lecture5
How is a GPU different from a CPU?
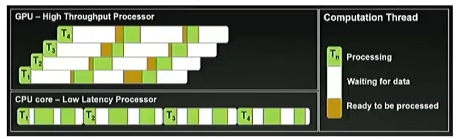
CPUs optimize for a few, fast threads while GPUs optimize for many many threads. (CPU目的是优化少但速度快的线程,GPU是针对大量线程进行优化)
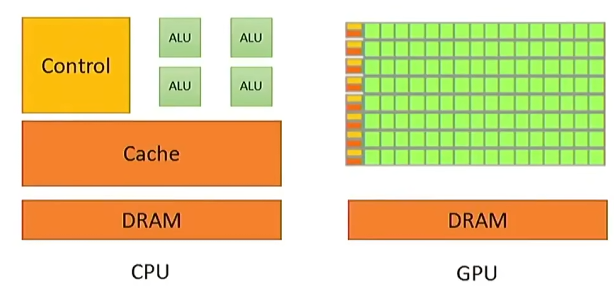
GPU有大量的compute units(ALU),优化的是总体数据的处理量,而CPU优化的是latency(每个线程尽快完成)
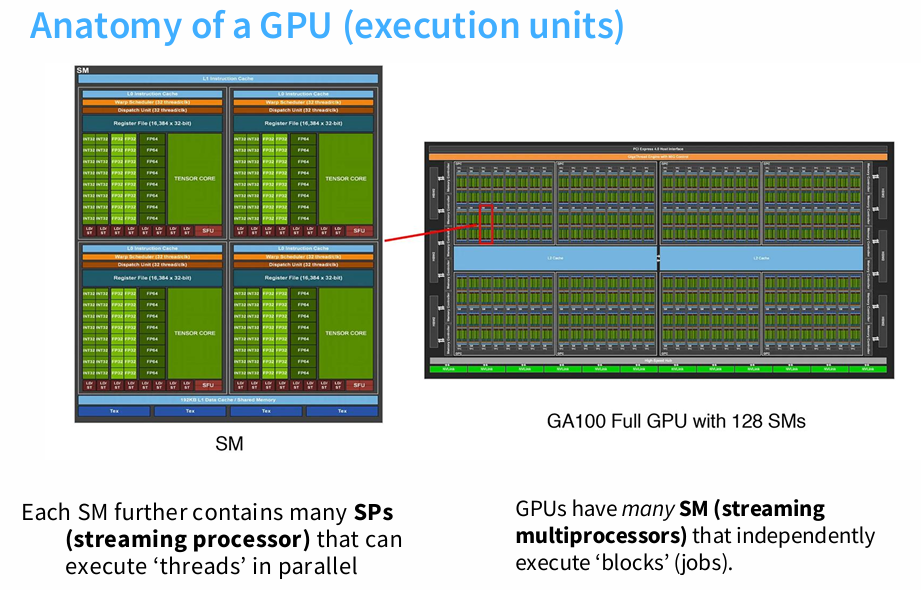
每个SM内部有大量的计算单元,然后每个SM都会启动很多的线程。
我们有很大的global memory(A100:80GB):big,slow
还有很多寄存器(上图中的蓝色部分):small,fast
Execution model
所以执行模型的流程如下:
我们有一系列线程块,一个线程块会被调度到一个SM上执行。而每个线程块内部有许多线程,实际执行计算的就是这些线程。
Why thread blocks? Shared memory.
在同一个线程块之内的线程有shared memory(as fast as L1 cache)。
流行处理器(SP)可以并行执行线程。SM有很多控制逻辑,它可以决定执行什么,SP的操作是接受相同的指令,并将其应用于许多不同的数据。
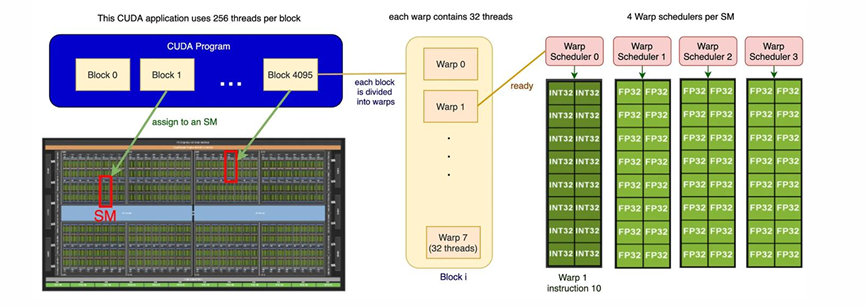
在这个execution model中,有三种层级。
1.Threads:用来执行并行任务。所有的线程会执行相同的指令,但有着不同的输入。
2.Blocks:一个block包含很多个threads。每个block在单独的SM上运行,并拥有独立的共享内存。
3.Warp:线程总是被划分为连续的32个为一组去执行。每一个block被划分为不同的warps。
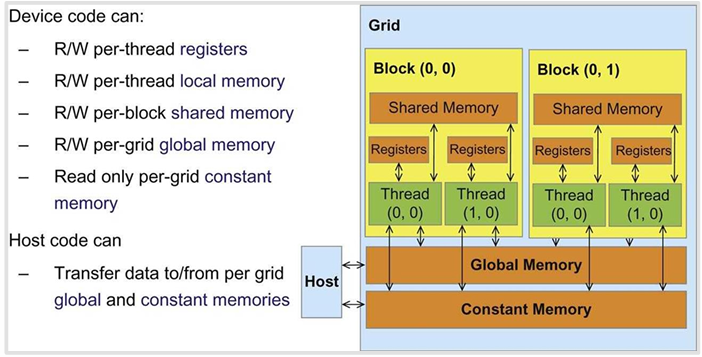
在GPU内部的memory传输中,每个线程私有一个Registers和local memory。理想情况下,某个线程执行任务所需要的一小块数据,可以写入shared memory,所有线程可以方便共享。相反,如果一个线程需要访问散落的数据,那就不得不写入global memory,会非常慢。
也就是说,跨越block的数据通信必须写入global memory。
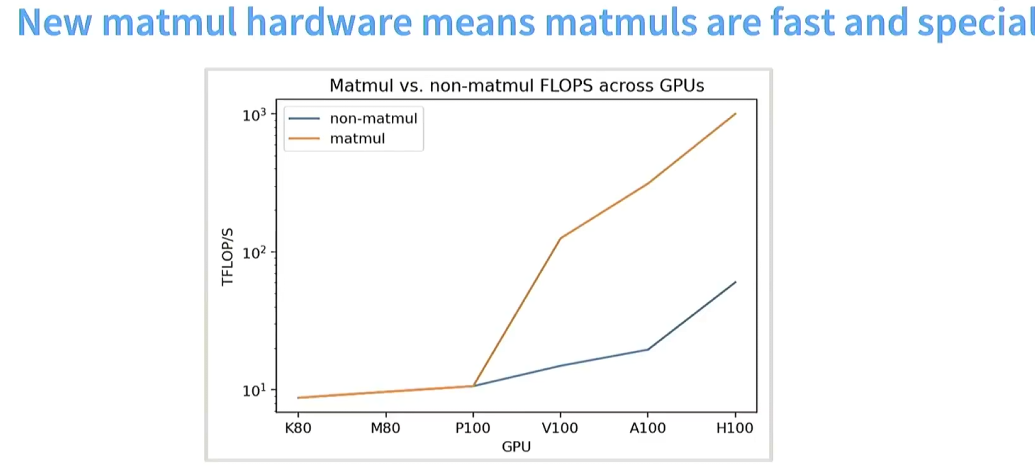
这就说明了在做神经网络架构时,我们要尽可能多的执行矩阵乘法运算。
How do we make GPUs go fast?
Triclk1:Control divergence :
GPUs操作在SIMT模型上---每个处于同一个warp的thread执行相同的指令。
假设有以下条件语句:

当执行if语句时,其它四个线程会停止。why?我不能在这些不同的线程上同时执行'A'和'X'吗?答案是每个线程必须执行相同的指令。所以在一个warp内部的条件语句可能非常有破坏性,因为它们会迫使你暂停那些完全没有按照主控制流执行的线程。
Trick2:Low precision computation
通过 ReLU(x)=max(0,x),我们来举个例子,对于 Float 32 来说,Memory access 需要读取一次 x, 1 if x < 0 需要 write 一次,float 32 = 8 bytes。由于需要比较大小所以 Operations 为 1 次,整个 Intensity: 8 bytes / FLOP。对于 Float 16 来说,float 16 = 4 bytes,但是 Operations 不变,所以 Intensity 整整小一倍。
Trick3:Operator fusion
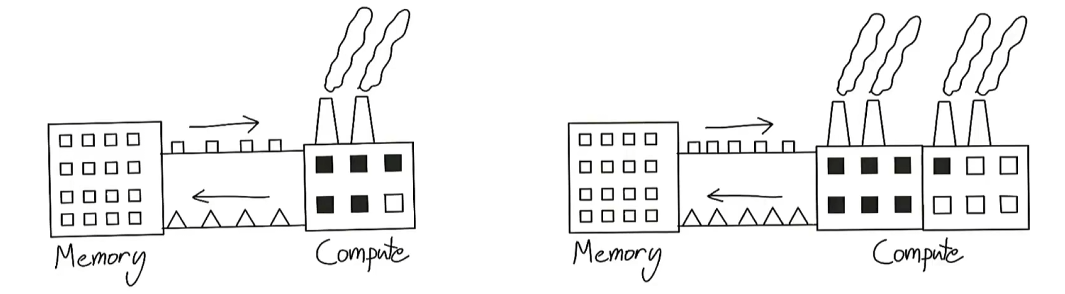
将GPU看作一个工厂,输入来自于一个房子(内存),工厂接收小方块,计算后输出小三角。
如果增加计算能力,但是传送带负责将内存数据传送到计算单元,是有限带宽的,这样的话,我们就无法同时使用两个工厂。也就是说,我们仍然受限于从内存到计算传输数据的速度。
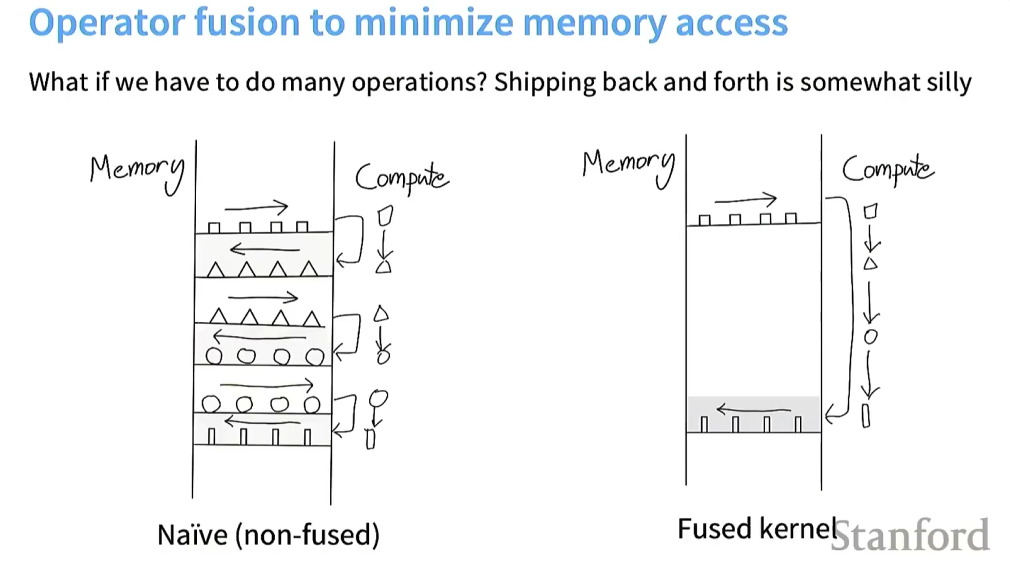
操作融合的思想就是:相比于左图需要不断的将数据运回内存再传输给计算单元,我可以在计算单元中一直运算,直到我必须将其送回内存时。
Trick4:Recomputation
在梯度回流的时候,我们会选择存储 activations,但这样会导致大量的 memory read/write,不如 Throw away the activations, re-compute them!这样我们会牺牲一点计算,来换取更少的内存访问。
Memory coalescing and DRAM(内存合并和 global memory)
当一个 warp 中的所有线程同时执行一个 load instruction,并且它们访问的内存地址落在同一个 burst section 内时,这些内存访问可以被合并为一个 DRAM 请求。(the big one): tiling。
tiling 是对线程进行分组和排序,以尽量减少 global memory access。下面这张图是一个实际的矩阵相乘的例子,这种情况下,thread0,0 和 thread0,1 要从 global memory 读取两次 M0,0,这显然会降低速度。那我们应该怎么办呢,将矩阵分割为很多的 tiles,然后加载进 shared memory。这样计算的优点在于:重复读取使用 shared memory 而非 global memory,速度快;线程访问的内存地址更连续,符合内存合并的优化原则,提高效率。