目录
- 摘要
- Abstract
- 一、什么是机器学习
- 二、有监督学习和无监督学习的区别
- 三、什么是过拟合、欠拟合,分别该如何解决
-
- [1、 过拟合](#1、 过拟合)
- 2、欠拟合
- 四、分类问题和回归问题的区别
- 五、怎么做异常检测,其目标函数是什么,与有监督学习的区别是什么
- 六、K-means的基本步骤,如何生成结果,计算方法,目标函数
- 七、单变量和多变量的线性回归模型是什么,损失函数是什么,梯度下降法怎么计算
- 八、正则方程和梯度下降优缺点是什么,学习率的设置不同有什么影响
- 九、协同过滤算法
- 十、如何在二分类的数据基础上做出多分类的问题
- 十一、主要的评估指标有哪些,召回率、F1等如何计算
- 十二、逻辑回归
- 总结
摘要
本周系统整理了机器学习的基础知识,涵盖了监督学习、无监督学习、模型评估和常用算法等多个核心主题。通过对比学习,我清晰地理解了监督学习与无监督学习的本质区别,掌握了过拟合与欠拟合的识别方法及解决方案。重点梳理了线性回归、逻辑回归、K-means聚类和异常检测等算法的原理和应用,并对分类问题的评估指标进行了总结归纳。
Abstract
This week I study systematically organized the foundational knowledge of machine learning, covering core topics including supervised learning, unsupervised learning, model evaluation, and common algorithms. Through comparative learning, I clearly understood the essential differences between supervised and unsupervised learning, and mastered the identification methods and solutions for overfitting and underfitting. Special emphasis was placed on summarizing the principles and applications of algorithms such as linear regression, logistic regression, K-means clustering, and anomaly detection, along with evaluation metrics for classification problems.
一、什么是机器学习
机器学习是计算机利用计算的手段,通过经验(一般来说都是以数据为载体)来改善自身系统性能的学科
传统的编程模式:输入数据 + 明确的规则(程序)= 输出结果
机器学习的模式: 输入数据 + 预期的结果 = 学习出隐含的规则(模型)
然后学习出的新规则可以用于对新的输入数据产生出正确的输出
二、有监督学习和无监督学习的区别
1、有监督学习
训练集中的每个训练样本都有其对应的标签,学习完后尽可能对训练集外的样本进行分类
2、无监督学习
训练集中的每个训练样本都没有对应的标签,对未标记的样本进行学习,来掌握被训练样本的结构知识
3、区别
首先,有监督学习的训练集中每个样本都有其对应的标签,而无监督学习的训练集中每个样本都没有标签,换句话说,我们是知道有监督学习的输出结果是什么,但是我们不知道无监督学习的输出结果是什么
其次,有监督学习主要处理的是连续的数据样本集,适合处理回归问题,而无监督学习主要处理的是离散的数据样本集,适合处理分类的问题
最后,有监督学习是可以被量化效果的,而无监督学习是无法量化结果的
三、什么是过拟合、欠拟合,分别该如何解决
1、 过拟合
过拟合的表现是,模型拟合训练集的效果非常好,但是模型拟合验证集的效果不好,特点是高方差。
解决的方法有: 增加训练样本
适当增加正则化约束
适当减少样本特征
降低模型复杂度
2、欠拟合
欠拟合的表现是,模型拟合训练集和验证集的效果都差不多,但是两者离预定表现的能力差距很大,特点就是高偏差
解决的方法有: 适当减少正则化约束
适当增加样本特征
适当增加模型复杂度
注意:欠拟合是无法通过增加训练样本来解决,原因是欠拟合本来就是模型拟合能力不足的表现,本身能力不行,你给再多的样本也是这个表现
四、分类问题和回归问题的区别
回归问题:输入变量和输出变量均为连续变量的预测问题被称为回归问题
分类问题:输入变量和输出变量均为离散变量的预测问题被称为分类问题
区别:
输出类型不同,分类问题输出的是离散变量,回归问题输出的是连续变量
目的不同,分类问题寻找的是决策边界,回归问题寻求最优拟合
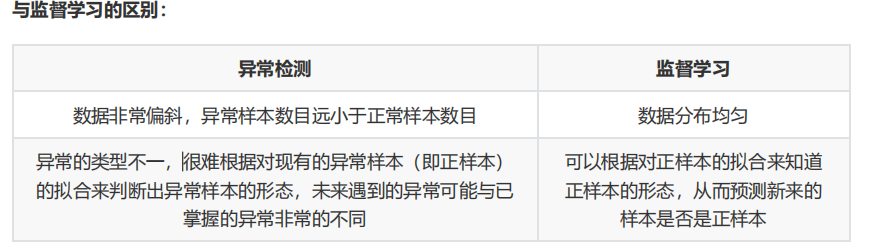
五、怎么做异常检测,其目标函数是什么,与有监督学习的区别是什么

六、K-means的基本步骤,如何生成结果,计算方法,目标函数

七、单变量和多变量的线性回归模型是什么,损失函数是什么,梯度下降法怎么计算

八、正则方程和梯度下降优缺点是什么,学习率的设置不同有什么影响


九、协同过滤算法

1、冷启动问题怎么解决
对于用户冷启动:可以先给其推荐热门的商品,等收集到足够的信息再做个性化推荐
对于物品冷启动:利用物品的特征,将其推荐给可能会感兴趣的用户
对于系统冷启动:我们可以引入专家的知识,通过一些高效的方式来快速构建出相关度表
十、如何在二分类的数据基础上做出多分类的问题
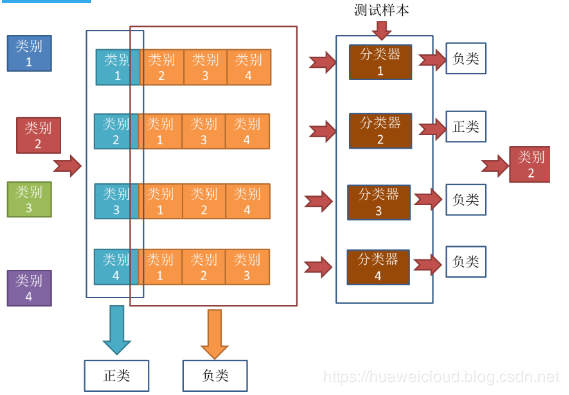
采用一对多(one-vs-all)方法。将一个类别作为正例,其余所有类别作为反例,这样 N 个类别可以产生 N 个二分类器,将测试样本输入这些二分类器中得到 N 个预测结果,如果仅有一个分类器预测为正类,则将对应的预测结果作为最终预测结果。
如果有多个分类器预测为正类,则选择置信度最大的类别作为最终分类结果。
下图所示,数据集中共 4 个类别,产生 4 个二分类器,类别 2 对应的分类器 2 预测结果为正例,则最终预测结果为类别 2。
十一、主要的评估指标有哪些,召回率、F1等如何计算
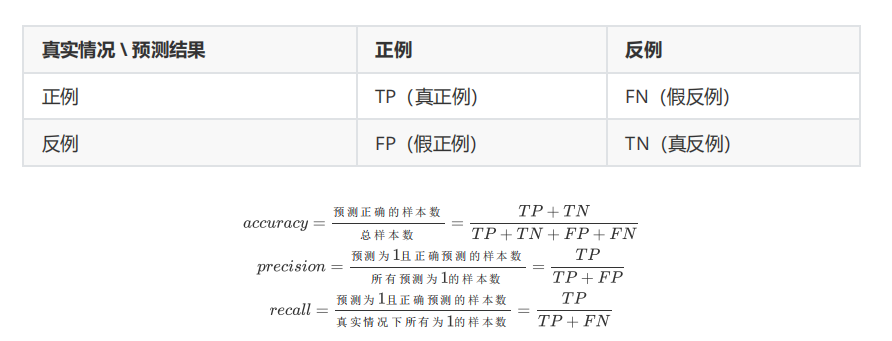
1、主要的评估指标
查准率:模型预测分类正确的样本当中,有多少个是正确的
召回率:实际正确的样本当中,模型查出多少正确的
准确率:正确分类的样本占总数的多少
具体公式如下:
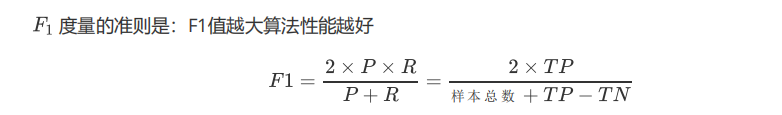

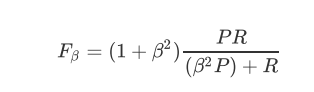

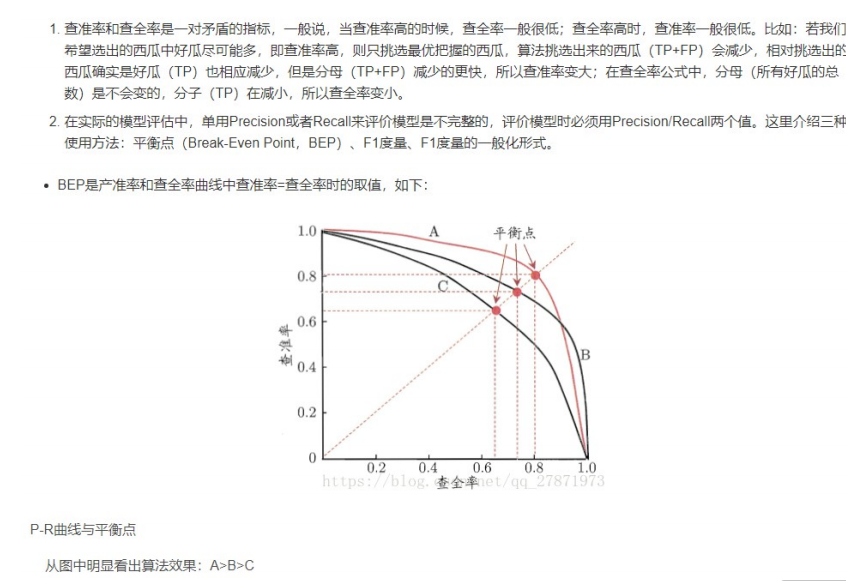
2、召回率和查准率的关系
十二、逻辑回归
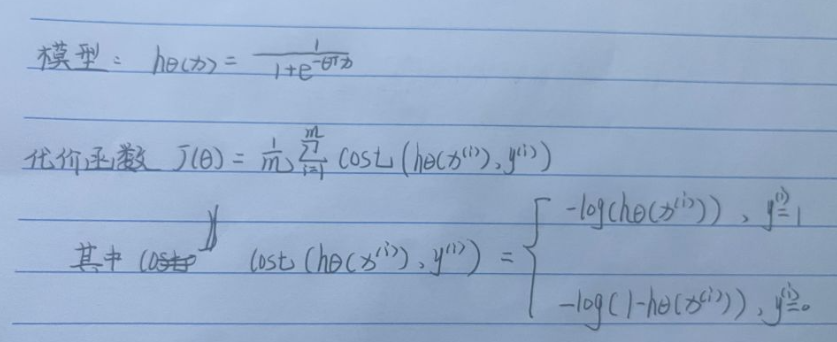

总结
本周的学习是一次全面的知识梳理,让我对机器学习的核心概念有了更系统的认识。最核心的收获是清晰区分了监督学习和无监督学习------一个有标签指导学习,一个靠数据自身结构发现模式。过拟合和欠拟合这对概念现在我能准确识别:过拟合是训练好但泛化差(高方差),欠拟合是两者都差(高偏差),而且明白了欠拟合不能靠增加数据解决。各种算法的对比也很有价值:线性回归用于连续预测,逻辑回归用于分类,K-means用于聚类,异常检测用高斯分布建模正常范围。评估指标部分,查准率、召回率和F1分数的计算和应用场景让我明白了如何全面评价分类模型。这些基础知识构成了我理解更复杂机器学习模型的坚实基础。