⭐ 深度学习入门体系(第 3 篇):反向传播到底怎么工作的?
------用"找丢失的钱包"讲懂梯度下降与链式法则
反向传播(Backpropagation)是深度学习里最"常见但最难讲清"的知识点。很多人学完的感觉是:
知道它在干什么,但不知道它是怎么做到的。
这篇文章我会用一种非常贴近生活的方式,把它从"抽象数学"还原到"你每天都能理解的事情"。
文章目录
- [⭐ 深度学习入门体系(第 3 篇):反向传播到底怎么工作的?](#⭐ 深度学习入门体系(第 3 篇):反向传播到底怎么工作的?)
- [🧭 一、先用一句人话说清楚反向传播](#🧭 一、先用一句人话说清楚反向传播)
- [👛 二、为什么我总喜欢用"找丢了的钱包"解释反向传播?](#👛 二、为什么我总喜欢用“找丢了的钱包”解释反向传播?)
- [👜 三、类比:梯度下降 = "逆着脚印找钱包"](#👜 三、类比:梯度下降 = “逆着脚印找钱包”)
- [📉 四、损失函数 = "你丢钱包的痛苦程度"](#📉 四、损失函数 = “你丢钱包的痛苦程度”)
- [🧠五、梯度 = "往哪里走才能更快找到钱包"](#🧠五、梯度 = “往哪里走才能更快找到钱包”)
- [🧩六、链式法则 = "沿着你走过的路线反推每一步的责任"](#🧩六、链式法则 = “沿着你走过的路线反推每一步的责任”)
- [🧩 七、为什么反向传播必须"层层倒推"?](#🧩 七、为什么反向传播必须“层层倒推”?)
- [⚙️ 八、再换成专业一点的解释(但保持易懂)](#⚙️ 八、再换成专业一点的解释(但保持易懂))
- [🚶 九、优化器 = "你走路的方式"](#🚶 九、优化器 = “你走路的方式”)
- [🎯 十、把反向传播一句话讲透](#🎯 十、把反向传播一句话讲透)
- [📌 十一、为什么反向传播是深度学习的技术基石?](#📌 十一、为什么反向传播是深度学习的技术基石?)
- [🏁 十二、本文总结(极简版)](#🏁 十二、本文总结(极简版))
- [🔜 下一篇](#🔜 下一篇)
🧭 一、先用一句人话说清楚反向传播
反向传播就是:
根据错误往回推,修正每一层该负责的那部分错误,让它下次表现更好。
就像一个团队出错后,不是光骂队长,而是找出每个人在这件事上的责任,然后做针对性的改进。
👛 二、为什么我总喜欢用"找丢了的钱包"解释反向传播?
因为它真的太贴切了。
我们直接来看这个生活化的类比。
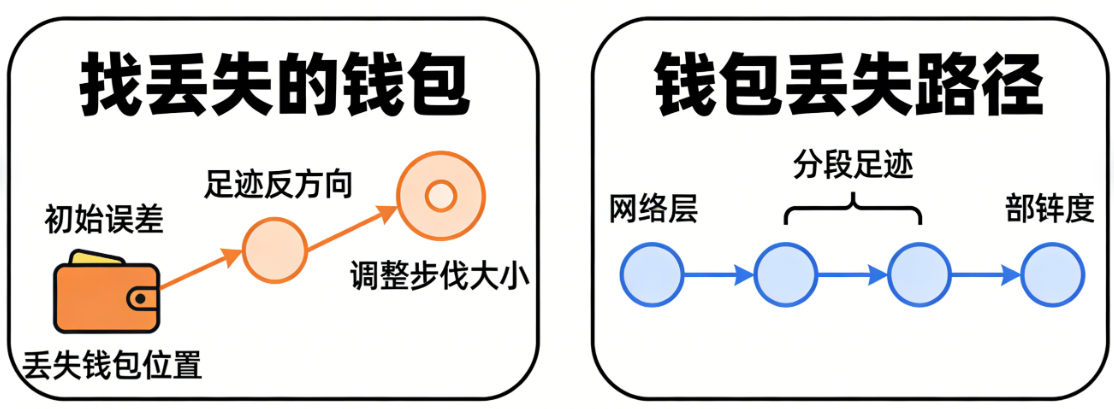
👜 三、类比:梯度下降 = "逆着脚印找钱包"
假设你今天在公园丢了钱包。
你不知道它在哪,但你知道两件事:
1. 你是沿着某条路线走的
2. 钱包是在某个地方掉的
你要找到钱包最自然的方法是什么?
逆着你刚才的路线一点点往回走,找丢失的位置。
这就是梯度下降。
你现在走在"错误的一端"(预测错误、损失较大),想办法一步步往"正确的方向"倒推
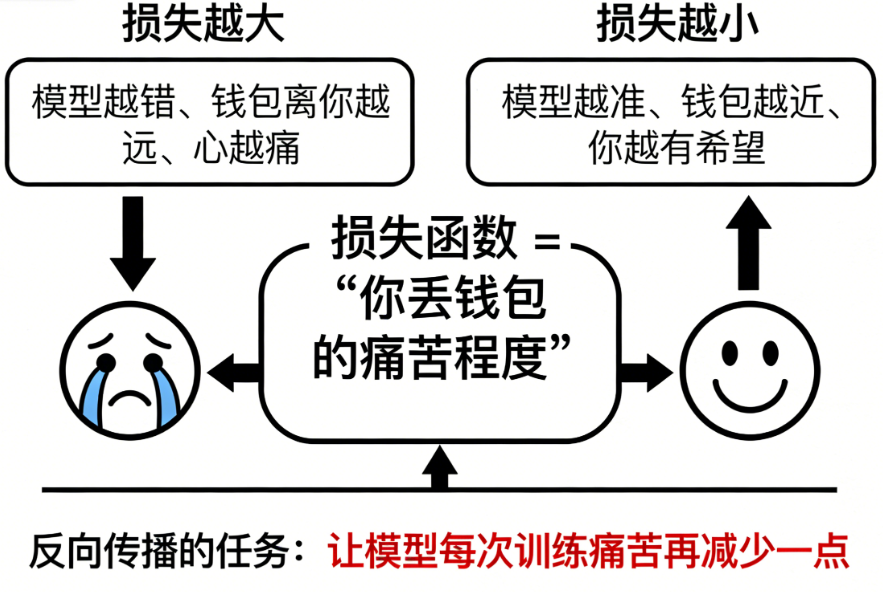
📉 四、损失函数 = "你丢钱包的痛苦程度"
损失越大:
- 模型越错
- 钱包离你越远
- 心越痛
损失越小:
- 模型越准
- 钱包越近
- 你越有希望
反向传播的任务,就是让模型每次训练:
痛苦稍微少一点。
🧠五、梯度 = "往哪里走才能更快找到钱包"
梯度这个词本来挺玄乎。
但其实它就是一句话:
"告诉你往哪个方向走,错误下降得最快。"
比如:
- 如果你往左走损失变小:梯度指向左
- 如果你往右走损失变小:梯度指向右
- 如果你原地踏步:梯度为 0
梯度的符号和大小,决定了:
- 方向(左/右/上/下)
- 步子大小(快点走/慢点走)
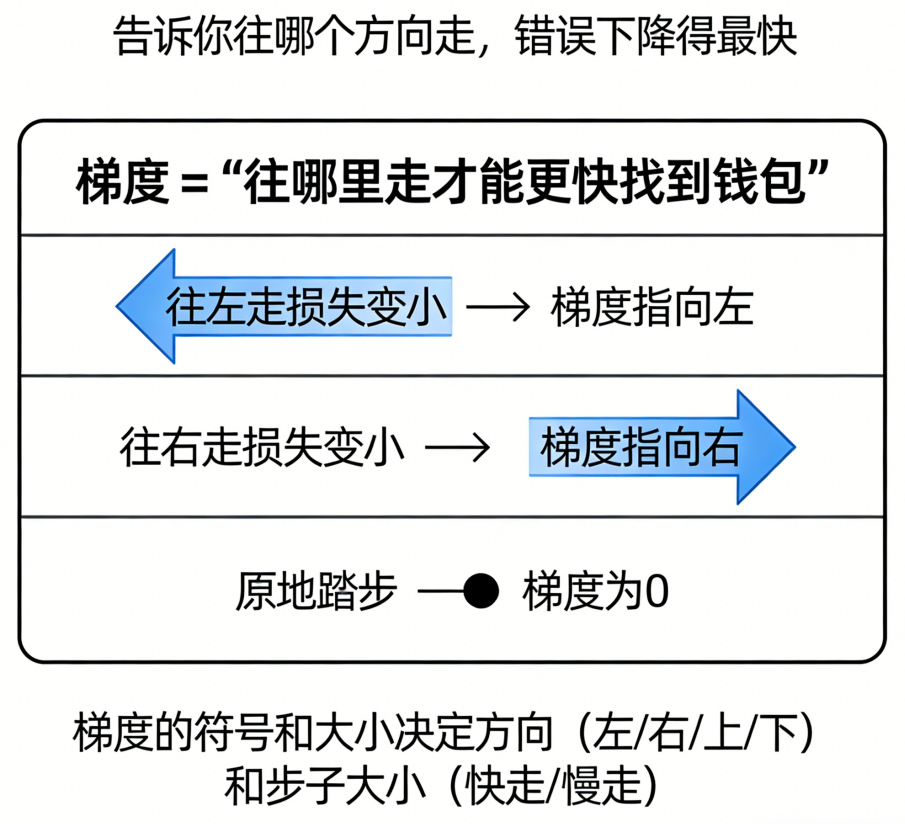
这就是"梯度下降"的含义。
🧩六、链式法则 = "沿着你走过的路线反推每一步的责任"
我们再回到找钱包的例子。
你从家 → 商场 → 公园 → 小吃摊 → 地铁站
最后发现钱包丢了。
你怎么查?
你会从最后一个地点往前查:
- 地铁站有没有?
- 小吃摊有没有?
- 公园有没有?
- 商场有没有?
越早的地方你就越轻松,因为范围变小了。
反向传播做的就是:
根据最终的损失,按路径逐层倒推,检查每一层对错误的贡献是多少。
数学上,就是链式法则:
最终损失 L
依赖于
模型输出 y
依赖于
每一层的输出
依赖于
每一层的权重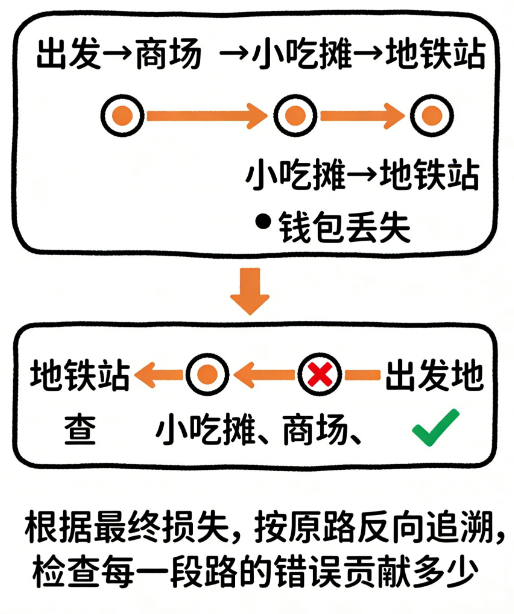
于是:
dL/dW = (dL/dy) × (dy/dx) × (dx/dW)这就是反向传播的"数学骨架"。
🧩 七、为什么反向传播必须"层层倒推"?
因为神经网络的结构是链式的:
输入 → 层 1 → 层 2 → 层 3 → 输出
就像你走过的路径:
家 → 商场 → 公园 → 小吃摊 → 地铁站
你要准确定位哪一层让输出变偏了,就必须沿着路径反推。
反向传播就是这么一个"逐层倒查责任"的过程。
⚙️ 八、再换成专业一点的解释(但保持易懂)
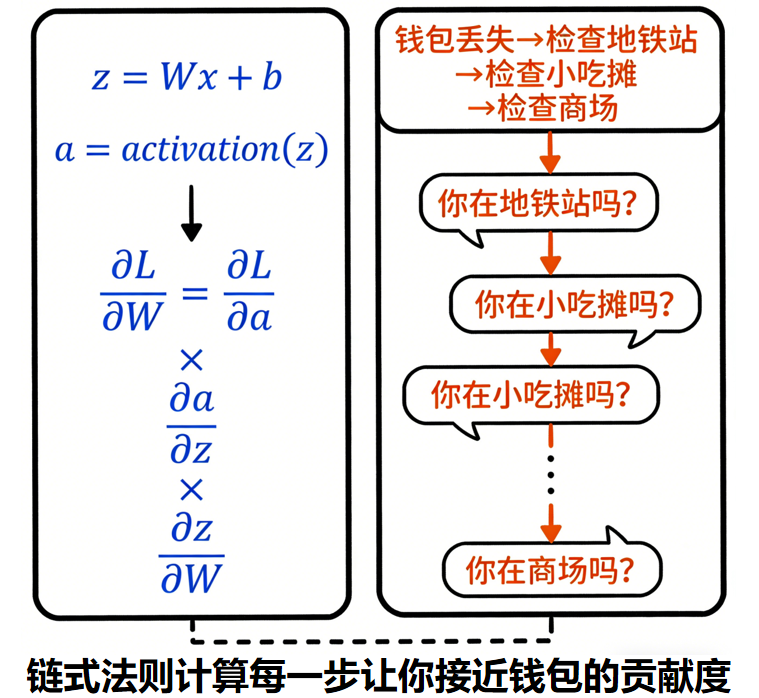
每一层计算如下:
z = Wx + b
a = activation(z)损失 L 想要优化,需要对每个参数 W 求偏导:
∂L/∂W但 L 并不是 W 的直接函数,而是通过很多层间接联系的。
链式法则告诉我们:
∂L/∂W = ∂L/∂a × ∂a/∂z × ∂z/∂W你看是不是很像:
"钱包最终丢了"
→ "你在地铁站掉的吗?"
→ "你在公园掉的吗?"
→ "你在商场掉的吗?"
链式法则是在计算:
每一步让你更接近"丢钱包"的贡献是多少。
有了这个责任分摊,优化器(SGD、Adam)就可以调整每个 W,使损失下降。
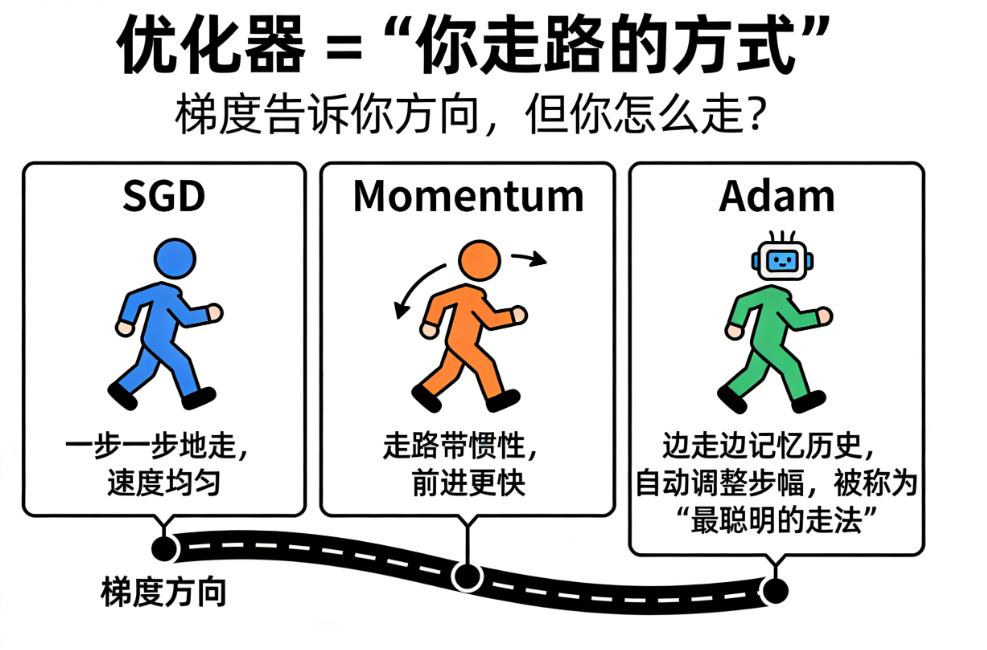
🚶 九、优化器 = "你走路的方式"
梯度告诉你方向,但你怎么走?
不同优化器就像不同的"找钱包策略":
SGD
一步一步地走,速度均匀。
Momentum
走路带惯性,前进更快。
Adam
边走边记忆历史,自动调整步幅,被称为"最聪明的走法"。
🎯 十、把反向传播一句话讲透
如果你要记一句话:
反向传播是用链式法则,把最终的错误从输出层一步一步传回输入层,让每个参数都知道自己该怎么调整。
它不是"魔法",它是很朴素的数学。
📌 十一、为什么反向传播是深度学习的技术基石?
因为它让神经网络具有:
| 能力 | 描述 |
|---|---|
| 自我纠错 | 知道自己错在哪里 |
| 分层学习 | 每一层学它应该学的特征 |
| 可扩展性 | 你堆 100 层,也能正常训练 |
| 优化能力强 | 可以拟合复杂任务 |
| 自动特征学习 | 不需要人工写特征了 |
一句话概括:
没有反向传播,深度学习根本"深"不起来。
🏁 十二、本文总结(极简版)
- 损失函数:你离正确答案有多远
- 梯度:往哪里走损失下降最快
- 反向传播:让每一层都知道自己错了多少
- 链式法则:层与层之间的误差计算方式
- 优化器:根据梯度走、修正所有参数
- 最终目标:不断减少损失,让模型越来越准
反向传播并不神秘,它本质就是:
根据错误往回推,逐层算责任,再逐层修正。
🔜 下一篇
《深度学习入门体系(第 4 篇):损失函数与优化器到底"怎么选择"?------给新手最清晰的一份指南》