核心机制
AI视频生成的高质量输出,依赖于多个关键技术组件的协同工作,每个组件都承担着不可或缺的角色。
1. 像素空间与潜空间:降维与提效的核心
- 像素空间:直接感知的原始数据域,由像素颜色值(如RGB)构成,特点是高维度、冗余度高、计算成本高,且缺乏语义意义(如像素平均仅得模糊图像)。
- 潜空间:通过模型学习到的低维抽象表示空间,不存储像素信息,而是捕捉数据的高层语义特征,特点是维度低、信息密度高、计算高效,且支持有意义的数学操作(如"男人"向量到"女人"向量的平滑过渡)。
将视频生成从像素空间转移到潜空间,是实现计算效率和生成质量突破的关键,让模型能更深刻地理解物理世界的动态规律。
2. 时空压缩:高效处理的基础
时空压缩是将冗余的像素空间转换为高效潜空间的过程,核心依赖包含编码器和解码器的视觉压缩网络(常用VAE模型):
- 编码器:将高维度复杂视频数据压缩为低维度、含核心信息的潜向量;
- 解码器:将潜向量还原为高维度的原始像素画面。
在Sora等模型中,训练前会先通过编码器压缩所有视频数据,后续模型仅处理高效潜向量,大幅提升计算效率;生成阶段则通过解码器将潜向量"翻译"为可见视频帧。
3. 时空补丁:统一格式与降低复杂度
时空补丁(Spacetime Patch)是将视频在空间(宽高)和时间维度同时切块得到的"小方块视频",类似从一叠胶片中挖出的小块。其核心价值在于:
- 统一数据格式:无论是长短视频、宽屏竖屏,还是单张图片(视为单帧视频),都能转化为标准化Patches,增强模型泛化能力;
- 降低计算复杂度:将视频拆解为Patches后,可充分发挥Transformer的优势,像分析文本单词一样高效处理视觉内容。
4. CLIP:文本与视觉的"翻译官"
CLIP(对比语言-图像预训练模型)是连接文本与视觉的关键,通过海量"图片-文字描述"训练,能将内容相似的图文映射到相近的表示空间。在视频生成中,它承担两大核心作用:
- 文本编码:将用户输入的文字描述(如"穿宇航服的猫在火星行走")转换为数学向量;
- 生成指导:将文本向量作为条件输入模型,在每一步去噪过程中引导生成内容与文本描述高度一致。
5. 典型模型架构示例(以Sora为例)
Sora的架构集中体现了上述组件的协同工作流程:
- 训练数据预处理:原始高分辨率视频经VAE编码器压缩为低维潜表示,再切分为时空Patches;
- 条件信息处理:用户输入的文本、图像或视频,经DALL·E 3转化为详细文字描述,再由CLIP编码为条件向量;
- 核心生成过程:DiT(Diffusion+Transformer)从随机噪声开始,在条件向量引导下多次迭代去噪,生成连贯潜向量序列;
- 最终视频输出:线性解码器恢复Patches的原始时空结构,VAE解码器将潜向量解码为高分辨率像素画面,拼接成完整视频。
四、训练数据:AI视频生成的"燃料"
随着模型架构逐渐趋同,训练数据成为决定生成效果上限的核心变量,其规模、质量和多样性直接影响模型的泛化能力与生成质量。
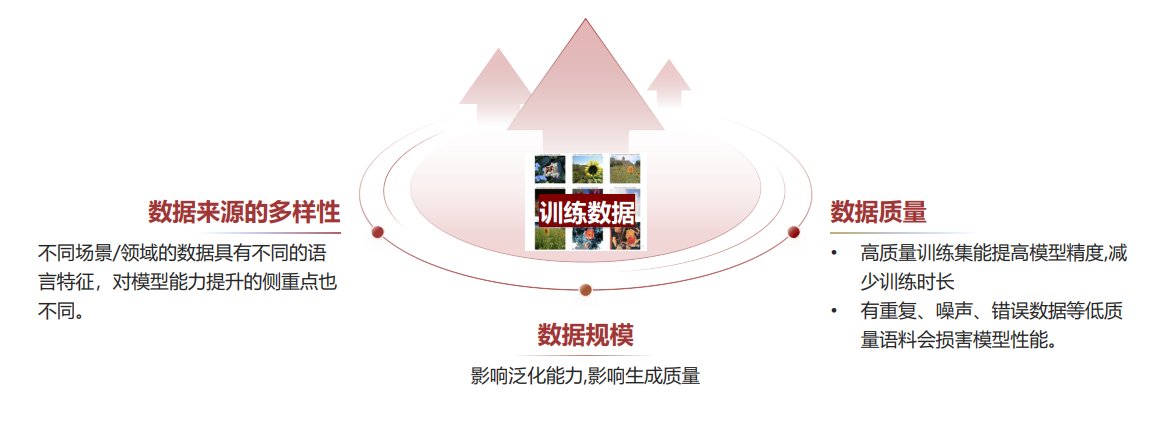
1. 数据的三大核心影响因素
- 规模:足够大的数据集能提升模型泛化能力,为高质量生成提供基础;
- 质量:高质量数据可提高模型精度、减少训练时长,而重复、噪声、错误等低质量数据会严重损害模型性能;
- 多样性:不同场景、领域的数据具有不同特征,能针对性提升模型在特定方向的能力。
2. 主流数据集分类
训练数据主要分为三大类,分别服务于不同生成需求:
- 文本-视频对数据集:公开的大规模文生视频专用数据集,包含视频及对应文本描述,如WebVid-10M、Panda-70M、HD-VILA-100M;
- 类别级数据集:用于视频理解和行为识别的基础数据集,视频按类别标注,适用于无条件视频生成,如UCF-101、Kinetics、Something-Something;
- 私有数据集:巨头公司专属的非公开数据集,如OpenAI(Sora)、Google(Imagen Video、Lumiere)的内部训练数据。
五、核心要点总结
- AI视频生成是数据驱动的系统工程,核心流程为数据收集→预处理→模型训练→视频生成,模型本质是算法与数据构成的"输入-输出"映射系统;
- 扩散模型因训练稳定性、生成多样性、可控性三大优势成为主流,当前主流架构分为U-Net(易训练、一致性弱)和DiT(高成本、长视频表现优)两条路线;
- Transformer的自注意力机制是实现时间一致性和动态关系理解的关键,VAE、时空补丁、CLIP等组件各司其职,共同支撑高质量视频生成;
- 训练数据是生成效果的核心约束,其规模、质量、多样性直接决定模型上限,不同类型数据集服务于不同生成场景。
AI视频技术正处于快速演进阶段,从基础范式到架构设计的持续创新,再到高质量数据的积累,共同推动着视觉内容创作进入智能化、高效化的新时代。