在AIGC视频赛道里,"多任务统一""长视频高效生成""可控性"往往是互相制约的难点------而阿里开源的WAN(通义万相)模型,通过巧妙的架构设计把这些痛点捏在了一起。今天我们就结合架构图,拆解WAN的技术骨架。
1. 先解决"长视频的内存噩梦":Wan-VAE
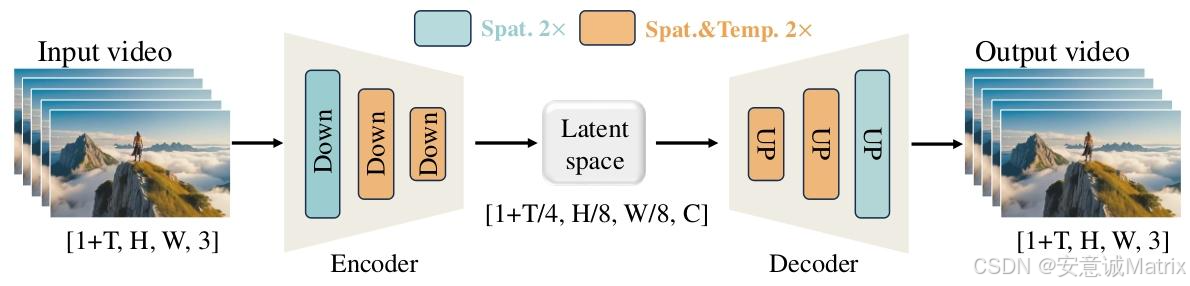
要处理视频,第一步就得面对"时间+空间"的双重数据爆炸:一段10秒的视频(按24帧算),像素维度是[241, H, W, 3](1+T里的1是参考帧),直接喂给模型会撑爆显存。
WAN的解法是3D因果变分自编码器(Wan-VAE),它是整个模型的"时空压缩引擎":
- Encoder:分层压缩,保留因果性
图1里的Encoder用了3个Down模块,分成两类:- 浅蓝色模块(Spat. 2×):只做空间下采样(分辨率缩小2倍),保留时间维度;
- 橙色模块(Spat.&Temp. 2×):同时做空间+时间下采样 (分辨率、时间帧各缩2倍)。
最终把输入视频[1+T, H, W, 3]压缩到隐空间[1+T/4, H/8, W/8, C]------既把数据量压到了原有的1/64左右,又保证了"未来帧不影响过去帧"的因果性,支持任意长度视频的流式处理。
- Decoder:精准恢复,还原细节
用和Encoder对称的Up模块,把压缩后的隐特征"还原"成原分辨率的视频输出[1+T, H, W, 3],确保生成结果的清晰度。
2. 生成与编辑的"核心大脑":扩散Transformer
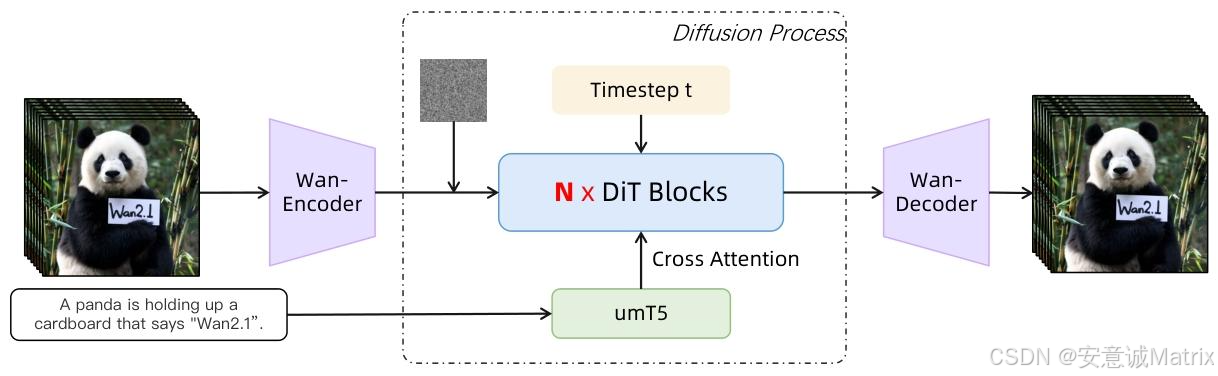
压缩后的隐空间只是"素材库",真正实现"文生视频、图生视频、局部编辑"的是扩散Transformer(DiT)模块:
- 多模态输入的"翻译官":umT5
图2里的umT5是多语言文本编码器,它把自然语言指令(比如"A panda is holding up a cardboard...")转换成特征向量,再通过Cross Attention和视频隐特征对齐------这一步让WAN能听懂中英双语的"编辑需求"。 - 逐步去噪的"画师":N×DiT Blocks
扩散过程中,模型会在不同时间步t给隐特征"加噪-去噪":DiT Blocks结合"时间步信息""文本特征""视频隐特征",一步步把随机噪声优化成符合指令的内容。 - 端到端的"接口":Wan-Encoder/Wan-Decoder
这里的Wan-Encoder/Wan-Decoder其实是调用了图1的Wan-VAE模块,负责把"原始视频/图片"转成隐特征、再把生成好的隐特征转成最终视频。
3. 架构设计的"巧思":为什么WAN能兼顾多任务与效率?
WAN的架构本质是"统一隐空间+模块化扩散":
- 不管是文生视频、图生视频还是局部编辑,所有任务都在Wan-VAE的隐空间里完成,不用为不同任务单独设计分支;
- 因果性压缩+隐空间计算,让1.3B参数的轻量版仅需8GB显存就能运行,消费级GPU(比如RTX 4090)也能部署;
- Cross Attention+多模态对齐,让WAN支持"文本+图片+mask"的组合控制(比如"保留熊猫主体,替换背景为雪山")。
写在最后
WAN的架构没有走"堆参数"的路线,而是用"Wan-VAE压缩+DiT扩散"的组合,在"效率、多任务、可控性"之间找到了平衡------这也是它能成为开源视频生成工具里"落地友好型选手"的关键。