重要信息
时间:2026年01月16-18日
地点:中国-上海



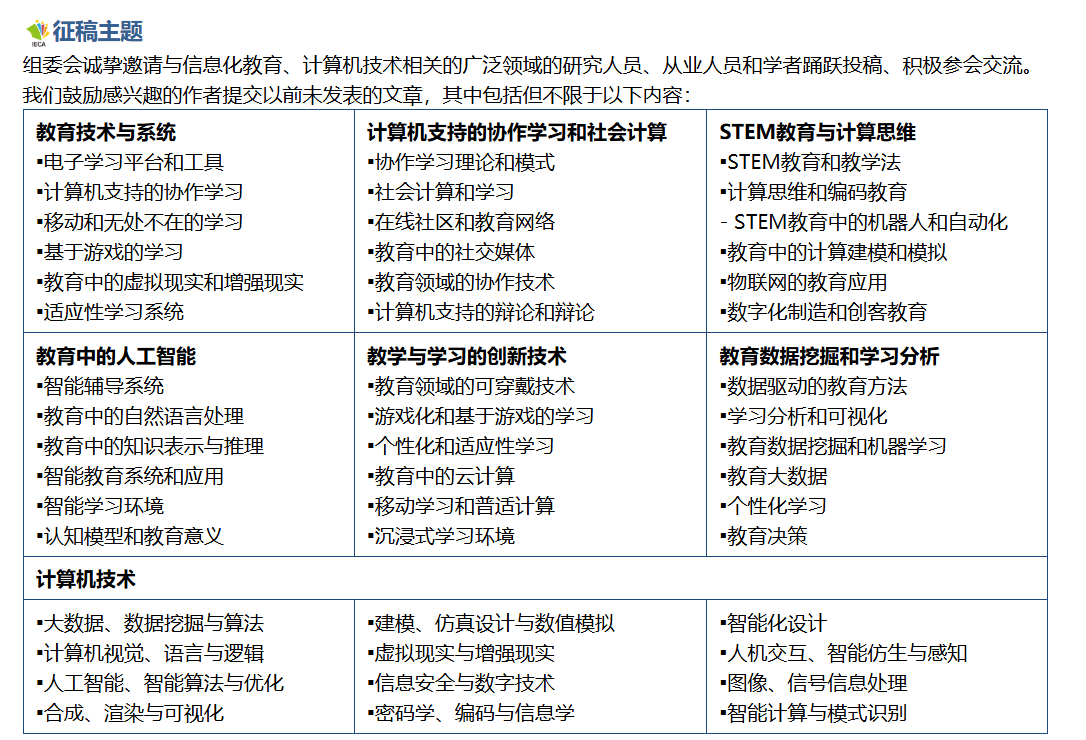
征稿主题
一、信息化教育与计算机技术融合的核心维度
信息化教育的本质是利用计算机技术、数据科学、人工智能等手段重构教育场景、优化教学流程、提升学习效率。IECA 2026 聚焦这一领域的技术落地与创新,本文从数据驱动的教学分析 、智能化教学工具开发 、教育资源数字化管理三个核心维度,结合技术原理与 Python 实践,拆解计算机技术在信息化教育中的落地路径。
1.1 核心技术体系梳理
下表汇总了信息化教育中主流计算机技术的应用场景、核心优势及技术难点,是 IECA 2026 重点探讨的技术方向:
| 技术领域 | 典型应用场景 | 核心优势 | 技术难点 |
|---|---|---|---|
| 数据分析 | 学生成绩趋势分析、教学效果评估 | 量化教学问题,精准定位薄弱环节 | 数据异构性、样本偏差 |
| 机器学习 | 个性化学习路径推荐、学情预警 | 自适应匹配学生认知水平 | 模型泛化能力、小样本学习 |
| 自然语言处理 | 智能答疑、作业自动批改 | 提升教学交互效率,降低人工成本 | 语义理解准确性、多语种适配 |
| 数据库技术 | 教育资源库、学生档案管理 | 数据高效存储与快速检索 | 高并发访问、数据安全与隐私保护 |
| 可视化技术 | 教学数据看板、学习轨迹展示 | 直观呈现数据规律,辅助决策 | 多维度数据融合可视化、交互设计 |
二、数据驱动的教学分析实践
2.1 教学数据预处理核心流程
教学数据通常包含成绩数据、考勤数据、课堂互动数据等多类异构数据,预处理是分析的基础,核心步骤包括:数据清洗、缺失值填充、特征标准化、数据融合。以下是基于 Python 的教学成绩数据预处理示例:
python
运行
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
# 1. 读取教学成绩数据(模拟数据)
data = pd.DataFrame({
'学生ID': [1001, 1002, 1003, 1004, 1005],
'数学成绩': [85, np.nan, 78, 92, 65],
'语文成绩': [79, 88, 81, np.nan, 72],
'课堂互动次数': [15, 8, 22, 18, 9],
'作业完成率': [1.0, 0.8, 0.95, 1.0, 0.7]
})
# 2. 缺失值填充(使用学科平均分填充)
math_mean = data['数学成绩'].mean()
chinese_mean = data['语文成绩'].mean()
data['数学成绩'].fillna(math_mean, inplace=True)
data['语文成绩'].fillna(chinese_mean, inplace=True)
# 3. 特征标准化(消除量纲影响)
scaler = StandardScaler()
numeric_cols = ['数学成绩', '语文成绩', '课堂互动次数', '作业完成率']
data[numeric_cols] = scaler.fit_transform(data[numeric_cols])
# 4. 输出预处理结果
print("预处理后的教学数据:")
print(data.round(2))2.2 学情趋势分析与可视化
基于预处理后的数据,可通过时序分析、相关性分析挖掘学情规律。以下代码实现成绩与课堂互动的相关性分析及可视化:
python
运行
import matplotlib.pyplot as plt
# 设置中文显示(避免乱码)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 计算相关性系数
corr = data[['数学成绩', '语文成绩', '课堂互动次数']].corr()
print("\n相关性矩阵:")
print(corr.round(2))
# 2. 绘制散点图(数学成绩 vs 课堂互动次数)
plt.figure(figsize=(8, 6))
plt.scatter(data['课堂互动次数'], data['数学成绩'], color='blue', s=80)
plt.title('课堂互动次数与数学成绩相关性分析', fontsize=14)
plt.xlabel('课堂互动次数(标准化)', fontsize=12)
plt.ylabel('数学成绩(标准化)', fontsize=12)
plt.grid(True, alpha=0.3)
plt.show()
# 3. 绘制热力图(相关性可视化)
plt.figure(figsize=(8, 6))
im = plt.imshow(corr, cmap='coolwarm')
plt.colorbar(im)
# 添加数值标注
for i in range(len(corr.columns)):
for j in range(len(corr.columns)):
plt.text(j, i, f'{corr.iloc[i, j]:.2f}',
ha='center', va='center', color='white', fontsize=12)
plt.xticks(range(len(corr.columns)), corr.columns, rotation=45)
plt.yticks(range(len(corr.columns)), corr.columns)
plt.title('教学数据相关性热力图', fontsize=14)
plt.tight_layout()
plt.show()三、智能化教学工具开发核心思路
3.1 智能答疑系统的技术架构
智能答疑系统是信息化教育的典型应用,核心由问题解析层 、知识库匹配层 、答案生成层组成,技术架构如下:
- 问题解析层:基于 NLP 的分词、实体识别、意图分类,将自然语言问题转化为结构化查询;
- 知识库匹配层:基于向量检索、语义相似度计算,匹配知识库中最优答案候选;
- 答案生成层:基于 Prompt 工程、轻量化 LLM,生成精准、易懂的答疑内容。
3.2 轻量化智能答疑 demo 实现
以下是基于 Python 和 jieba、scikit-learn 实现的简易智能答疑系统核心代码:
python
运行
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 1. 构建教育知识库(模拟学科答疑数据)
knowledge_base = {
"q1": "什么是Python的列表推导式?",
"a1": "Python列表推导式是一种简洁的创建列表的方式,语法为[表达式 for 变量 in 可迭代对象 if 条件],例如[x*2 for x in range(10) if x%2==0]。",
"q2": "如何提高Python代码的运行效率?",
"a2": "提高Python效率的方法包括:使用内置函数代替自定义循环、采用生成器减少内存占用、使用NumPy替代原生列表、合理使用多线程/多进程等。",
"q3": "线性回归的核心原理是什么?",
"a3": "线性回归通过最小二乘法拟合自变量与因变量的线性关系,目标是最小化预测值与真实值的残差平方和,公式为y = wX + b。"
}
# 2. 预处理函数:分词+去除停用词
def preprocess_text(text):
stop_words = ['什么', '是', '的', '如何', '?', '吗', '呢']
words = jieba.lcut(text)
words = [w for w in words if w not in stop_words and w.strip()]
return ' '.join(words)
# 3. 构建TF-IDF向量模型
questions = [knowledge_base[f'q{i}'] for i in range(1, 4)]
preprocessed_qs = [preprocess_text(q) for q in questions]
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(preprocessed_qs)
# 4. 智能匹配函数
def get_answer(user_question):
# 预处理用户问题
preprocessed_user_q = preprocess_text(user_question)
# 转换为TF-IDF向量
user_vec = vectorizer.transform([preprocessed_user_q])
# 计算余弦相似度
similarities = cosine_similarity(user_vec, tfidf_matrix)[0]
# 找到最相似的问题
max_idx = similarities.argmax()
max_sim = similarities[max_idx]
# 相似度阈值判断
if max_sim < 0.2:
return "抱歉,暂未找到相关答案,请重新描述问题。"
return knowledge_base[f'a{max_idx+1}']
# 测试智能答疑系统
if __name__ == "__main__":
user_input = input("请输入你的问题:")
answer = get_answer(user_input)
print("\n答疑结果:", answer)四、教育资源数字化管理的技术实现
4.1 教育资源库的数据库设计
教育资源库需存储课件、视频、习题等多类资源,基于 MySQL 的核心表设计如下(以课件资源表为例):
| 字段名 | 数据类型 | 主键 / 外键 | 说明 |
|---|---|---|---|
| resource_id | INT(11) | 主键 | 资源唯一标识 |
| resource_name | VARCHAR(255) | - | 资源名称 |
| resource_type | VARCHAR(50) | - | 资源类型(课件 / 视频 / 习题) |
| upload_time | DATETIME | - | 上传时间 |
| file_path | VARCHAR(500) | - | 资源存储路径 |
| subject | VARCHAR(50) | - | 所属学科 |
| download_count | INT(11) | - | 下载次数 |
| is_valid | TINYINT(1) | - | 是否有效(1 = 有效,0 = 无效) |
4.2 资源库检索功能实现
基于 Python+SQLAlchemy 实现教育资源的精准检索,支持按名称、学科、类型多条件筛选:
python
运行
from sqlalchemy import create_engine, Table, MetaData, select, and_
import pandas as pd
# 1. 连接数据库(模拟本地MySQL)
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/education_db')
metadata = MetaData()
# 2. 映射资源表
resource_table = Table(
'resource', metadata,
autoload_with=engine
)
# 3. 多条件检索函数
def search_resource(name_keyword=None, subject=None, res_type=None):
# 构建查询条件
conditions = []
if name_keyword:
conditions.append(resource_table.c.resource_name.like(f'%{name_keyword}%'))
if subject:
conditions.append(resource_table.c.subject == subject)
if res_type:
conditions.append(resource_table.c.resource_type == res_type)
# 执行查询
query = select(resource_table).where(and_(*conditions))
with engine.connect() as conn:
result = conn.execute(query)
# 转换为DataFrame便于展示
df = pd.DataFrame(result.fetchall(), columns=result.keys())
return df
# 测试检索功能
if __name__ == "__main__":
# 检索"Python"相关的课件资源(数学学科)
result_df = search_resource(
name_keyword="Python",
subject="数学",
res_type="课件"
)
print("\n资源检索结果:")
print(result_df[['resource_id', 'resource_name', 'upload_time', 'download_count']])五、国际交流与合作机会
作为国际学术会议,将吸引全球范围内的专家学者参与。无论是发表研究成果、聆听特邀报告,还是在圆桌论坛中与行业大咖交流,都能拓宽国际视野,甚至找到潜在的合作伙伴。对于高校师生来说,这也是展示研究、积累学术人脉的好机会。