目录
- 引言
- [一、Seedance 2.0 模型原理](#一、Seedance 2.0 模型原理)
-
- [🧠 核心架构与技术原理](#🧠 核心架构与技术原理)
- [📈 与前代模型及主要竞品的对比](#📈 与前代模型及主要竞品的对比)
- [💎 总结](#💎 总结)
- [二、Seedance 2.0 案例体验](#二、Seedance 2.0 案例体验)
- 三、小结
引言
记得去年10月Sora2爆火,小马还写过体验文章《国庆爆火的Sora2使用初探和实例生成》,时隔数月,号称国内的Sora2大模型Seedance 2.0再次火了一把。小马自然要去试一下了。

一、Seedance 2.0 模型原理
根据非官方科学资料,Seedance 2.0 的核心原理是基于 "双分支扩散变换器(Dual-branch Diffusion Transformer)" 架构,实现了在同一生成链路中并行处理视觉与听觉信息,从而实现原生音画同步和多镜头叙事。
🧠 核心架构与技术原理
其核心技术原理主要包括以下几点:
| 核心技术模块 | 作用与特点 | 解决的问题 |
|---|---|---|
| 双分支扩散变换器 (Dual-branch DiT) | 这是模型的核心。它并非单一处理视频,而是拥有并行处理视觉和听觉信息的两个分支。这让音频生成不再是后期添加,而是与画面同步生成。 | 解决了传统AI视频"声画游离"、"口型对不上"的问题,实现原生音画同步。 |
| 多镜头叙事算法 | 模型能理解复杂的文本提示,自动拆解成"全景-中景-特写"等分镜逻辑,生成多个连贯镜头,并确保角色、场景、光影在不同镜头间保持一致。 | 攻克了长视频生成的"连贯性崩塌"难题,使AI能从"生成素材"迈向"完成叙事"。 |
| 3D空间感知与动态记忆网络 | 增强模型对三维空间和物体运动规律的理解,让运镜、光影变化更符合物理规则。同时,动态记忆网络帮助模型在生成长序列时"记住"并保持角色特征(如面部、服装)的一致性。 | 使生成的角色运动、摄像机运镜更真实自然,并确保了长视频中角色形象的高度稳定。 |
| "万物参考"多模态输入系统 | 支持同时上传最多12个参考文件(如图片、视频、音频),用来精确控制生成内容的人物外貌、运镜轨迹、画面氛围等。 | 极大提升了创作者对生成结果的可控性,降低了随机性,实现"像素级引导"。 |
📈 与前代模型及主要竞品的对比
为了更好地理解Seedance 2.0的定位,可以参考以下对比:
| 对比维度 | Seedance 2.0 | 前代 (Seedance 1.5 Pro) | 主要竞品对比 |
|---|---|---|---|
| 核心技术路线 | 叙事与音频优先:专注于多镜头连贯叙事和原生音画同步。 | 已实现基础音画同步,但叙事一致性和控制精度较低。 | Sora :侧重物理世界模拟与真实感。 Kling:侧重精确的物体运动控制(Motion Control)。 |
| 核心突破 | 导演级分镜、卓越的角色一致性、空间音频。 | 实现了音画同步生成,是一次重要突破。 | 各自在物理模拟、运动控制等不同维度领先。 |
| 生成速度 | 声称生成2K视频的速度比竞品Kling快30%。 | 比Seedance 1.0快15%。 | 速度是当前市场竞争的关键维度之一。 |
| 应用场景 | 适合需要完整叙事、多镜头切换的场景,如AI短剧、广告、影视预演。 | 适合对一致性要求不高的短视频生成。 | 适用于对物理真实感(Sora)或运动轨迹精确性(Kling)有极高要求的场景。 |
💎 总结
总的来说,Seedance 2.0通过架构创新,在原生音画同步 和多镜头一致性叙事 两大关键体验上取得了突破,将AI视频生成从"素材生成"推向了"导演级叙事工具"。它的出现也标志着AI视频赛道竞争重点,从基础画质转向了对创作意图的理解、执行精度和完整工作流的整合。
不过该技术仍有局限,例如生成的内容本质上是"不可编辑的完整视频",修改需重新生成。同时,对于处理非常复杂的物理交互和长逻辑链条,仍有提升空间。
二、Seedance 2.0 案例体验
体验Seedance 2.0 目前有两种方式,打开即梦或者小云雀。
小马以即梦网页平台为例,打开平台选择视频生成,自然就能选到Seedance 2.0这个模型。
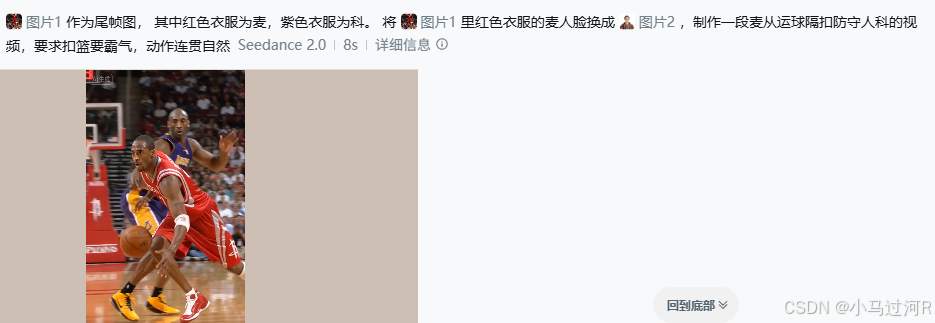
小马准备了一张图片(图片1)如下:

事实上小马还准备了一张图片,为小马的个人头像照(在这里就不展示了),作为图片2。
于是小马的提示词如下:
bash
@图片1作为尾帧图, 其中红色衣服为麦,紫色衣服为科。 将@图片1里红色衣服的麦人脸换成@图片2,制作一段麦从运球隔扣防守人科的视频,要求扣篮要霸气,动作连贯自然这里有个小插曲,第一次生成它提示我"视频未通过审核,本次不消耗积分",索性小马直接进行了再次生成,于是第二次成功了。后来小马又顺手加了AI配音。
生成的视频成果如下:
Seedance 2.0视频生成案例
三、小结
总体效果来讲呢,确实视频的各方面表现和动作流畅度等整体很自然了,就是有些细节问题还是存在的,比如过程中篮球突然变成了两个等等。而且人脸也没有根据提示词变换,当然以小马的经验,这可能和提示词的编写有关,我们需要调整提示词再看看。只不过即梦每天基本上只给了一次的生成机会,你懂的。小马明天再来调整试下看看。
小马认为虽然有点小瑕疵但是整体上也算瑕不掩瑜,确实能媲美Sora2(有小差距咱慢慢改进),号称国内的Sora2一点不过分。
这里附上《即梦 Seedance 2.0 使用手册(全新多模态创作体验)》、《即梦官方学习文档》的地址供大家一起学习参考使用。
本文就到这啦,感谢评阅。