在高性能网络编程的领域,我们一直在追求更低的延迟、更高的吞吐量。从 select、poll 到 epoll,每一次演进都带来了巨大的性能提升。而今天,io_uring 的出现,正引领着一场更深刻的变革。它不仅仅是 epoll 的简单升级,而是一种从根本上改变应用与内核交互方式的全新范式。
深入 io_uring 的内部:一套高效的"零拷贝"物流系统
io_uring 的高性能并非魔法,而是源于其精巧的内部设计。它在你的应用程序和内核之间,建立了一套基于共享内存的高效"物流系统"。
这套系统由两个核心组件构成:
-
提交队列 (Submission Queue - SQ): 你的"发货单"暂存区。
-
完成队列 (Completion Queue - CQ) : 内核送回的"收货回执"暂存区。
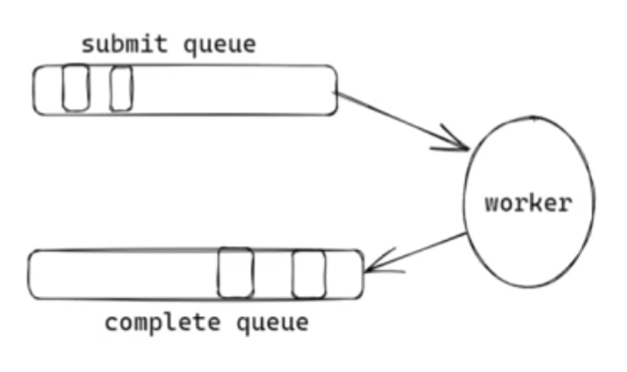
这两个队列存在于通过 mmap 创建的共享内存中,这意味着你的应用和内核可以像访问自家内存一样读写它们,彻底消除了传统系统调用中昂贵的内存拷贝开销。
整个工作流程如下:
-
打包任务 (构建 SQE) : 你需要发的每一个 I/O 请求,都会被打包成一个"任务单元",即 io_uring_sqe (Submission Queue Entry)。这个结构体里详细记录了任务的所有信息:要操作的 fd、数据要读/写到哪个 buffer (addr)、buffer 的多长 (len)、具体的操作类型 (opcode) 等。
-
"零拷贝"入队: 你的应用直接在共享内存的 SQ 中填写这个 SQE。这并非传统意义的拷贝,而是直接写入,效率极高。
-
通知内核: 通过一次 io_uring_submit() 系统调用(这是一个非常轻量的调用),直接批量把整个队列里的请求直接提交到系统里面。
-
内核异步处理: 内核的工作线程被唤醒,它直接从共享内存的 SQ 中取出任务,然后发起真正的异步 I/O 操作。在此期间,你的应用程序完全是自由的。
-
结果返回 : I/O 操作完成后,内核会在共享内存的 CQ 中放入一个"完成回执",即 io_uring_cqe (Completion Queue Entry),里面包含了操作的结果(如成功读取的字节数)。(注意此时想读写缓存里的内容已经被读进到咱们预先设置好的buffer 里面了)
-
应用获取结果: 你的应用通过检查 CQ 来获取已完成的任务结果,然后直接进行业务处理。
这套机制的核心优势在于:批量化、全异步、零拷贝。
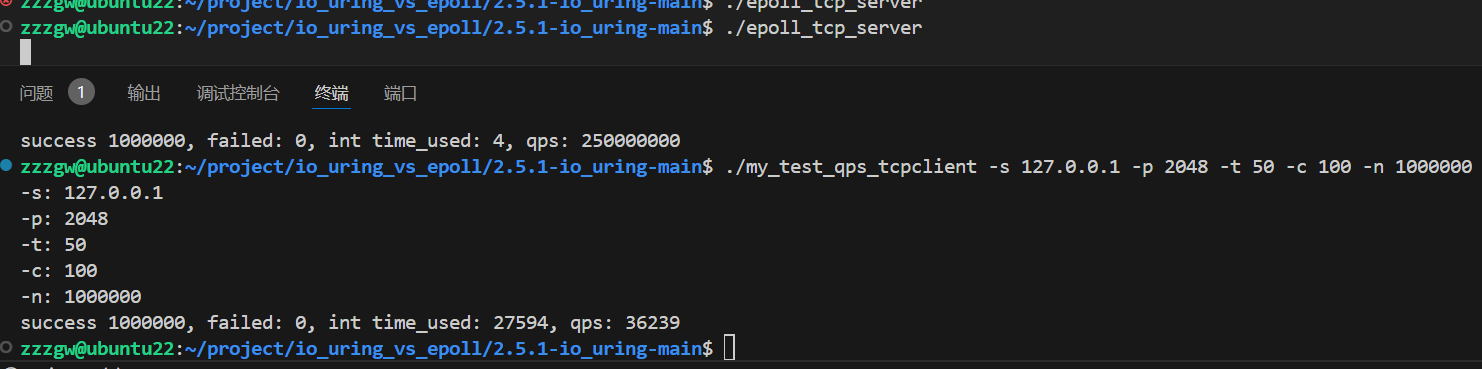
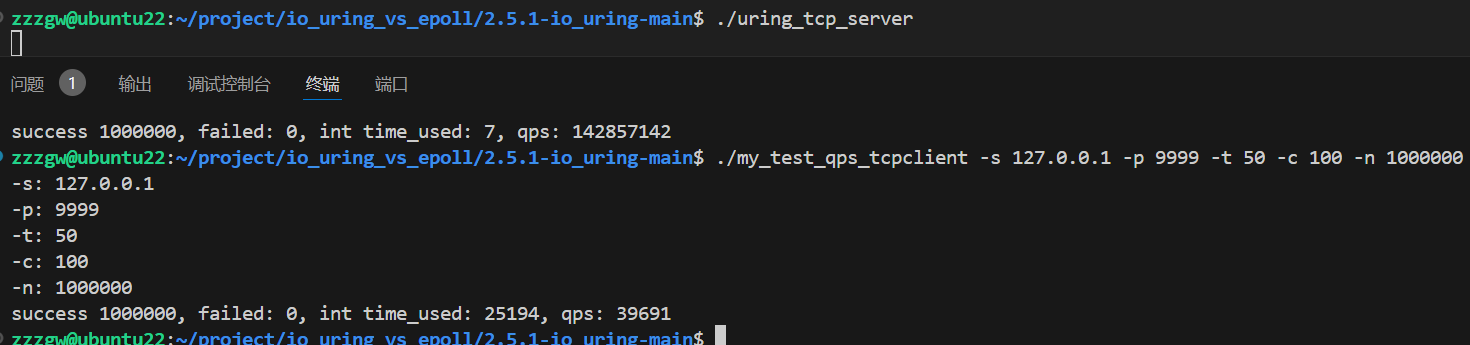
qps测试对比:
100W个包每个包 2 * 64Bytes
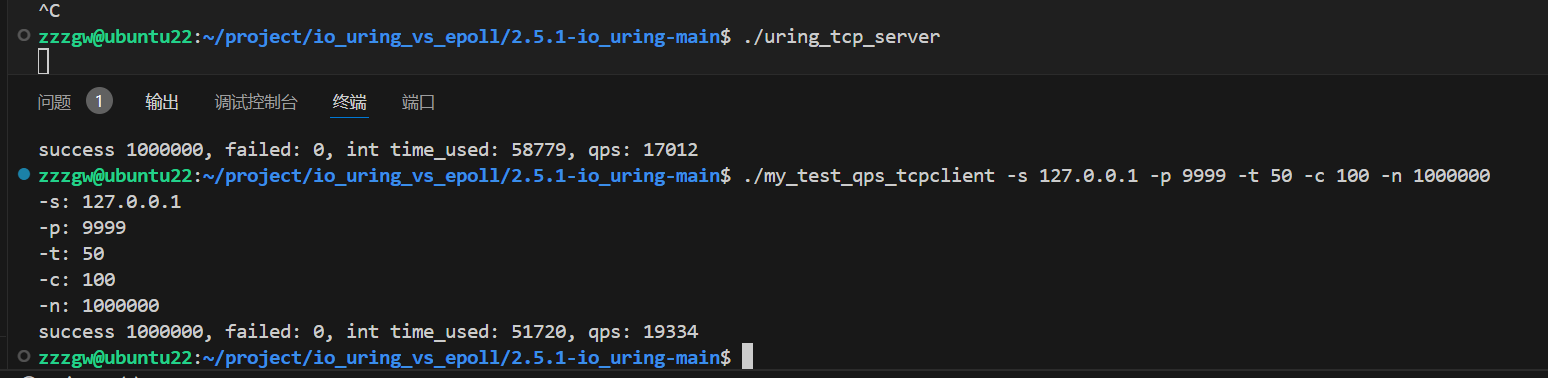
100W个包每个包 4 * 64Bytes

cpp
#include <stdio.h>
#include <liburing.h> // 包含了所有 io_uring 的函数和数据结构定义
#include <netinet/in.h>
#include <string.h>
#include <unistd.h>
// 定义三种不同的事件类型,用于在请求完成时区分是哪种操作
#define EVENT_ACCEPT 0 // 接受新连接事件
#define EVENT_READ 1 // 读数据事件
#define EVENT_WRITE 2 // 写数据事件
/**
* @brief 连接信息结构体
* 这个结构体作为上下文信息,会被附加到每一个提交给 io_uring 的请求 (SQE) 上。
* 当请求完成后,内核会原封不动地将它返回到完成队列 (CQE) 中。
* 这样,我们就能知道完成的这个事件是关于哪个 fd、属于哪种类型的操作。
*/
struct conn_info {
int fd; // 事件关联的文件描述符
int event; // 事件的类型 (EVENT_ACCEPT, EVENT_READ, or EVENT_WRITE)
};
/**
* @brief 初始化TCP服务器
* 这是一个标准的网络编程函数,用于创建、绑定和监听一个套接字。
* @param port 服务器监听的端口号
* @return 创建的监听套接字文件描述符
*/
int init_server(unsigned short port) {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in serveraddr;
memset(&serveraddr, 0, sizeof(struct sockaddr_in));
serveraddr.sin_family = AF_INET;
serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);
serveraddr.sin_port = htons(port);
if (-1 == bind(sockfd, (struct sockaddr*)&serveraddr, sizeof(struct sockaddr))) {
perror("bind");
return -1;
}
listen(sockfd, 10);
return sockfd;
}
#define ENTRIES_LENGTH 1024 // io_uring 队列的深度,表示可以同时处理多少个在途请求
#define BUFFER_LENGTH 1024 // 每个连接的读写缓冲区大小
/**
* @brief 准备一个异步接收数据的请求
* @param ring io_uring 实例的指针
* @param sockfd 要接收数据的文件描述符 (连接 fd)
* @param buf 接收数据的缓冲区
* @param len 缓冲区的长度
* @param flags 接收操作的标志,通常为0
* @return int
*/
int set_event_recv(struct io_uring *ring, int sockfd,
void *buf, size_t len, int flags) {
// 1. 从提交队列 (Submission Queue, SQ) 中获取一个可用的空槽位 (Submission Queue Entry, SQE)
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
// 2. 创建本次请求的上下文信息
struct conn_info read_info = {
.fd = sockfd,
.event = EVENT_READ, // 标记这是一个读事件
};
// 3. 使用 liburing 提供的帮助函数来填充 SQE,告诉内核这是一个 recv 操作
io_uring_prep_recv(sqe, sockfd, buf, len, flags);
// 4. 将我们的上下文信息拷贝到 SQE 的 user_data 字段中
memcpy(&sqe->user_data, &read_info, sizeof(struct conn_info));
return 0;
}
/**
* @brief 准备一个异步发送数据的请求
*/
int set_event_send(struct io_uring *ring, int sockfd,
void *buf, size_t len, int flags) {
// 步骤同 set_event_recv
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
struct conn_info write_info = {
.fd = sockfd,
.event = EVENT_WRITE, // 标记这是一个写事件
};
io_uring_prep_send(sqe, sockfd, buf, len, flags);
memcpy(&sqe->user_data, &write_info, sizeof(struct conn_info));
return 0;
}
/**
* @brief 准备一个异步接受新连接的请求
*/
int set_event_accept(struct io_uring *ring, int sockfd, struct sockaddr *addr,
socklen_t *addrlen, int flags) {
// 步骤同上
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
struct conn_info accept_info = {
.fd = sockfd, // 这里是监听的 sockfd
.event = EVENT_ACCEPT, // 标记这是一个 accept 事件
};
io_uring_prep_accept(sqe, sockfd, (struct sockaddr*)addr, addrlen, flags);
memcpy(&sqe->user_data, &accept_info, sizeof(struct conn_info));
return 0;
}
int main(int argc, char *argv[]) {
unsigned short port = 9999;
int sockfd = init_server(port);
struct io_uring_params params;
memset(¶ms, 0, sizeof(params));
struct io_uring ring;
// 初始化 io_uring 实例。这是最关键的一步。
// 内核会创建提交队列 (SQ) 和完成队列 (CQ) 所需的共享内存。
io_uring_queue_init_params(ENTRIES_LENGTH, &ring, ¶ms);
// 准备并提交第一个 accept 请求。
// 服务器必须先提交一个 accept 请求,才能接收客户端的连接。
struct sockaddr_in clientaddr;
socklen_t len = sizeof(clientaddr);
set_event_accept(&ring, sockfd, (struct sockaddr*)&clientaddr, &len, 0);
char buffer[BUFFER_LENGTH] = {0};
// 进入主事件循环
while (1) {
// 1. 提交请求
// 调用 io_uring_submit(),这是一个系统调用。
// 它会通知内核去检查提交队列 (SQ) 中是否有新的请求需要处理。
// 我们可以一次性准备多个请求,然后通过一次 submit 全部提交。
io_uring_submit(&ring);
// 2. 等待完成事件
struct io_uring_cqe *cqe;
// io_uring_wait_cqe() 会阻塞程序,直到完成队列 (Completion Queue, CQ) 中至少有一个完成事件 (CQE)。
// 这类似于 epoll_wait() 的作用。
io_uring_wait_cqe(&ring, &cqe);
// 3. 批量获取完成事件
struct io_uring_cqe *cqes[128];
// io_uring_peek_batch_cqe() 尝试从 CQ 中一次性取出多个已完成的事件,非常高效。
// 它返回实际获取到的事件数量。
int nready = io_uring_peek_batch_cqe(&ring, cqes, 128);
int i = 0;
// 4. 遍历并处理所有已完成的事件
for (i = 0; i < nready; i++) {
struct io_uring_cqe *entries = cqes[i];
struct conn_info result;
// 从 CQE 的 user_data 中拷贝出我们之前存入的上下文信息
memcpy(&result, &entries->user_data, sizeof(struct conn_info));
// 根据事件类型,执行不同的逻辑
if (result.event == EVENT_ACCEPT) {
// 一个 accept 请求完成了,意味着一个新客户端连接进来了。
// 我们需要立刻提交下一个 accept 请求,以便能继续接收其他客户端。
set_event_accept(&ring, sockfd, (struct sockaddr*)&clientaddr, &len, 0);
// entries->res 字段存放了 I/O 操作的结果。
// 对于 accept 操作,它就是新连接的文件描述符 connfd。
int connfd = entries->res;
// 为这个新连接提交一个读请求,准备接收客户端发来的数据。
set_event_recv(&ring, connfd, buffer, BUFFER_LENGTH, 0);
} else if (result.event == EVENT_READ) { // 一个读请求完成了
// 对于读写操作,entries->res 是成功读/写的字节数。
int ret = entries->res;
if (ret == 0) { // ret 为 0 表示客户端关闭了连接
close(result.fd);
} else if (ret > 0) { // 成功读取到数据
// 提交一个写请求,将刚刚读取到的数据原样发回 (Echo Server)
set_event_send(&ring, result.fd, buffer, ret, 0);
}
} else if (result.event == EVENT_WRITE) { // 一个写请求完成了
// 数据已经成功发回给客户端。
// 继续为这个连接提交一个读请求,等待客户端的下一次数据。
set_event_recv(&ring, result.fd, buffer, BUFFER_LENGTH, 0);
}
}
// 5. 标记事件已消费
// io_uring_cq_advance() 告诉内核,我们已经处理完了 nready 个完成事件。
// 内核可以安全地重用这部分完成队列的空间了。
// 这一步非常重要,必须调用!
io_uring_cq_advance(&ring, nready);
}
}结论:
epoll 已经足够优秀,但它仍然遵循"应用查询就绪态,应用执行I/O"的两步走模式。而 io_uring 则通过 Proactor 模式和基于共享内存的无锁队列,将这一过程简化为"应用提交任务,内核完成任务"的一步到位模式。极致的性能: 大幅减少了系统调用次数和用户态/内核态的切换,消除了内存拷贝,最大化地利用了CPU。