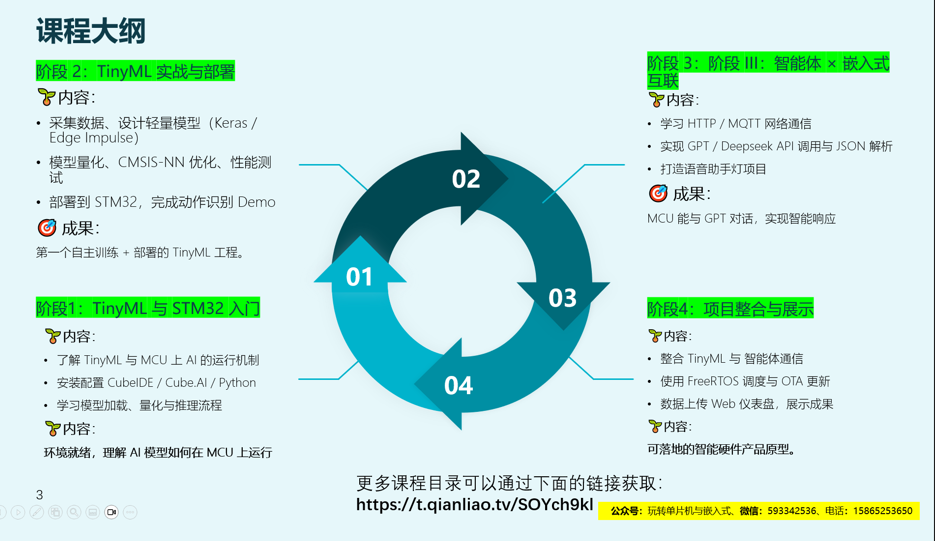
我的上一篇文章:谁说单片机根本不能跑AI模型?我已在STM32F103上实测TinyML除了获得很多的点赞和收藏之外,留言或者质疑声比较多的是:为什么为了计算正弦波,非要搞个神经网络出来?

针对这么多的质疑,确实有必要再写一篇文章将这个事情说道说道了。
这篇文章我主要是要回答下面的两个问题:
为什么几乎所有 TinyML 的 Hello World,都选择了 正弦波 作为第一个 Demo?
在资源有限的 STM32F103 上,这件事到底有多"可行"?
一、从"点亮 LED"到"学会一个函数"
我相信很多单片机入门的同学们或者很多开发板的第一个例程就是:点亮一个 LED。
为什么仅仅就点亮一个LED灯呢?
其实原因很简单:
(1)足够直观,灯亮或者灭,一下就看懂;
(2)足够简单,几行最简单的代码就能跑通整个工具链;
也就是:用最简单的功能、最直观的效果,验证硬件连通、编译、下载、调试的整个流程。
其实,TinyML(TIny machine learning)的Hello World,也在做类似的事情:
拿一个足够简单、足够直观、足够容易验证的任务,让我们用一整套TinyML 流水线(数据 → 模型 → 部署 → MCU)完整走一遍。
TInyML的工作流如下图:
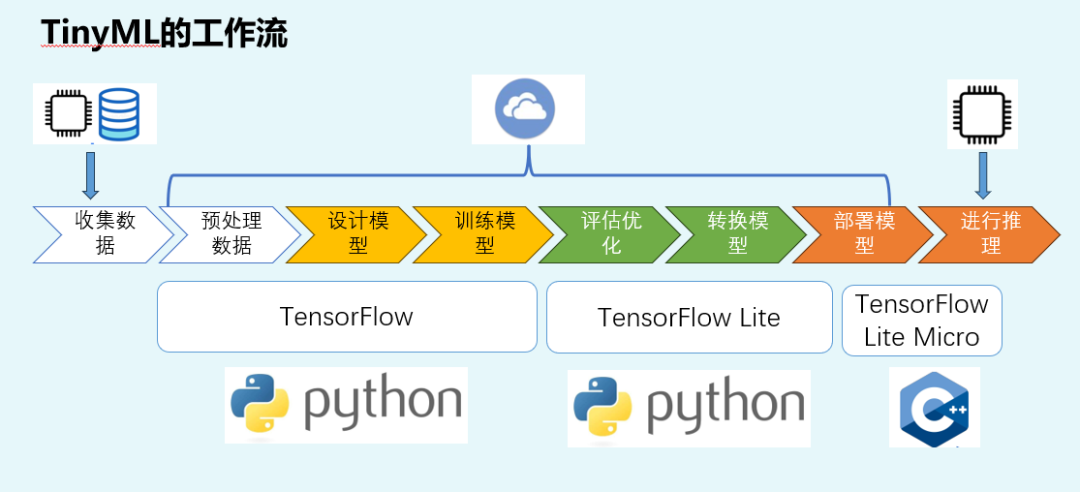
上面这个图是我课程的"老演员":因为我会根据这个流程,手把手的教会大家从收集数据、预处理数据、部署模型到模型部署和运行的全部流程;
与普通的单片机课程不同的是,我们的功能不是让 LED 亮/灭,而是让 MCU 输出一个"学会的函数"。于是,"用神经网络拟合 sin(x)",就成了一个非常理想的初始任务。
也正是因为接触TInyML的同学大多都有一定的单片机或编程基础,所以会对"可以使用函数实现的功能,非要上这么复杂的神经网络",感到难以理解。
二、为什么TinyML的Hello World选sin(x)?
当然了,选择sin(x)也不是小编自己选择的,而是TInyML的教材中使用的就是sin(x)。这也就好比:很多开发板的第一个例程都是GPIO,都是在控制LED一样。

TinyML选择sin(x)也是一个非常理想的"回归问题"。在机器学习里,任务大致可以分两类:
- 第一类是分类(Classification):输出是离散的类别,比如 0/1、A/B/C;网络上或者很多介绍神经网络的文章很喜欢用"用猫的照片训练,让大模型去识别是不是猫?",这类问题就是分类
- 第二类是回归(Regression):输出是连续的数值,比如温度、角度、函数值等等。同样以猫的例子来举例:给出猫的照片,让大模型去推理猫有多少岁?。
上面的两类其实就可以类比我们数字电路中的开关量、模拟量。
其实sin(x) 就是非常典型的回归问题:
-
输入x是一个标量 ,一般为弧度值,(0 ~ 2π);
-
输出y也是一个标量,
y=sin(x),连续值,范围在 -1, 1 之间。
用这小型神经网络来学习这个关系,本质上是在做:给神经网络一堆(x, sin(x)) 的样本,让它学会"记住并归纳"这条光滑函数的形状。进而可以实现最终的推理。
这有几个好处:
(1)模型结构可以非常简单
只需要1维输入、几层全连接层、1维输出,小到离谱;训练收敛比较容易。sin(x)是光滑、周期性的函数,梯度友好,网络很容易拟合;可以顺带引出很多概念
-
回归 vs 分类;
-
过拟合:用非常复杂的网络去拟合简单函数
-
泛化能力:在没见过的 x 上还能不能预测对
对于 TinyML 初学者或者我们学员(零AI基础的嵌入式工程师)来说,这比一上来就做人脸分类、语音唤醒要友好得多。
(2)非常容易"可视化误差",一眼就能看出模型好坏
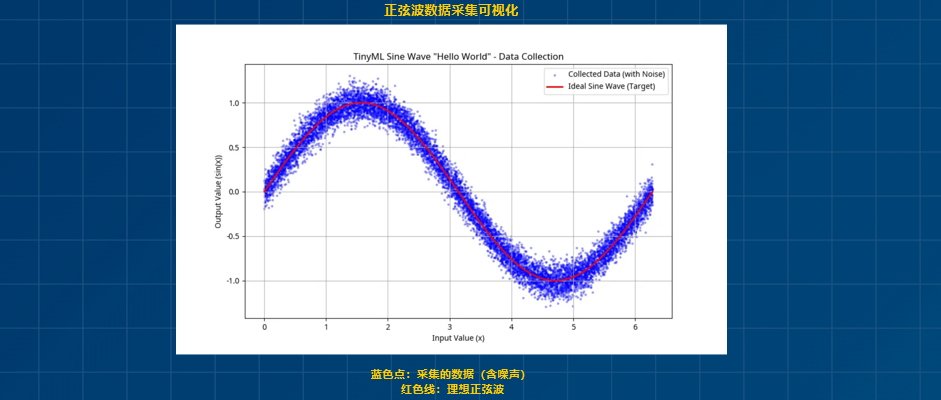
选sin(x)做Hello World,另一个关键原因是:模型效果可以直接"画出来"。
比如我把模型跑在 STM32F103 上的例子:每隔0.1rad输入一个 x,然后输出预测的 y_pred,同时上位机还能算出真实值 y_ref = sin(x),那么我们就可以得到两条曲线:
-
一条是真实曲线:y_ref = sin(x)。
-
另一条是模型曲线:y_pred = f_model(x)。
这时,你只要把这两条曲线画在同一个坐标系里就行了。
如下面的图片所示。
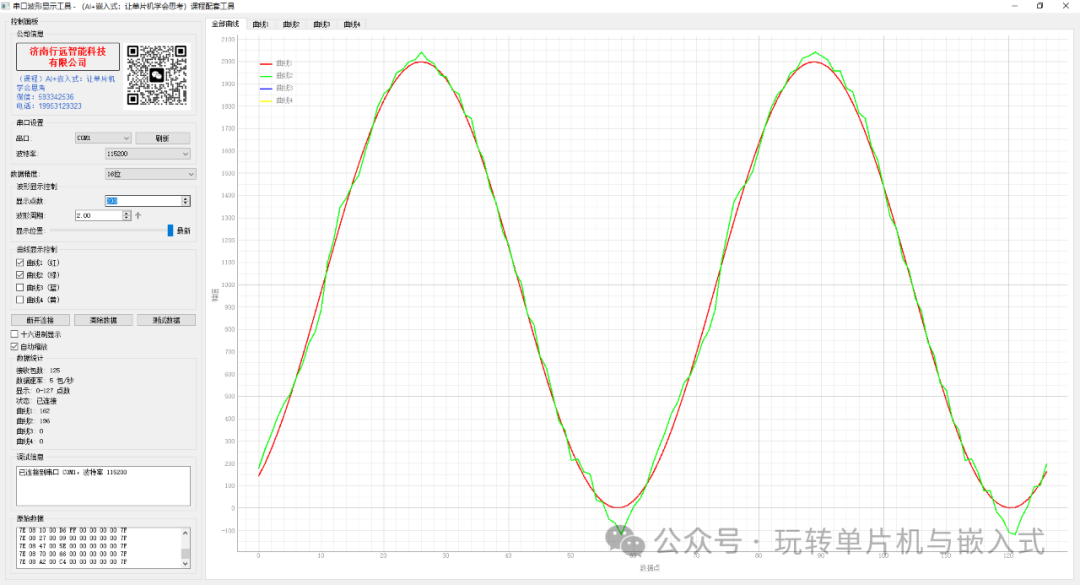
如果模型学得好,两条曲线几乎重合,只在局部有一点小误差;
如果模型有问题,你会看到两条曲线在某些区间偏得很厉害。
并且我们课程中同学也提到:怎么降低误差(也是我们课程中主要讲解的内容之一:如果对模型进行优化)
这种"直观可视化"的能力,是很多 TinyML 入门 Demo 不具备的。
对于初学者或者零AI基础的同学来说,这种画曲线的形式比单纯打印损失值、准确率要更有感知:
"原来 AI 模型就是在学一条曲线啊,它学得好不好,我用眼睛就能看出来。"
这也非常适合你在我们课程中里做效果展示。
(3)数据集生成极其方便,不依赖传感器
TinyML 的很多实际项目,都涉及真实传感器数据采集:如IMU(加速度、陀螺仪)、麦克风(音频)、环境传感器(温度、湿度、气压),这些都很"真实"或者更接近与实际的产品,但对初学者来说反而不是很直观。
我们把sin(x)作为第一阶段的入门,对TinyML有了整体的认知,才方便在课程的第二阶段进行真实实战。
因为没有了真实传感器,所以sin(x)让我们把所有注意力集中在模型训练、模型优化、部署流程本身,而不是纠结在先把硬件都买回来。
三、STM32F103 的资源,够不够跑一个 TinyML 模型?
很多人听到"在 F103 上跑 AI",第一反应是:内存根本不够吧?
其实我们可以用一个非常工程师的方式,精确计算 一遍资源占用,来证明这件事在 F103 上是完全可行的。
(1)STM32F103 的典型资源情况
以我文章中使用的STM32F103RCT6为例:主频:72 MHz,Flash:256KB,SRAM:48 KB。对于很多传统裸机项目,这些资源绰绰有余;
对于 TinyML 来说,关键是:TFLM 运行时 + 模型参数 + 中间张量,需要多少 Flash / RAM?
(2)TinyML占用的资源如下:
拿真实数据说话,从下面的截图可以看出,我们的Demo使用的资源情况如下:
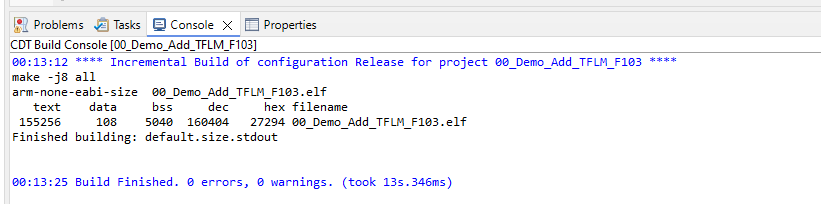
-
Flash 实际占用:
text + data = 155256 + 108 = 155364字节 ≈ 151.7KB -
RAM 实际占用:
data + bss = 108 + 5040 = 5148字节 ≈ 5.03KB
总之:对于 STM32F103 这类资源不算夸张的 M3 MCU,一个 sin(x) 级别的 TinyML Hello World,无论从 Flash 还是 RAM 的角度,都非常"轻量"。