
引言
间隔重复(Spaced Repetition)作为提升长期记忆效率的有效方法,已经在语言学习、医学教育等专业领域得到广泛应用。Anki作为该领域最流行的开源软件,其内置的SM2算法在过去十多年间服务了数百万学习者。然而,随着认知科学研究的深入和计算能力的提升,传统算法的局限性也逐渐显现。2022年,一个名为FSRS(Free Spaced Repetition Scheduler)的开源项目开始进入Anki社区视野,它试图通过更精细的数学模型来优化复习调度策略。本文将从技术角度客观分析FSRS算法的设计原理、实现特点及其在间隔重复系统中的实际表现。
FSRS算法的核心概念
FSRS由开发者L-M-Sherlock在GitHub上开源发布,项目地址为open-spaced-repetition/free-spaced-repetition-scheduler。与Anki默认的SM2算法不同,FSRS基于DHP(Difficulty, Historical Performance)模型构建,该模型试图更准确地模拟人类记忆遗忘曲线。
四个关键参数
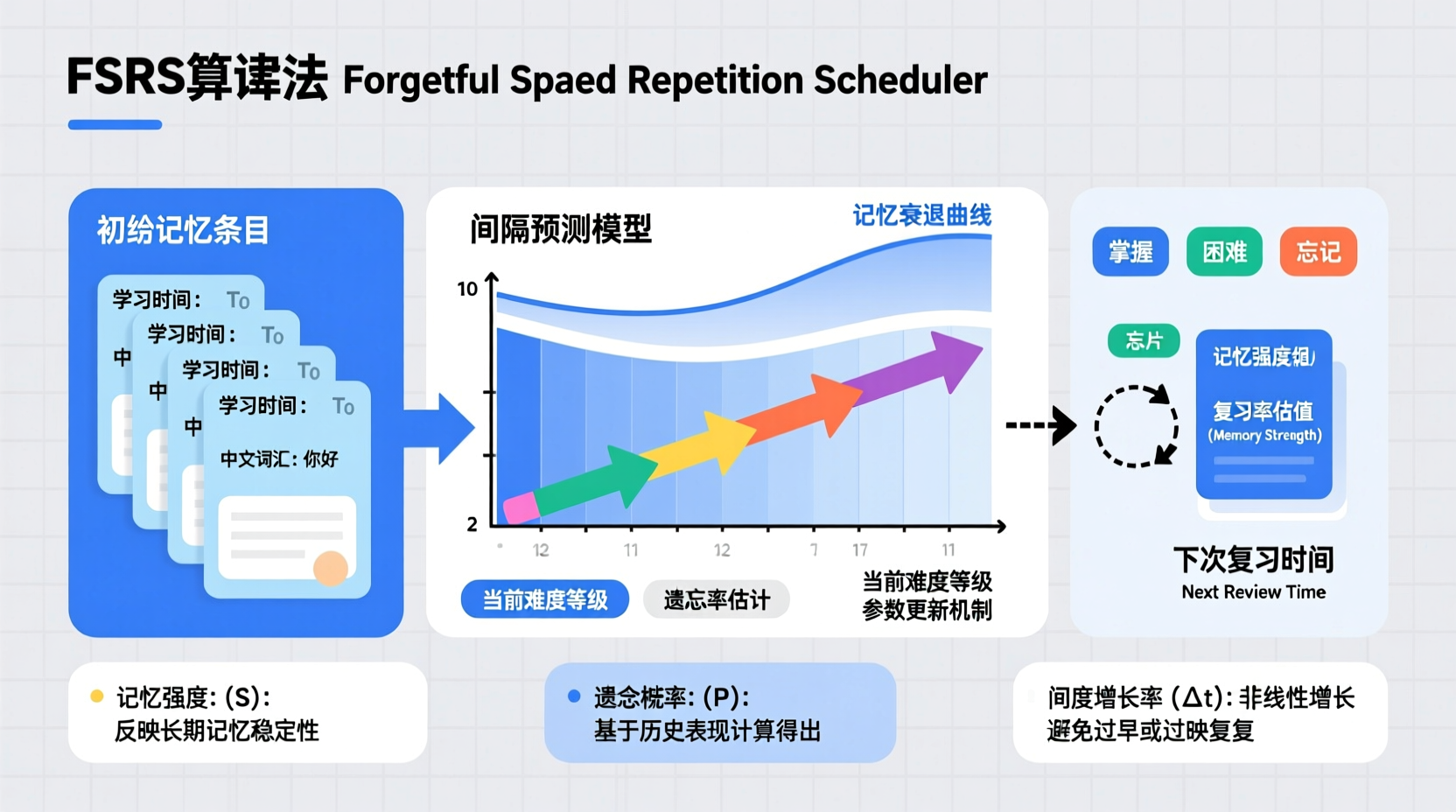
FSRS算法为每个记忆项目维护四个动态参数:
1. 难度(Difficulty, D)
难度参数反映特定知识点的内在复杂程度。与SM2固定的难度等级(1-4)不同,FSRS的难度是一个连续浮点数,范围通常在0到10之间。算法会根据用户的实际回忆表现动态调整这一数值:连续成功回忆会降低难度估计值,而失败则会显著提高难度。这种连续化设计使得难度评估更加精细,避免了传统算法中"非此即彼"的离散化局限。
2. 稳定性(Stability, S)
稳定性参数衡量记忆痕迹的牢固程度,单位为天。它直接决定了下一次复习的推荐间隔。稳定性越高,意味着该记忆在大脑中保留的时间越长,系统会相应延长复习间隔。FSRS通过指数增长模型来更新稳定性,增长速率与当前稳定性水平和回忆成功率相关。
3. 可提取性(Retrievability, R)
可提取性表示在特定时间点成功回忆该项目的概率,取值范围0,1。这是一个时间依赖参数,会随着距离上次复习的时间推移而衰减。FSRS使用指数遗忘曲线模型来计算可提取性:R = e^(-t/S),其中t是经过的天数,S是稳定性参数。这种设计使得算法能够量化"几乎遗忘"的临界状态。
4. 回忆概率(Probability of Recall)
这是算法预测用户在某次复习中能够正确回忆的概率。FSRS的目标是将这个概率维持在预设的理想范围内(通常为0.85-0.95),既避免过度复习(效率低下),也防止遗忘风险过高。
状态更新机制
当用户完成一次复习并给出评分(Again/Hard/Good/Easy)后,FSRS按以下流程更新参数:
首先,算法根据当前参数计算预测的回忆概率,并与用户实际表现对比,计算预测误差。然后,使用梯度下降方法调整难度和稳定性参数,使得未来预测更加准确。具体而言:
- Again(失败):难度显著增加,稳定性大幅降低,可能触发短期内的重新学习序列
- Hard(困难):难度小幅增加,稳定性适度提升但低于Good水平
- Good(良好):难度略微下调,稳定性按正常速率增长
- Easy(简单):难度明显降低,稳定性获得额外加成
这种基于实际表现反馈的动态调整机制,使得FSRS能够逐渐适应个体的记忆特征和学习内容特性。
与SM2算法的客观对比
为了理解FSRS的技术定位,有必要将其与Anki默认的SM2算法进行客观比较。
模型复杂度
SM2采用简化的经验公式,仅维护两个核心变量:间隔天数和简易度因子。其计算过程涉及固定的乘数(如2.5、1.3等)和线性调整。相比之下,FSRS的数学模型更为复杂,使用指数函数和连续参数空间,计算开销相对更高,但提供了更精细的控制能力。
个性化程度
SM2的简易度因子虽然也会调整,但调整幅度和频率有限,且对所有卡片采用相同的更新规则。FSRS则为每张卡片维护独立的四维参数向量,能够实现真正的个性化调度。对于同一用户而言,不同主题的卡片(如语言词汇与法律条文)会演化出完全不同的复习模式。
预测能力
SM2本质上是一个基于规则的经验系统,不具备概率预测能力。FSRS则明确建模了回忆概率,可以量化评估复习效果。这种预测能力不仅用于调度优化,也为用户提供了可解释的复习建议依据。
计算资源需求
在性能方面,FSRS的复杂模型需要更多的CPU计算。在大型牌组(数万张卡片)中,初次启用FSRS时可能需要数分钟进行参数初始化。不过,开发者通过Rust实现核心计算模块,并提供了GPU加速选项,实际日常使用中的延迟通常在毫秒级别,对用户体验影响有限。
在Anki中的实现与使用
FSRS通过Anki插件形式集成,安装后可在牌组选项中启用。其工作流程如下:
参数初始化阶段:插件会分析用户的历史复习记录(需至少1000条复习日志),通过最大似然估计法计算初始参数。这个过程在本地完成,数据不会上传至服务器,符合隐私保护原则。
日常调度阶段:每次复习时,插件根据当前卡片参数和用户评分,实时计算新的间隔。计算结果会直接覆盖Anki默认的调度结果,显示在复习界面中。
周期性优化:FSRS建议每月重新运行一次参数优化,以纳入最新的学习数据。这种持续优化机制使得算法能够跟踪用户记忆能力的变化(如因年龄、健康状况等因素导致的记忆力波动)。
值得注意的是,FSRS完全在客户端运行,不依赖任何云服务。其代码开源,接受社区审计,这在数据隐私日益受到重视的今天是一个重要特点。
算法特点分析
优势方面
1. 科学依据更强
FSRS的模型设计参考了近期的记忆研究文献,其指数遗忘曲线假设在实证研究中获得了更多支持。相比SM2上世纪80年代的经验公式,理论基础更为现代。
2. 调度效率提升
早期用户数据显示,在达到相同记忆保留率的前提下,FSRS通常能减少约10-20%的复习次数。这得益于其更准确的间隔预测,避免了不必要的过早复习。
3. 可解释性与可调试性
由于FSRS输出概率预测,用户可以通过插件提供的统计图表,直观了解算法对自己的记忆模式的建模效果。这种透明度有助于建立用户信任。
局限性与考量
1. 冷启动问题
新用户或新牌组缺乏足够的历史数据时,算法性能可能不稳定。虽然FSRS会回退到类SM2的默认策略,但初始阶段的调度质量难以保证。
2. 模型假设的普适性
FSRS的遗忘曲线模型基于群体平均数据,但个体差异依然存在。某些特殊人群(如记忆障碍患者)或特殊学习内容(如技能性知识而非事实性知识)可能不完全符合模型假设。
3. 社区生态兼容性
由于FSRS改变了核心调度逻辑,某些依赖Anki默认算法的插件可能产生冲突。用户在启用前需要评估其插件环境的兼容性。
总结
FSRS算法代表了间隔重复技术从经验规则向数据驱动模型的一次演进。它通过引入连续参数空间和概率预测框架,在理论上提供了比传统SM2更精细的调度能力。对于追求学习效率优化且具备一定技术背景的用户,FSRS提供了一个值得研究的选择。
然而,需要明确的是,任何算法都只是工具,其效果最终取决于学习者的使用方式和内容质量。SM2经过数十年验证,其简单可靠的特性依然适合大多数普通用户。FSRS的出现丰富了间隔重复系统的技术生态,为特定需求用户提供了替代方案,而非简单的"升级"或"替代"。
未来,随着更多用户数据的积累和算法的持续迭代,FSRS模型有望进一步完善。同时,其开源特性也为学术研究提供了实验平台,可能促进记忆科学领域的新发现。对于技术爱好者和教育研究者,关注FSRS的发展动态将有助于理解人工智能如何与传统学习方法相结合,创造更高效的个性化学习体验。